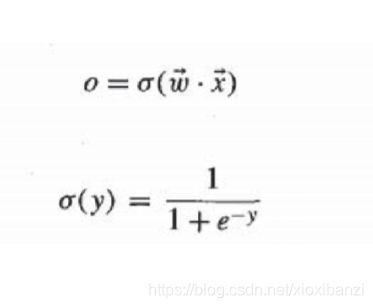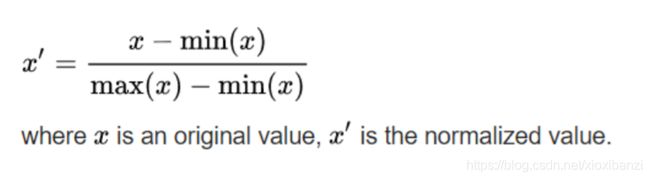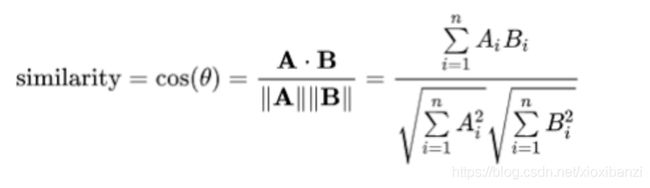使用K-NN,多类感知器和SVM等分类器进行手写数字识别的比较研究
手写数字是日常生活中的常见部分。如今,机器学习方法正在以超过人类准确性的精度对手写数字进行分类。这些方法用于制造光学字符识别器(OCR),其中包括从纸张读取文本并将图像转换为计算机可以操纵的形式(例如,转换为ASCII码)。这项技术解决了许多问题,例如自动识别以下内容:
- 邮政编码:邮政编码由一些数字组成,是字母中最重要的部分之一,可将其传递到正确的位置。许多年前,邮递员会手动读取邮政编码以进行邮递。但是,现在通过使用光学字符识别(OCR)可以使这类工作自动化。
- 银行支票:OCR的最常用用法是处理支票:扫描手写支票,将其内容转换为数字文本,验证签名并实时清除支票,而无需人工干预。
- 法律记录:誓章,判决书,文件,声明,遗嘱和其他法律文件(尤其是印刷的文件)的数量可以用最简单的OCR读者进行数字化,存储,数据库化和搜索。
4-医疗记录:在可搜索的数字商店中存储完整的病历,意味着过去的疾病和治疗方法,诊断检查,医院记录,保险付款等可以在一个统一的位置提供,而不必费力报告和X射线文件。 可用于扫描这些文档并创建数字数据库。
1.问题陈述:
当前的任务是使用监督机器学习对手写数字进行分类方法。 这些数字属于0 – 9类。“给出图像形式的查询实例(一个数字),我的机器学习模型必须正确地对其适当的类别进行分类。”:汤姆·米切尔(Tom Mitchell)的机器学习形式化理论可用于配制我的机器学习问题。 它说:据说一个计算机程序可以从经验E中学习关于任务T和绩效指标P,如果其在任务T的绩效(由P衡量),随着经验E的提高。因此,我的手写数字识别问题可以表述为:
•T –对图像中的手写数字进行分类。
•P –正确分类的数字的百分比。
•E –具有给定标签的手写数字数据集。
2.所采用数据集
MNIST手写数字数据集用于此任务。 它包含拍摄的数字图像从各种尺寸和居中标准化的扫描文档中提取。这使其成为用于评估模型的优秀数据集,使开发人员可以专注于机器只需很少的数据清理或准备工作即可学习。每个图像都是28 x 28像素的正方形(总计784像素)。 数据集包含60,000用于模型训练的图像和用于模型评估的10,000张图像。

图表 1-来自MNIST数据集的样本图像
3.机器学习训练方法
使用监督机器学习模型来预测数字。 由于这是一项比较研究,因此我将首先描述K最近邻分类器作为基准方法,然后将其与多类感知器分类器和SVM分类器进行比较。 K最近邻分类器–所采用的基准方法:k最近邻(k-NN)是一种算法,该算法:•在训练集中找到一组最接近测试对象的k个对象,并且•为 在这个邻里的班级优势上的标签。 此方法包含三个关键元素:•一组带标签的对象,例如一组存储的记录(训练数据)•用于计算对象之间距离的距离或相似性度量•和k的值(最近邻居的数量) )

