目标检测扩(六)一篇文章彻底搞懂目标检测算法中的评估指标计算方法(IoU(交并比)、Precision(精确度)、Recall(召回率)、AP(平均正确率)、mAP(平均类别AP) )
基本在目标检测算法中会碰到一些评估指标、常见的指标参数有:IoU(交并比)、Precision(精确度)、Recall(召回率)、AP(平均正确率)、mAP(平均类别AP)等。这些评估指标是在评估阶段评价训练的网络好坏的重要依据。

1、IOU(交并比)
计算方法
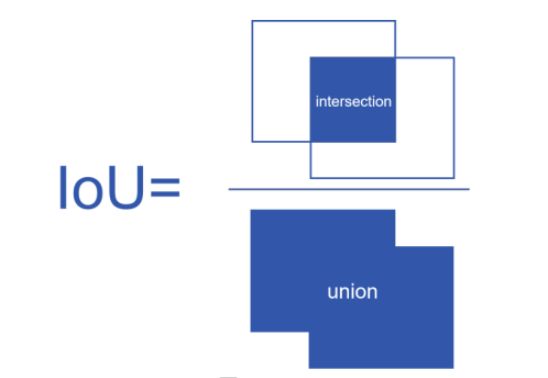
IoU: 用来评价目标检测算法的对象定位精度,IoU是目标检测的预测框和标签框之间的重叠面积与它们面积并集的比值,数值越大,说明目标检测算法定位越准确。 在实际过程中一般会设定一个IoU阈值(比如:0.5),如果大于等于0.5,对象将被识别为“成功检测”,否则将被识别为“错误”。
I o U = 两个矩形框相交的面积 / 两个矩形框相并的面积 IoU = 两个矩形框相交的面积 / 两个矩形框相并的面积 IoU=两个矩形框相交的面积/两个矩形框相并的面积
如下图所示:
指标作用
- 训练时
由于在训练过程中,会对同一个目标生成很多不同的检测框,以yolov1目标检测算法为例子,由于在训练过程中,会对每个grid cell预测生成很多不同的bounding box。在训练中我们挑选预测的bounding box与ground truth box的IOU最大的bounding box做为最优的box,但是在网络训练完成后,部署网络预测的过程中并没有ground truth box,怎么才能挑选最优的bounding box呢?
所以在yolov3模型训练阶段中,会通过结合损失函数去训练网络预测一个参数-置信度C,用来表示预测框中是否含有要检测目标的可信程度,在训练过程中,每个预测出来的bounding box都需要计算出一个真实的置信度,同时训练的网络要预测出一个置信度,通过损失函数约束真实置信度与预测置信度之间的差距,如yolov1的损失函数所示:

在yolov1中,会将一张图片分成77个小方格(损失函数中ss=7*7),每个小方格称为grid cell,yolov1官方代码中是对20个类别进行分类,所以每个grid cell会预测生成两个bounding box(损失函数中B=2),每个bounding box会预测一个置信度C,置信度C代表该bounding box中含有20个类别目标中的任一目标的置信度。其图如下:
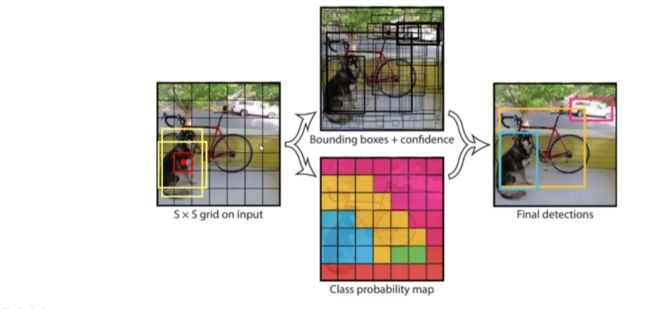
网络其中1^obj(i,j)表示第i个grid cell的第j个bounding box是否含有检测目标,是否含有目标的判断就是根据bounding box与ground truth box的IOU值是否超过0.5来判断。如果超过0.5为1,否则为0;
同时C^(i)表示真实的置信度,其值为第i个grid cell中第j个bounding box与ground truth box的IOU值,C(i)为网络预测出来的值,通过模型训练不断迭代训练使得C(i)不断拟合C^(i)真实值 。
- NMS(非最大抑制)
在目标检测中会出现同一个目标被多个bounding box检测到,如下图,为解决这个问题就需要用到NMS(非最大抑制)算法保留一个bounding box。
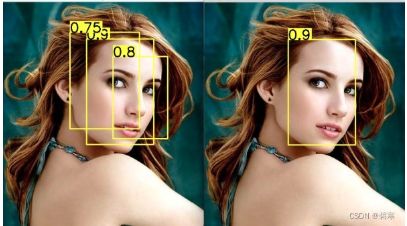
先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。NMS具体流程如下:
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。就这样一直重复,找到所有被保留下来的矩形框
2、Precision(精确度)
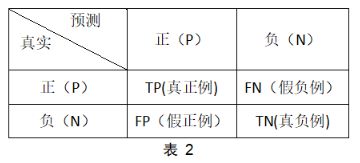
