图数据库扫盲和图数据选用
基础
存储实体和实体之间关系的数据结构,称为图
图数据库并不是指存储图片、图像的数据库,而是指存储图这种数据结构的数据库
图数据应用
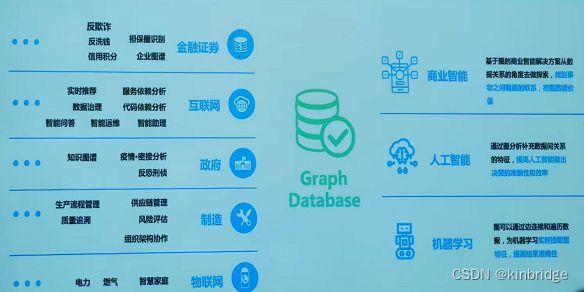
什么是图
我们通过下面的例子来认识一下。
东汉末年,孙权、刘备联军曾在赤壁一带以火攻敌船之计大破曹军。
如果我们把各阵营之间的关系抽象一下,以阵营作为点,阵营之间的关系作为边,这样我们就可以用如下的图来形象地表示上述关系:
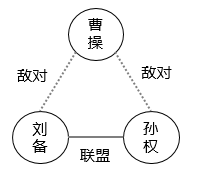
以上就是这里所谓的图(的可视化展示)。
我们把这种存储实体和实体之间关系的数据结构,称为图,Graph,图由点和边组成,一个点就是一个实体,比如上述实例中的阵营,两个实体之间的关系则用有方向或无方向的边来表示,比如刘备和孙权之间的联盟关系等。这种通用的结构可以对现实中的各种场景进行建模,从交通运输系统到组织架构管理,从工艺流程设计到社交网络。
什么是图数据库
知道了图的概念,你就可以理解什么是图数据库了。简单来说,图数据库就是用来处理图这种数据结构的工具。
不同于传统的使用二维表格存储数据的关系型数据库,图数据库在传统意义上被归类为NoSQL(Not Only SQL)数据库的一种,也就是说图数据库属于非关系型数据库。
一般的图数据库至少包含图存储、图查询、图分析这三种功能。
为什么要用图数据库
那我们为什么要用图数据库呢?我们还是用东汉末年的例子来讲解一下图数据库相对于关系型数据库的优势。
假设某关系型数据库中有三张表,分别是东汉末年人物表、东汉末年战役表和东汉末年人物参战表。

当我们想知道“樊城之战的守方是谁”,查询一般会比较快,从表2可以直接得到,但当我们想知道“刘备集团发动了哪些战争”的时候,尽管我们也可以从表2查到答案,但是我们可能需要遍历整个表2,查询效率会瞬间降低。而当我们要查询诸如“关羽出战过刘备集团发动的哪些战争”的时候,我们来看一下执行这条查询时关系型数据库是怎么做的:
A. 首先通过东汉末年人物表找到关羽对应的人物ID
B. 再使用东汉末年人物参战表找到其参战的战役
C. 最后通过东汉末年战役表找到其参战的哪些战役的攻方是刘备集团
我们会发现,这个查询实在是太繁琐了。
而如果我们将以上表格转化为如下的一张关系图谱,那么谁和谁是什么关系就一目了然了。

这么说也许你还没有真正领略到图数据库的巨大威力,我们再来看一个最经典的社交网络中查询性能对比的数据。
在《Neo4j in Action》这本书中,作者做了一个测试:在一个包含100万人,每个人约有50个朋友的社交网络中找最大深度为5的朋友的朋友,得到的实验结果如下:

测试结果表明,深度为2时两种数据库的性能差别不大,都很迅速;当深度为3时,关系型数据库需要半分钟完成查询,图数据库依旧在1秒内搞定;当深度为4时,关系型数据库耗费了接近半小时返回结果,图数据库不到2秒;而当深度达到5以后,关系型数据库就迟迟无法响应了,图数据库却依旧可以「秒杀」,表现出了非常良好的性能。
