剑指Offer week 0
1.二维数组的查找

本人看到后的第一想法是,一列一列查找,怎么查呢,先判断每一列的第一个元素的大小,若比目标小,就开始对这列进行对比,在没有找到目标前遇到比目标大的就跳出去,继续下一列,若在没有找到前列的首元素大于目标就直接return。
运行时间:13ms 占用内存:1824KB
class Solution {
public:
bool Find(int target, vector<vector<int> > array) {
int r = array.size();
int c = array[0].size();
for (int j = 0; j < c; j++) {
int t = 0;
while (t < r && array[t][j] < target) {
t++;
}
if (t < r && array[t][j] == target) {
return true;
} else {
continue;
}
}
return false;
}
};
从右上向左下查找慢慢逼近,这是看了秀哥的笔记后才了解的,当看到这句话的时候就想到了整个过程,就自己实现了一下,然后对比了秀哥的代码,然后又对比了其他的代码,发现有时候改变if语句的优先顺序,也可以让程序快不少
运行时间:12ms 占用内存:1792KB
class Solution {
public:
bool Find(int target, vector<vector<int> > array) {
int r = array.size();
int c = array[0].size();
int i = 0, j = c - 1;
while (i < r && j >= 0) {
if (array[i][j] < target) {
i++;
continue;
} else if (array[i][j] > target) {
j--;
continue;
} else {
return true;
}
}
return false;
}
};
2.替换空格
实现思路:
运行时间:4ms 占用内存:548KB
实现代码:
class Solution {
public:
void replaceSpace(char *str,int length) {
int space_count = 0;
for (int i = 0; i < length; i++) {
if (str[i] == ' ') {
space_count++;
}
}
int add_len = length + 2 * space_count;
for (int i = length - 1; add_len != i && i >= 0; i--) {
if (str[i] != ' ') {
str[--add_len] = str[i];
} else {
str[--add_len] = '0';
str[--add_len] = '2';
str[--add_len] = '%';
}
}
}
};
// 利用标准库
class Solution {
public:
void replaceSpace(char *str,int length) {
string rev, s = str;
for (char c : s) {
if (c == ' ') rev += "%20";
else rev += c;
}
strcpy(str, rev.c_str());
}
};
3.从头到尾打印链表

/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) :
* val(x), next(NULL) {
* }
* };
*/
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
if (!head) return vector<int>();
vector<int> ans;
while(head) {
ans.push_back(head->val);
head = head->next;
}
reverse(ans.begin(), ans.end());
return ans;
}
};
4.重建二叉树(二刷错误)