Precision: 精确度指目标检测模型判断该图片为正类,该图片确实是正类的概率。在这里需要明白什么是正类,如表二所示:
精确度衡量的是一个分类器预测出真正例的概率,计算公式如下图:
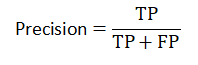
在图像的目标检测中精确度的计算公式还可以表示如下:
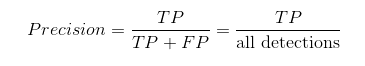
由于在目标检测的测试阶段,所有预测出来的框都是机器认为的正样本,上式中all detections就是预测标记为某一类的所有bounding box的数目,TP就是bounding box与ground truth box计算IOU值后大于阈值的框的数目(经过NMS算法,理论上每个ground truth box最多只有一个bounding box与之对应,也可以把TP理解为ground truth box被准确预测出来的个数),FP就是计算IOU值后小于阈值的框的数目(错误的被认为属于这一类的框的数目)。
目标检测一般不区分TN和FN。因为负样本根本没有显示出来,也不存在区分真假的问题。因此,目标检测中,TN和FN无意义。
为了更好理解精确度,举个例子,假如说有100个人中有50个好人,与50个坏人,结果分类器识别出来了59个好人,41个坏人。这59个人中有11个真正的坏人,41个人中有两个好人。所以如下:
T P = 59 − 11 = 48 TP=59-11=48 TP=59−11=48
T N = 41 − 2 = 38 TN=41-2=38 TN=41−2=38
F P = 11 FP=11 FP=11
F N = 2 FN=2 FN=2
所以该分类器的精确度P=48/(48+11)=0.814,可以看到这个分类器如果分类后的FP(假好人)越多,精确度就会越低,反之FP(假好人)越少,精确度就会越高,所以精确度表示了模型对于负样本(严格识别出坏人)的区分能力,精确率越高,则模型对负样本区分能力越强(越容易识别出每一个坏人)。
3、Recall(召回率)
Recall: 召回率是指分类器判为正类且真实类别也是正类的图像数量/真实类别是正类的图像数量,计算公式为:

同样、在在图像的目标检测中精确度的计算公式还可以表示如下:
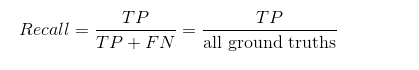
在目标检测中FN可以理解为测试数据集中ground truth box没有被检测出来的数量,TP理解为ground truth box被准确预测出来的数量,所以TP+FN=all ground truth,all ground truth就是测试样本中某一类别中的所有真实框的数目。
召回率衡量的是一个分类器能把所有的正类都找出来的能力,衡量的就是一个分类器能够把所有的好人都识别为好人,不冤枉一个好人的能力。由此可得上面的例子的召回率R=48/(48+2)=0.96。可以看到这个分类器的召回率还是很高的,但是我们也明显发现一个问题,虽然分类器把50个好人识别出来的数量高达48个,但是同时把11个坏人也识别成了好人,11个假好人的出现可不是什么好事情,但是单单从召回率的数值看并不能分析出这个分类器是一个优秀的分类器,他只是能够最大程度保证96%的好人可以识别出来。所以我们还需要其他指标参数辅助分析。
召回率高,意味着分类器尽可能将有可能为正样本的样本预测为正样本,这意味着召回率能够很好的体现模型对于正样本的区分能力,召回率越高,则模型对正样本的区分能力越强
精确率与召回率的关系