据此,我们可以从以下几个方面理解为什么要用图数据库:
- 关系型数据库不擅长处理数据之间的关系,而图数据库在处理数据之间关系方面灵活且高性能
我们不可否认关系型数据库自上世纪80年代以来一直都是数据库领域发展的主力,当前,随着社交、物联网、金融、电商等领域的快速发展,由此产生的数据呈现指数级的增长,而传统的关系型数据库在处理复杂关系的数据上表现很差,这是因为关系型数据库是通过外键的约束来实现多表之间的关系引用的。查询实体之间的关系需要JOIN操作,而JOIN操作通常非常耗时。
而图数据库的原始设计动机就是更好地描述实体之间的关系。图数据库与关系型数据库最大的不同就是免索引邻接。图数据模型中的每个节点都会维护与它相邻的节点关系,这就意味着查询时间与图的整体规模无关,只与每个节点的邻点数量有关,这使得图数据库在处理大量复杂关系时也能保持良好的性能。
另外,图的结构决定了其易于扩展的特性。我们不必在模型设计之初就把所有的细节都考虑到,因为在后续增加新的节点、新的关系、新的属性甚至新的标签都很容易,也不会破坏已有的查询和应用功能。
- 数据之间的关系越来越重要
当我们在问图数据库为什么如此重要时,其实就是在问,数据之间的关系为何如此重要?正如大家都知道人际关系的价值,其实数据的价值也在于它们之间的关联关系上。
举个例子。最近直播带货非常火,假如某个主播在微博上有几百万的粉丝,这个数据如果不利用起来,价值并不大,但如果他直播带货,把关注他的粉丝和可能来他直播间购物的顾客联系起来时,这些数据立马展现出巨大的商业价值。
- 使用图的方式表达现实世界中的很多事物更直接,更直观,也更易于理解
自然界中有各种各样的关系,而关系型数据库只能把这些拍扁成表格形态的行列数据,而图数据基于图模型以一种直观的方式去模拟这些关系,因而更形象。
另外,现在大部分的图数据库都提供了可视化的图展示,使得查询和分析变得很直观。
- 专业的图分析算法为实际场景提供解决方案
图数据库起源于图理论,借助于专业的图分析算法,能够为实际场景提供合适的解决方案。
图数据库如何存储、查询、分析
- 图存储
图数据库如何存储图,对查询和分析效率至关重要。图数据库使用图模型来操作图数据。所谓的图模型是指图数据库描述和组织图数据的方式。
目前主流的图数据库选择的图模型是属性图。属性图由点、边、标签和属性组成,我们结合一个具体的属性图实例来看一下。
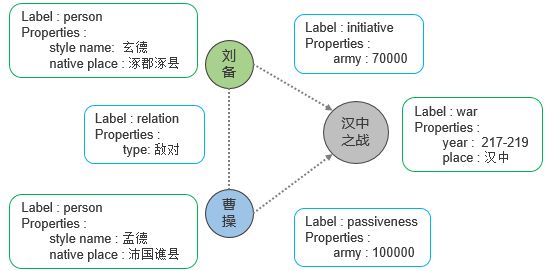
以上属性图可以帮助我们理解一些相关概念:
1) 可以为点设置标签,比如 person, war等,拥有相同标签的点我们认为它们属于一个分组,是一个集合,这样刘备和曹操属于一个分组;
2) 同样可以为边设置标签,标签可以为 relation等;