第一感觉是我会,之前在大二上的时候学过,根据前序,中序复原二叉树,然后画图整理了思路,敲代码的时候傻眼了,不会写我去,太长时间没写过类似的了,一些基本的stl函数都忘了。。。
运行时间:4ms 占用内存:536KB
根据前序中序可得到唯一的二叉树
/**
* Definition for binary tree
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* reConstructBinaryTree(vector<int> pre,vector<int> vin) {
if (pre.size() == 0 || vin.size() == 0) { // 递归结束的条件
return nullptr;
}
TreeNode* root = new TreeNode(pre[0]);
int mid = distance(vin.begin(), find(vin.begin(), vin.end(), pre[0]));
vector<int> left_vin(vin.begin(), vin.begin() + mid);
vector<int> right_vin(vin.begin() + mid + 1, vin.end());
vector<int> left_pre(pre.begin() + 1, pre.begin() + mid + 1);
vector<int> right_pre(pre.begin() + mid + 1, pre.end());
root->left = reConstructBinaryTree(left_pre, left_vin);
root->right = reConstructBinaryTree(right_pre, right_vin);
return root;
}
};
5.两个栈实现队列
运行时间:6ms 占用内存:608KB
class Solution
{
public:
void push(int node) {
stack1.push(node);
}
int pop() {
// 将元素放入stack2
while (stack1.size() != 1) {
stack2.push(stack1.top());
stack1.pop();
}
// 要返回的 “队头”
int ans = stack1.top();
stack1.pop();
// 将剩余元素放入stack1
while(!stack2.empty()) {
stack1.push(stack2.top());
stack2.pop();
}
return ans;
}
private:
stack<int> stack1;
stack<int> stack2;
};
6.旋转数组的最小数字
乍一看蒙了,这是让干啥?比较大小?这么简单?然后再仔细看题,非降序数组,然后将开始的若干个元素搬到尾巴,找出最小值
观察后,那思路就很清晰了,遍历找到第一次出现num[i] > num[i+1]的时候,那么后者就是答案;没有的话就返回第一个值
class Solution {
public:
int minNumberInRotateArray(vector<int> rotateArray) {
int len = rotateArray.size();
if (1 == len) return rotateArray[0];
for (int i = 0; i < len - 1; i++) {
if (rotateArray[i] > rotateArray[i + 1]) return rotateArray[i + 1];
}
return rotateArray[0];
}
};
还有一种是假设旋转后的第一个元素为最小值min_num,然后遍历比较,第一次出现比min_num更小的元素即为答案。
class Solution {
public:
int minNumberInRotateArray(vector<int> rotateArray) {
int len = rotateArray.size();
if (1 == len) return rotateArray[0];
for (int i = 0; i < len - 1; i++) {
if (rotateArray[i] > rotateArray[i + 1]) return rotateArray[i + 1];
}
return rotateArray[0];
}
};
二分,看完秀哥的笔记后学到的
记得二分是适用于有序的,但这里应该是旋转后分为两部分且也是有序的,也相当于变相有序了
class Solution {
public:
int minNumberInRotateArray(vector<int> rotateArray) {
if (rotateArray.size() == 1) return rotateArray[0];
int low = 0, high = rotateArray.size() - 1;
while (low < high) {
int mid = low + (high - low) / 2; // 这里是避免 直接相加导致溢出,较好的写法
if (rotateArray[mid] < rotateArray[high]) { // 右边是有序的
high = mid; // 那么最小值只能在左边
} else if (rotateArray[mid] == rotateArray[high]) {
high -= 1;
} else { // [mid] > [high]说明 当前最小值在它俩之间
low = mid + 1;
}
}
return rotateArray[low];
}
};
7.斐波那契数列

首先想到的是递归,看了之后太慢
运行时间:306ms 占用内存:540KB
class Solution {
public:
int Fibonacci(int n) {
if (n == 0) return 0;
if (n == 1 || n == 2) return 1;
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
};
开了3个元素,嗯快了不少
运行时间:5ms 占用内存:528KB
class Solution {
public:
int Fibonacci(int n) {
if (n == 1 || n == 2) return 1;
int first = 1, second = 1, ans = 0;
for (int i = 3; i <= n; i++) { // 这里只需要注意first与second变量的修改顺序即可
ans = first + second;
first = second;
second = ans;
}
return ans;
}
};
8.跳台阶

这个已经做过好多次了,跟斐波那契数列是同样思路
class Solution {
public:
int jumpFloor(int number) {
if (1 == number) return 1;
if (2 == number) return 2;
vector<int> dp(number + 1);
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= number; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[number];
}
};
9.跳台阶扩展
一开始还是想到dp,
得到公式 dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3] + … + dp[1]
而dp[i - 1] = dp[i - 2] + dp[i - 3] + … +dp[1] ==> dp[i] = 2 * dp[i - 1]
class Solution {
public:
int jumpFloorII(int number) {
if (1 == number) return 1;
vector<int> dp(number + 1);
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= number; i++) {
dp[i] = 2 * dp[i - 1];
}
return dp[number];
}
};
然后看了秀哥的笔记,嗯,很暴力哈,找规律
class Solution {
public:
int jumpFloorII(int number) {
return pow(2, number - 1);
}
};
10.矩阵覆盖

