GO FOR A WALK AND ARRIVE AT THE ANSWER: REASONING OVER PATHS IN KNOWLEDGE BASES USING REINFORCEMENT

MINERVA:使用强化学习对知识库中的路径进行推理
摘要
自动和手动构建的知识库 (KB) 通常是不完整的——通过综合现有信息可以从 KB 中推断出许多有效的事实。知识库补全的一种流行方法是通过对沿着连接一对实体的其他路径发现的信息进行组合推理来推断新关系。鉴于 KB 的巨大规模和路径的指数数量,以前的基于路径的模型只考虑了在给定两个实体的情况下预测缺失关系的问题,或者评估所提出的三元组的真实性。此外,这些方法传统上使用固定实体对之间的随机路径,或者最近学会在它们之间选择路径。我们提出了一种新算法 MINERVA,它解决了在关系已知但只有一个实体的情况下回答更困难和更实际的任务。由于随机游走在从起始节点开始组合多个目的地的环境中是不切实际的,因此我们提出了一种神经强化学习方法,该方法学习如何根据输入查询导航图以找到预测路径。根据经验,这种方法在几个数据集上获得了最先进的结果,显着优于以前的方法。
1.介绍
自动推理,即计算系统根据观察到的证据做出新推断的能力,一直是人工智能的一个长期目标。我们对具有丰富多样语义的大型知识库(KB)上的自动推理感兴趣(Suchanek等人,2007;Bollacker等人,2008;Carlson等人,2010)。知识库是高度不完整的(Min et al., 2013),没有直接存储在KB中的事实通常可以从KB中推断出来,这为自动化推理创造了令人兴奋的机会和挑战。例如,考虑图1中的小知识图。我们可以回答这个问题:“马拉拉和谁分享了她的诺贝尔和平奖?”从下面的推理路径:马拉拉·乌萨法扎伊→WonAward→2014年诺贝尔和平奖→award→冈仁波齐·萨蒂亚尔希。我们的目标是在KBs中自动学习这样的推理路径。我们把学习问题框定为一个查询回答的问题,也就是说,回答问题的形式(Malala Y ousafzai, SharesNobelPrizeWith, ?)
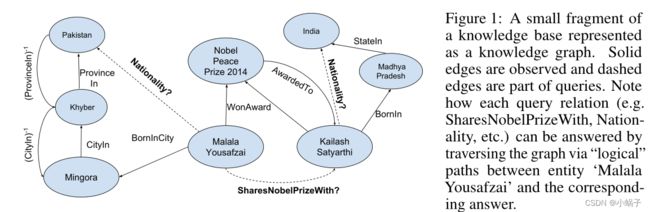
图 1:表示为知识图的知识库的一小部分。观察到实心边缘,虚线边缘是查询的一部分。 请注意如何通过实体“Colin Kaepernick”和相应答案之间的“逻辑”路径遍历图形来回答每个查询(例如 Nationality、PlaysInLeague、Layer HomeStadium)
从早期开始,自动推理方法的重点一直是构建可以学习清晰的符号逻辑规则的系统符号表示也已与机器学习集成,特别是在统计关系学习中,但由于泛化性能差,这些方法在很大程度上已被被分布式向量表示所取代。使用张量分解或神经方法学习实体和关系的嵌入一直是一种流行的方法,但这些方法无法捕获知识库路径表达的推理。神经多跳模型通过在向量空间中对 KB 路径进行操作,在一定程度上解决了上述问题。然而,这些模型将一组路径作为输入,这些路径是通过执行独立于查询关系的随机游走收集的。此外,诸如使用相同的一组最初收集的路径来回答不同的查询类型(例如,MarriedTo、Nationality、WorksIn 等)的模型。
本文提出了一种使用强化学习 (RL) 以输入问题为条件的有效搜索提供答案路径的图的方法,无需预先计算的路径。 给定一个庞大的知识图谱,我们学习一个策略,给定查询(实体,关系,?),从实体开始,并通过在每一步选择带标签的关系边来学习走到答案节点,条件是 查询关系和整个路径历史。 这将查询-回答任务表述为强化学习 (RL) 问题,其目标是采取最佳决策序列(关系边的选择)以最大化预期奖励(到达正确答案节点)。 我们将 RL 代理 MINERVA 称为“在实体网络中蜿蜒以达到相似答案”。
我们基于 RL 的配方具有许多理想的特性。
- 首先,MINERVA 具有采用可变长度路径的内置灵活性,这对于回答需要复杂推理链的更难的问题非常重要。
- 其次,MINERVA 不需要预训练,通过强化学习从头开始训练知识图谱; 不需要其他监督或微调,这代表了 RL 在 NLP 中的先前应用的显着进步。
- 我们的基于路径的方法在计算上是有效的,因为通过在查询实体周围的一个小邻域中进行搜索,它避免了像之前的工作那样对 KB 中的所有实体进行排名。
