让一个模型处理多种数据的N种方法
微信公众号“ 圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~ 后台回复“ 交流”加入“ 圆圆的算法笔记”交流群;回复“ 时间序列“、”多模态“、”迁移学习“、”NLP“、”图学习“、”表示学习“、”元学习“等获取各个领域干货算法笔记~ 后台留言”交流“,加入圆圆算法交流群~ 后台留言”论文“,获取各个方向顶会论文汇总~
在一些场景我们希望模型能够兼容多种分布不同的数据,例如希望一个模型用在多种不同的场景上,或者希望模型在头部数据和长尾数据上都表现好,或者希望一个模型同时预测多个任务。都有哪些方法能够让一个模型处理多种数据呢?一种最简单的办法是,不同类型的数据增加一个单独的标识ID作为特征,输入到模型中,以此达到区分不同数据的目的。然而,这种方法可能由于某些原因无法达成预定目标,例如特征对最终预测结果影响较小、数据量差异大导致头部样本主导模型参数等情况。另一种直观的方法是不同类型的数据分别训练一个模型,这种方法的问题在于无法充分挖掘不同类型数据之间可以贡献的信息,往往无法达到最优解。
为了实现一个模型处理多种不同分布数据的能力,业内提出了很多先进的解决方法。我整理了三种类型的方法,分别是多专家网络、生成个性化参数和Meta-learning,它们都可以实现针对不同数据进行参数空间分离的作用。下面对这三类方法的几个典型工作进行介绍。
1. 多专家网络
多专家网络的核心思路是,在模型中引入多个独立、冗余的网络,并引入一个可以根据样本信息生成各个冗余网络输出结果融合权重的子网络,实现参数空间的分离。通过这种方式,直接的扩大了参数空间,并能根据每种类型数据的特点,选择最适合它的子空间。
2017年Google第一次提出了MoE模型结构:OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER(2017)。模型包括一个门控网络,输入样本特征,输出对每个Expert的选择得分,并将原来每层所有样本共享的参数,变成多组参数,每组参数被称为一个Expert。
在此基础上,Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts(KDD 2018)提出了用多专家网络(MMoE)解决多任务学习问题。网络由多个多任务共享的Expert,以及每个任务独有的Gate网络构成。每一个任务k的具体输出结果表示如下(fi表示第i个专家,gk表示第k个任务的门网络):


通过这种方式,每个Task的门网络可以基于样本信息学习如何选择一组专家进行预测。通过这种方式,实现了对于不同任务或不同数据的参数空间分割,从而让模型兼容不同类型的任务和数据。

此后,有很多针对MMoE的模型优化工作。Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations(Recsys 2020)提出了PLE方法,将模型参数显示的划分为私有部分和公共部分,提升多任务学习的鲁棒性,缓解私有知识和公共知识之间的负向影响。PLE和MMoE的主要区别在于,将多专家分成公共部分和每个Task独有的部分。同时,论文中指出在网络最初阶段并不能真正确定哪些Expert需要公用哪些Expert独有。因此论文提出了多层次的信息提取方法,在网络的最底层增加多个Extraction Layer全局Gate,用来给所有Expert打分,在上层再区分公共和独有部分。其实可以理解底层先通过MoE不区分公共/私有部分提取基础特征,在上层再逐渐将公共/私有部分区分开。

MoE模型结构也被广泛应用于高效进行模型容量扩充,Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity(2021)中就利用MoE结构扩展Transformer模型容量,并设计了多种MoE调优方法。
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems(2021)将多专家网络应用到了解决冷启动问题上。长尾用户的行为分布和正常用户不一样。简单的加标记特征(比如加一个特征标记是否是冷启动user),由于数据不平衡,模型不会侧重学习标记特征,因此加入标记特征对于最终效果影响不大。因此本文采用了MoE的思路,用user特征生成一个gate,控制每层的输出,实现一种不同user的参数空间分割功能。
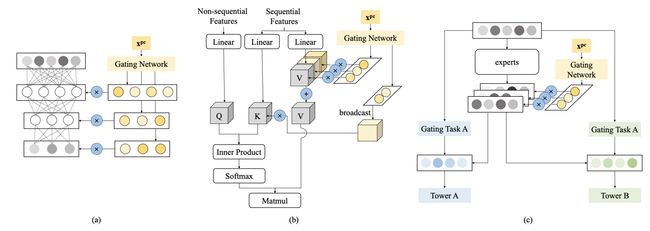
Multi-Faceted Hierarchical Multi-Task Learning for a Large Number of Tasks with Multi-dimensional Relations(2021)将用户分为新用户、低活用户、高活用户三种类型,直接将每种类型数据视作一个单独的任务,通过MoE实现不同任务的参数空间划分。

