《剑指offer》题解——week5(持续更新)
❤ 作者主页:Java技术一点通的博客
❀ 个人介绍:大家好,我是Java技术一点通!( ̄▽ ̄)~*
❀ 微信公众号:Java技术一点通
记得点赞、收藏、评论⭐️⭐️⭐️
认真学习!!!
文章目录
- 一、剑指 Offer 44. 数字序列中某一位的数字
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 二、剑指 Offer 45. 把数组排成最小的数
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 三、剑指 Offer 46. 把数字翻译成字符串
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 四、剑指 Offer 47. 礼物的最大价值
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 五、剑指 Offer 48. 最长不含重复字符的子字符串
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 六、剑指 Offer 49. 丑数
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 七、剑指 Offer 50. 第一个只出现一次的字符
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 八、剑指 Offer 51. 数组中的逆序对
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 九、剑指 Offer 52. 两个链表的第一个公共节点
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 十、剑指 Offer 53 - I. 在排序数组中查找数字 I
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
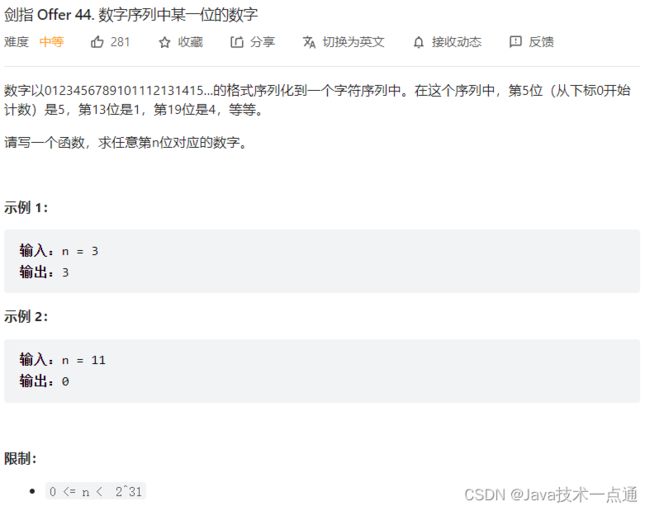
一、剑指 Offer 44. 数字序列中某一位的数字
1. 题目描述
2. 思路分析
解题思路:
- 将 101112... 101112... 101112... 中的每一位称为 数位,记为 n n n;
- 将 10 , 11 , 12 , . . . 10, 11, 12, ... 10,11,12,... 称为 数字 ,记为 n u m num num;
- 数字 10 10 10 是一个两位数,称此数字的 位数 为 2,记为 d i g i t digit digit;
- 每 d i g i t digit digit 位数的起始数字(即:1,10,100,…),记为 s t a r t start start。
通过推算可以发现:
位数递推公式: d i g i t = d i g i t + 1 digit = digit + 1 digit=digit+1
起始数字递推公式: s t a r t = s t a r t × 10 start = start \times 10 start=start×10
数位数量计算公式: c o u n t = 9 × s t a r t × d i g i t count = 9 \times start \times digit count=9×start×digit
算法流程:
- 确定 n n n 所在 数字 的 位数 ,记为 d i g i t digit digit :
循环执行 n n n 减去 一位数、两位数、… 的数位数量 c o u n t count count ,直至 n ≤ c o u n t n \leq count n≤count 时跳出。
由于 n n n 已经减去了一位数、两位数、…、 ( d i g i t − 1 ) (digit−1) (digit−1) 位数的 数位数量 c o u n t count count ,因而此时的 n n n是从起始数字 s t a r t start start 开始计数的。 - 确定 n n n 所在的 数字 ,记为 n u m num num :