最后,我们的智能体找到的推理路径自动形成其预测的可解释来源。
这篇论文的主要贡献是:(a)我们提出了代理 MINERVA,它通过在以输入查询为条件的知识图上行走来学习查询回答,当它到达答案节点时停止。代理使用强化学习进行训练,特别是策略梯度(第 2 节)。 (b) 我们在几个基准数据集上评估 MINERVA,并与在 KB 中进行逻辑规则学习的 Neural Theorem Provers (NTP) 和 Neural LP 进行比较。 我们还与 DeepPath 进行比较,后者使用强化学习来选择实体对之间的路径。主要区别在于,他们的 RL 代理的状态包括答案实体,因为它是为更简单的任务而设计的,即预测事实是否为真或不是。因此,他们的方法不能直接应用于我们更具挑战性的查询回答任务,其中第二个实体未知且必须推断。尽管如此,在他们的实验设置中进行比较时,MINERVA 在他们的基准 NELL-995 数据集上的表现优于 DeepPath。
2.任务与模型
我们正式地在知识库中定义了查询回答任务。![]() 表示实体的集合,R表示二元关系的集合。知识库是将事实以三联体(e1,r,e2)的形式存储的集合,其中e1,e2∈
表示实体的集合,R表示二元关系的集合。知识库是将事实以三联体(e1,r,e2)的形式存储的集合,其中e1,e2∈![]() ,r∈R。通过知识库,可以构建一个知识图G,其中实体e1,e2表示为节点,关系r表示为它们之间的标记边。形式上,知识图是一个有向标记多重图G = (V,E,R),其中V和E分别表示图的顶点和边。注意V =
,r∈R。通过知识库,可以构建一个知识图G,其中实体e1,e2表示为节点,关系r表示为它们之间的标记边。形式上,知识图是一个有向标记多重图G = (V,E,R),其中V和E分别表示图的顶点和边。注意V = ![]() 和E⊆V × R ×V。同样,按照前面的方法,我们添加每条边的逆关系,也就是说,对于一条边(e1,r,e2)∈E,我们将边(e2,r−1,e1)添加到图中。(如果二元关系的集合R中不包含反比关系R−1,则将反比关系R也加到R中)。
和E⊆V × R ×V。同样,按照前面的方法,我们添加每条边的逆关系,也就是说,对于一条边(e1,r,e2)∈E,我们将边(e2,r−1,e1)添加到图中。(如果二元关系的集合R中不包含反比关系R−1,则将反比关系R也加到R中)。
由于KBs有大量的信息缺失,信息抽取界自然而然地出现了两个任务——事实预测和查询回答。
查询回答寻求回答形式为(e1,r,?)的问题,例如T oronto, locatedIn, ?,
事实预测涉及预测一个事实是否为真,例如(T oronto, locatedIn, Canada)?。事实预测的算法可以用于查询回答,但会带来很大的计算开销,因为必须对所有候选答案实体进行评估,这使得具有数百万个实体的大型KBs非常昂贵。在这项工作中,我们提出了一个查询回答模型,它学习了有效地遍历知识图来找到一个查询的正确答案,而不需要评估所有实体。
查询回答自然地简化为一个有限视域序列决策问题,如下所示:我们首先在知识库衍生的知识图G上将环境表示为一个确定性的部分观察到的马尔科夫决策过程(§2.1)。我们的RL代理得到了一个表单的输入查询![]() 从G中e1q对应的顶点开始,代理沿着图中的一条路径,在它预测的节点处停止(§2.2)。使用已知事实的训练集,我们通过REINFORCE (Williams, 1992)和控制变量(§2.3)更具体地使用策略梯度来训练代理。让我们从描述环境开始。
从G中e1q对应的顶点开始,代理沿着图中的一条路径,在它预测的节点处停止(§2.2)。使用已知事实的训练集,我们通过REINFORCE (Williams, 1992)和控制变量(§2.3)更具体地使用策略梯度来训练代理。让我们从描述环境开始。
2.1环境——状态、行动、过渡和奖励
我们的环境是一个有限的、确定性的部分观察到的马尔科夫决策过程,这个决策过程建立在由知识库导出的知识图上。在这个图上,我们现在将指定一个确定性的部分观察马尔可夫决策过程,它是一个5元组(S,O, a,δ,R),每一个我们将在下面详细说明。