2. 生成个性化参数
另一种思路是针对不同的场景、用户等条件,生成不同的个性化参数。这种方法一般利用输入数据的某些特征,直接生成个性化的模型参数,或者生成一个影响模型参数的中间参数,进而让每种类型的数据得到自适应的参数空间。
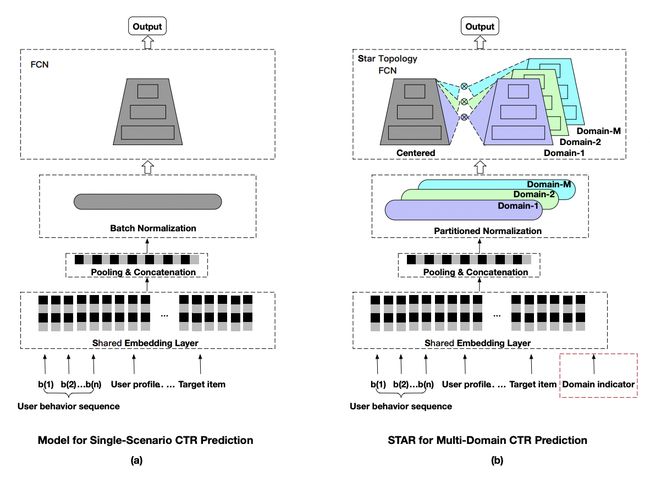
One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction(2021)解决一个模型服务多个场景数据的问题。本文的方法是,所有场景共享一个相同的中心全连接模型,同时每个场景也有一套各自独立的全连接参数,使用共享模型参数和场景个性化参数融合,作为各个场景最终的模型参数。通过这种方法,既能实现不同场景之间的信息共享,又能保持每个场景一定的独立性,,让模型能够同时处理不同场景的数据。此外,为了突出不同场景的差异,文中引入了一个辅助网络,将不同场景的id特征通过一个2层全连接直接生成一个logit,直接和主模型logit相加影响最终预测结果。
APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction(2022)核心思路是输入场景的特征,经过一个函数后,生成一套模型参数用于当前样本。文中提出了group-wise、mix-wise、self-wise三种方法作为生成参数的输入:
- Group-wise:根据user对样本分组,每个user生成一组模型参数;
- Mix-wise在user信息的基础上,引入user最近一次的历史行为,以此客户用户在不同场景下不同的意图;
- Self-wise:直接根据当前样本的输入生成模型参数。
上述三种方法中,都是将不同的外部信息输入到一个模型参数生成器,产出模型参数。对于模型参数的生成函数,文中采用了简单的全连接进行生成。这种方法直接根据样本场景特征生成一套个性化的模型参数。

3. Meta-learning
更极端的方法是每个类型的数据直接fiinetune一个子模型,meta-learning是这类方法的代表工作。首先利用全量数据结合meta-learning的方法训练一个全局初始化参数,然后在每种类型的数据上分别finetune,得到各个场景独立的参数。例如MeLU: meta-learned user preference estimator for cold-start recommendation(KDD 2019)一文中,将每个用户视为一个独立的任务,使用meta-learning+finetune的方式,为每个用户生成一个单独的模型。

需要指出得到是,这种方法在实际上线应用可能比较困难,需要上线的模型数量和场景数量相同。如果以用户为场景,上亿的用户数量就要对应上亿个模型,上线的复杂度和运行效率都是一个不小的挑战。
4. 3类方法的对比和总结
上面我们介绍了让一个模型用于多种类型数据的3种方法。这3种方法的相同点是既利用了不同数据之间的共性,又能实现不同数据一定程度上的参数空间区隔。
在多专家网络中,所有数据共享一个网络,一种类型的数据由多个网络的结果进行融合。每个冗余的子网络都在所有数据上进行了学习,只是各自侧重的信息不同。
正在个性化参数生成方法中,模型根据输入样本动态生成参数,实现了参数差异,但是整体网络仍然是在所有数据上联合训练的。
在Meta-learning方法中,模型首先在所有数据上联合训练得到基础模型,再在此基础上进行finetune得到各类数据的子模型。基于Meta-learning的预训练阶段实现了不同类型数据的共享,而个性化的finetune实现了参数空间的区隔。
微信公众号“ 圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~ 后台回复“ 交流”加入“ 圆圆的算法笔记”交流群;回复“ 时间序列“、”多模态“、”迁移学习“、”NLP“、”图学习“、”表示学习“、”元学习“等获取各个领域干货算法笔记~ 后台留言”交流“,加入圆圆算法交流群~ 后台留言”论文“,获取各个方向顶会论文汇总~
【历史干货算法笔记】
12篇顶会论文,深度学习时间序列预测经典方案汇总
如何搭建适合时间序列预测的Transformer模型?
Spatial-Temporal时间序列预测建模方法汇总
最新NLP Prompt代表工作梳理!ACL 2022 Prompt方向论文解析
图表示学习经典工作梳理——基础篇
一网打尽:14种预训练语言模型大汇总
Vision-Language多模态建模方法脉络梳理
花式Finetune方法大汇总
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程