Yolov3关键代码解读
在看此篇前,先理清楚VOC2007数据是怎么转换成yolo所需要的数据
参考:
从已有VOC2007数据集生成yolov3所需要的数据集,以及正式开始调试程序需要修改的地方_AutoGalaxy的博客-CSDN博客
一. 从loss出发,tragets是怎么计算出来的
推演:涉及到执行到这一部分时,可迭代对象在内部做了啥事
pbar = tqdm(enumerate(dataloader), total=nb)
for i, (imgs, targets, paths, _) in pbar:进入到dataset 对象实现的 __getitem__()方法(基础的python语法)
在读代码的时候,发现yolov3,采取的resize图片策略是,先以长的一边进行resize,再把短的边进行补齐,避免了图像变形。
这为啥还有马赛克啊,这就涉及到mosaic数据增强
1.1 mosaic 数据增强
关于这一部分请看博客:大白话图解YOLOV3中的mosaic算法_AutoGalaxy的博客-CSDN博客
上面的最后输出 的labels 是 xyxy,即框在图像里面的像素坐标,长下面这个样子

1.2. 色域增强
代码如下:
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
1.3. 把xyxy label 变成 xywh label
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5])1.4. 再把label 归一化,除以 图像 的 w 和 h
labels[:, [2, 4]] /= img.shape[0] # height
labels[:, [1, 3]] /= img.shape[1] # width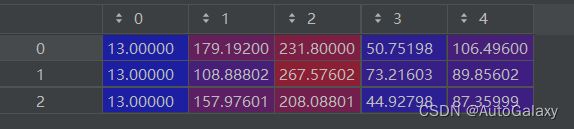
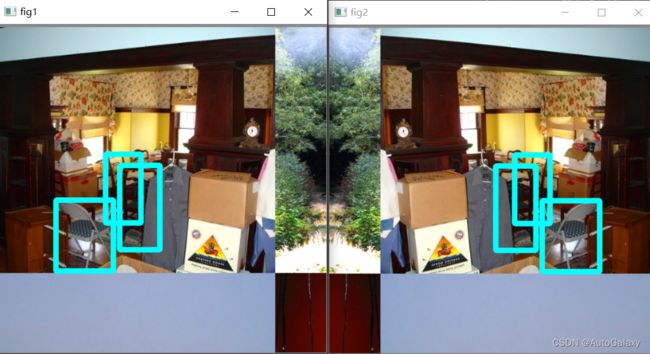
1.5. 以0.5的概率镜像图片
就是把下面的fig2 变成 fig1
实现代码是
img = np.fliplr(img)fliplr的具体用法看官方代码注释即可知道,如下是官方给的例子