很简单,画图找规律就行,斐波那契同样的思路
class Solution {
public:
int rectCover(int number) {
if (number <= 2) return number;
int first = 1, second = 2;
int ans = 0;
for (int i = 3; i <= number; i++) {
ans = first + second;
first = second;
second = ans;
}
return ans;
}
};
11.二进制中1的个数
当看到这题的时候就想到了通过移位计算
然后敲代码,运行,好嘛,直接超时
class Solution { // 错误思路,不断右移n,但忽略了负数补码的补位问题
public:
int NumberOf1(int n) {
int cnt = 0;
while (n) {
if ((n & 1) == 1) {
cnt++;
}
n >>= 1;
}
return cnt;
}
};
思考了一会,想到计算机中是以补码存储的,正数是没问题的,因为它右移补0,但负数补码右移是补1的,所以,-1的时候就是死循环。既然传入的数不能移位,换个思路,将比较的数移位,又因为是一个int,比较32次即可,略作修改,OK通过
运行时间:4ms 占用内存:556KB
class Solution {
public:
int NumberOf1(int n) {
int sum = 32, cnt = 0;
while (sum--) {
if ((n & 1) == 1) {
cnt++;
}
n >>= 1;
}
return cnt;
}
};
看到官方有个扩展思路
根据 n&(n-1),会将n的二进制中最低位由1变成0,所以n会越来越小,直到为0,因此记录计算的次数即可
class Solution {
public:
int NumberOf1(int n) {
int cnt = 0;
while (n) {
n &= n-1;
cnt++;
}
return cnt;
}
};
然后看了秀哥的笔记,看到了bitset,平时没用过,就去学了学
bitset是将传入的数,显示指定的二进制位数,如果32位能够表达的数小于n,则取其低位,大,则前面补0
count()则是返回二进制中1的个数
class Solution {
public:
int NumberOf1(int n) {
bitset<32> bit(n);
return bit.count();
}
};
12.数值的整数次方

除了特判,就注意负数需要求倒数即可
运行时间:3ms 占用内存:600KB
class Solution {
public:
double Power(double base, int exponent) {
// 特判
if (0 == base) return 0.0;
if (0 == exponent) return 1.0;
int flag = false; // 记录符号是否为负
if (exponent < 0) {
flag = true;
exponent *= -1;
}
double ans = base;
for (int i = 2; i <= exponent; i++) {
ans *= base;
}
if (flag) {
ans = 1 / ans;
}
return ans;
}
};
然后去看了秀哥的做法,提到了快速幂,记得以前写过快速幂,但是忘了,又去看了看其他人的笔记
算法学习笔记(4):快速幂 (侵删)
class Solution {
public:
double Power(double base, int exponent) {
// 非递归快速幂
double ans = 1.0;
bool flag = false;
if (exponent < 0) {
flag = true;
exponent *= -1;
}
while (exponent) {
if (exponent % 2 == 1) ans *= base;
base *= base;
exponent /= 2;
}
if (flag) {
ans = 1 / ans;
}
return ans;
}
};
13.调整数组顺序使奇数位于偶数前面

法一:很暴力,再开出一个数组存储,然后在赋值回去
class Solution {
public:
void reOrderArray(vector<int> &array) {
int len = array.size();
if (len < 2) return;
vector<int> ans(len);
int index = 0;
for (int i = 0; i < len; i++) {
if (array[i] % 2 == 1) {
ans[index++] = array[i];
}
}
for (int i = 0; i < len; i++) {
if (array[i] % 2 == 0) {
ans[index++] = array[i];
}
}
array.assign(ans.begin(), ans.end());
}
};
法二:优化,只保留偶数部分
class Solution {
public:
void reOrderArray(vector<int> &array) {
int len = array.size();
vector<int> even; // 保留偶数的容器
int oddIndex = 0;
for (int i = 0; i < len; i++) {
if (array[i] % 2 == 1) { // 原容器先只保留奇数
array[oddIndex++] = array[i];
}
else {
even.push_back(array[i]);
}
}
// 追加偶数到原容器
for (int i = 0; i < even.size(); i++) {
array[oddIndex + i] = even[i];
}
}
};
法三:原地解法,类似冒泡的做法
class Solution {
public:
void reOrderArray(vector<int> &array) {
int len = array.size();
for (int i = 0; i <= len / 2; i++) {
for (int j = len - 1; j > i; j--) {
// 这样一轮下来之后,数组的首尾就满足要求了,接着向内扩展
if (array[j] % 2 == 0 && array[j - 1] % 2 == 1) {
swap(array[i], array[j - 1]);
}
}
}
}
};
14.链表中倒数第k个结点