3) 节点可以拥有很多属性,比如 style name、year等,这些属性值以键值对的形式表示,例如:刘备的style name是玄德;
4) 边也可以拥有属性,比如army等;
5) 边允许有方向,例如刘备和汉中之战之间的边的方向是由刘备指向汉中之战的;
6) 元数据是用来描述点和边的属性信息的,元数据由若干标签组成,每个标签由若干属性组成。
- 图查询
如果我们想知道刘备的籍贯在哪,刘备和曹操是什么关系,汉中之战的发动方是谁等等,这些都属于图查询的范畴。
我们知道,SQL是关系型数据库的查询语言,但是图数据库的查询语言并没有复用SQL。这是因为本质上图数据库处理的是高维数据,而SQL所适用的是二维的数据结构,其并不擅长关系的查询和操作。使用专门的图查询语言比SQL更加高效。
目前主流的图查询语言包括Gremlin和Cypher等。
- 图分析
图分析是指通过各种图算法来挖掘图信息的一门技术。
核心的图算法可以分成三类:路径搜索类、中心性分析类和社区发现类。
路径搜索是探索图中节点通过边建立的直接或间接的联系。例如在下图中,通过路径搜索,我们发现了这样一条路径:孙策-[夫妻]-大乔-[姐妹]-小乔-[夫妻]-周瑜,据此得知孙策和周瑜是连襟的关系。路径搜索类算法广泛用于物流配送、社交关系分析等场景。

中心性分析是指分析特定节点在图中的重要程度及其影响力。例如在上图中,直观来看,孙权是一个重要的人物,因为与他直接相连的边的数量最多。中心性分析类算法一般用于网页排序、意见领袖挖掘、流感传播等场景。
社区发现意在发现图中联系更紧密的群体结构。如果把更多的三国人物和关系加到上图中,利用Louvain等社团挖掘类算法,我们很容易发现这些人物分属三个阵营,如下图所示。

社区发现类算法可用于犯罪团伙挖掘等场景。
图数据库有什么用
介绍完图数据库的主要功能,我们再来看看图数据库都有哪些应用场景。图数据库擅长的应用领域包括:
- 社交领域:Facebook, Twitter用它来进行社交关系管理、好友推荐
我们熟悉的好友推荐。就可以采用推荐好友的好友的方法。

徐庶和司马徽向刘备推荐诸葛亮可以通过下图形象地展示

- 电商领域:华为商城用它来实现商品实时推荐
通过分析目标用户和其他用户的喜好商品,找到相似的其他用户,把这些用户购买过的商品推荐给目标用户。
- 金融领域:中国工商银行、摩根大通用它来做风控管理
目前来看,金融领域对图数据库的需求很迫切,以贷款为例,在整个贷款周期中,图数据库都能发挥巨大的作用。

- 安平领域:公安用它来进行嫌疑关系审查、犯罪团伙挖掘
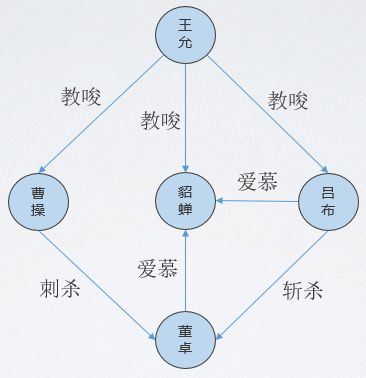
东汉末年,曹操刺杀董卓,貂蝉挑拨董卓父子关系,吕布斩杀董卓,但是董卓却不知道,这些事件幕后主凶之一都有王允,如下图所示。现实中也可能是这样,幕后真凶可能与目标案件没有直接关系,只有间接的关系。