所求数位 在从数字 s t a r t start start 开始的第 [ ( n − 1 ) / d i g i t ] [(n - 1) / digit] [(n−1)/digit] 个数字中( s t a r t start start 为第 0 个数字)。 - 确定 n n n 是 n u m num num 中的哪一数位,并返回结果。
所求数位为数字 n u m num num 的第 [ ( n − 1 ) % d i g i t ] [(n - 1) \% digit] [(n−1)%digit] 位( 数字的首个数位为第 0 位)。
3. 代码实现
class Solution {
public:
int findNthDigit(int n) {
long long start = 1, count = 9, digit = 1;
while (n > count) {
n -= count;
digit ++;
start *= 10;
count = 9 * start * digit;
}
long long num = start + (n - 1) / digit;
long long index = (n - 1) % digit;
string s = to_string(num);
int ans = s[index] - '0';
return ans;
}
};
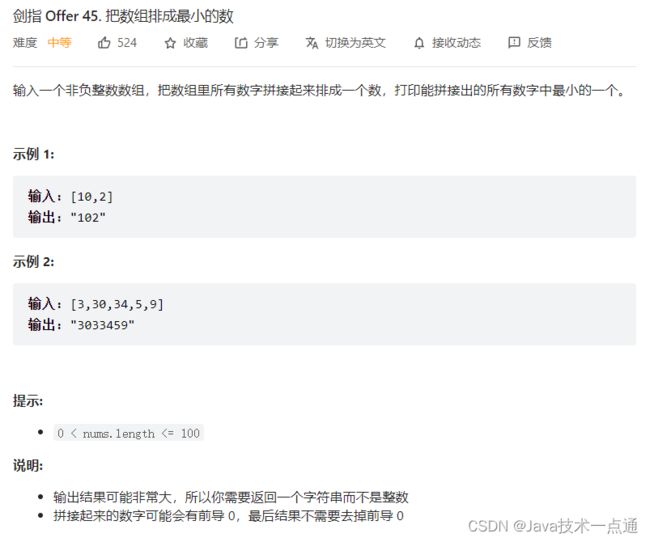
二、剑指 Offer 45. 把数组排成最小的数
1. 题目描述
2. 思路分析
此题求拼接起来的最小数字,本质上是一个排序问题。设数组 n u m s nums nums 中任意两数字的字符串为 x x x 和 y y y ,则规定 排序判断规则 为:
- 若拼接字符串 x + y > y + x x+y>y+x x+y>y+x ,则 x x x “大于” y y y ;
- 若拼接字符串 x + y < y + x x+y
x x x “小于” y y y 代表:排序完成后,数组中 x x x 应在 y y y 左边;“大于” 则反之。
算法流程:
- 初始化: 定义字符串列表 s t r str str, 保存各数字的字符串格式;
- 列表排序: 使用“排序判断规则”,对 s t r str str执行排序;
- 返回值: 拼接 s t r str str中的所有字符串,并返回。
3. 代码实现
class Solution {
public:
static bool cmp(string a, string b) {
return a + b < b + a;
}
string minNumber(vector& nums) {
vector str;
for (auto num : nums) str.push_back(to_string(num));
sort(str.begin(), str.end(), cmp);
string res;
for (auto num : str) res += num;
return res;
}
};
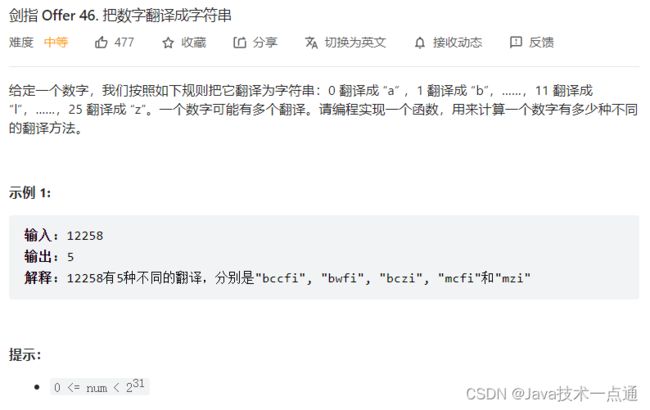
三、剑指 Offer 46. 把数字翻译成字符串
1. 题目描述
2. 思路分析
动态规划:
- 状态定义: 设动态规划列表 d p dp dp, d p [ i ] dp[i] dp[i]表示以 x i x_i xi 为结尾的数字的翻译方案数量。
- 转移方程: 若 x i x_i xi 和 x i − 1 x_{i - 1} xi−1 组成的两位数字可以被翻译,则
dp[i] = dp[i - 1] + dp[i - 2];否则dp[i] = dp[i - 1]。
可被翻译的两位数的区间:当 x i − 1 = 0 x_{i - 1} = 0 xi−1=0时,组成的两位数是无法被翻译的(例如00,01,……),因此区间为 [ 10 , 25 ] [10, 25] [10,25]。
- 初始化: d p [ 0 ] = d p [ 1 ] = 1 dp[0] = dp[1] = 1 dp[0]=dp[1]=1,即 “无数字” 和 “第 1位数字” 的翻译方法数量均为 1 。
无数字情况 d p [ 0 ] = 1 dp[0]=1 dp[0]=1 ?