在实现过程中,我们将计算图展开到固定数量的时间步长t。我们用一个名为“NO-OP”的特殊操作来扩充每个节点,该操作从节点到节点本身。有些问题比其他问题更容易回答,需要的推理步骤也更少。这种设计决策允许代理在任意数量的时间步骤中保持在节点上。当代理在时间步t < T成功地获得了正确的答案,并且可以在剩余的时间步中继续停留在“答案节点”时,这尤其有用。或者,我们也可以允许代理采取一个特殊的“STOP”动作,但我们发现当前的设置工作得足够好。如前所述,我们还添加了一个三元组的反比关系,即对于三元组(e1,r,e2),我们将三元组(e2,r−1,e1)添加到图中。我们认为这很重要,因为这实际上允许我们的代理撤销一个潜在的错误决定 。

2.2策略网络


2.3训练
对于上文所述的策略网络(πθ),我们希望找到使期望回报最大化的参数θ:
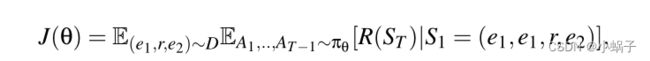
其中,我们假设存在一个真正的潜在分布(e1,r,e2) ~ D。为了解决这个优化问题,我们使用如下的REINFORCE (Williams, 1992):
- 第一个期望被训练数据集上的经验平均值所取代。
- 对于第二个期望,我们通过对每个训练示例运行多个演示来进行近似。推出的数量是固定的,对于我们的所有实验,我们将这个数字设置为20。
- 为了减少方差,常用的策略是使用加性控制变量基线(Hammersley, 2013;Fishman, 2013;Evans & Swartz, 2000)。我们使用累计折现奖励的移动平均值作为基准。我们调整这个移动平均线的权重作为一个超参数。注意,在我们的实验中,我们发现使用学习基线的结果与此类似,但由于其简单性,我们最终选择了累积折现奖励作为基线。
- 为了鼓励训练时政策抽样路径的多样性,我们将熵正则化项添加到以常数(β)缩放的成本函数中。
3.实验
我们现在提供MINERVA的实证研究,以建立
(i) MINERVA在小型(第3.1.1节)和大型KBs(第3.1.2节)的查询回答方面具有竞争力
(ii) MINERVA优于基于路径的模型,不能有效地搜索KB或训练查询特定模型(第3.2节)
(iii) MINERVA不仅可以用于格式良好的查询,还可以轻松处理部分结构化的自然语言查询(第3.3节)
(iv) MINERVA在长链上的推理能力很强
(v) MINERVA训练起来很健壮,并且有更快的推理时间(第3.5节)。
3.1知识库查询应答
为了衡量MINERVA的推理能力,我们从知识库上的查询回答任务开始。我们想要回答这样的查询(e1,r,?)注意,如第2节所述,此任务与知识库的事实检入略有不同。此外,正如之前的大多数文献在事实核查制度中工作,它们的排名包括(e1,r,x)和(x,r,e2)的变化。然而,由于我们在问答场景中无法访问e2,因此同样的排序过程对我们不成立——我们只需要在(e1,r,x)上排序。这种排名上的差异使得我们有必要重新运行之前工作的所有实现。我们使用了rock¨aschel & Riedel(2017)的实现或最好的预训练模型(只要有)。为了在推理过程中MINERVA生成答案实体的排序,我们进行波束搜索,波束宽度为50,并根据模型到达实体的轨迹的概率对实体进行排序,其余实体的排序为∞。
方法
我们使用HITS@1、3、10和平均互反秩(MRR)将MINERVA与各种最先进的模型进行比较,这是知识库完成任务的标准指标。特别是,我们比较了基于嵌入的模型- DistMult (Yang等人,2015),ComplEx (Trouillon等人,2016)和ConvE (Dettmers等人,2018)。对于ConvE和ComplEx,我们使用Dettmers等人(2018)发布的实现对他们报告的最佳超参数设置。对于DistMult,我们使用了高度调优的实现(例如,它的性能比Toutanova等人(2015)的最新结果更好)。我们还比较了最近在学习逻辑规则的KB的两个工作,即神经定理证明(NTP) (Rockt¨aschel & Riedel, 2017)和NeuralLP (Yang等人,2017)。Rockt¨aschel & Riedel(2017)也报告了一个NTP模型,该模型使用ComplEx (NTP-λ)的附加目标函数进行训练。对于这些模型,我们使用了相应作者发布的实现,同样是基于他们报告的最佳超参数设置。
3.1.1较小的数据集
Dataset
