模型推理加速系列|如何用ONNX加速BERT特征抽取-part2(附代码)
背景
本文紧接之前的一篇文章如何用ONNX加速BERT特征抽取,继续介绍如何用ONNX+ONNXRuntime来加速BERT模型推理。如果看过之前的那篇文章如何用ONNX加速BERT特征抽取的童鞋估计还记得文中留了一个疑问:为何优化过的ONNX模型与未优化的ONNX性能相近?说好的优化,说好地提速呢?与预期不符~
经热心网友冠达提醒优化的ONNX模型运行时要开启OpenMP(如果没有安装,用apt-get install libgomp1安装OpenMP运行时库即可)。回来一试,果然如此,在此感谢热心网友!本文一方面将以正确姿势重新对比ONNX和优化过的ONNX,另一方面引入量化进一步提升模型的推理性能。
PS:本文的实验模型是BERT-base中文版;实验环境的CPU型号信息如下:32 Intel(R) Xeon(R) Gold 6134 CPU @ 3.20GHz。
优化ONNX v.s 未优化ONNX
相比于之前代码的唯一区别是在开头加入以下内容,开启OpenMP加速运行。
from os import environ
from psutil import cpu_count
# Constants from the performance optimization available in onnxruntime
# It needs to be done before importing onnxruntime
environ["OMP_NUM_THREADS"] = str(cpu_count(logical=True))
environ["OMP_WAIT_POLICY"] = 'ACTIVE'
所以,此次所有模型都是在此基础上对比,对比结果如下图所示:

各个模型运行的平均时长如下所示,可以看出,PyTorch模型在开启了OpenMP之后,也从130ms骤降到35ms。其他模型也受益于OpenMP,优化过的ONNX推理耗时只要7ms。
{'PyTorch CPU': 35.71977376937866,
'ONNX CPU': 8.49233627319336,
'ONNX opt CPU': 7.421176433563232}
模型量化
量化(使用整数而不是浮点)能够让神经网络模型运行得更快。量化是将浮点32范围的值映射为int8,同时尽量地维持模型原来的精度。Hugging Face的transformers也提供了量化功能,可以很方便地导出量化模型。
Pytorch模型量化
import torch
from transformers import BertTokenizerFast
# Load Pytorch model
torch_model = "/home/data/pretrain_models/bert-base-chinese-pytorch"
model_pt = BertModel.from_pretrained("/home/data/pretrain_models/bert-base-chinese-pytorch").to(device)
tokenizer = BertTokenizerFast.from_pretrained(torch_model)
# Quantize
model_pt_quantized = torch.quantization.quantize_dynamic(
model_pt.to("cpu"), {torch.nn.Linear}, dtype=torch.qint8
)
model_inputs = tokenizer("大家好, 我是卖切糕的小男孩, 毕业于华中科技大学", return_tensors="pt")
# Warm up
model_pt_quantized(**model_inputs)
# Benchmark PyTorch quantized model
time_buffer = []
for _ in trange(100):
with track_infer_time(time_buffer):
model_pt_quantized(**model_inputs)
results["PyTorch CPU Quantized"] = OnnxInferenceResult(
time_buffer,
None
)
ONNX模型量化
## ONNX Quantize
from transformers.convert_graph_to_onnx import quantize
onnx_quantized_model_path = quantize(Path(model_onnx_path))
quantized_model = create_model_for_provider(onnx_quantized_model_path.as_posix(), "CPUExecutionProvider")
# Warm up the overall model to have a fair comparaison
outputs = quantized_model.run(None, inputs_onnx)
# Evaluate performances
time_buffer = []
for _ in trange(100, desc=f"Tracking inference time on CPUExecutionProvider with quantized model"):
with track_infer_time(time_buffer):
outputs = quantized_model.run(None, inputs_onnx)
# Store the result
results["ONNX CPU Quantized"] = OnnxInferenceResult(
time_buffer,
onnx_quantized_model_path
)
量化前后结果对比
Pytorch模型及其量化模型、ONNX模型、优化过的ONNX模型及其量化模型在CPU上运行的对比结果如下图所示:
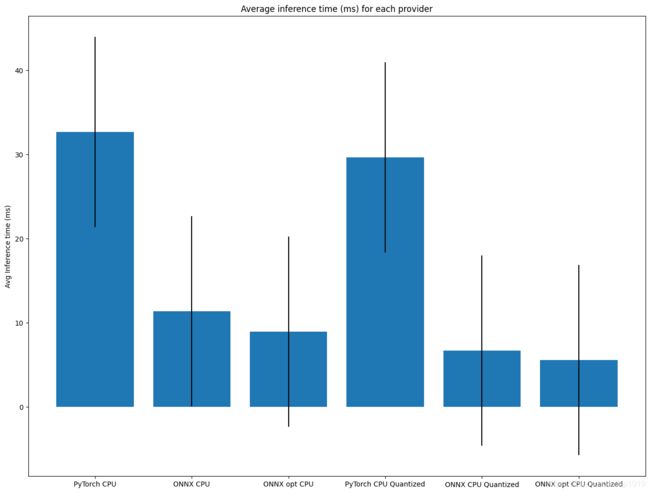
具体数值如下图所示,可以看出,优化过的ONNX模型,再加持量化操作,可以取得5ms的推理耗时。
{'PyTorch CPU': 32.65737533569336,
'ONNX CPU': 11.347918510437012,
'ONNX opt CPU': 8.921334743499756,
'PyTorch CPU Quantized': 29.652047157287598,
'ONNX CPU Quantized': 6.680562496185303,
'ONNX opt CPU Quantized': 5.557553768157959}
总结
综上,得出以下结论:
- 将Pytorch模型转为ONNX格式,再用ONNX Runtime 进行推理,可以显著提速。本文这里的实验结果,单条数据在CPU上的推理提速约3倍。
- 优化ONNX模型在OpenMP上运行加速显著。
- 量化效果提速显著。在ONNX上进行量化,大约可以继续提速2倍,最终取得5.5ms的模型推理性能。