第一眼就想到了怎么写,运行后也通过了,然后看了一眼题解,好么,都没人开空间么?果然还是我太low了
运行时间:3ms 占用内存:424KB
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
vector<ListNode*> vec;
while (pListHead) {
vec.push_back(pListHead);
pListHead = pListHead->next;
}
int index = vec.size() - k;
if (index < 0) {
return nullptr;
}
return vec[index];
}
};
优化改进,前后指针,让两个指针相差 k 步,前指针到达最后时,后指针即为所求
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
ListNode* preNode = pListHead;
ListNode* bckNode = pListHead;
while (k--) {
if (preNode) {
preNode = preNode->next;
} else { // 当 k 大于单链表的长度
return nullptr;
}
}
while (preNode) {
preNode = preNode->next;
bckNode = bckNode->next;
}
return bckNode;
}
};
15.反转链表

太长时间没写过链表,依稀记得有个原地反转的方法,然后过了
然后看了秀哥的笔记,想起来头插法,嗯好像看起来不太像
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* ReverseList(ListNode* pHead) {
if (!pHead) return nullptr;
ListNode* Node_A = pHead;
ListNode* Node_B = pHead->next;
while (Node_B) {
ListNode* tmp = Node_B->next;
Node_B->next = Node_A;
Node_A = Node_B;
Node_B = tmp;
}
pHead->next = nullptr;
return Node_A;
}
};
又看了题解,写了一边,正规头插
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* ReverseList(ListNode* pHead) {
if (!pHead || !pHead->next) return pHead;
ListNode* new_head = nullptr;
while (pHead) {
ListNode* node = pHead->next;
pHead->next = new_head;
new_head = pHead;
pHead = node;
}
return new_head;
}
};