当 n u m num num 第 1,2 位的组成的数字 ∈ [ 10 , 25 ] ∈[10,25] ∈[10,25] 时,显然应有 2 种翻译方法,即 d p [ 2 ] = d p [ 1 ] + d p [ 0 ] = 2 dp[2]=dp[1]+dp[0]=2 dp[2]=dp[1]+dp[0]=2 ,而显然 d p [ 1 ] = 1 dp[1]=1 dp[1]=1 ,因此推出 d p [ 0 ] = 1 dp[0]=1 dp[0]=1 。
- 返回值: d p [ n ] dp[n] dp[n],即数字的翻译方案数量。
3. 代码实现
class Solution {
public:
int translateNum(int num) {
string s = to_string(num);
int n = s.size();
vector f(n + 1);
f[0] = 1, f[1] = 1;
for (int i = 2; i <= n; i ++ ) {
int t = (s[i - 2] - '0') * 10 + s[i - 1] - '0';
if (t >= 10 && t <= 25) f[i] = f[i - 1] + f[i - 2];
else f[i] = f[i - 1];
}
return f[n];
}
};
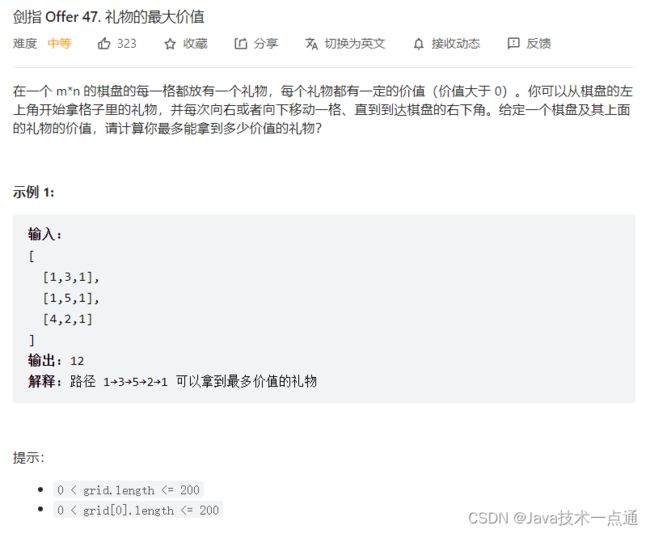
四、剑指 Offer 47. 礼物的最大价值
1. 题目描述
2. 思路分析
动态规划:
- 状态定义: 设动态规划矩阵 d p dp dp , d p ( i , j ) dp(i,j) dp(i,j) 代表从棋盘的左上角 ( 1 , 1 ) (1,1) (1,1) 开始,到达单元格 ( i − 1 , j − 1 ) (i - 1,j - 1) (i−1,j−1)时能拿到礼物的最大累计价值。
- 转移方程: f [ i ] [ j ] = m a x ( f [ i − 1 ] [ j ] , f [ i ] [ j − 1 ] ) + g r i d [ i − 1 ] [ j − 1 ] f[i][j] = max(f[i - 1][j], f[i][j - 1]) + grid[i - 1][j - 1] f[i][j]=max(f[i−1][j],f[i][j−1])+grid[i−1][j−1]
- 初始化: 下标 i i i、 j j j都从1开始;
- 返回值: d p [ n ] [ m ] dp[n][m] dp[n][m], m m m, n n n 分别为矩阵的行高和列宽,即返回 d p dp dp 矩阵右下角元素。
3. 代码实现
class Solution {
public:
int maxValue(vector>& grid) {
int n = grid.size(), m = grid[0].size();
vector> f(n + 1, vector(m + 1, 0));
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
f[i][j] = max(f[i - 1][j], f[i][j - 1]) + grid[i - 1][j - 1];
return f[n][m];
}
};
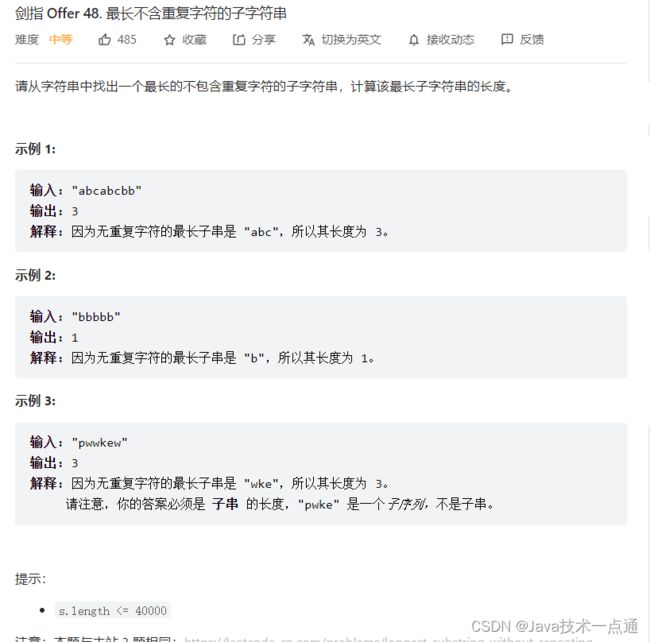
五、剑指 Offer 48. 最长不含重复字符的子字符串
1. 题目描述
2. 思路分析
双指针 + 哈希表:
定义两个指针 i i i, j j j ( i < = j ) (i <= j) (i<=j), 表示当前扫描到的子串是 [ i , j ] [i,j] [i,j](闭区间)。扫描过程中维护一个哈希表unorderes_map, 表示 [ i , j ] [i,j] [i,j]中每个字符出现的个数。