什么样的场景适合用图数据库
你可以根据以下几点来判断你的问题是否需要图数据库:
如果你的问题中频繁出现多对多的关系,建议首选图数据库;
如果你的问题中数据之间的关系非常重要,建议首选图数据库;
如果你需要处理大规模数据集之间的关系,建议首选图数据库。
图数据库产品
现在图数据库产品已经出现百家争鸣的局面,Neo4j作为老牌图数据的代表,尽管依然拥趸众多,但是由于其自身的缺陷,挑战者正在增多,而华为云图引擎图数据库GES作为国产图数据库之光,正在成为其中的佼佼者。
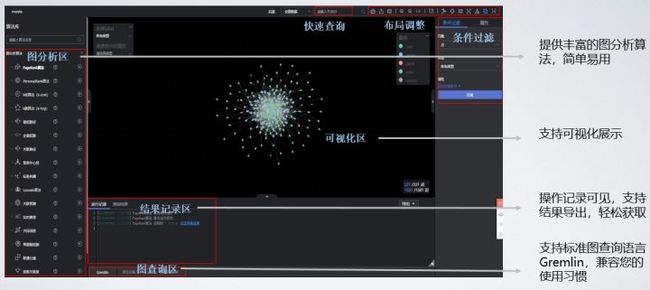
1. 图数据库概览
Tips:
不了解一个领域的时候,先去找找这个领域的白皮书。
想做一个知识图谱,需要调研一下图数据库,就直接去找这方面的白皮书。相对权威但是不是非常实时的内容
或者直接搜索知识图谱 图数据库 对比。不那么权威但是相对实时的内容,另外有人使用说明这个东西比较实在。
结合一下,得到的结果应该就比较靠谱了
- 白皮书:
知识图谱标准化白皮书(2019) - 搜索博客文章:
✅图数据库排名、对比
知识图谱简介及常用图数据库Neo4j vs OrientDB
【持续更新】知识图谱相关工具平台整理
以上内容中基本都提到一个网站:DB-Engines Ranking - popularity ranking of graph DBMS
所以听得最多的,基本就是第一名了,和猜测中一样,基本就是要去使用neo4j这个图数据库了
另外,还有个趋势图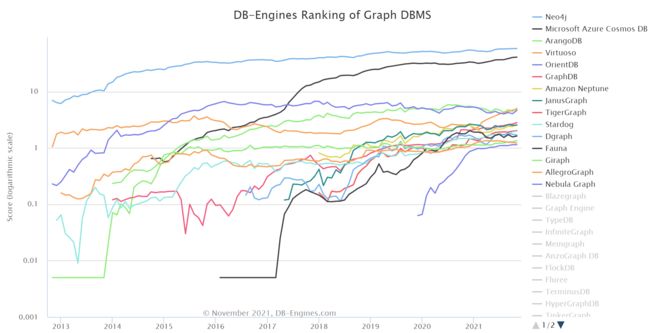
虽然neo4j还是第一,但是第二名的微软的cosmos隐隐有超过的趋势。。。网上似乎没有很多关于Azure Cosmos DB的介绍,这里放了一个博客和官方文档链接,有兴趣的可以看看
- Azure Cosmos DB(Azure 宇宙数据库)–地球已无法阻止微软玩数据库了
- 世纪天成运营的——Azure Cosmos DB 文档
- 微软本身的——Azure Cosmos DB 文档
2. neo4j比较
另外,还有几张很大的图表,也直接汇总到一起好了。
来源于:图数据库排名、对比
Neo4J和JanusGraph比较
| 特性\数据库名称 | Neo4j | JanusGraph |
|---|---|---|
| 是否开源 | 社区版开源,企业版收费 | 完全开源 |
| 第一版发行时间 | 2007年 | 2016年12月【基于TitanDB[2012]】 |
| 技术特点 | 一站式服务、工具齐全 | 需要开发者自行组合,因此技术门坎高 |
| 查询语言 | Cypher | Gremlin |
| 开发语言 | Java | Java |
| 集群 | 企业版支持,社区版不支持 | 支持 |
| 量级 | 轻量级 | 重量级 |
