推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第1张图片](http://img.e-com-net.com/image/info8/3ef215e7e927459ba4a6cb72b12e94f4.jpg)
本文介绍的论文是《Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction》
论文下载地址:https://arxiv.org/abs/1905.09248
代码地址:https://github.com/UIC-Paper/MIMN/tree/master/script
又双叒叕是一篇用户行为序列建模的文章,主要关注三个方面,分别是数据特征存储、线上预测效果、线上预测耗时,即如何在使用更长的用户行为序列,提升线上预测准确性的基础上,减少特征存储空间以及线上预测耗时呢?一起来看一下本文提出的MIMN模型。
1、背景
在CTR预估中,用户历史行为信息是很重要的一类信息,如何利用用户的历史行为信息呢?大致可以分为以下几类方法:
1)pooling-base方法:将用户行为序列中的单个行为作为单独的信号,并通过sum/max/mean pooling等方式来进行聚合,作为用户的兴趣表示。除此之外,DIN通过attention的方式来对用户历史行为的embedding进行加权求和。
2)sequential-modeling方法,将用户行为序列当作连续的信号,并使用LSTM/GRU等方法来抽取用户的兴趣,如DIEN的兴趣抽取层和兴趣演化层。
然而,在工业场景中,将如此复杂的包含用户行为序列的模型部署上线,是非常困难的。主要有以下几方面:
1)在高并发的场景下,同时访问系统的用户增加时,整体预测的性能需要保证。
2)需要将用户所有的行为序列进行存储和读取,当用户行为序列特别长(达到1000或更多)的时候,存储所需要的空间会更加巨大,同时读取所有行为的延时更高。
使用更长的用户行为序列是否有意义呢?下图表示了淘宝用户的平均行为序列长度,以及使用不同长度的用户行为序列所能得到的AUC情况,可以看到,注册天数为120天的用户,其平均行为长度已经达到了900。同时,当使用更多的用户行为序列时,模型的AUC也有一定的收益,显然,使用长用户行为序列建模是有一定意义的。
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第2张图片](http://img.e-com-net.com/image/info8/8ca735cec21c4e58a468e884fa950a3a.jpg)
那么如何能够同时实现使用更长的用户行为序列(长度为1000),提升线上预测准确性,减少特征存储空间以及减少线上预测耗时呢?论文提出了MULTI-CHANNEL USER INTEREST MEMORY NETWORK(MIMN)。接下来,咱们首先来介绍一下实时点击率预估系统,再介绍一下MIMN模型。
2、实时点击率预估系统
在推荐或者广告系统中,点击率预估模块起着至关重要的作用。该模块接收一系列候选集,通过实时计算,返回相应的点击率预估结果。下图是对阿里妈妈的实时点击率预估系统流程的一个概括性描述:
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第3张图片](http://img.e-com-net.com/image/info8/43f1d8ecc0414d1482b00a744033c6d6.jpg)
1)首先,预测系统接收一个请求,请求中包含用户ID、以及一些列广告ID
2)系统将用户ID和广告ID传入到特征平台
3)特征平台返回对应的用户统计特征、用户行为序列特征、广告特征,特征通常存储在内存存储系统中,如TAIR(对线上特征存取不太了解的同学可以百度一下)
4)基于给定的特征,调用相关的模型,系统给出对应的点击率预估结果
这样一套实时点击率预估系统看似比较完善,一般的公司也大都采用类似的流程。但对于阿里妈妈来说,在处理长用户行为序列时,却面临着存储和线上耗时两方面的挑战:
1)存储空间限制(Storage Constraints):阿里妈妈有超过6亿的用户,当存储的用户行为序列长度为150时(存储商品id、店铺id、品牌id等),需要1TB的空间,当长度上升为1000时,存储空间需要6TB。巨大的存储消耗,会导致更高的特征抽取耗时、更困难的用户行为序列更新,以及更多的资金花费
2)线上延时限制(Latency Constraints):对于线上实时预测,当QPS(每秒请求量)为500时,延时控制在30ms。当DIEN处理的用户行为序列长度为1000时,模型的延迟却达到了200ms,这显然是不能接受的
为了解决上述的挑战,论文提出了MIMN模型,并通过User Interest Center(UIC)模块,解决了存储和线上耗时两方面的问题。
3、MIMN模型介绍
MIMN模型的结构如下:
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第4张图片](http://img.e-com-net.com/image/info8/d4c62dc9c6f94fbc8c00a7a199040170.jpg)
接下来我们简单介绍一下其中的细节。
3.1 Neural Turing Machine
MIMN主要通过 Neural Turing Machine(以下简称NTM)来对行为序列进行处理,该部分的图示如下:
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第5张图片](http://img.e-com-net.com/image/info8/00d1e866b10b49748b8db2e5c0f01f07.jpg)
标准的NTM通过记忆网络对序列数据的信息进行提取和存储,以时间步t为例,存储的记忆矩阵记作Mt-1,一共有m个槽位(slot),第i个slot的记忆向量记作Mt-1(i),此时输入用户第t个行为embedding向量。行为向量通过controller以及两个基本的模块memory read和memory write对记忆进行读取和更新。(这里说明一下,在看论文的时候对论文中的下标存在一定的疑问,所以去看了源代码,本文对下标做了一定的调整,当然我个人也可能理解的不对,欢迎大家批评指正)