同时镜像之后,记得label 也要镜像哦:
labels[:, 1] = 1 - labels[:, 1]这里是左右镜像,同时还有上下镜像,也是以0.5的概率选择的。
1.6. 创建3行6列的tensor变量
把labels放到 索引是第1~5列里面
labels_out = torch.zeros((nL, 6))
labels_out[:, 1:] = torch.from_numpy(labels)注意,上面没有直接给 第1列赋值,目前第1列还是0
1.7. 把BGR转为RGB图,再变成 3 x 416 x 416的形式
代码解读:
img = img[:, :, ::-1].transpose(2, 0, 1)其中的::-1参考博客:numpy总结_AutoGalaxy的博客-CSDN博客
我们可以查看一下img的取值样子
3通道,就意味着最里面的元素是一个有3个元素的array
 转换成RGB,就逆一下就可以了。
转换成RGB,就逆一下就可以了。
img = img[:, :, ::-1].transpose(2, 0, 1)上面的代码把 416 x 416 x 3 的array 转化成了 3 x 416 x 416
参考博客:numpy总结_AutoGalaxy的博客-CSDN博客
最后做了一步内存连续的操作:
img = np.ascontiguousarray(img)1.8. 最后便得到了我们的输出
经过以上步骤的详细分析,你也清楚了为什么输出的label框跟原始txt文件里面的label不一样,是因为这里的框经过了图像裁剪拼接,还有可能镜像等等操作,导致最后的结果不一样。
return torch.from_numpy(img), labels_out, img_path, shapes因此,targets虽然值不同于原始labels,但是物理意义是相同的。
x_center/图像宽,y_center/图像高,框宽/图像宽,框高/图像高
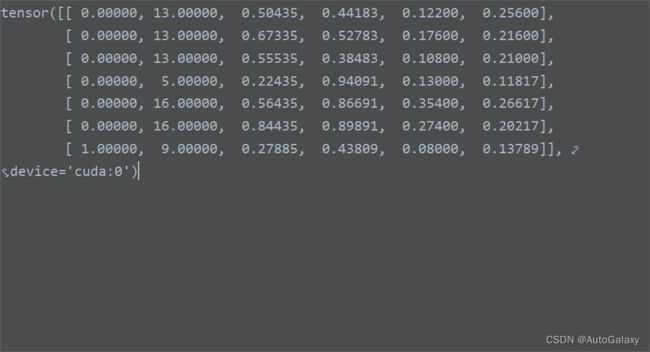
tragets的输出长下面这个样子:这里的batch_size = 2
第一个label表示,这一行属于哪batch_size的第几张图片,具体这里是怎么操作的有待商榷
二. 从epoch循环开始,到进入batch计算,做了哪些事
2.1. 训练模式下运行model.train()
参考博客:nn.Moudle模块-创建神经网络结构需要注意的细节_AutoGalaxy的博客-CSDN博客
2.2. prebias条件下做的事(第0轮训练才进入到这里,为什么其他轮不用进行做这里的事呢?)
以下代码做的事:
optimizer.param_groups[2]['lr'] = ps[0]优化bias参数的优化器使用的学习率是ps[0]
由下面句代码引起的疑问,SGD为什么还会有momentum参数呢?
optimizer.param_groups[2]['lr'] = ps[0]
if optimizer.param_groups[2].get('momentum') is not None: # for SGD but not Adam
optimizer.param_groups[2]['momentum'] = ps[1]第3轮训练会做以下的事:(也暂时不知道原因)
if epoch == ne:
ps = hyp['lr0'], hyp['momentum'] # normal training settings
model.gr = 1.0 # giou loss ratio (obj_loss = giou)
print_model_biases(model)
prebias = False2.3. 为什么要有dataset.image_weights呢?
实在没想明白这里更新图像权重是什么意思?以及为什么要有这一步,为什么可选
if dataset.image_weights:
w = model.class_weights.cpu().numpy() * (1 - maps) ** 2 # class weights
image_weights = labels_to_image_weights(dataset.labels, nc=nc, class_weights=w)
dataset.indices = random.choices(range(dataset.n), weights=image_weights, k=dataset.n)至此,这一部分就完结了,之所以很懵的原因,其实也显示出来了,以上大部分代码你都不清楚来由,不能直观理解。
三. targets计算之后,做了哪些事
一行一行解析,第一行里面参数意义:
nb:训练集的图片数量
epoch:当前训练的幕数
i:把原训练集划分为n个batch,然后i取值范围是 0,1,2,.......,n-1
右边参数意义都知道,合起来之后ni你就不知道了。。。。
ni = i + nb * epoch再把图像的像素值归一化:以及把图像传给GPU
imgs = imgs.to(device).float()
targets = targets.to(device)3.1. 超参数老化部分做的事
n_burn = 200 # number of burn-in batches
if ni <= n_burn:
# g = (ni / n_burn) ** 2 # gain
for x in model.named_modules(): # initial stats may be poor, wait to track
if x[0].endswith('BatchNorm2d'):
x[1].track_running_stats = ni == n_burn3.2. 用边界框画图像
if ni < 1:
f = 'train_batch%g.png' % i # filename
plot_images(imgs=imgs, targets=targets, paths=paths, fname=f)
if tb_writer:
tb_writer.add_image(f, cv2.imread(f)[:, :, ::-1], dataformats='HWC')
3.3. 多尺度训练
if opt.multi_scale:
if ni / accumulate % 1 == 0: # adjust img_size (67% - 150%) every 1 batch
img_size = random.randrange(img_sz_min, img_sz_max + 1) * 32
sf = img_size / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / 32.) * 32 for x in imgs.shape[2:]] # new shape (stretched to 32-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)3.4. 模型预测并且计算loss
pred = model(imgs)但是pred长下面这个样子:
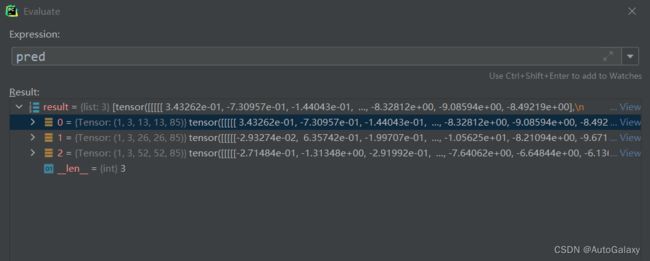
pred的输出正好是yolov3网络结构中的3个特征图层
13x13,26x26,52x52
然后开始分析输出数据的含义