我们使用三个标准数据集:国家、亲属关系和UMLS。“国家”数据集包含作为实体的国家、地区和次区域,并经过精心设计,以明确测试链接预测模型的逻辑规则学习和推理能力。查询的形式是LocatedIn(c, ?),答案是一个区域(例如LocatedIn(埃及,?),答案是非洲)。数据集有3个任务(表2中的S1-3),每个任务都需要增加推理步骤的长度和难度(参见rock¨aschel & Riedel(2017)了解更多关于任务的细节)。按照国家数据集的设计,对于任务S1和S2,我们设置最大路径长度T = 2,对于S3,我们设置T = 3。统一医学语言系统(UMLS)数据集来自生物医学。实体是生物医学概念(如疾病、抗生素),关系就像治疗和诊断。亲属关系数据集包含澳大利亚中部Alyawarra部落成员之间的亲属关系。对于这两个任务,我们使用最大路径长度T = 2。此外,对于MINERVA,我们在这些实验中关闭实体。
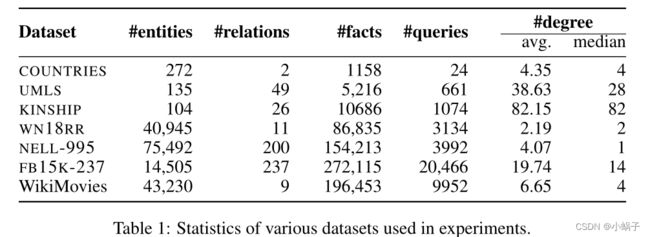
表1:实验中使用的各种数据集的统计。

表2:使用AUC-PR指标对国家数据集的三个任务的性能。MINERVA在最难的任务(S3)上明显优于所有其他方法。此外,与其他方法相比,MINERVA的运行方差更低。
观察
对于国家数据集,在表2中,我们报告了一个更强的指标——精确召回曲线下的面积——这在文献中很常见。我们可以看到,MINERVA比较好或优于所有基准模型,除了在国家的任务S2,其中集成模型NTP-λ和ConvE优于它,尽管在运行中有更高的方差。我们的收获在任务S3中更加明显,它是所有任务中最难的。
亲属关系和UMLS数据集都是小KB数据集,每个数据集大约有100个实体,正如我们从表3中看到的,嵌入的基于方法(ConvE, ComplEx和DistMult)比旨在学习逻辑规则的方法(NTP, NeuralLP和MINERVA)性能要好得多。
在亲属关系上,MINERVA优于NeuralLP和NTP,并匹配NTP在UMLS上的HITS@10性能。与COUNTRIES不同的是,这些数据集并不是用来测试模型的逻辑规则学习能力的,并且在较小的规模下,基于嵌入的模型能够获得真正的高性能。结合这两种方法,从NTP-λ的结果可以看出,性能略有提高。然而,当我们用预先训练好的ComplEx嵌入来初始化MINERVA时,我们并没有发现性能的显著提高。

3.1.2大数据集
Dataset
下一步,我们在三个大型KG数据集上评估MINERVA - WN18RR, FB15K-237和NELL995。WN18RR 和FB15K-237数据集分别由原始WN18和FB15K数据集通过去除各种来源的测试泄漏来创建,使数据集更加真实和具有挑战性。Xiong等人(2017)发布的NELL-995数据集对每个查询关系都有单独的图,其中一个查询关系的图可以有来自另一个查询关系测试集的三元组。在查询回答实验中,我们将所有的图进行组合,并从图中移除所有的测试三元组(以及对应的具有逆关系的三元组)。我们还注意到,测试集中的几个三元组有一个实体(源或目标)从未出现在图中。因为这些实体没有经过训练的嵌入,所以我们将它们从测试集中移除。这将测试集的大小从3992个查询减少到2818个查询。
观察
表4报告了对较大的WN18RR、FB15K-237和NELL-995数据集的查询回答结果。我们不能包括NeuralLP在NELL-995上的结果,因为它没有缩放到那个大小。同样,NTP不能扩展到任何更大的数据集。除了这些,我们是第一个报告所有基线方法在这些数据集上的性能的全面总结。
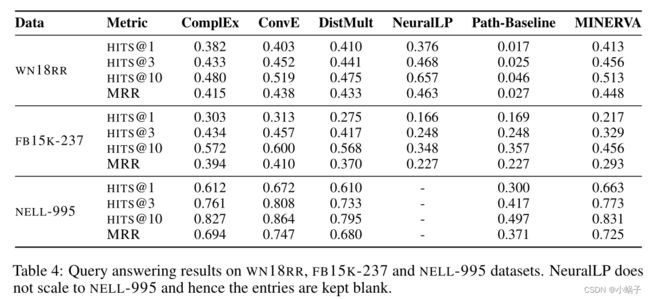
表4:WN18RR、FB15K-237和NELL-995数据集上的查询应答结果。NeuralLP不能扩展到NELL-995,因此条目保持空白。
在NELL-995上,MINERVA可与基于嵌入的方法(如DistMult和ComplEx)相媲美,并在更严格的HITS@1度量上与ConvE相媲美。但是ConvE在HITS@10上的NELL-995上超过了我们。在WN18RR上,基于逻辑的方法(NeuralLP, MINERVA)通常优于基于嵌入的方法,MINERVA在HITS@1指标上获得最高分数,而NeuralLP在HITS@10上显著优于。