| 额外组件依赖 | 官方提供组件,可以与ES、MongoDB、Cassandra等NoSqlDb进行交互 | 数据存储服务可以选用Cassandra、HBase或Berkeley DB服务。数据索引可以选用Es、Solr或Lucene服务。 |
- 这里其实有一个点要注意,查询语言。。。
- 普通的关系型数据库采用的查询语言都是基于sql的,只是各家数据库厂商实现会有差距
- 但是对于图数据库这种新兴的数据库,标准并没有完全统一。
- 另外,之前看到:Gremlin中文文档
阿里云GDB图数据库,是在gremlin语言框架下的实现 - 有兴趣的可以看第二部分,Cypher和Gremlin比较
来源于:图数据库排名、对比
Neo4J企业与社区版本对比
| 特性 | 企业版 | 社区版 |
|---|---|---|
| 数据库集群 | 支持 | 无支持 |
| 数据库热备份 | 支持 | 手工备份,运行时需要停止服务 |
| 在线存储空间再使用 | 回收并再使用数据删除释放的空间 | 无支持 |
| LDAP/AD继承 | 与企业级用户身份认证和访问控制系统集成 | 无支持 |
| 访问控制 | 为数据库管理员提供指定的用户角色功能 | 无支持 |
| 数据库监控 | 提供监控数据库运行状况的整套指标 | 无支持 |
| JMX日志和监控 | 包含GraphiteJMX客户端 | 无支持 |
| 更全面的日志 | 包括http,security日志 | 无支持 |
| 节点、关系、属性限制 | 无限制 | 节点344亿,关系344亿 |
| 节点键 | 使用一个或者多个属性来表示唯一的节点(类似主键) | 无支持 |
| 运营管理工具 | 管理员命令行界面 | 无支持 |
| 写入锁、执行过程优化、硬件支持 | 支持超过4核心 | 最多4核心 |
从这个表来看,neo4j的社区版其实功能个还是挺少的,和同为开源版的mysql对比的话。
最后,还有一个大表,来源于:图数据库选型:Neo4j、Janus、HugeGraph
这里还是注意到 图查询语言的不同
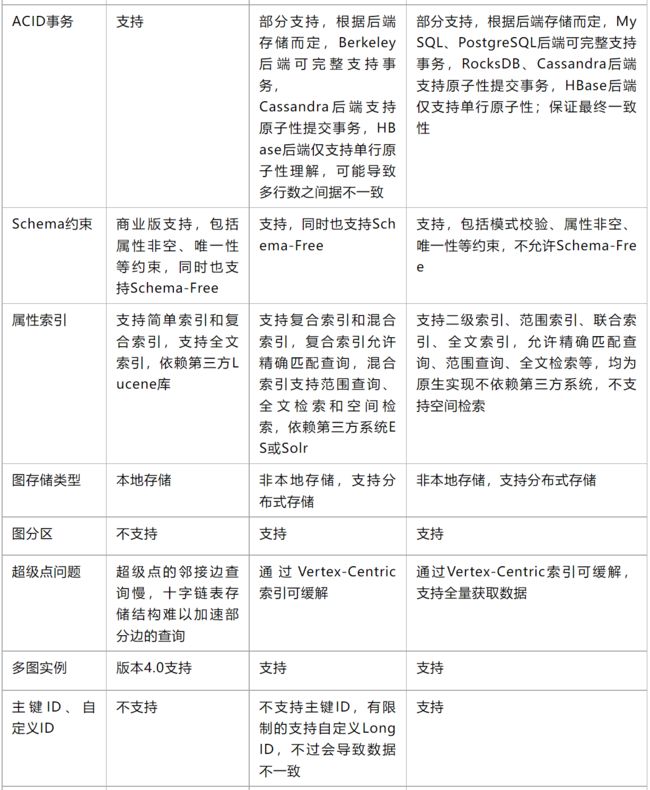
这里看到了可能会有些问题的东西,主要是看neo4j为主:
- schema约束。社区版没有schema约束,感觉有点坑的样子
- 属性索引,lucene是solr和es使用的基础,可能索引功能比较简单吧
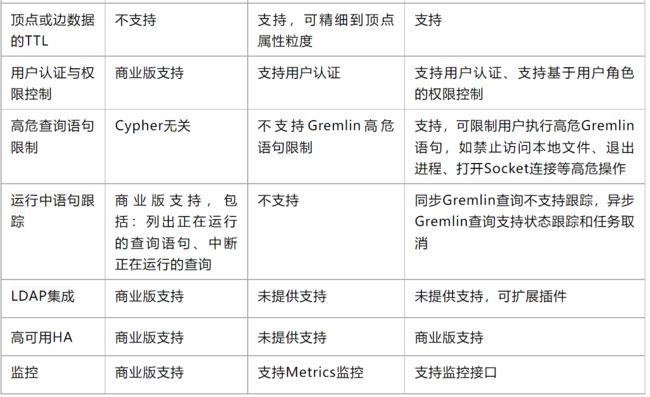
这里有一点,neo4j社区版本没有用户认证和权限控制。。。有点诡异。
3. Cypher和Gremlin比较
这里需要提前说明一些概念,然后才可以介绍这cypher,gremlin以及网上尝尝一起比较的SPARQL三者的区别。
学过数据结构的应该都知道,对于不同的数据存储/描述方式,会采用不同的算法进行排序。
所以这里想要知道知识图谱查询语言,先要了解知识图谱的存储/表示方式