精确率与召回率是此消彼长的关系, 在图像的目标检测过程中,precision表示的是预测出来的检测框定位的准确率,就是我们得到了这么多框到底有多少个是好的(iou>5),比如我们一共有5个目标你给出了200个框(测试阶段,不对预测出来的框进行非最大抑制),同时这200个框中都包含了这5个目标,可以得到该模型的Recall=1,但是其他的195个框都是没用的,从而导致精确率低,这样无疑是很蠢的。那么recall怎么解释呢,recall是表征我们到底找到了多少个目标物的量,比如我们一共有200个目标,我们最后给出的检测框是20个而且这20个里面竟然有19个都是TP那么无疑我们的precision是很高的有95%,但是我们发现我们还有181个目标没有找到,也就是我们的recall是很低的,这肯定不行啊,比如我要通过雷达找导弹,一共12个导弹你就找到3个,好了够你死好几回了。所以我们可以看到无论是precision还是recall在目标检测中都是很重要的,但是我们发现我们多取一些框那么recall就可能比较的高,但是这样就可能会使得precision降低,所以在模型如果不是特别特别精确的情景下,这两个量是相互矛盾的,所以我们对于不同的场景可能就必须要选择到底要照顾那一边。那么对于普适的情况下我们就要综合考虑二者的取一个平衡,也就有了我们的AP这个指标。好吧下面来介绍AP的计算过程。
4、AP
AP的计算方法相对来说比较复杂,要综合上面的所有指标,所以下面的文字和代码,大家不要怕啰嗦,我保证你看我还不懂的话,可以打死我。
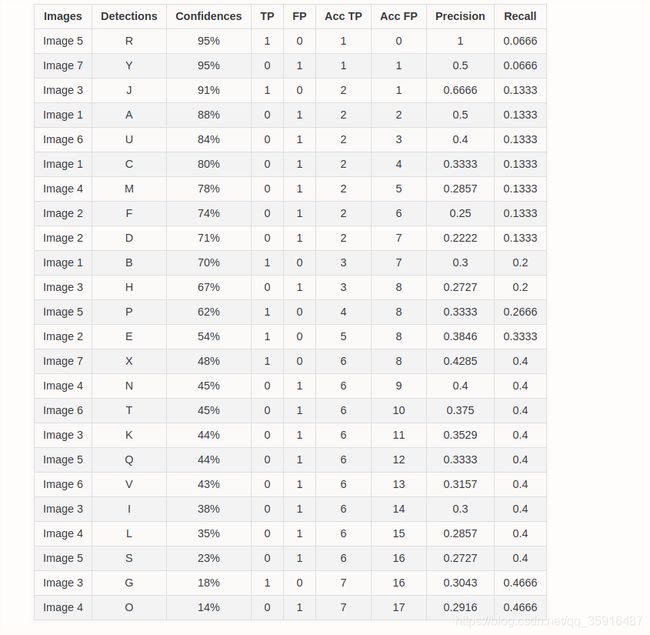
AP: 平均正确率就是得出每个类的检测好坏的结果,它的计算方法我们举例子说明,首先我们假设这个数据集中的某个类别一共有7张图像,然后这些图像中绿色的框是ground truths然后红色的框是我们得到的bounding box。
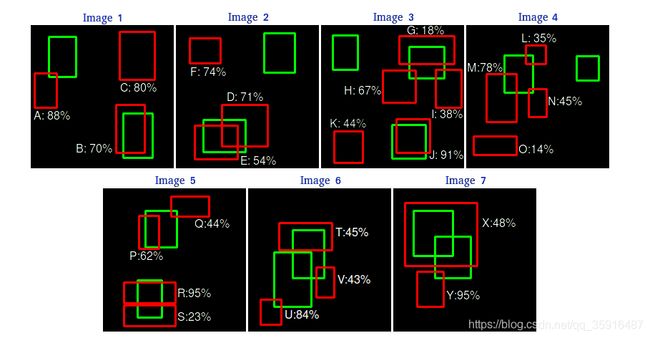
然后我们首先我们按置信度(confidence)来给这些bounding box排个序,就像下面这样,然后我们要看下这些框到底是TP还是FP,怎么判断我们上都有解释过,但是这里有一个问题就是对于同一个ground truth我们可能同时有多个框都和它的IOU都大于阈值,那么我么把它们都当做TP吗?肯定不是啊,这个时候我们就从这些框里面选一个和我们的ground truth重合率最大的一个框作为TP剩下的作为FP,注意这里是重合率大的留下而不是置信度(confidence)大的留下。其实我感觉这样也不太合理重合率大的作为TP没问题但是小的作为FP就不合理了,应该直接跳过这个框就好了不是TP也不是FP。好吧反正就是这么算。

然后得到了每个框是TP还是FP之后我们来计算 precision和recal序列,针对precision和recall序列,我这里在详细介绍一下。
precision序列
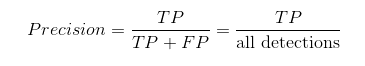
我们在计算AP的时候要首先要计算precision。在我们实际计算的时候是一个序列,如果我们一共有N个bounding box那么它就是一个长度维N的序列,我们计算Precision的时候是针对某一个类别的,首先确定一个类别,然后对这个类别的所有的检测结果按他们得到的分数也就是confidence进行从大大小排序,然后我们每次取一个结果出来不管这个detection是TP还是FP,all detections都要加1也就是在实际计算的过程中上述的公式中的all detections是一个递增变化的数,每次取一个框就加1,然后每次取一个框出来如果这个框是TP那么TP的数目就加1,然后TP和all detections比值作为当前的precision,这样取完所有的框就有了N个precision组成的一个序列。
recall序列
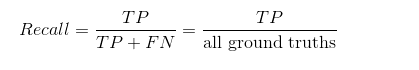
与precision对应的recall也是一个长度维N的序列,其中N是我们得到bounding box的数目,我们没取出来一个框如果这个框是TP,那么TP的数目就加1,然后我们用当前的TP数目来除以all ground truths来得到当前的recall,这里要注意all ground truths就是我们这数据集中所有的这个类别的目标的数目,对于一个特定的数据集的一个特定的类别这是一个定值。
