《Colab使用训练指南》
简介
-
Colaboratory 是一个免费的 Jupyter 笔记本环境
-
借助 Colaboratory,可以编写和执行代码、保存和共享分析结果,以及利用强大的计算资源,所有这些都可通过浏览器免费使用
-
Colab 支持大多数主流浏览器,并且在 Chrome、Firefox 和 Safari 的最新版本上进行了最全面的测试。
-
总体使用量限额、空闲超时时长、虚拟机最长生命周期、可用 GPU 类型以及其他因素都会随机变化
-
Colab地址
-
google云盘 (可以用来上传自定义数据集)
使用
-
进入
Colab -
登陆
google账号 -
点击文件——新建笔记本,进入.ipynb界面
-
查看和配置
-
查看
pytorch版本 -
查看是否可以使用
cuda(如果不可以,需要修改运行设置)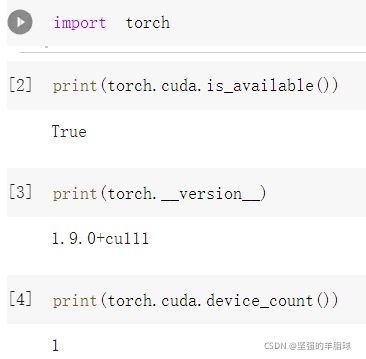
-
点击
修改——笔记本设置——硬件加速度器
-
查看显卡配置(随机,大部分是
K80)-
!nvidia-smi(命令行运行,前面要加!)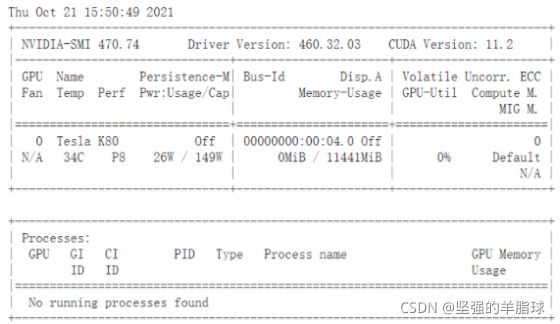
-
-
如何挂载谷歌云盘
Colab的运行原始路径不是谷歌云盘所在路径,所以需要挂载到远程主机上
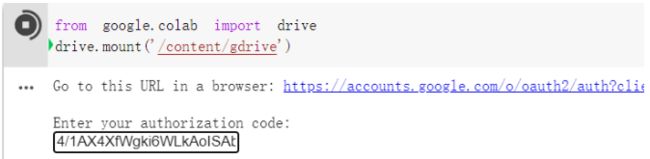
from google.colab import drive
drive.mount('/content/gdrive')
- 点击链接,登录Google账户,获取授权码,复制粘贴回车,提示
Mounted at /content/gdrive则挂载成功
- 上传数据文件到
Google云盘,检查文件
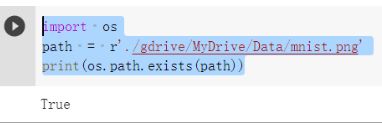
-
如果想要更改运行目录,直接运行文件
- 修改运行目录
import os os.chdir("/content/gdrive/MyDrive/Colab Notebooks/MyCode")- 使用命令行运行
! python example.py
测试
- MNIST数据集:训练数据60000,测试数据10000
- LeNet模型
- 分别测试CPU版本、GPU版本、多GPU版本训练
- 分别使用torchvision数据集和本地上传数据集测试
CPU版本
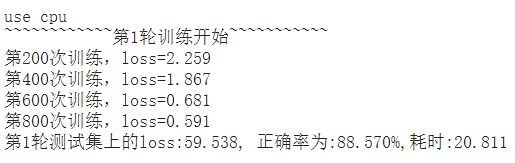
train_gpu_cpu.py,设置runing_mode='cpu'
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
import time
"""
测试在Colab上训练
CPU
GPU
"""
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(16*4*4, 120),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
def forward(self, x):
output = self.model(x)
return output
train_datasets = torchvision.datasets.MNIST(
root = r'../data',
download=True,
train=True,
transform=transforms.ToTensor()
)
train_dataloader = DataLoader(
dataset=train_datasets,
batch_size=64
)
test_datasets = torchvision.datasets.MNIST(
root = r'../data',
train=False,
download=True,
transform=transforms.ToTensor()
)
test_dataloader = DataLoader(
dataset=test_datasets,
batch_size=64
)
train_datasets_size = len(train_datasets)
test_datasets_size = len(test_datasets)
print("训练集数量为:{}".format(train_datasets_size))
print("测试集数量为:{}".format(test_datasets_size))
runing_mode = "gpu" # cpu,gpu, gpus
if runing_mode == "gpu" and torch.cuda.is_available():
print("use cuda")
device = torch.device("cuda")
else:
print("use cpu")
device = torch.device("cpu")
model = LeNet()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
learning_rate = 1e-2
optim = torch.optim.SGD(model.parameters(), lr=learning_rate)
epoch = 10
train_step, test_step = 0, 0
for i in range(epoch):
print("~~~~~~~~~~~~第{}轮训练开始~~~~~~~~~~~".format(i+1))
start = time.time()
model.train()
for data in train_dataloader:
imgs, targets = data
imgs, targets = imgs.to(device), targets.to(device)
output = model(imgs)
loss = loss_fn(output, targets)
optim.zero_grad()
loss.backward()
optim.step()
train_step += 1
if train_step % 200 == 0:
print("第{}次训练,loss={:.3f}".format(train_step, loss.item()))
#
model.eval()
with torch.no_grad():
test_loss, true_num = 0, 0
for data in test_dataloader:
imgs, targets = data
imgs, targets = imgs.to(device), targets.to(device)
output = model(imgs)
test_loss += loss_fn(output, targets)
true_num += (output.argmax(1) == targets).sum()
end = time.time()