如上所示,论文里面说的比较清楚了,3代表3个anchor框,每个anchor框都有 4个边界框偏置参数,一个是否有物体的参数,以及80个类别预测的参数
咦,但是你的VOC2007只有20个类别,这里的80个类别是怎么回事?最多预测80类,那么80以下的都能预测 。更改cfg文件里面的classes即可。
4个边界框偏置分别是![]() ,分别其到的作用如下所示
,分别其到的作用如下所示

那么这里的![]() 又有什么意义呢?其中的
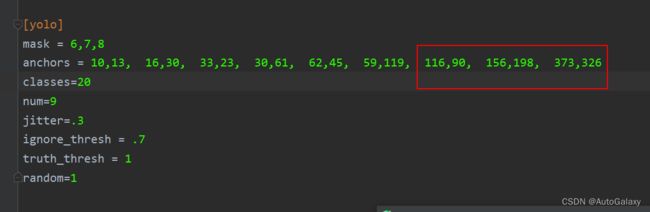
又有什么意义呢?其中的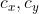 是anchor框的大小,例如对于13x13的特征图层,anchor框有如下三个取值:这里更加实际意义的取值,看下文,下文有更加具体的解释
是anchor框的大小,例如对于13x13的特征图层,anchor框有如下三个取值:这里更加实际意义的取值,看下文,下文有更加具体的解释
116,90, 156,198, 373,326注意:对于划分13x13的图像,
是神经网络输出4中的2(是这里面的(4+1+20)的4)
是框的中心坐标,以32个像素为一个单位长度,换算到实际,记得乘以32哦!
是神经网络输出4中的2(是这里面的(4+1+20)的4)
而targets长这个样子