线性扫描,每次循环的流程如下:
- 指针 j j j向后移一位,同时将哈希表中 s [ j ] s[j] s[j] 的计数加一:
hash[s[j]] ++; - 假设 j j j移动前的区间 [ i , j ] [i,j] [i,j]中没有重复字符,则 j j j移动后,只有 s [ j ] s[j] s[j]可能出现2次。因此我们不断向后移动 i i i,直至区间 [ i , j ] [i,j] [i,j]中 s [ j ] s[j] s[j]的个数等于1为止。
3. 代码实现
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_map hash;
int res = 0;
for (int i = 0, j = 0; i < s.size(); i ++ ) {
hash[s[i]] ++;
while (hash[s[i]] > 1) hash[s[j ++]] --;
res = max(res, i - j + 1);
}
return res;
}
};
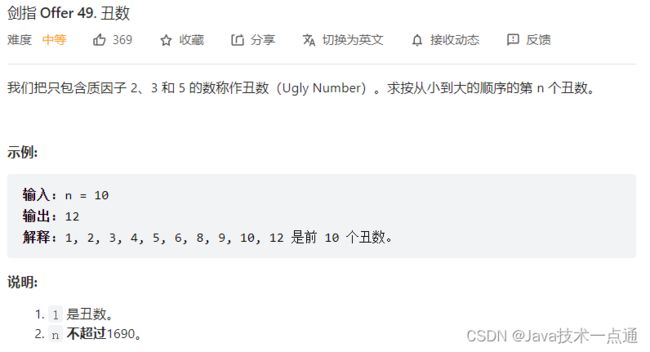
六、剑指 Offer 49. 丑数
1. 题目描述
2. 思路分析
丑数的递推性质: 丑数只包含因子 2, 3, 5 ,因此有 “丑数 = 某较小丑数 × 某因子” (例如:10 = 5 x 2)。
设已知长度为 n n n 的丑数序列 x 1 x_1 x1, x 2 x_2 x2, … x n x_n xn,求第 n + 1 n + 1 n+1 个丑数 x n + 1 x_{n + 1} xn+1。根据递推性质,丑数 x n + 1 x_{n + 1} xn+1 只可能是一下三种情况其中之一(索引 a a a, b b b, c c c为未知数):
x n + 1 = { x a × 2 , a ∈ [ 1 , n ] x b × 3 , b ∈ [ 1 , n ] x c × 5 , c ∈ [ 1 , n ] x_{n + 1} =\begin{cases} x_a \times 2 ,& a∈[1,n] \\ x_b \times 3 ,& b∈[1,n] \\ x_c \times 5 ,& c∈[1,n] \end{cases} xn+1=⎩ ⎨ ⎧xa×2,xb×3,xc×5,a∈[1,n]b∈[1,n]c∈[1,n]
丑数递推公式: 若索引 a , b , c a,b,c a,b,c 满足以上条件,则下个丑数 x n + 1 x_{n+1} xn+1 为以下三种情况中的 最小值 :
即 x n + 1 x_{n+1} xn+1 = min( x a x_a xa × \times × 2, x b x_b xb × \times × 3, x c x_c xc × \times × 5)
动态规划:
-
状态定义: 设动态规划列表 d p dp dp, d p [ i ] dp[i] dp[i]代表第 i + 1 i + 1 i+1 个丑数;
-
状态方程: 每轮计算 d p [ i ] dp[i] dp[i]后,需要更新索引 a , b , c a, b, c a,b,c的值,使其始终满足方程条件。实现方法:分别独立判断 d p [ i ] dp[i] dp[i] 和 d p [ a ] × 2 , d p [ b ] × 3 , d p [ c ] × 5 dp[a] \times 2, dp[b] \times 3, dp[c] \times 5 dp[a]×2,dp[b]×3,dp[c]×5 的大小关系,若相等则将对应索引 a , b , c a, b, c a,b,c 加 1;