print("第{}轮测试集上的loss:{:.3f}, 正确率为:{:.3f}%,耗时:{:.3f}".format(test_step+1, test_loss.item(), 100 * true_num / test_datasets_size, end-start))
test_step += 1
GPU版本

train_gpu_cpu.py,设置runing_mode="gpu"
测试本地数据挂载
-
上传数据
mnist.mat到Google云盘 -
挂载云盘
-
检查文件是否存在
-
train_with_data_upload.py
import torchvision, torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
import time
from torch.utils.data import Dataset
import scipy.io as sio
import numpy as np
"""
测试训练自定义数据集
"""
class mnistDataset(Dataset): # 继承Dataset
def __init__(self, imgs, targets):
self.imgs = imgs
self.targets = targets
def __len__(self):
return self.targets.shape[0]
def __getitem__(self, idx):
target = self.targets[idx,0]
img = self.imgs[idx].reshape((20, 20)).T
img_tensor = torch.tensor(img, dtype=torch.float).view(-1, 20, 20)
return img_tensor, np.long(target)
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(6, 16, kernel_size=3),
# nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(16*6*6, 120),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
def forward(self, x):
output = self.model(x)
return output
# 加载自定义数据集
path = './gdrive/MyDrive/Data/mnist.mat'
data = sio.loadmat(path)
imgs, targets = data['X'], data['y'] % 10 # 5000*400, 5000*1
np.random.seed(222)
np.random.shuffle(imgs)
np.random.seed(222)
np.random.shuffle(targets)
train_imgs, test_imgs = np.split(imgs, [4000])
train_targets, test_targets = np.split(targets, [4000])
train_datasets = mnistDataset(train_imgs, train_targets)
train_dataloader = DataLoader(
dataset=train_datasets,
batch_size=32,
shuffle=True
)
test_datasets = mnistDataset(test_imgs, test_targets)
test_dataloader = DataLoader(
dataset=test_datasets,
batch_size=32,
shuffle=True
)
train_datasets_size = len(train_datasets)
test_datasets_size = len(test_datasets)
print("训练集数量为:{}".format(train_datasets_size))
print("测试集数量为:{}".format(test_datasets_size))
runing_mode = "gpu" # cpu,gpu, gpus
if runing_mode == "gpu" and torch.cuda.is_available():
print("use cuda")
device = torch.device("cuda")
else:
print("use cpu")
device = torch.device("cpu")
model = LeNet()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
learning_rate = 1e-2
optim = torch.optim.Adam(model.parameters(), lr=learning_rate)
epoch = 20
train_step, test_step = 0, 0
for i in range(epoch):
print("~~~~~~~~~~~~第{}轮训练开始~~~~~~~~~~~".format(i+1))
start = time.time()
model.train()
for data in train_dataloader:
imgs, targets = data
imgs, targets = imgs.to(device), targets.to(device)
output = model(imgs)
loss = loss_fn(output, targets)
optim.zero_grad()
loss.backward()
optim.step()
train_step += 1
if train_step % 200 == 0:
print("第{}次训练,loss={:.3f}".format(train_step, loss.item()))
#
model.eval()
with torch.no_grad():
test_loss, true_num = 0, 0
for data in test_dataloader:
imgs, targets = data
imgs, targets = imgs.to(device), targets.to(device)
output = model(imgs)
test_loss += loss_fn(output, targets)
true_num += (output.argmax(1) == targets).sum()
end = time.time()
print("第{}轮测试集上的loss:{:.3f}, 正确率为:{:.3f}%,耗时:{:.3f}".format(test_step+1, test_loss.item(), 100 * true_num / test_datasets_size, end-start))
test_step += 1
参考
如何正确地使用Google Colab
Tesla K80 GPU shown instead of Tesla T4