图表 2-直观表示如何使用K-NN对测试实例进行分类
要对未标记的图像进行分类:
•计算出此图像与标记对象的距离(训练数据)
•确定其k最近邻,并按照以下顺序降序排列计算相似度
•然后将前k个邻居中最频繁出现的最近邻居分配为对象的类标签

图表 3-KNN算法步骤
当我使用K-NN方法时,观察到以下优点和缺点:
优点:
•对于小型训练数据集,K-NN快速执行。
•没有关于数据的假设-例如对于非线性数据有用
•简单的算法-可以解释和理解/解释
•通用-对分类或回归有用
•训练阶段非常快,因为它不会学习任何数据缺点
缺点:
•昂贵,因为该算法将测试数据与训练数据中的所有示例进行比较,然后最终确定标签
•K的值未知,可以使用交叉验证技术进行预测
•内存需求量大-因为所有训练数据都已存储
•预测阶段 如果训练数据很大,可能会很慢

图表 4-我的代码的K-NN实现

图表 5-查询实例被馈送到Multiclass Perceptron分类器中的所有分类器
可以使用经过1对全部策略训练的多个二进制分类器来制作多类感知器分类器。 在这种策略中,在训练感知器的同时,训练标签应使得例如 对于分类器2与全部,对于Sigmoid单位,带有2的标签将被标记为1,其余部分将被标记为0,而对于Rosenblatt的感知器,对于正例和负例,标签分别为1和-1。现在,要做的就是分别训练(学习权重)10个分类器,然后将查询实例提供给所有这些分类器(如上图所示)。 然后,具有最高置信度的分类器标签将分配给查询实例。
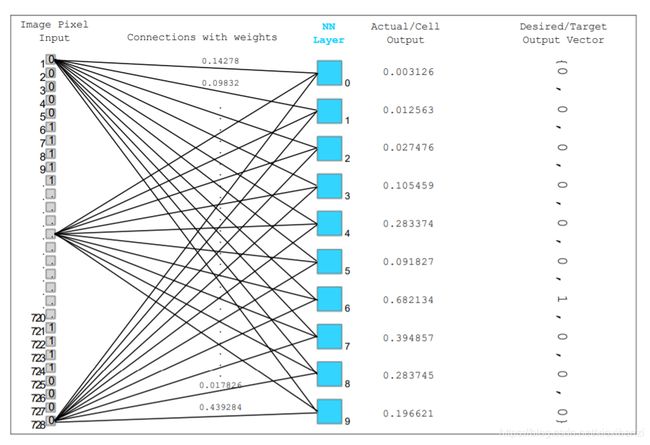
图表 6-将查询实例馈送到1层多感知器分类器,并将具有最高置信度的分类器标签分配给测试实例,在这种情况下,分类器“ 6”具有最高置信度,因此将其分配给测试查询。
查询实例被馈送到1层多感知器分类器,分类器的标签带有最高可信度分配给测试实例,在这种情况下,分类器“ 6”具有最高可信度,因此其分配给测试查询。
4.训练算法:
每个感知器的训练算法如下:
1.将权重和阈值初始化为较小的随机数(在此的示例中为零)。
2.将向量x呈现给神经元输入并计算输出。
3.根据以下条件更新权重:

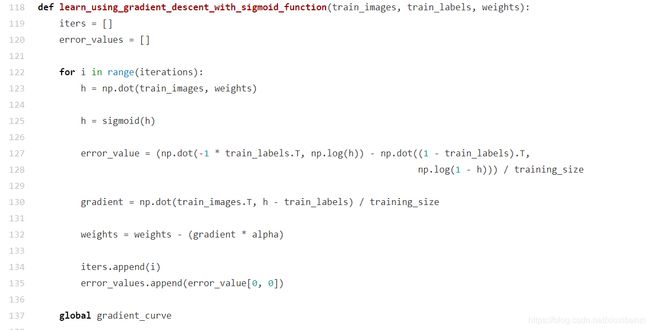
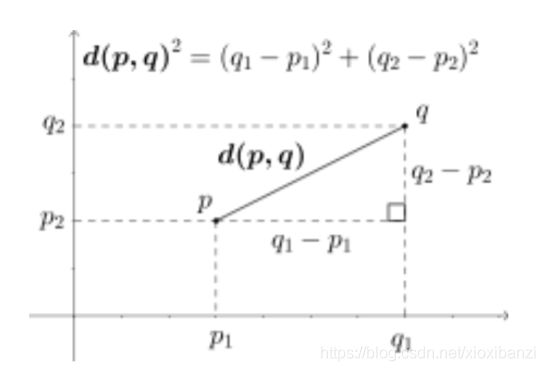
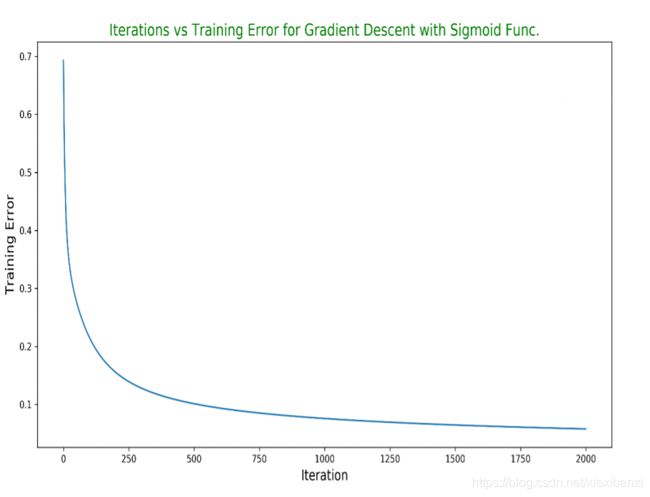
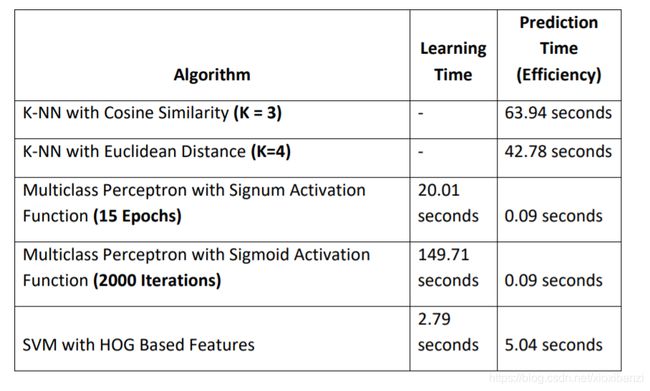
d是所需的输出,在感知器的情况下使用信号函数规则和sigmoid函数
t是迭代数