d p [ i ] = m i n ( d p [ a ] × 2 , d p [ b ] × 3 , d p [ c ] × 5 ) dp[i] = min(dp[a] \times 2, dp[b] \times 3, dp[c] \times 5) dp[i]=min(dp[a]×2,dp[b]×3,dp[c]×5)
-
初始化: d p [ 0 ] = 1 dp[0] = 1 dp[0]=1,即第一个丑数为 1;
-
返回值: d p [ n − 1 ] dp[n - 1] dp[n−1],即返回第 n n n 个丑数。
3. 代码实现
class Solution {
public:
int nthUglyNumber(int n) {
int a = 0, b = 0, c = 0;
int dp[n];
dp[0] = 1;
for (int i = 1; i < n; i ++ ) {
int n2 = dp[a] * 2, n3 = dp[b] * 3, n5 = dp[c] * 5;
dp[i] = min(min(n2, n3), n5);
if (dp[i] == n2) a ++;
if (dp[i] == n3) b ++;
if (dp[i] == n5) c ++;
}
return dp[n - 1];
}
};
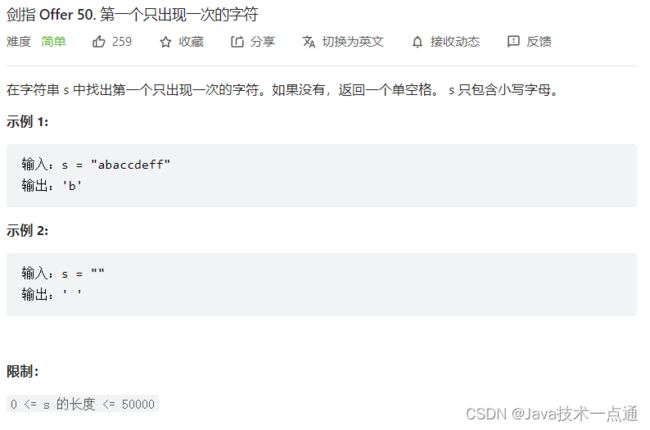
七、剑指 Offer 50. 第一个只出现一次的字符
1. 题目描述
2. 思路分析
哈希表:
- 遍历字符串 s s s,使用哈希表
unordered_map统计各字符出现的次数; - 再遍历字符串 s s s,在哈希表中找到首个 ”次数为1的字符“,并返回。
3. 代码实现
class Solution {
public:
char firstUniqChar(string s) {
unordered_map hash;
for (auto c : s) hash[c] ++;
char res = ' ';
for (auto c : s) {
if (hash[c] == 1) {
res = c;
break;
}
}
return res;
}
};
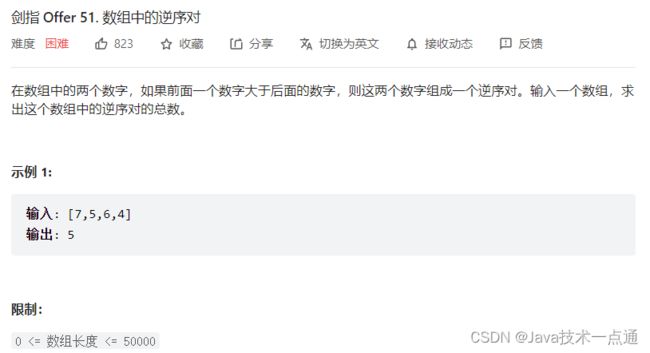
八、剑指 Offer 51. 数组中的逆序对
1. 题目描述
2. 思路分析
「归并排序」 与 「逆序对」 是息息相关的。归并排序体现了 “分而治之” 的算法思想,具体为:
- 分: 不断将数组从中点位置划分开(即二分法),将整个数组的排序问题转化为子数组的排序问题;
- 治: 划分到子数组长度为 1 时,开始向上合并,不断将 较短排序数组 合并为 较长排序数组,直至合并至原数组时完成排序;
算法流程:
merge_sort() 归并排序与逆序对统计:
-
终止条件: 当 l ≥ r l \geq r l≥r 时,代表子数组长度为 1 ,此时终止划分;
-
递归划分: 计算数组中点 m i d mid mid ,递归划分左子数组
merge_sort(l, mid)和右子数组merge_sort(mid + 1, r); -
合并与逆序对统计:
-
暂存数组 n u m s nums nums 闭区间 [ l , r ] [l,r] [l,r] 内的元素至辅助数组 t m p tmp tmp ;
-
循环合并: 设置双指针 i , j i , j i,j 分别指向左 / 右子数组的首元素;
- 左子数组和右子数组还可以合并的条件是:
i <= mid && j <= r - 当 t m p [ i ] ≤ t m p [ j ] tmp[i] \leq tmp[j] tmp[i]≤tmp[j] 时: 添加左子数组当前元素 t m p [ i ] tmp[i] tmp[i] ,并执行 i = i + 1 i = i + 1 i=i+1;
- 否则(即 t m p [ i ] > t m p [ j ] tmp[i] > tmp[j] tmp[i]>tmp[j])时: 添加右子数组当前元素 t m p [ j ] tmp[j] tmp[j] ,并执行 j = j + 1 j = j + 1 j=j+1 ;此时构成 m i d − i + 1 mid - i + 1 mid−i+1 个 「逆序对」,统计添加至 r e s res res ;
- 左子数组和右子数组还可以合并的条件是:
-
-
返回值: 返回直至目前的逆序对总数 r e s res res 。
3. 代码实现
class Solution {
public:
int reversePairs(vector& nums) {
return merge(nums, 0, nums.size() - 1);
}
int merge(vector& nums, int l, int r) {
if (l >= r) return 0;
int mid = (l + r) / 2;
int res = merge(nums, l, mid) + merge(nums, mid + 1, r);
vector temp;
int i = l, j = mid + 1;
while (i <= mid && j <= r)
if (nums[i] <= nums[j]) temp.push_back(nums[i ++ ]);
else {
temp.push_back(nums[j ++ ]);
res += mid - i + 1;
}
while (i <= mid) temp.push_back(nums[i ++ ]);
while (j <= r) temp.push_back(nums[j ++ ]);
int k = l;
for (auto x : temp) nums[k ++ ] = x;
return res;
}
};
九、剑指 Offer 52. 两个链表的第一个公共节点
1. 题目描述

2. 思路分析
双指针:
设「第一个公共节点」为 n o d e node node ,「链表 h e a d A headA headA」的节点数量为 a a a ,「链表 h e a d B headB headB」的节点数量为 b b b,「两链表的公共尾部」的节点数量为 c c c ,则有:
- 头节点 h e a d A headA headA 到 n o d e node node 前,共有 a − c a - c a−c 个节点;
- 头节点 h e a d B headB headB 到 n o d e node node 前,共有 b − c b - c b−c 个节点;
算法流程:
-
考虑构建两个节点指针 p p p , q q q 分别指向两链表头节点 h e a d A headA headA, h e a d B headB headB ,做如下操作:
- 指针 p p p 先遍历完链表 h e a d A headA headA,再开始遍历链表 h e a d B headB headB ,当走到 n o d e node node 时,共走步数为:
a + ( b − c ) a + (b - c) a+(b−c) - 指针 q q q 先遍历完链表 h e a d B headB headB,再开始遍历链表 h e a d A headA headA ,当走到 n o d e node node 时,共走步数为:
b + ( a − c ) b + (a - c) b+(a−c)