最后这一类别计算的precision和recall序列如下所示:

然后怎么算我们已经说过了现在我们在简单提下看最前面的两个框。取到第一个框的时候我们的all detections就是1正好我我们这个框就是TP,所以我们这里的precision就是1咯,然后在取一个框,但是这个框是FP,所有我们的TP数目还是1,但是我们的all detections就变成2了所以我们的precision这个时候变成了0.5,然后我们看下recall我们一共有15个groundtrus然后我们的recall只有在我们取到了一个TP之后才会变化对吧,好了这个很明显了我不想写了。
然后有了recall和precision序列了然后我们怎么搞,AP的计算有两套标准,一套是07年的标准,一套是后面的标准我们一般现在使用的都是新的标准。
第一种方是根据recall将我们的得到的那个序列分成11段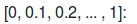

就是首先我们取出来所有的recall在0到0.1这个区间内的所有的recall以及对应的那些precision,然后我们从这些precision中找到最大值作为这个区间内precision的代表,然后我们在剩下的10个区间内也分别找到最大的precision,最后把这11个数求均值就作为我们的AP。如果没懂没关系,我们先看方法一在例子中的运用。
运用方法一求解例子的AP的展示如下图:
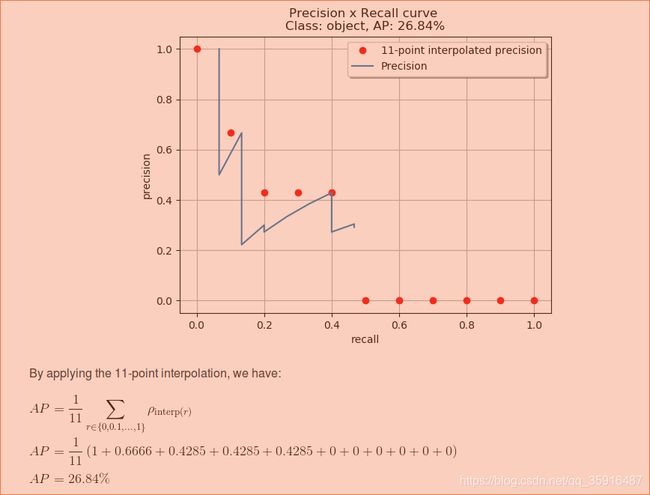
我们可以看到我们上面只是取了11个recall的区间,这样做其实也可以但是总是感觉太粗糙了些,所以后面大家就提出了一种新的AP的计算方法,我们可以把所有的recall取值都取一遍,仔细观察下我们会发现其实在recall序列中有些位置都是相等的,因为只有我们取到了一个TP的时候recall的数值才会发生变化。

好了我们结合上面的公式来看看到底怎么算,首先我们取到了第n种recall的取值,然后我们我们在往后看直到发现出现了不同的recall,我们然后我们在这个区间里找到最大的precision,然后用这个最大的precision和这个区间长度相乘作为这段区间的AP,然后我们遍历所有的区间然后把每段的AP加起来就得到了最后的AP。如果还是没有看懂我们看个例子,看完下面例子你一定就懂了。
如上图,就是每个recall区间做相应的计算,即每个recall的区间内我们只取这个区间内precision的最大值然后和这个区间的长度做乘积,所以最后体现出来就是一系列的矩形的面积,上面的那个例子,我们一共有recall一共变化了7次,我们就有7个recall区间要做计算,然后实际我们计算的时候人为的要把这个曲线变化成单调递减的,也就是对现有的precision序列要做一些处理,具体的处理我结合代码说明一下:
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
print(mpre)
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
print(mpre)
return ap
这个代码在任何一个目标检测的代码里应该都可以找到的,下面我们看下这个代码做了哪些事情:首先我们输入的序列是我们得到的:
rec:[0.0666,0.0666,0.1333,0.1333,0.1333,0.1333,0.1333,0.1333,0.1333,0.2,0.2,0.2666,0.3333 ,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4,0.4666,0.4666],
然后是我们的pre:[1,0.5,0.6666,0.5,0.4,0.3333,0.2857,0.25,0.2222,0.3,0.2727,0.3333,0.3846,0.4285,0.4,0.375,0.3529, 0.3333,0.3157,0.3,0.2857,0.2727,0.3043,0.2916]。