eta是学习率或步长,其中0.0 4.重复步骤2和3,直到:迭代误差小于用户指定的误差阈值或预定的迭代次数已完成 激活功能: 将激活函数应用于感知器的输出,以确定是否触发该神经元。 根据使用的激活函数,有两种类型的感知器: •具有信号激活功能的感知器规则 •具有S形激活功能的Delta规则 1)具有Signum激活功能的感知器规则:(Rosenblatt的感知器 在此规则中的假设函数如下: 下面给出的是Rosenblatt感知器的视觉表示: 这是我对单个感知器的训练代码: 图表 7-我的代码段,用于使用一些预定义的时期来训练Rosenblatt的感知器随机梯度下降,可最大程度地降低成本函数并提升权重 2)具有S型激活功能的Delta规则:在此规则中的假设函数如下: 以下是具有Sigmoid激活功能的感知器的直观表示: Perceptron规则和Delta规则之间的区别:感知器规则和增量规则之间有两个区别: •感知器规则基于阶跃函数(信号函数),而增量规则使用S型激活函数。 •假设以下条件,感知器可以收敛到一致的假设数据是线性可分离的(如果不是这样,则定义要训练的时期)。另一方面,Delta规则的收敛不取决于条件线性可分离数据。 5.多类感知器如何减轻K-NN的局限性: 正如之前讨论过的那样,K-NN会存储所有训练数据,并在有新查询时实例来它比较其相似性与所有训练数据,这使得它在计算和内存方面都很昂贵。 没有学习,因为这样。 另一方面,多类感知器在学习阶段需要花费一些时间,但训练完成后,它将学习可以保存然后使用的新砝码。现在,当一个查询实例到来时,只需要加点该实例的乘积有了学习的权重,就会有输出(应用激活后功能)。 •与K-NN相比,预测阶段非常快。 •此外,在计算方面(预测阶段),它的效率要高得多和内存(因为现在只需要存储权重即可,而不是所有培训数据)。 6.SVM分类器: 仅出于比较目的,我还使用了第三种监督机器学习名为支持向量机分类器的技术。该模型尚未实现。 它直接从scikit的python学习模块导入和使用。 7.实验设定 功能缩放: 特征缩放是一种用于标准化自变量范围或数据特征。在数据处理中,也称为数据规范化,它是通常在数据预处理步骤中执行。由于原始数据值的范围差异很大,因此在某些机器中学习算法时,如果没有规范化,目标函数将无法正常工作。例如,大多数分类器通过以下方式计算两点之间的距离欧几里得距离。如果其中一个要素的取值范围很广,则距离将受此特定功能的约束。 因此,所有功能的范围应为标准化,以便每个特征对最终特征的贡献大致成比例距离。 重新缩放: 最简单的方法是重新调整要素范围以将范围调整为[0,1]或[−1,1]。 选择目标范围取决于数据的性质。 通用公式为给出为: 我的MNIST数据集首先被重新缩放。 由于每个像素的最小值为0且最大值值是255。因此,每个输入向量都被255除以重新缩放。 K-NN的实验设置: K-NN实验进行了两次。 一次使用余弦相似性度量,一次欧氏距离作为相似性度量。 资料分割: 在针对训练和测试数据的不同分割运行算法之后,以下内容选择split是因为它可以达到更好的结果: 使用的训练数据:3000个数据点 使用的测试数据:1000个数据点 使用的验证数据:1000个数据点 相似性度量(距离度量): 对于K-NN,有两点要考虑。一种是与被使用,最重要的一个是K的值。我选择了两种相似性衡量指标,并且每次均进行了一次实验。 