知识图谱(一)—— 简介
个人认知,仅供参考,欢迎大佬们批评指正!
知识图谱简介
一、 概述
从2012年,谷歌提出知识图谱概念以来,知识图谱在AI领域变逐步处于一个掌上明珠的地位,尤其近几年,知识图谱火的一塌糊涂。互联网相关公司,都会有人问,是否在做知识图谱。不管技术、产品、前端、销售,都对知识图谱有着无限美好的憧憬。
然而问题来了,在这样一个知识图谱发展火热的背景下,很多人被放大的宣传错误引导,认为知识图谱拥有像智能大脑一样的潜能,能做到非结构化到结构化数据、智能推荐、智能搜索、智能推理等等强大的功能。诚然,这些功能基于知识图谱都是可以做到的,但是却不完全是知识图谱的功劳。知识图谱可以理解为 一个牛逼的知识库,像是变形金刚,能将关系数据库存储模式变成点点边这种实体关系的存储结构,并能很好的展示,更直观、更形象、更便捷。
但是知识图谱中的实体 关系,是通过NLP信息抽取的功能,以及相关的文本解析,视觉分析,音频分析等AI算法,将多模态的非结构化数据转化为结构化数据之后,存储到知识图谱中,而进行下一步的应用。所谓的智能推理,也是基于知识图谱,结合相关算法实现的。
虽然独立的知识图谱看起来比较简单,但是依附于知识图谱产生的一系列技术,包括信息抽取、实体链接、知识推理等技术,以及基于知识图谱的下游应用,是很强大的。知识图谱也为一些之前难易解决的问题,提供了很好的启发。
下面几章节,我来简单介绍一下知识图谱构建的流程以及应用,便于大家更直白的了解。
二、 知识图谱构建
知识图谱的构建包括两部分, 数据层和模式层。
数据层,存放具体的实体和关系/属性,包括 实体-关系-实体, 和 实体-属性-值 两种基本的方式。实体和值采用节点表示, 关系和属性采用边表示,通过数据层这种实体和实体之间的关系建立以事实为单位存储的数据库,同时可以对实体,通过属性进行相关描述添加。
模式层,在数据层之上,是经过提炼的只是,通过本体库来管理,借助本体库对实体、关系以及实体的类型和属性等数据层内容进行限制。
数据层和模式层的区别联系,可以理解为代码中的 类和对象的区别。 模式层相当于类, 数据层相当于实例化之后的对象。
举例:
模式层:公司-法人-人;公司-成立时间-时间;
数据层:腾讯-法人-马化腾;腾讯-成立时间-1998年11月;
知识图谱的构建有自顶向下和自底向上两种构建方式。自顶向下构建通常借助于百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库中;所谓自底向上构建,通过借助一定的技术手段,从公开采集的数据中提取出相关模式,选择置信度高的新模式,经人工审核,加入知识库中。目前大多知识图谱构建采用自底向上的构建方式,本文也主要介绍自底向上的知识图谱构建技术, 按照知识获取的过程,分为三个层次:信息抽取、知识融合和知识加工。
2.1 知识图谱构建技术
信息抽取
通过不同类型的数据源提取出实体(概念)、属性以及实体之间的关系,再次基础上形成本体化的知识表达。
目前的数据源包括文本(网页、图表、文件等)、语音、图片、视频等类型,目前基于文本的信息抽取比较多。这里主要介绍基于文本的信息抽取方法,语音视频方面自行研究。
基于文本的信息抽取主要包括:实体识别、关系抽取、属性抽取。
实体抽取NER:无监督方法多采用词典、规则、句法等,有监督的NER方法主要有HMM、EMHMM、CRF、LSTM+CRF、BERT+LSTM+BERT,具体方法可以浏览我其它博文或自行百度。
关系抽取:初始多采用语法和语义规则实现,有标注数据的前提下可以转化为 实体-关系-实体 是否正确的二分类问题,可以通过人为构建特征(例如文本中的距离,是否有标点符号,实体位置,关系类型等),通过机器学习分类(SVM、NB、LR、GBDT等)方法进行二分类。随着神经网络的兴起,及BERT预训练模型的训练,也随之出现了对偶注意力模型、端到端的实体+关系抽取模型等。
属性抽取,同关系抽取。另外还包括一些半结构化数据进行自动抽取训练。
这里多说一点, 远程监督的逻辑,对于关系抽取,因为难易标注大规模的语料,可以考虑采用远程监督,通过已有标注实体对,进行文本标注,来得到近似人工标注的数据,从而进行进一步模型训练和调优。
知识融合
信息抽取得到的结构化数据可能包含大量的冗余和错误信息,数据之间的关系也是扁平化的,缺乏层次性和逻辑性,需要进行进一步清理和整合。随之而来诞生了很多知识融合相关技术,包括 实体链接、知识合并等。
聊技术之前,让我先来说说我看到的一大堆头疼的概念:实体链接、实体消歧、实体链指、实体对齐、属性对齐、共指消解.... (有没有看了很晕)
实体链接/实体对齐/实体链指: 这三者是同一件事儿,指的是将不同数据源的相同的实体(可能有不同的描述)指向同一个对象,进行对齐。
实体消歧:判断知识库中的同名实体是否代表不同的含义,可以理解为解决实体概念的一词多义现象。经典的例子是“苹果”指的是水果,还是手机。实体消歧是实体链接下的一个子任务。
属性对齐:把同一个属性的不同描述方式进行融合。
共指消解:知识库中是否存在其它命名实体和当前实体表示相同的含义。