然而,我们观察到在FB15K-237上,基于嵌入的方法优于MINERVA和NeuralLP。通过深入考察,我们发现FB15K-237知识图谱的查询关系类型与其他知识图谱有显著差异。
FB15k-237查询关系分析:我们分析了FB15k-237数据集上查询关系类型的类型。在Bordes等人(2013)之后,我们将查询关系分为(M)任意到1、1到M或1到1的关系。M对1关系的一个例子是“/人/职业”(X个人的职业是什么?)1到M关系的一个例子是/音乐/乐器/乐器演奏者(“谁演奏X乐器?”)或/人/种族/人(“谁是X种族的人?”)。从查询回答的角度来看,这些问题的答案是一个实体列表。但是,在评估过程中,模型的评估是基于它是否能够预测查询三重中的一个目标实体。此外,由于MINERVA将路径的端点输出为目标实体,有时可能三元组的特定目标实体没有从源实体的路径(然而有到其他“正确”答案实体的路径)。表9(在附录中)显示了属于不同类的关系的其他几个例子。

根据Bordes等人(2013)的研究,如果尾实体与头实体的基数比大于1.5,我们将关系归类为1比m;如果尾实体与头实体的基数比小于0.67,则归类为m比1。在FB15K-237的验证集中,54%的查询是1对m的,而只有26%是m对1的。与NELL-995相比,27%是1对m, 36%是m对1,UMLS只有18%是1对m。表10(附录)显示了FB15K-237数据集中尾头比高的关系很少。FB15K-237中1对m关系的平均比率为13.39(大大高于1.5)。如前所述,目前的评价方案并不适合1对m关系,FB15K-237中1对m关系的高比例也解释了MINERVA的性能不是最优。

able 10: FB15K-237中很少有1- m关系的例子,尾巴和头部的基数比很高
我们还检查各种惟一路径类型出现的频率。我们将路径类型定义为路径中关系类型的序列(忽略实体)。直观地说,跨查询泛化的预测路径将在图中出现很多次。图2显示了该图。我们可以看到,FB15K-237的特征与其他数据集有很大的不同。例如,在NELL-995中,超过1000种不同的路径类型出现超过1000次。WN18RR只有11种不同的关系类型,这意味着长度为3的可能路径类型只有113种,其中可以预测的更少。可以看出,出现次数超过104次的路径类型很少,超过1000次的路径类型约有50种。然而,在关系类型数量最多的FB15K-237中,我们观察到出现次数显著增多的路径类型数量急剧减少。因为MINERVA不能找到经常重复的路径类型,所以很难学习一般化的路径类型。
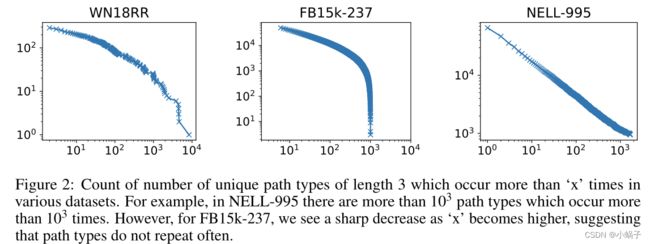 图2:长度为3的唯一路径类型在各种数据集中出现超过“x”次的计数。例如,在NELL-995中,出现103次以上的路径类型超过103种。然而,对于FB15k-237,我们看到随着' x '变得更高,急剧下降,这表明路径类型不经常重复。
图2:长度为3的唯一路径类型在各种数据集中出现超过“x”次的计数。例如,在NELL-995中,出现103次以上的路径类型超过103种。然而,对于FB15k-237,我们看到随着' x '变得更高,急剧下降,这表明路径类型不经常重复。
3.2与基于路径的模型比较
3.2.1与随机游走模型
在这个实验中,我们比较了一个基于随机漫步收集路径的模型,并试图预测答案实体。神经多跳模型(Neelakantan等人,2015;Toutanova等人,2016),对一个知识库中实体对之间的路径进行操作。然而,这些方法需要知道目标实体,以便预计算实体对之间的路径。(Guu et al., 2015)在这方面是一个例外,因为他们从源实体“e1”开始进行随机漫步,然后使用路径,他们训练分类器来预测目标答案实体。但是,它们只考虑从源实体开始的一条路径。相比之下,Neelakantan等人(2015);Toutanova等人(2016)使用来自源实体和目标实体之间的多条路径的信息。我们设计了一个结合了这两种方法优点的基线模型。从' e1 '开始,模型对最大长度为T = 3的随机路径(k = 100)进行采样。在Neelakantan等人(2015)之后,我们用LSTM和一个最大池化操作对每个路径进行编码,以使这些路径具有特色。该特性与源实体和查询关系向量连接,然后通过前馈网络对所有可能的目标实体打分。在推理过程中,我们根据模型得分对目标实体进行排序。
