从头开始学人工智能day01
从头开始学人工智能
文章目录
- 从头开始学人工智能
-
- 第一天,先从pandas开始学习算法路线
-
-
- 选择编程工具(jupyter notebook或者idea)
- 介绍pandas
- 搭建环境(开启征程)
-
- 导库
- 使用序列化对象
- 使用date_range()函数生成一系列连续的日期值
- 使用DataFrame来生成一张表格
- 结合储备知识,做一个多功能的表
- 查看表的各项数据
- 查看数据(更科学性)
- 小结
-
第一天,先从pandas开始学习算法路线
选择编程工具(jupyter notebook或者idea)
介绍pandas
Pandas是一个开源的,BSD许可的库,为Python (opens new window)编程语言提供高性能,易于使用的数据结构和数据分析工具。
Pandas是NumFOCUS (opens new window)赞助的项目。这将有助于确保Pandas成为世界级开源项目的成功,并有可能捐赠 (opens new window)给该项目。
这是啥我们了解即可,主要是要知道做什么的,怎么用就好!
搭建环境(开启征程)
我这里使用的是idea当然,jupyter更推荐,因为我是java人,所以对工程性情有独钟,这没有多大影响,好吧,开启征程!建立一个项目,然后开始我们的第一天代码编写!
导库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
使用序列化对象
arr = pd.Series([1,3,5,np.nan,6,8])
print(arr)
输出结果就是类似于数组之类的一个索引对应一个数的结构类型,就是列向数组

使用date_range()函数生成一系列连续的日期值
dates = pd.date_range("20101023",periods=15)
print(dates)

这个也就是一个数组生成,可以相同
使用DataFrame来生成一张表格
indexs = pd.array([1,2,3,4,5],dtype="int32")
dataFrame = pd.DataFrame("-1",index = indexs,columns=list('abed'))
print(dataFrame)

参数就是values ,index(横向索引),columns(纵向索引)
然后就可以得到一张表了
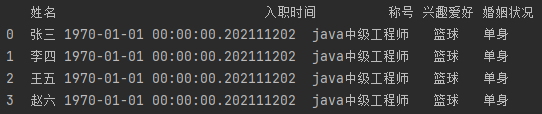
结合储备知识,做一个多功能的表
table = pd.DataFrame({
'姓名': ['张三', '李四', '王五', '赵六'],
'入职时间': pd.Timestamp(202111202),
'称号': pd.Series('java中级工程师', index = list(range(4))),
'兴趣爱好': np.array(['篮球']*4),
'婚姻状况': '单身'
})
print(table)
这里只是说明可以使用这些参数来建立这张表,不代表只能用这些!
可以发现,除啦前面的横向索引,其他的都是等长的列式数组一样的数据结构!
查看表的各项数据
print(table.dtypes) #表的各列数据类型
print("-----------------------------")
print(table.index) #表的全部索引
print("-----------------------------")
print(table.head()) #表的顺序前几个信息
print("-----------------------------")
print(table.tail(2)) #表的逆序前几个信息
print("-----------------------------")
print(table.columns) #表的列向索引信息
print("-----------------------------")
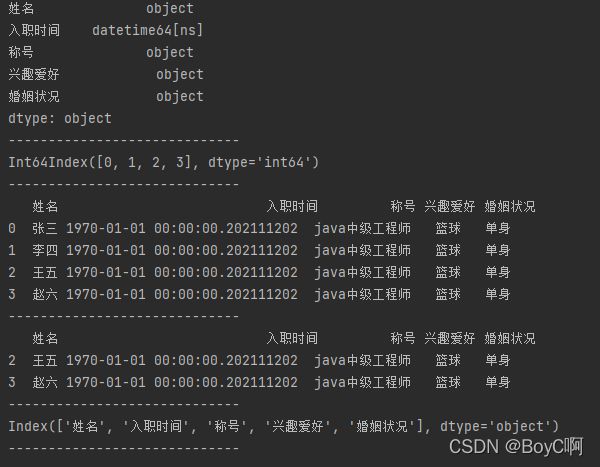
这里不在多解释,还有继续学习!
查看数据(更科学性)
print(table.values) #底层结构一目了然
print("------------------------")
print(table.describe()) #将数据统计好后显示
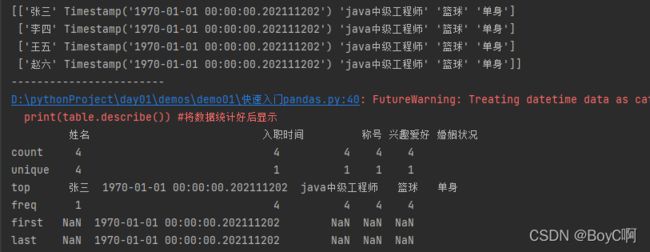
报错原因是因为没有可以进行数字统计的值,而使用了日期来统计,就会报错!这个问题不大,只是数据设计不是很好而已,下次改进!
通过索引查询想要列的数据
#按列索引信息
print(table["兴趣爱好"])

#转置
print(table.T)

升序排列或者降序排列
#按下标序排列
print(table.sort_index(axis=1,ascending=True))#true表示升序,false表示降序

这里提一嘴,还有一个按值排序,里面的axis参数也就变成了列,而且要具体到哪一列,参数是by
#按值序列排序
print(table.sort_values(by = "姓名",ascending=False))

这里是按照字典序排列的!降序!!!
小结
pandas入门就结束了,后面就是实战联系了,当然,我们还得回去补补numpy,慢慢来吧,后天就是蓝桥杯了!
纪录于2022 04 07