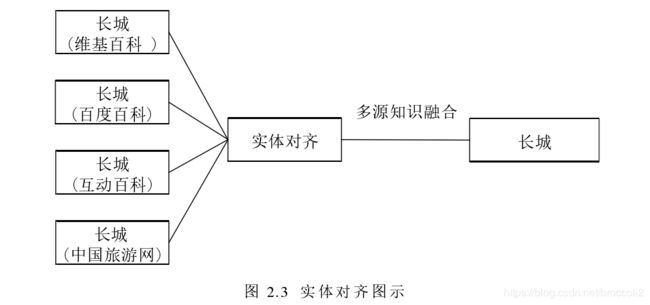
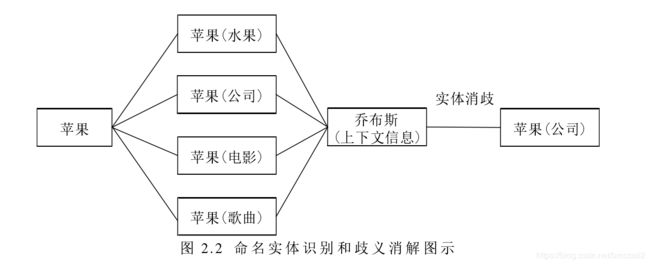
实体链接的一般流程:
1. 从文本中通过实体抽取得到实体指称项
2. 进行实体消歧和共指消解
3. 再确认知识库中对应的正确实体对象后,将该实体指称链接到知识库中对应实体
知识合并
将现有的知识库与第三方知识库进行合并,第三方知识库可能是关系数据库,也可能是外部知识库。合并的操作主要包括 数据层的融合和模式层的融合。
数据层的融合包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余;
模式层的融合,主要是将得到的本体融入已有的本体库中。
知识加工
通过信息抽取,可以从原始语料中提取出实体、关系与属性等知识要素,再经过知识融合,可以消除实体指称项与实体对象之间的歧义,得到一系列基本的事实表达。然而事实本身并不等于知识,要想最终获得结构化,网络化的知识体系,还需要经历知识加工的过程。知识加工主要包括3方面内容:本体构建、知识推理和质量评估。
本体构建
即模式层的本体概念模板构建,通常领域专家制定,或者通过实体相似度计算,进行粗略归类之后,人工进行相关统计归纳得到。
知识推理
知识图谱之间大多数关系都是残缺的,缺失值非常严重,知识推理是指从知识库中已有的实体关系数据出发,进行计算机推理,建立实体间的新关联,从而拓展和丰富知识网络。知识推理是知识图谱构建的重要手段和关键环节,通过知识推理,能够从现有知识中发现新的知识。假设,A的孩子Z,B有孩子Z,那么A,B的关系很有可能是配偶关系
知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等。
知识的推理方法可以分为2大类:基于逻辑的推理和基于图的推理。
基于逻辑的推理主要包括一阶逻辑谓词、描述逻辑以及基于规则的推理。
基于规则的推理可以利用专门的规则语言,如SWRL(semantic Web rule language)。
基于图的推理方法主要基于神经网络模型或Path Ranking算法。Path Ranking算法的基本思想是将知识图谱视为图(以实体为节点,以关系或属性为边),从源节点开始,在图上执行随机游走,如果能够通过一个路径到达目标节点,则推测源和目的节点可能存在关系。
质量评估
对知识的可信度进行量化,通过舍弃置信度较低的知识,可以保障知识库的质量。
知识更新
包括概念层的更新、数据层的更新
- 概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的概念层中
- 数据层的更新主要是新增或更新实体、关系、属性值,对数据层进行更新需要考虑数据源的可靠性、数据的一致性(是否存在矛盾或冗杂等问题)等可靠数据源,并选择在各数据源中出现频率高的事实和属性加入知识库。
知识图谱的内容更新有两种方式:
- 全面更新:指以更新后的全部数据为输入,从零开始构建知识图谱。这种方法比较简单,但资源消耗大,而且需要耗费大量人力资源进行系统维护;
- 增量更新:以当前新增数据为输入,向现有知识图谱中添加新增知识。这种方式资源消耗小,但目前仍需要大量人工干预(定义规则等),因此实施起来十分困难。
------------------------------------------------------
相关参考链接:
概述:https://blog.csdn.net/coder_oyang/article/details/88376537?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-10.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-10.channel_param
https://zhuanlan.zhihu.com/p/84861905( zh 推荐)
知识融合:
https://blog.csdn.net/pelhans/article/details/80066810
知识推理 https://zhuanlan.zhihu.com/p/89803165
实体链接 https://zhuanlan.zhihu.com/p/88766473
https://blog.csdn.net/broccoli2/article/details/102531077?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~first_rank_v2~rank_v25-1-102531077.nonecase&utm_term=%E5%AE%9E%E4%BD%93%E5%AF%B9%E9%BD%90%E6%98%AF%E4%BB%80%E4%B9%88&spm=1000.2123.3001.4430
KBQA :https://m.sohu.com/a/163278588_500659/?pvid=000115_3w_a