表4的PATH-BASELINE列显示了该模型在三个数据集上的性能。正如我们所看到的,MINERVA大大超过了这个基线。这表明,基于一组随机抽样路径进行预测的模型不如MINERVA做得好,因为它要么在随机漫步中丢失了重要的路径,要么无法从所有k条路径聚合预测特征,其中许多与回答给定的查询无关。后者类似于远程监督的问题(Mintz et al., 2009),重要的证据在大量不相关的信息中丢失。但是,通过以查询关系为条件进行每一步操作,MINERVA可以有效地减少搜索空间,并将重点放在回答查询的相关路径上。
3.2.2与deeppath
我们还比较了MINERVA和DeepPath,后者使用RL在实体对之间选择路径。为了进行公平的比较,我们只将答案实体与实验中使用的数据集中的负面示例进行排名5,并报告每个查询关系的平均平均精度(MAP)得分。deepppath将其代理收集的路径作为输入特征提供给路径排名算法(PRA) (Lao et al., 2011),该算法训练每个关系分类器。但与它们不同的是,我们训练了一个学习所有查询关系的模型,以便使我们的代理能够利用相关性和更多的数据。如果我们的代理不能到达正确的实体或消极实体之一,相应的实体将获得负无穷大的分数。如果MINERVA未能到达正确和负面实体集合中的任何实体。然后我们回到实体的随机排序。如表5所示,对于所有查询关系,我们的性能都优于它们或达到了相当的性能。虽然训练每个关系模型是繁琐的,并且不能扩展到具有数千种关系类型的大量KBs,但我们也训练MINERVA的每个关系模型,复制DeepPath的设置(MINERVAa在表5中)。MINERVAa优于DeepPath,表现类似于MINERVA,这是一个令人鼓舞的结果,因为训练一个对所有关系都表现良好的模型是非常可取的。
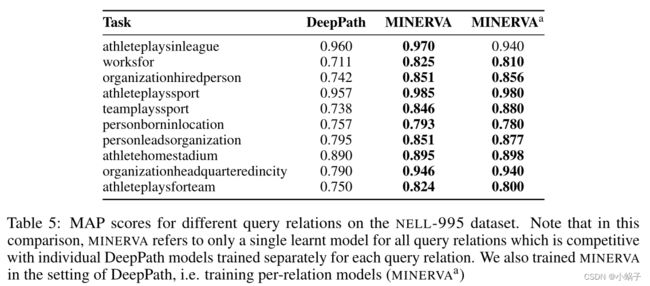
表5:NELL-995数据集上不同查询关系的MAP得分。注意,在这个比较中,MINERVA只针对所有查询关系引用了一个学习的模型,与针对每个查询关系单独训练的各个DeepPath模型相竞争。我们还在DeepPath的设置中训练MINERVA,即训练每关系模型(MINERVAa)。
3.2.3部分结构化查询
KBs中的查询以三元组的形式结构。但是,这并不令人满意,因为对于大多数实际应用程序,查询都是用自然语言显示的。作为朝着这个方向迈出的第一步,我们扩展了MINERVA以接受“部分结构化”的查询。我们使用WikiMovies数据集(Miller等人,2016),其中包含自然语言的问题,尽管这些问题是由人类注释器创建的模板生成的。举个例子,“哪部电影是赫伯·弗里德写的?”WikiMovies还有一个附带的知识库,可以用来回答所有问题。
我们通过简单的字符串匹配将问题中出现的实体链接到KB。为了形成查询关系的向量表示,我们设计了一个简单的问题编码器,它计算问题词嵌入的平均值。嵌入这个词是从零开始学习的,我们不使用任何预先训练的嵌入。我们将我们的结果与Y等人(2017)报告的结果进行了比较(表6)。对于这个实验,我们发现T = 1就足够了,这表明WikiMovies不是多跳推理的最佳测试平台,但这个实验是朝着使用KBs回答自然语言问题的现实设置迈出的有希望的第一步。

3.4网格世界寻径
而KB中的链不需要很长就可以得到好的实证结果(Neelakantan et al., 2015;Das等人,2017;Yang等人,2017),原理上MINERVA可以用来学习长推理链。为了评估相同的效果,我们在Yang等人(2017)创建的一个合成的16 × 16网格世界数据集上测试我们的模型,其中的任务是通过遵循一组方向(查询关系)从一个随机单元格(开始实体)开始导航到一个特定的单元格(答案实体)。KB由形式为((2,1),North,(1,1))的原子三元组组成——实体(1,1)在实体(2,1)的北面。查询包含一系列方向(例如,北、西南、东)。查询根据路径长度被分类为不同的类。图3显示了在不同路径长度上的精度。与Neural LP相比,MINERVA对于需要更长的路径的查询更健壮,即使是数据集中最长的路径,性能下降也很小。
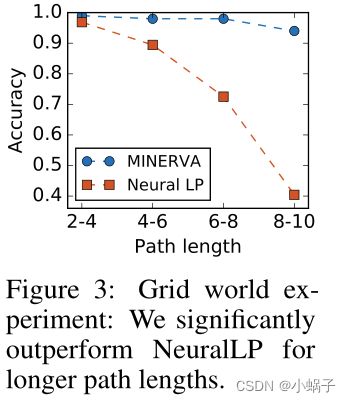