以下内容摘自:
- 王昊奋老师书籍:知识图谱:方法、实践与应用
- 知乎:【知识图谱】知识图谱(一)—— 综述
- 知乎:知识图谱 | 存储与可视化篇
3.1 知识图谱数据模型
从数据模型角度来看,知识图谱本质上是一种图数据。不同领域的知识图谱均需遵循相应的数据模型。知识图谱数据模型的数学基础是图论
其实知识图谱常见的表示方法/数据模型, 主要是RDF和属性图。在知识图谱数据模型上,需要借助特定的查询语言进行查询操作。
- 在RDF图上的查询语言是SPARQL语言
- 属性图上的查询语言使用的是Cypher和Gremlin
知识图谱领域形成了
- 负责存储RDF图(RDF graph)数据的
三元组库(Triple Store) - 管理属性图(Property Graph)的
图数据库(Graph Database)
RDF图
RDF是W3C制定的在语义万维网上表示和交换机器都可理解信息的标准数据模型。
在 RDF 三元组集合中,每个 Web 资源具有一个 HTTP URI 作为其唯一的 id;
一个 RDF图定义为三元组(s, p, o)的有限集合;
每个三元组代表一个陈述句,其中s是主语,p是谓语,o是宾语;
(s, p, o)表示资源s与资源o之间具有联系p,或表示资源s具有属性p且其 取值为o。
实际上,RDF三元组集合即为图中的有向边集合。
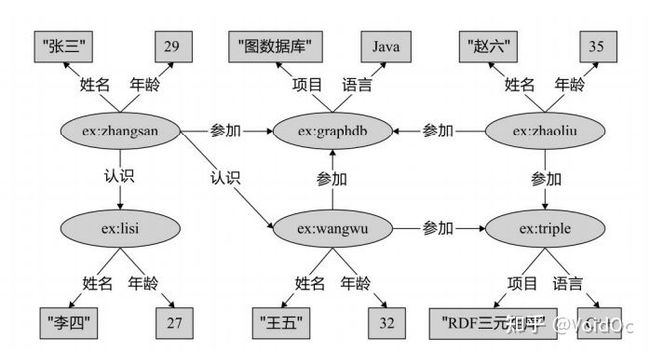
- RDF三元组集合即为RDF图中的有向边集合
- RDF图对于节点和边上的属性没有内置的支持
- 节点属性可以用三元组表示,即上图中的矩形
属性图
属性图可以说是目前被图数据库业界采纳最广的一种图数据模型。属性图由节点集和边集组成,且满足如下性质:
- 每个节点具有唯一的id;
- 每个节点具有若干条出边;
- 每个节点具有若干条入边;
- 每个节点具有一组属性,每个属性是一个键值对;
- 每条边具有唯一的id;
- 每条边具有一个头节点;
- 每条边具有一个尾节点;
- 每条边具有一个标签,表示联系;
- 每条边具有一组属性,每个属性是一个键值对。
属性图如下所示: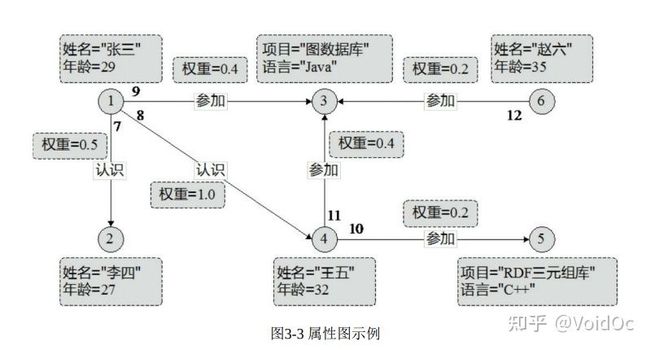
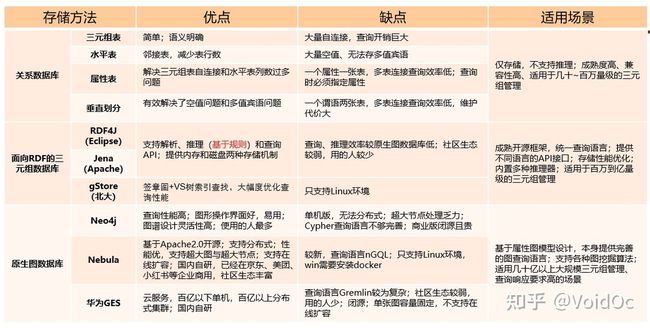
根据不同的数据模型,有以下存储知识图谱的图数据库
- 面向 RDF 的三元组数据库:主要的 RDF 三元组库包括:商用的 Virtuoso、AllegroGraph、GraphDB和BlazeGraph,开源系统Jena、RDF4J、 RDF-3X和gStore。
以三元组进行存储的,jena是比较常见的 - 原生图数据库:主要包括开源的Neo4j、Nebula(国内自研)、JanusGraph和商用的OrientDB等。
Neo4j最常听说,Nebula是国内自研的!