1-余弦相似度: 两个向量之间的余弦相似性是一种度量的余弦相似度他们之间的角度。 此度量标准是方向而非大小的度量。 根据两个向量之间的角度余弦,得出两个向量的相似性 2-欧几里得距离: 欧几里得距离是欧几里得中两个向量之间的直线距离空间。 它通过考虑两个向量彼此之间的距离来告诉它们大小。 两点之间的欧几里得距离p和q。 K的最佳值:(使用弯头法) 为了找到K的最佳值,将训练数据分为两部分。 •第一部分是KNN的新训练数据(3000张图像) •第二部分是验证数据(1000张图像),其验证误差曲线将被计算。现在,为了找到验证误差最小的K值,对从1到sqrt(N)的K的不同值,其中N是新训练的大小数据。 –对k = 1到sqrt(N)运行K-NN,并为每个k计算精度。以前计算过所有邻居一次,所以现在只更改k。 验证误差曲线: 使用弯头法找到K的最佳值。由于实验进行了两次,因此必须为KNN找到K的最佳值具有余弦相似度,而KNN具有欧氏距离。K的最佳值是验证误差最小的那个。 对于K = 3,验证误差是最小的,因此对于带有余弦的K-NN选择此k相似 –对于K = 4,验证误差为最小,因此对于具有欧几里得的K-NN选择此k距离 8.多类感知器的实验设置: 多类感知器实验进行了两次。一次与Perceptron一起信号激活功能,以及带有Sigmoid激活功能的感知器。 偏压: 为了使模型适合训练数据,还添加了偏差w0模型决策边界穿过原点的限制。为了使权重和输入要素的点积一致,功能以x0的形式添加到输入向量,其值设置为1。 资料分割: 在针对训练和测试数据的不同分割运行算法之后,以下内容选择split是因为它可以达到更好的结果: 使用的训练数据:5000个数据点 使用的测试数据:10,000个数据点 学习率: 学习率不应太小,以免收敛太慢也不要太大,以至于梯度永远不会收敛,并且会不断地来回跳动。用不同的eta(学习率)值运行实验后,选择0.01。 成本函数: •sigmoid单元: 对于S形单位,由于使用S形时,不能使用均方成本函数激活功能已插入其中,它不会保持凸状。为了有凸梯度下降将导致全局最小值的成本函数,使用以下对数成本函数: m =训练量 h(x)=预测标签 y =原始标签 •门槛单位(罗森布拉特的感知器) Perceptron成本函数为 Epochs: 一个Epochs基本上是对所有训练数据的完整一轮。 •sigmoid单元: 使用梯度下降的批处理模式对Sigmoid单元进行训练。为此模式选择的迭代次数/时期数为2000。并且绘制了一个图,用于一个感知器针对不同迭代及其各自成本的训练。显然,当迭代次数达到1500时,梯度会收敛,此后成本降低较少。 图表 8-使用Sigmoid激活函数的梯度下降(批处理模式)的多类分类器的一个感知器的迭代与训练误差曲线 •门槛单元(罗森布拉特的感知器) 阈值单元是使用随机梯度下降训练的,该方法不是在一个完整的历元之后更新权重,而是为每个训练实例更新权重,这使该方法收敛速度比梯度下降快,且成本明智。