网格世界实验:我们在更长的路径长度上明显优于NeuralLP
3.5进一步分析
Training time
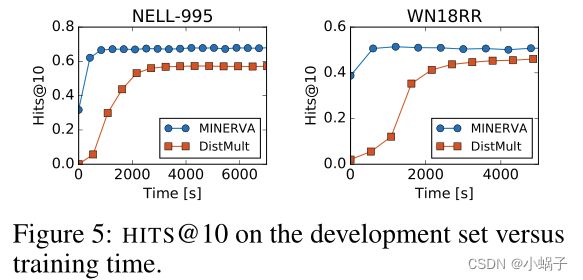
图5绘制了MINERVA与DistMult的开发集与训练时间的HITS@10得分。可以看出,MINERVA比DistMult更快地收敛到更高的分数。同样值得注意的是,即使在训练的早期阶段,MINERVA也比DistMult有更高的性能,因为在这些初始阶段,MINERVA只是在源实体(e1)的附近进行随机漫步。这意味着MINERVA在e1的邻域内搜索答案的方法比对知识图中的所有实体进行排序(如DistMult和其他相关方法所做的那样)更有效、更智能。
Inference Time

在测试时,基于嵌入的方法如ConvE, ComplEx和DistMult对图中的所有实体进行排序。因此,对于测试时间查询,运行时间总是O (|E|),其中R表示图中的实体集(=节点)。另一方面,MINERVA在推理时是有效的,因为它必须在其局部邻域内搜索答案实体。MINERVA在推断时间的许多代价是计算沿路径所有出方向边的概率。因此,MINERVA的推断时间只取决于图的程度分布。如果我们假设知识图像许多自然图一样服从幂律度分布,那么对于MINERVA,当幂律α的系数> 1时,平均推理时间可以显示为O(α/α−1)。对于所有α值,MINERVA的中值推断时间为O(1)。注意,这些量与实体的大小|E|无关。例如,在WN18RR的测试数据集上,MINERVA的挂钟推断时间是63秒,而其中最简单的GPU实现DistMult的挂钟推断时间是21s。同样,对于GPU实现的DistMult, NELL-995测试集上的挂钟推断时间为115s,而MINERVA测试集上的挂钟推断时间为35s。
基于查询的决策
在做出决定之前的每一步,我们的代理都对查询关系进行条件查询。图4显示了一些示例,其中基于查询关系,不同操作的概率最高。例如,当查询关系是WorksFor时,MINERVA分配了一个比AthletePlaysInLeague更高的概率获得edge CoachesTeam。我们还在WikiMovies数据集中看到了类似的行为,其中查询由单词而不是固定的模式关系组成。
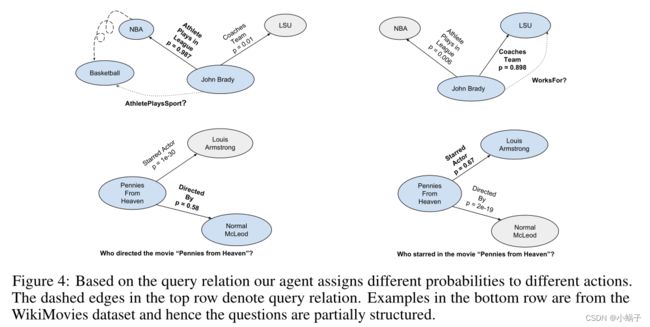
图4:基于查询关系,我们的代理为不同的操作分配不同的概率。第一行中的虚线边表示查询关系。下面一行中的示例来自WikiMovies数据集,因此问题是部分结构化的。
模型的鲁棒性
表7还报告了MINERVA三次独立运行的平均值和标准差。我们发现在几次运行中很容易获得/重现最高的分数,这可以从分数的低偏差中看出。
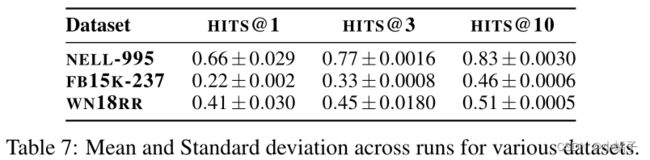 表7:不同数据集的平均值和标准差。
表7:不同数据集的平均值和标准差。
记忆路径历史的有效性
MINERVA利用lstm对其过去所做决策的历史进行编码。为了测试记忆决策序列的重要性,我们做了一项消融研究,在该研究中,agent仅根据局部信息(即当前实体和查询)选择下一个行动,而不访问历史信息。对于亲属关系数据集,我们观察到HITS@1减少了27%,HITS@10减少了13%。对于网格世界,我们看到性能的大幅下降也不足为奇。对于长度为2-4的路径,最终精度为0.23,对于长度为8-10的路径,最终精度为0.04。对于FB15K-237, HITS@10的性能从0.456下降到0.408
NO-OP和逆关系
在每一步,MINERVA可以选择采取一个NO-OP边缘,并保持在同一个节点。这给了代理采用可变长度路径的灵活性。有些问题比其他问题更容易回答,需要的推理步骤更少,如果agent提前得到答案,它可以选择留在那里。表8中的示例(i)显示了这样一个示例。类似地,反向关系赋予代理从以前做出的可能错误的决定中恢复的能力。例(ii)展示了这样一个例子,agent在第一步做出了错误的决定,但由于倒立边的存在,它能够恢复原来的决定。

表8:MINERVA在国家和NELL上发现的一些路径示例。MINERVA可以根据国家数据集的要求学习一般规则(例(i))。如果有必要,它可以学习更短的路径(示例(ii)),并有能力纠正之前做出的决定(示例(iii))