以下内容摘自:
- 知乎:知识图谱 | 存储与可视化篇
3.2 知识图谱查询语言
- RDF图上的查询语言是SPARQL
- 属性图上的查询语言常用的有Cypher和Gremlin
- 知识图谱查询语言可分为声明式Declarative和导航式Navigational两类。
SPARQL
是W3C制定的RDF图数据的标准查询语言。从语法上借鉴了SQL,属于声明式语言。Jena就属于RDF三元组图数据库,使用的就是SPARQL。
例如下面的查询:
查询张三认识的其他程序员
PREFIX ex:! 输出 ex:lisi ex:wangwu
Cypher
- 最初是图数据库Neo4j中实现的属性图数据查询语言。与SPARQL一样,Cypher也是一种声明式语言。
声明式语言:
- 即用户只需要声明"查什么",而无需关心"怎么查",就好像打车只用跟师傅说去哪,怎么走就是司机的任务,你不用管关心。
- 这类语言的优点是:便于用户学习掌握,同时给予数据库进行查询优化的空间。
- 缺点是不能满足高级用户导航查询的要求,数据库规划的查询执行计划有可能不是最优方案
使用示例:
! 查询图中所有程序员节点
MATCH {p:程序员}
RETURN p
! 输出 {姓名=张三,年龄=29} {姓名=李四,年龄=27} {姓名=王五,年龄=32} {姓名=赵六,年龄=35}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Gremlin
- 是
Apache TinkerPop图计算框架提供的属性图查询语言。 - Apache TinkerPop被设计为访问图数据库的通用API接口,其作用类似于关系数据库上的JDBC接口
- Gremlin的定位是图遍历语言,其执行机制就好比是一个人置身于图中沿着有向边,从一个节点到另一个节点进行导航式游走。这种执行方式决定了用户使用Gremlin需要指明具体的导航步骤,类似于自驾,需要知道明确的路线,所以Gremlin是一种过程式语言,需要明确
怎么做 - 这类语言的优点是,可以时刻知道自己在图中所处的位置,以及是如何到达该位置的
- 缺点是,用户需要
认识路
以下是代码示例(参考图查询语言——Gremlin):
g.V().has('code','AUS').out().value('name','age').order().by('age',desc)
- 1
第一步:g.V() 标明是对图库中的所有节点进行操作的
第二步:has(‘code’,‘AUS’) 获取包含属性code并且该属性的值为AUS的所有节点
第三步:out() 获取上个结果集中所有节点的出边对应的节点
第四步:value(‘name’,‘age’) 获取上个结果集中所有节点的name和age属性值
第五步:order().by(‘age’,desc) 对结果集根据age进行降序排序
- 图数据库查询语言Cypher、Gremlin和SPARQL
- 图数据库入门教程-深入学习Gremlin(1):图基本概念与操作
- Neo4j - Cypher vs Gremlin query language
- 一文了解各大图数据库查询语言(Gremlin vs Cypher vs nGQL)| 操作入门篇
4. 其他考虑
根据:【持续更新】知识图谱相关工具平台整理
尚未找到国内企业基于Neo4j构建和使用比较大型知识图谱的案例→这东西有一定的缺陷和不足,所以还是再继续调研调研。
一些评测文章:
- 主流开源分布式图数据库Benchmark
- 图数据库对比
- 图数据库对比:Neo4j vs Nebula Graph vs HugeGraph
- Nebula 与 Neo4j、ArangoDB 等图数据库的 Benchmark
- 知乎:【知识图谱】知识图谱(一)—— 综述

调研一下,看了一下目前国内一些知识图谱公司都是用哪个图数据库
4.1 美团知识图谱——Nebula Graph
- 美团技术团队:美团图数据库平台建设及业务实践
- 百家号: 美团图数据库平台建设及业务实践