- 指针 p p p 先遍历完链表 h e a d A headA headA,再开始遍历链表 h e a d B headB headB ,当走到 n o d e node node 时,共走步数为:
-
即 a + ( b − c ) = b + ( a − c ) a+(b−c)=b+(a−c) a+(b−c)=b+(a−c),此时指针 p p p , q q q 重合,并有两种情况:
- 若两链表 有 公共尾部 (即 c > 0 c > 0 c>0 ) :指针 p p p , q q q 同时指向「第一个公共节点」 n o d e node node 。
- 若两链表 无 公共尾部 (即 c = 0 c = 0 c=0 ) :指针 p p p , q q q 同时指向 n u l l null null。
-
**返回值:**直接返回指针 p p p即可。
3. 代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
auto p = headA, q = headB;
while (p != q) {
if (p) p = p->next;
else p = headB;
if (q) q = q->next;
else q = headA;
}
return p;
}
};
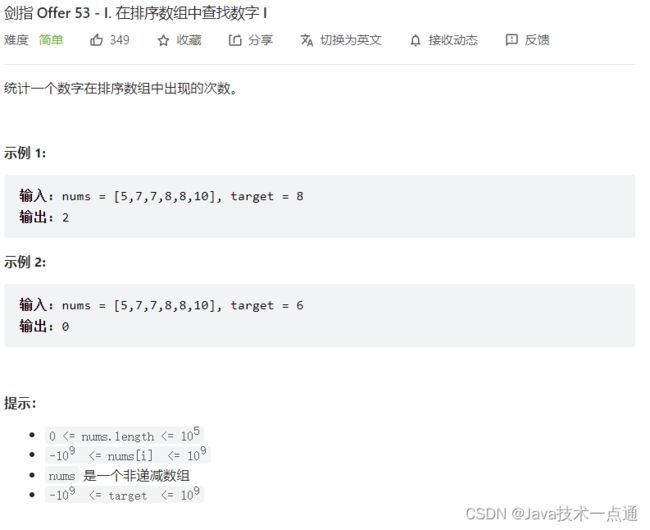
十、剑指 Offer 53 - I. 在排序数组中查找数字 I
1. 题目描述
2. 思路分析
直观的思路肯定是从前往后遍历一遍。用两个变量记录第一次和最后一次遇见 t a r g e t target target 的下标,但这个方法的时间复杂度为 O ( n ) O(n) O(n),没有利用到数组升序排列的条件。
由于数组已经排序,因此整个数组是单调递增的,我们可以利用二分法来加速查找的过程。
考虑 t a r g e t target target 在数组中出现的次数,其实我们要找的就是数组中 「第一个等于 t a r g e t target target 的位置」(记为 l e f t left left)和 「最后一个等于 t a r g e t target target 的位置」(记为 r i g h t right right)。当 t a r g e t target target 在数组中存在时, t a r g e t target target 在数组中出现的次数为 r i g h t − l e f t + 1 right- left + 1 right−left+1 。
3. 代码实现
class Solution {
public:
int search(vector& nums, int target) {
if (nums.empty()) return 0;
int l = 0, r = nums.size() - 1;
while (l < r) {
int mid = (l + r) / 2;
if (nums[mid] >=target) r = mid;
else l = mid + 1;
}
int left = l;
if (nums[r] !=target) return 0;
l = 0, r = nums.size() - 1;
while (l < r) {
int mid = (l + r + 1) / 2;
if (nums[mid] <=target) l = mid;
else r = mid - 1;
}
int right = r;
return right - left + 1;
}
};
创作不易,如果有帮助到你,请给文章点个赞和收藏,让更多的人看到!!!
关注博主不迷路,内容持续更新中。