16.合并两个有序链表
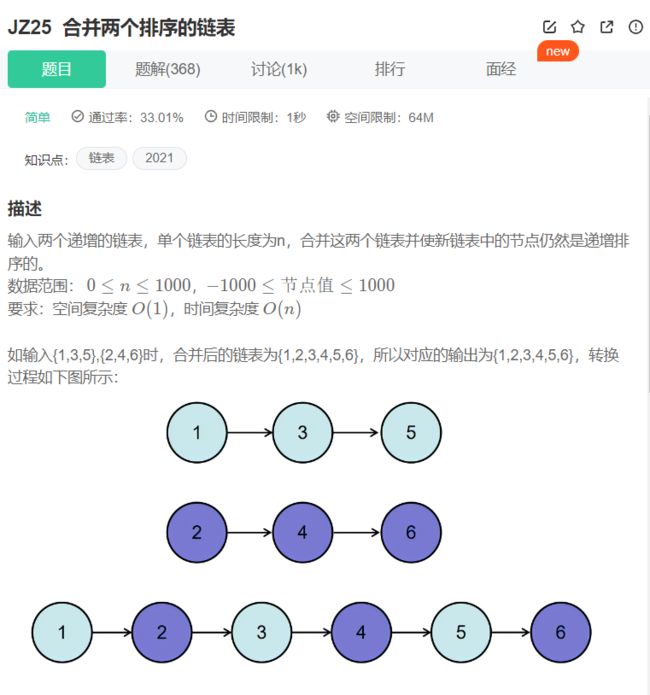
哎,有思路但死活做不出来的感觉真难受
运行时间:4ms 占用内存:604KB
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
ListNode* new_head = new ListNode(0);
ListNode* node = new_head;
while (pHead1 && pHead2) {
if (pHead1->val < pHead2->val) {
node->next = pHead1;
pHead1 = pHead1->next;
} else {
node->next = pHead2;
pHead2 = pHead2->next;
}
node = node->next;
}
if (pHead1) {
node->next = pHead1;
}
if (pHead2) {
node->next = pHead2;
}
return new_head->next;
}
};
17.树的子结构
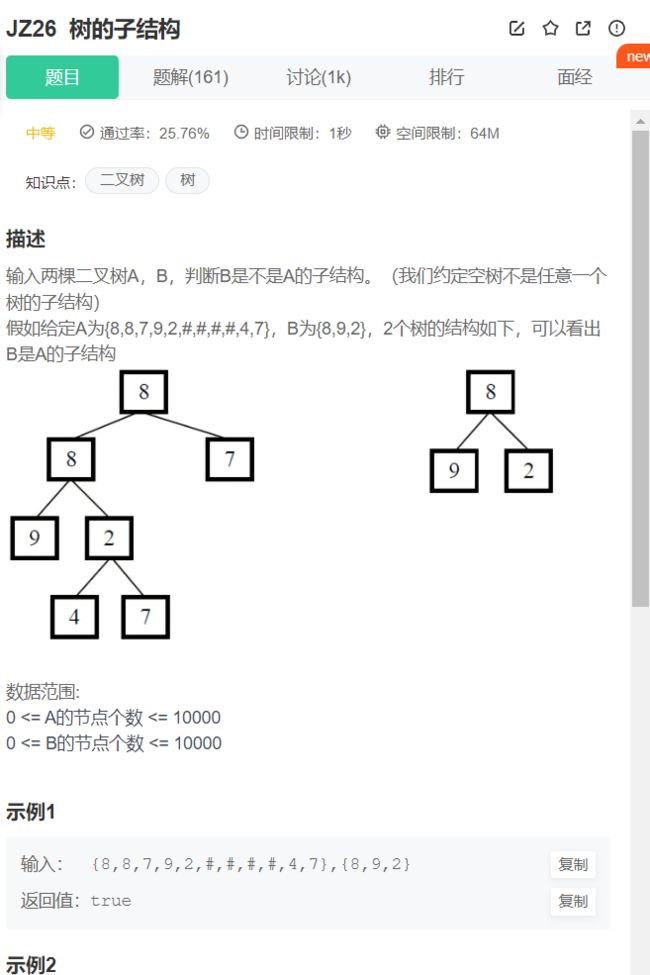
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
bool HasSubtree(TreeNode* pRoot1, TreeNode* pRoot2) {
if (pRoot1 == nullptr || pRoot2 == nullptr) return false;
bool result = false;
if (pRoot1->val == pRoot2->val) { // 第一步,在树1中找到与树2根节点相同的节点
result = isFind(pRoot1, pRoot2);
}
if (!result) { // 如果,当前节点不等于树2的根节点,就从左子树中找
result = HasSubtree(pRoot1->left, pRoot2);
}
if (!result) { // 如果,左子树没有节点等于树2的根节点,就从右子树中找
result = HasSubtree(pRoot1->right, pRoot2);
}
return result;
}
bool isFind(TreeNode* pRoot1, TreeNode* pRoot2) {
if (pRoot2 == nullptr) return true; // 递归结束条件
if (pRoot1 == nullptr) return false; // 当B不为空,而A为空,说明A没有B的节点
if (pRoot1->val != pRoot2->val) return false;
// 第二步,递归比较左右子树
return isFind(pRoot1->left, pRoot2->left) && isFind(pRoot1->right, pRoot2->right);
}
};
18.二叉树的镜像