维度都完全不一样,二者怎么做loss呢?
得进一步分析函数compute_loss
def compute_loss(p, targets, model)开头两行代码其实都没怎么看懂
ft = torch.cuda.FloatTensor if p[0].is_cuda else torch.Tensor
lcls, lbox, lobj = ft([0]), ft([0]), ft([0])这里又要进入支线函数build_tragets:
tcls, tbox, indices, anchor_vec = build_targets(model, targets)里面有一句涉及多GPU的代码
multi_gpu = type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
for i in model.yolo_layers: 关于上面的代码,model.yolo_layers,来源:
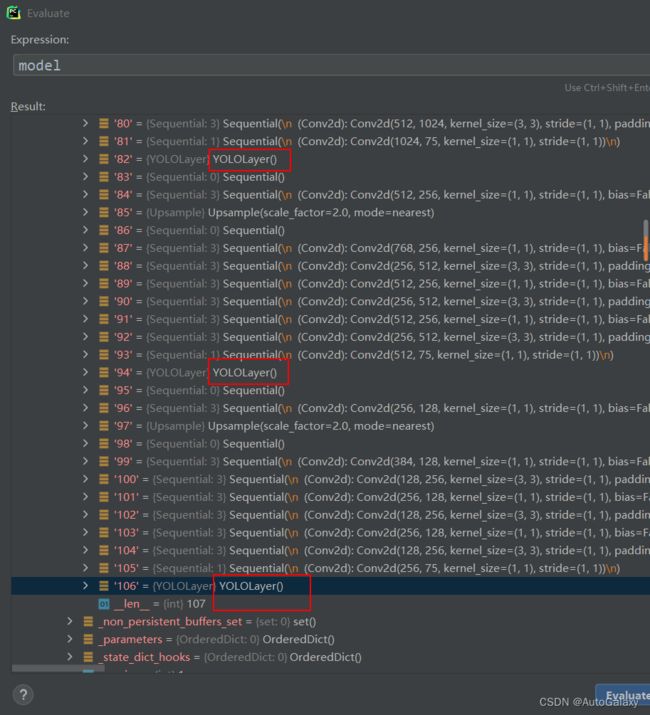
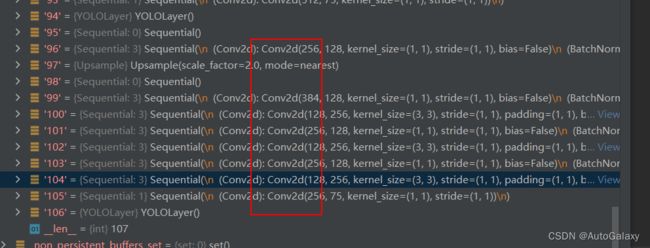
上图两个yolo层之间隔了8个卷积层,正好跟.cfg文件里面相同。
接下来对每一个特征图层分别进行下述代码运算
ng, anchor_vec = model.module_list[i].ng, model.module_list[i].anchor_vecng的结果是13x13
anchor_vec长下面这样

anchor_vec对应值是anchor框值,
看出来了吗?
下面详细解析
一张416x416图片划分成13x13个宽高为32个像素的网格

要把像素单位转换成0~12之间的单位表示
![]() ,,因此边框,
,,因此边框,![]() ,依次类推
,依次类推
进入到这一行代码,这里蕴含着这一关系:ng=[13,13]
gwh = t[:, 4:6] * ng![]()
其中![]() 代表label框中宽的实际像素长度,除以
代表label框中宽的实际像素长度,除以![]() 代表把像素长度单位换算成 以32像素长度为单位。
代表把像素长度单位换算成 以32像素长度为单位。
同时观察一下这里的维度,说明这里仅仅是点乘
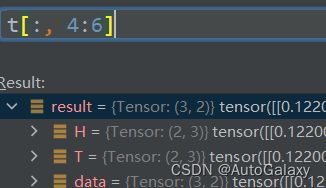

这里的计算iou的代码有一点复杂啊!
def wh_iou(wh1, wh2):
# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
wh1 = wh1[:, None] # [N,1,2]
wh2 = wh2[None] # [1,M,2]
inter = torch.min(wh1, wh2).prod(2) # [N,M]
return inter / (wh1.prod(2) + wh2.prod(2) - inter)这里就是计算交并比而已,但是这里假设了真实框与锚框起点是相同的,
如下图所示,各个黄框(anchor)分别与蓝框(真实框)计算交并比