Memory Read:对于第t个输入的embedding向量,通过controller得到一个读键kt ,通过kt计算与当前记忆矩阵Mt-1中每个记忆向量计算相关性向量wrt,计算过程如下(看了代码应该用Mt-1更为合适,但论文中是Mt):
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第6张图片](http://img.e-com-net.com/image/info8/635333121b1747668ab2991bb9ba6a68.jpg)
然后计算得到一个加权的记忆汇总向量rt,计算如下:
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第7张图片](http://img.e-com-net.com/image/info8/4dccab0e2f0c4db8b63e68e17ece4dcf.jpg)
Memory Write:对于记忆存储部分,首先通过与记忆读取相似的过程,得到权重向量wwt,然后通过如下的方式对记忆进行更新:
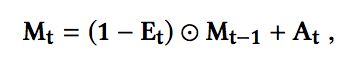
其中:
![]()
![]()
at代表添加向量,et代表擦除向量,圆圈+点代表点积(这里叫哈达玛积更为合适),圆圈+乘代表外积。
3.2 Memory Utilization Regularization
使用基本的NTM结构,热门的商品会出现在多个用户的行为数据中并主导memory的更新,使得memory的使用效率不高,为了提高memory的使用效率,论文提出了Memory Utilization Regularization,其主要的思想是对不同slot写入权重的方差进行约束。(符号不好打,下文是PPT的截图):
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第8张图片](http://img.e-com-net.com/image/info8/cf411fb2af2e4ed8aa861a36471246ce.jpg)
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第9张图片](http://img.e-com-net.com/image/info8/87e6fbe1375647c4b735d69b3466667b.jpg)
可以看到,辅助loss就是约束不同slot的调整后的写入权重的方差。
3.3 Memory Induction Unit
NTM的memory通常用来存储原始数据信息,忽略了对更高阶信息的捕捉,如用户兴趣的演进过程,因此为了能更好的捕捉用户兴趣,MIMN设计了Memory Induction Unit (以下称作MIU)来捕捉用户兴趣的演化过程。
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第10张图片](http://img.e-com-net.com/image/info8/392a9cf99c344a9198eaa71aa758f3b3.jpg)
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第11张图片](http://img.e-com-net.com/image/info8/8061c06c86b44fc08aed394bbb9f2ff1.jpg)
这里,将每一个slot当作一个兴趣轨道,在t时刻MIU选择K个兴趣轨道进行演化,每个轨道采用GRU结构来进行演化计算:
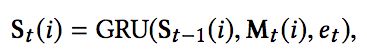
其中,et是用户t时刻的行为向量(这里看了代码感觉还是应该用Mt-1)。
3.4 线上服务
MIMN的设计初衷还是为了解决在使用长用户行为序列时的数据存储和线上预测耗时问题,那么本节来介绍下如何解决的。其线上应用如下图所示:
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第12张图片](http://img.e-com-net.com/image/info8/f5c935d35a8148feb54c4d2264dd983d.jpg)
如上图,将MIU和NTM模块统一到了UIC server中,对于每个用户来说,TAIR中不再直接存储用户的行为序列,而是存储NTM模块中的记忆矩阵M,以及兴趣演化矩阵S。当用户访问系统时,从TAIR中读取M和S,并计算最终的点击率预估值,线上仅需要如下图红圈中的部分:
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第13张图片](http://img.e-com-net.com/image/info8/6df78130148542d48cc61a93ac39a6ee.jpg)
而当新的用户行为发生时,UIC server通过MIU和NTM模块快速队S和M进行更新,并重新写入TAIR中。
那么在使用UIC server之后,实时点击率预估的架构变为如下:
![推荐系统遇上深度学习(八十五)-[阿里]长用户行为序列建模探索:MIMN_第14张图片](http://img.e-com-net.com/image/info8/8c0f953a5fc346a38a4d0621b9c65c8a.jpg)
前述两方面的挑战是否解决了呢?答案是肯定的:
1)使用长度为1000的用户行为序列,当QPS为500时,DIEN的平均耗时是200ms,而MIMN的平均耗时是19ms
2)存储长度为1000的用户行为序列,存储原始行为序列需要6T空间,而存储M和S矩阵只需要2.7TB
实验结果部分咱们就不写了,这篇也写的足够长了,需要一段时间来消化啦。
4、总结
本文引入了NTM来存储和更新用户长期兴趣表达,并通过MIC来刻画用户兴趣的演化过程,一定程度上解决了长用户序列建模的难题,同时减少了特征存储空间。在线上应用时,通过UIC(User Interest Center) Server与线上预测过程解耦,以达到降低预测耗时的目的。但该模型使用的场景也是比较局限的,最主要的就是要有足够长的用户行为序列数据,一般的场景下是不符合模型使用场景的。不过这种模型拆解的思路,给大家在解决线上耗时难题时提供了一定的借鉴。
推荐系统遇上深度学习(八十四)-[阿里]抽取用户多维度兴趣的DHAN网络介绍
2020-06-06

推荐系统遇上深度学习(八十三)-[阿里]记忆增强网络—MA-DNN模型介绍
2020-05-23