代码里首先是判断是不是用11点的方法,我们这里不用所以跳转到下面的代码:
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
那么这一步呢就是相当于把我们的recall的开区间给补上了,补成了闭合的闭区间。mpre也是做了对应的补偿使得一一对应。np.concatenate()函数,concatenate在英文中是级联的意思,我们可以简单地理解为连接。具体用法大家可以自己去了解,
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
那这一步呢就是在做我们上面说到的人为地把这个pre-rec曲线变成单调递减的,为什么这么做呢,我也不太清楚。我们这里可以看到他就是在做一个比较,就是后一项要是比前一项大的话那么就把这个大的值赋值给前一项。做完这一步后的pre就变成了:[1. 1. 0.6666 0.6666 0.5 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4285 0.4 0.375 0.3529 0.3333 0.3157 0.3043 0.3043 0.3043 0.3043 0.2916 0. ]我们发现与之前的[0. 1. 0.5 0.6666 0.5 0.4 0.3333 0.2857 0.25 0.2222 0.3 0.2727 0.3333 0.3846 0.4285 0.4 0.375 0.3529 0.3333 0.3157 0.3 0.2857 0.2727 0.3043 0.2916 0. ]对比那些在0.4285之前出现的但是比0.4285小的数值都被替换成了0.4285.,相当于强行把这个曲线给填的鼓了起来。
做完这个操作后,我们就要按rec区间去计算ap了,准确来说是用rec的区间长度乘以这个区间上的最大的pre(注意这里是处理后的pre)。代码实现起来就是:
i = np.where(mrec[1:] != mrec[:-1])[0]#获取rec区间变化的点
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])#(mrec[i + 1] - mrec[i])这里得到rec区间的
#长度,mpre[i + 1]这里是这个区间上对应的pre数值(处理后的)
我们这里分别输出一下:
print((mrec[i + 1] - mrec[i]))
print(mpre[i + 1])
结果是:[0.0666 0.0667 0.0667 0.0666 0.0667 0.0667 0.0666 0.5334]和[1. 0.6666 0.4285 0.4285 0.4285 0.4285 0.3043 0. ]我们看一下首先是0.0666他代表第一个rec0.0666到0的区间长度,然后呢这个区间上出现的最大的pre是1,第二项0.0667代表0.0666到0.1333的区间长度是0.0667,在rec取0.1333这段区间上最大额pre是0.4285(变化后的),后面的以此类推这块还有疑问的建议结合这上面的那个表和pre处理后的序列看一下哈,。为啥pre输出的最后一项是0呢,是因为这段区间实际上recall是没有达到过的我们最大的rec也就只到了0.4666就结束了。
那么对于这个例子就是通过上面的就可以算出来了,其实还是蛮直观的。恩到这里我们就把怎么算AP讲完了。
5、mAP
到这里mAP的计算方法就非常简单了,mAP是啥呢,其实m就是mean均值的意思我们AP不是算个一个类别的吗,mAP就是把所有的类别的AP都算出来然后求个均值就可以了,然后至于代码github上面或者你看faster-RCNN这些都有现成的,恩希望大家看完这个就能理解AP咋算的啦,有不懂的地方好好看看这个例子肯定是可以看懂的。