inter = torch.min(wh1, wh2).prod(2)上面这行代码实现的就是计算下面橙色面积,总共有9个橙色面积,我这里只画了3个

return inter / (wh1.prod(2) + wh2.prod(2) - inter)最后一行代码里面的,
wh1.prod(2) + wh2.prod(2)
代表计算参与交并比的一个黄色框和一个蓝色框面积和,再减去一份公共的,就得到想并的面积
注意,这里的wh1.prod(2)是3x1维,wh2.prod(2)是1x3维,inter是3x3维,这里内部自动进行了维度扩展。
最终上面得到的iou结果如下
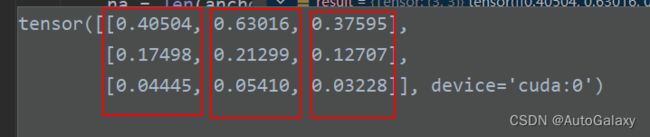
一个红色框的三个值,分别代表一个target框与3个anchor框的交并比,注意这一切的交并比计算都不是最终的交并比,仅仅只是为了选取最合适的一个锚框而已,近似看作真实框起点与锚框起点重合,实际上并非一定重合,但是由于网格划分小,因此误差很小,而且这一大部分的目标仅仅只是为了选择一个合适的锚框来套这个target框。
若使用所有的锚框
if use_all_anchors:
na = len(anchor_vec) # number of anchors
a = torch.arange(na).view((-1, 1)).repeat([1, nt]).view(-1) #nt=39 a中有39个0 39个1 39个2
t = targets.repeat([na, 1])
gwh = gwh.repeat([na, 1])
else: # use best anchor only
iou, a = iou.max(0) # best iou and anchor
# reject anchors below iou_thres (OPTIONAL, increases P, lowers R) 去除一些iou小的 该种方式准确率提升,召回率下降
if reject:
j = iou.view(-1) > model.hyp['iou_t'] # iou threshold hyperparameter
# a代表第几个锚框
t, a, gwh = t[j], a[j], gwh[j]
# 这里得出来的结果,表示,第1个target框,可以由第0个锚框和第1个锚框来框
# 第2个target框,可以由第0个锚框和第1个锚框来框
# 第3个target框,可以由第0个锚框来框上面这部分代码的意义表示如上以及如下

b, c = t[:, :2].long().t() # target image, class
gxy = t[:, 2:4] * ng # grid x, y
gi, gj = gxy.long().t() # grid x, y indices 实际物体的中心坐标落在13*13哪个框里 long是在进行向下取整
indices.append((b, a, gj, gi)) #b是这个框在batch_size中的第几张图 a代表该目标与哪个锚框对应 gj, gi是grid x, y indices
之后上面这部分代码,又把上面的出来的target待选框,如下所示


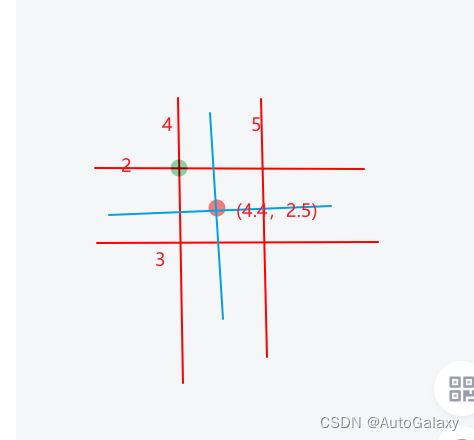
把上面得出来的target待选框,先取出中心坐标,以32像素网格为单位长度,然后向下取整,具体就是如下所示,原来中心坐标是(4.4,2.5),现在取(4,2)
最后得出一个list indices,这个list存储(traget框在batch_size的第几张图,该目标与哪个锚框对应,以及该目标框的坐标所属于的网格)
gxy -= gxy.floor() # xy floor是取整3.14-->3 所以这个时候的gxy对应的是0.14
tbox.append(torch.cat((gxy, gwh), 1)) # xywh (grids) tbox内部存储的是gxy去除整数部分 以及wh
av.append(anchor_vec[a]) # anchor vecgxy代表下图中,黑色括号的长度

然后把这个黑色括号的长度,与,target框的宽高(以32像素或者其他像素为单位长度)组合起来
最后av这个list存储的label框对应的锚宽
tcls.append(c)tcls存储对应label框的类别
这里特意采用list来存储,目的就是为了区分这是第几个图层
第一个图层13x13,list的索引是0
第二个图层26x26,list的索引是1
第三个图层52x52,list的索引是2
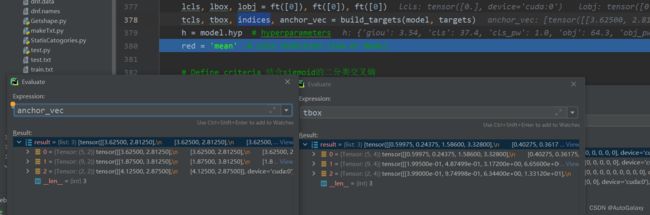 上图3list,各个list分别对应不同图层检测出来的target框以及对应的锚框
上图3list,各个list分别对应不同图层检测出来的target框以及对应的锚框
至此,build_targets分支函数已经完结。
其目的就是找出target框对应的锚框,
其中的tbox是关键数据