最初,此感知器用于不断更新权重,直到所有训练示例正确分类为止。 为此,训练数据应该是线性可分离的。但是在这次的情况下,数据不是线性可分离的,因此为了避免无限循环,将感知器序列用于某些预定义的时期。 为了为这次的场景选择最佳时期,针对不同时期进行了实验,并绘制了一条曲线,如下所示。 图表 9-随着epoch的增加和融合,培训成本通常会降低。这是使用带有信号函数的随机梯度下降的多类感知器分类器的一个感知器的图 仅出于实验目的,将epoch设定为2000,然后再次绘制成本曲线。 现在很明显,成本在10到30个epoch之间收敛,此后成本几乎没有变化。 训练cost集中在10到30 ep之间。因此,根据上述实验,决定选择15个ep来训练罗森布拉特的感知器。 9.SVM分类器的实验设置: 在K-NN和Multiclass Perceptron分类器中,直接在原始图像上训练此模型,而不是从输入图像中计算一些特征,并在那些计算出的度量/特征上训练模型。特征描述符是图像的表示,通过提取有用的信息并丢弃无关的信息来简化图像。 HOG描述符: 现在,将从数字图像中计算定向梯度直方图作为特征,并在此基础上训练SVM分类器。HOG描述符技术对图像检测窗口的局部部分中梯度取向的出现进行计数。 计算方式: 为所有训练示例计算HOG特征向量,然后在这些特征上训练模型。 同样,在测试测试图像时,将计算测试图像的HOG特征,并根据这些特征而不是原始测试图像评估模型。要计算HOG功能,设置: •每个块中的像元数等于每个单个像元的大小为14×14。 由于图像大小为28×28,因此将拥有四个大小为14×14的块/单元。 •另外,将方向向量的大小设置为9。因此,每个样本的HOG特征向量的大小将为4×9 = 36。 10.结果分析 每种算法使用的精度度量为:精度=正确分类的图像/总图像* 100。现在是最后阶段,用不同的算法运行实验后,总结结果。首先比较基于精度的技术: 准确性(性能): 当根据准确性将K-NN方法与Multiclass Perceptron和SVM进行比较时,其准确性与其他两个分类器相似,这意味着尽管其简单性,K-NN确实是一个很好的分类器。 预测时间(效率): 我的观察:K-NN的主要限制之一是它的计算量很大。 它的预测时间很大,因为每当一个新的查询实例到来时,它就必须将其相似性与所有训练数据进行比较,然后根据其置信度对邻居进行排序,然后分离出前k个邻居,并选择顶部出现次数最多的邻居的标签k。 在所有这些过程中,需要花费相当多的时间。 尽管对于多类感知器分类器,观察到它将减轻效率方面的限制,从而使其预测时间较短,因为现在它仅在预测阶段计算点积。 在学习阶段,大部分时间仅花费一次。 然后就可以预测测试实例了。 结果: 我的结论: 在为K-NN,Multiclass Perceptron和SVM的预测阶段计算时间时,Multiclass Perceptron显然以最短的预测时间脱颖而出,而另一方面,K-NN在预测测试实例上花费了大量时间。因此,就预测时间的效率以及计算和内存负载而言,多类感知器显然将K-NN甩在了后面。