- csdn: 美团图数据库平台建设及业务实践
- b站视频回放:nLive vol.001|美团图数据库平台建设及业务实践_哔哩哔哩_bilibili
- github地址(6.8k star):https://github.com/vesoft-inc/nebula
- 有中文md
nebula graph排名有,虽然不是很高
4.2 腾讯TEG-AI平台部——JanusGraph
参考:万字详解:腾讯如何自研大规模知识图谱 Topbase
- Topbase 知识图谱的存储是基于分布式图数据库 JanusGraph,选择 JanusGraph 的主要理由有:1)JanusGraph 完全开源,像 Neo4j 并非完全开源;2)JanusGraph 支持超大图,图规模可以根据集群大小调整;3)JanusGraph 支持超大规模并发事务和可操作图运算,能够毫秒级的响应在海量图数据上的复杂的遍历查询操作等。
Graph_Loader 模块主要是将上述数据生产流程得到的图谱数据转换为 JanusGraph 存储要求的格式,批量的将图谱数据写入图数据库存储服务中,以及相关索引建立。- 图数据库
存储服务:JanusGraph数据存储服务可以选用 ScyllaDb、HBase 等作为底层存储,topbase 选用的是 ScyllaDb。Graph_loader 会每天定时的将数据更新到图数据库存储服务。 - 图数据库
索引:由于 JanusGraph 图数据库存储服务只支持一些简单查询,如:“刘德华的歌曲”,但是无法支持复杂查询,如多条件查询:“刘德华的 1999 年发表的粤语歌曲”。所以我们利用 Es 构建复杂查询的数据索引,graph_loader 除了批量写入数据到底层存储之外,还会建立基于复杂查询的索引。 - 图数据库
主服务:主服务通过 Gremlin 语句对图数据库的相关内容进行查询或者改写等操作
JanusGraph排名第7,还是可以的。
4.3 阿里知识图谱数据库——自研
自研的,没有一个个性化的名称,就是GDB,图数据库。。什么是图数据库GDB? - 图数据库 GDB - 阿里云
4.4 字节跳动知识图谱数据库——自研
- 自研的,叫ByteGraph,字节跳动自研万亿级图数据库 & 图计算实践_ 字节跳动技术团队的博客-CSDN博客
- 从解决一个最核心的抖音社交关系问题入手,逐渐演变为支持有向属性图数据模型、支持写入原子性、部分 Gremlin 图查询语言的通用图数据库系统,在公司所有产品体系落地,称之为 ByteGraph。
- 里面有一句话,有点讽刺。。
Tencent Plato 是基于 Gemini 思想的开源图计算系统,采用了 Gemini 的核心设计思路,但相比 Gemini 的开源版本有更加完善的工程实现,我们基于此,做了大量重构和二次开发,将其应用到生成环境中,这里分享下我们的实践。
4.5 明略科技——自研
图数据库NEST
明略科技HAO图谱:从数据到知识的应用实践
其他——ArangoDB
参考: Nebula 与 Neo4j、ArangoDB 等图数据库的 Benchmark
- 在上述比较中,出现了ArangoDB,且性能非常好。
- 此外,其在DB Engines中排名第三。
- ArangoDB 是一个开源的多模态数据库,可用来存储文档,图等类型的数据。支持集群,具有良好的读写性能。
- github地址(star:11.8k):https://github.com/arangodb/arangodb
- 最早的提交tag是2011年10月27日:https://github.com/arangodb/arangodb/releases/tag/v0.0.1
- 但是似乎没什么人用,据说是bug比较多,有内存泄漏,并发性不好。
参考博客
https://www.zhihu.com/question/310467190/answer/2319629705
https://blog.csdn.net/Castlehe/article/details/121602870