红色框存储的是上面第3张图片里面黑色括号的长度,橙色框存储的是traget框用 13x13或者26x26或者52x52 网格单位表示的 label宽高
接下来继续进入到剖析 compute_loss函数的部分
pxy = torch.sigmoid(ps[:, 0:2]) # pxy = pxy * s - (s - 1) / 2, s = 1.5 (scale_xy) 预测xy值通过sigmoid进行归一化
pwh = torch.exp(ps[:, 2:4]).clamp(max=1E3) * anchor_vec[i] # 预测wh值通过exp进行非负处理
pbox = torch.cat((pxy, pwh), 1) # predicted box
giou = bbox_iou(pbox.t(), tbox[i], x1y1x2y2=False, GIoU=True) # giou computation上面这一部分,第一行代码在做下面这个公式里面的红框运算
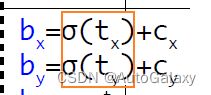
注意是sigmod函数,长这个样子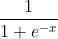 。实际上,这里红框计算出来的预测结果,是下面黑色线的部分:绿色点是(cx,cy),也就是label里面给定的。深度学细的本质就是学习数据。
。实际上,这里红框计算出来的预测结果,是下面黑色线的部分:绿色点是(cx,cy),也就是label里面给定的。深度学细的本质就是学习数据。

第二行代码,中的anchor_vec[i],代表在对应图层中,此label框所使用的锚框宽和高。
clamp表示限制元素范围
这一行代码表示做下面公式的运算:

也说明了论文里面的pw和ph,是进行了单位转换的,bw和bh的单位和pw和ph的单位一致
第三行代码,很自然的组合成了预测的输出值
第四行代码中,tbox存放的是真实label框的xywh,tbox是一个list,含有3个元素,分别对应3个特征图层,第一个特征图层是对应13x13,里面的xywh自然也是换算到了13x13的单位。
进入到bbox_iou函数,box1和box2的量纲是一致的了,一个是预测值,另一个是目标值
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2以上前两行代码,是预测框左上角坐标,和右下角坐标
下面两行代码,是目标框左上角坐标,和右下角坐标
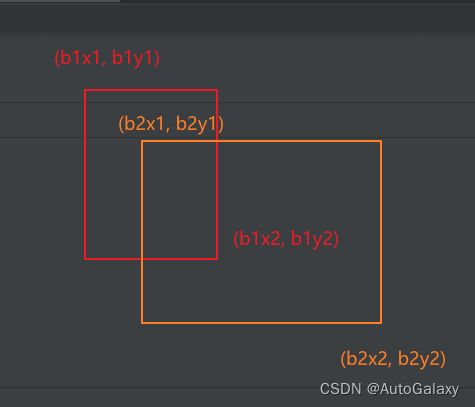
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)上面这行代码实现的功能是求下面两个框的交集面积,把坐标对应一下就知道了。
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1
union = (w1 * h1 + 1e-16) + w2 * h2 - inter上面这三行代码求并集面积
iou = inter / union # iou
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if GIoU: # Generalized IoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + 1e-16 # convex area
return iou - (c_area - union) / c_area # GIoU这里计算的是GIoU,关于IOU的解析,又是一门学问哩!待了解
又回到compute_loss函数,看如下这一行的代码
lbox += (1.0 - giou).sum() if red == 'sum' else (1.0 - giou).mean()注意lbox构成一个loss的一部分,这跟你之前看网上的用t值来减不一样,这里用的是giou来当作损失,正常情况,iou越接近1越好,但loss一般求最小,因此用1减去
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * giou.detach().clamp(0).type(tobj.dtype) 再进入到下面的代码
if model.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], cn) # targets
t[range(nb), tcls[i]] = cp
lcls += BCEcls(ps[:, 5:], t) # BCE其中tcls[i]代表第i个图层里面label对应的类别
t[range(nb), tcls[i]] = cp
上面这一行代码在创建类别目标值,如下图所示,就是一个vector,是就是1,不是就是0