递归实现
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return TreeNode类
*/
TreeNode* Mirror(TreeNode* pRoot) {
if (pRoot == nullptr) return nullptr;
swap(pRoot->left, pRoot->right);
Mirror(pRoot->left);
Mirror(pRoot->right);
return pRoot;
}
};
迭代版本
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return TreeNode类
*/
TreeNode* Mirror(TreeNode* pRoot) {
queue<TreeNode*> q;
TreeNode* node = nullptr;
q.push(pRoot);
while (!q.empty()) {
node = q.front();
q.pop();
if (node) {
q.push(node->left);
q.push(node->right);
swap(node->left, node->right);
}
}
return pRoot;
}
};
19.顺时针打印矩阵
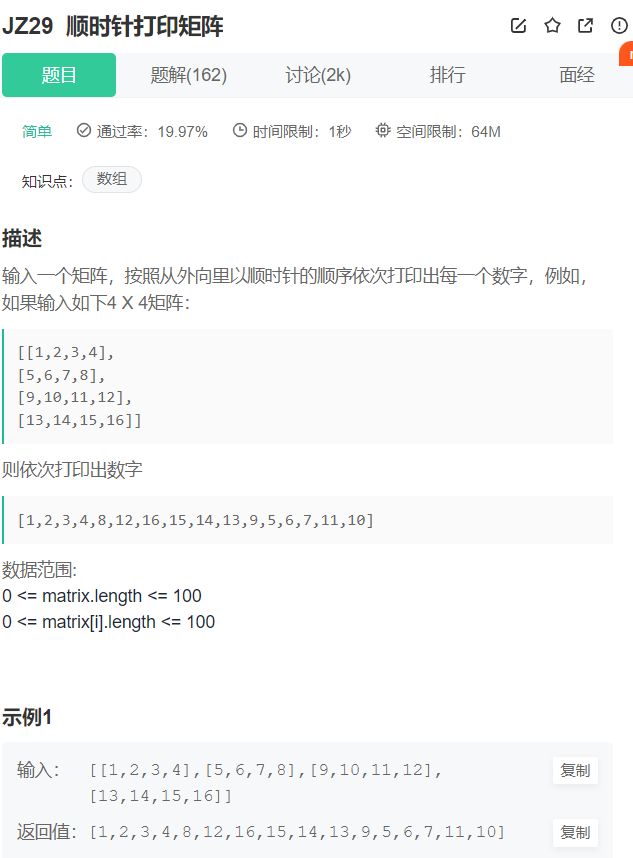
这题主要找边界条件
class Solution {
public:
vector<int> printMatrix(vector<vector<int> > matrix) {
if (matrix.size() == 0) return vector<int>();
if (matrix.size() == 1) return matrix[0];
int top = 0, bottom = matrix.size() - 1; //记录待打印的矩阵上下边缘
int left = 0, right = matrix[0].size() - 1; //记录待打印的矩阵左右边缘
vector<int> res;
while (1) {
for (int i = left; i <= right; i++) { // 从左到右
res.push_back(matrix[top][i]); // 打印最上边
}
if (++top > bottom) break; // ++上边缘,大于下边缘,退出
for (int i = top; i <= bottom; i++) { // 从上到下
res.push_back(matrix[i][right]); // 最右边
}
if (--right < left) break; // --右边缘,小于左边缘,退出
for (int i = right; i >= left; i--) { // 从右到左
res.push_back(matrix[bottom][i]); // 最下边
}
if (--bottom < top) break; // --下边缘,小于上边缘,退出
for (int i = bottom; i >= top; i--) { // 从下到上
res.push_back(matrix[i][left]); // 最左边
}
if (++left > right) break; // ++左边缘,大于右边缘,退出
}
return res;
}
};
20.包含min函数的栈

思路是,在push的时候,将最新的最小值也加入栈中,在pop的时候,需要pop两次,然后更新最小值
class Solution {
public:
void push(int value) {
if (value < minNum) {
minNum = value;
}
sk.push(minNum); // 每次存取的时候,将加入该值后的最小值也一并存取
sk.push(value);
}
void pop() {
sk.pop(); // pop目标值
sk.pop(); // pop最小值
int tmp = sk.top();
sk.pop();
minNum = sk.top(); // 更新最小值
sk.push(tmp);
}
int top() {
return sk.top();
}
int min() {
return minNum;
}
stack<int> sk;
int minNum = INT_MAX;
};
记录一下每周的刷题记录,会在每周周日发布