4.相关工作
使用张量因子分解学习实体和关系的向量表示或神经方法是一种流行的基于知识库的推理方法。然而,这些方法不能捕获更复杂的推理模式,如通过在KBs中遵循推理路径发现的模式。多跳链路预测方法解决了上述问题,但它们操作的推理路径是通过执行独立于查询关系类型的随机游走来收集的。Lao等人(2011)进一步根据路径必须结束于训练集中的目标实体之一且长度在最大范围内的限制,从采样路径集中过滤路径。这些约束使它们依赖于查询,但它们本质上是启发式的。我们的方法消除了任何预先计算路径的必要性,并学会了根据输入查询关系有效地搜索图。
归纳逻辑规划(ILP) 旨在从实例和背景知识中学习通用谓词规则。ILP的早期工作,如FOIL,要么是基于规则的,要么需要负面的例子,这通常很难在KBs中找到(通过设计,KBs存储真实的事实)。统计关系学习方法以及概率逻辑将机器学习和逻辑结合起来,但这些方法操作的是符号而不是向量,因此不具有基于嵌入的方法的泛化特性。
很少有研究将推理视为对自然语言空间的搜索。Nogueira和Cho(2016)提出了一个任务(WikiNav),其中图中的每个节点都是维基百科页面,边缘是到其他维基页面的超链接。实体将由页面中的文本表示,因此需要代理在自然语言空间上进行推理,以便在图中导航。与WikiNav类似的是Wikispeedia (West et al., 2009),其中代理需要学习以尽可能快的速度遍历给定的目标实体节点(wiki页面)。Angeli和Manning(2014)提出了自然逻辑推理,他们将推理转换为从查询到任何有效前提的搜索。在每个步骤中,动作都是MacCartney & Manning(2007)引入的七个词汇关系之一。
神经定理证明程序(NTP) (Rockt¨aschel & Riedel, 2017)和神经LP (Y¨aschel & Riedel, 2017)是学习逻辑规则的方法,可以通过基于梯度的学习进行端到端训练。利用Prolog的向后链推理方法构造ntp。它作用于向量而不是符号,因此为每个证明路径提供一个成功分数。但是,由于任意两个向量之间可以计算一个分数,在逆向链代入步骤中,由于这种软匹配,计算图变得相当大。为了便于处理,它求助于启发式方法,例如只保留top-K评分证明路径,以保证精确的梯度。此外,NTPs的疗效尚未在大型KBs上显示出来。神经LP引入了一种差分规则学习系统,使用TensorLog中定义的操作符(Cohen, 2016)。它有一个基于LSTM的控制器,具有可微内存组件(Graves等人,2014;Sukhbaatar等人,2015),规则得分通过注意力计算。尽管可微分内存允许端到端训练,但它需要访问整个内存,这可能是计算昂贵的。能够硬选择记忆的RL方法(Zaremba & Sutskever, 2015)在计算上很有吸引力。MINERVA使用类似的关系边硬选择在图上行走。更重要的是,MINERVA在它们各自的基准数据集上都优于这两种方法。
DeepPath (Xiong等人,2017)使用基于RL的方法在KBs中找到路径。然而,他们的MDP的状态要求目标实体提前被知道,因此他们的寻路策略依赖于知道答案实体。MINERVA不需要目标实体的任何知识,而是学习在所有实体中寻找答案实体。此外,DeepPath还将其收集到的路径提供给路径排名算法(Lao et al., 2011),而MINERVA是一个完整的系统,用于进行查询回答。DeepPath也使用固定的预训练嵌入它的实体和关系。最后,在比较MINERVA和DeepPath在他们的实验设置在NELL数据集上,我们匹配他们的性能或超过他们。MINERVA也类似于学习搜索结构化预测的方法。这些方法基于模仿引用策略(oracle),在每一步做出接近最优的决策。在我们的问题设置中,不清楚什么是好的参考策略。例如,两个实体之间的最短路径oracle是不理想的,因为提供路径的答案应该依赖于查询关系。
5.结论
我们探索了一种在大型知识库上进行自动推理的新方法,即利用知识库的知识图表示,训练agent根据输入的查询信息走到答案节点。我们在多个基准知识库完成任务上取得了最先进的结果,我们还展示了我们的模型是稳健的,可以学习长链推理。此外,它不需要预先培训或最初的监督。未来的研究方向包括应用更复杂的RL技术和直接处理文本查询和文档。