再到这一行代码
lcls += BCEcls(ps[:, 5:], t) 我们查看一下,类别预测值:
现在的关键在于上面的loss,是如何计算的呢?
现在我单独取出一个label框出来:
目标向量值:[ [0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.] ]
实际输出向量值:[ [-3.57031, -6.14844, -4.58594, -6.32422, -6.58203, -5.46875, -6.03125, -5.57031, -5.18359, -6.05859, -6.52734, -6.59375, -6.28906, -3.80664, -4.39062, -6.24609, -5.04688, -5.81250, -6.31250, -5.58594] ]
目标向量的第一个0代表不是第0类,第二个0代表不是第1类,依次类推
向量第一个位置的交叉熵:需要把输出换算成概率,因此使用sigmod函数;
第一个位置信息熵:
依次类推可以算出其他位置的信息熵。
然后所有交叉熵之和再求平均。
再到这一行代码:表示是否这个位置存在物体,同样使用逻辑交叉熵损失函数,对应位置使用像上面计算类别一样的公式。
lobj += BCEobj(pi[..., 4], tobj) lbox *= h['giou'] #3.54
lobj *= h['obj'] #64.3
lcls *= h['cls'] #37.4上面这一行损失乘的权重是如何确定的呢?
四. 计算完损失之后,做了哪些事儿
4.1. 计算梯度
if mixed_precision:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()听说是混合精度加速训练
4.2. 每次batch训练,假设batch是16张图片,那么每隔 16 * accumulate张图片才更新一次参数
if ni % accumulate == 0:
optimizer.step()
optimizer.zero_grad()看到这里之后,便可以正式开始训练了。但是似乎总觉得有问题,说不清楚
五. 这份程序主体之外的事的一些疑问:
5.1. 为什么我修改了epochs = 1仍然还要这么久才能完成一幕训练呢?


因为:训练模式如下
假设数据集有1024张图片,batch_size=16,那么首先把1024分成64份,每份16张图片,当作一个batch,然后把这64份数据集依次训练完才算全部训练完。
5.2. 一般情况,随着epoch的增大,学习率逐渐减小
lf = lambda x: (1 + math.cos(x * math.pi / epochs)) / 2 # cosine https://arxiv.org/pdf/1812.01187.pdf
# 注意这里的epochs为之前的设置的总的epoch数,x代表epoch
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf, last_epoch=start_epoch - 1)可以参考这篇博客:[pytorch] torch.optimizer.lr_scheduler调整学习率_一点也不可爱的王同学的博客-CSDN博客_optimizer.lr
5.3. tqdm
参见:python进度条库tqdm详解 - 知乎 (zhihu.com)
5.4. 运行到这一行代码,为什么突然生成了两张图片
final_epoch = epoch + 1 == epochs
if not opt.notest or final_epoch: # Calculate mAP
is_coco = any([x in data for x in ['coco.data', 'coco2014.data', 'coco2017.data']]) and model.nc == 80
results, maps = test.test(cfg,
data,
batch_size=batch_size * 2,
img_size=img_size_test,
model=model,
conf_thres=0.001 if final_epoch else 0.01, # 0.001 for best mAP, 0.01 for speed
iou_thres=0.6,
save_json=final_epoch and is_coco,
single_cls=opt.single_cls,
dataloader=testloader)
很懵,我的数据集图片不是这个样子的啊,而且我只训练了一幕,真心有蛮奇怪的
5.5. 训练一幕完成做的事以及全部训练结束后做的事也是蛮复杂的,很多博客都不愿细细分析。
5.6. 运行时,还出现下面这个错误

找到出错的地方了,三个warning,刚好对应三个yolo层

感觉解决不了这个问题了,以及yolov3的网络结构,反正我的代码不能传给tensorboard
不能传入不是由于你的问题,而是代码的问题。找一份官方纯净代码。