谷歌年度AI技术总结来了!Jeff Dean执笔,附赠27个开源工具和数据大礼包
杨净 梦晨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Jeff Dean亲笔盘点谷歌AI研究成果,已经成了一年一度的保留节目。
今年也不例外,还是他抽出一部分假期时间完成的。
过去一年,谷歌研发投入依然是全球最高,在一整年的时间里产出不少成果。
光论文数就达750+篇,让人眼花缭乱。
如果你担心自己错过了一些的话也不用担心,这位谷歌AI掌门人都帮你总结好了。

Jeff本人亲眼目睹了AI过去几十年的诸多进展,对当下最大的感触是:
早期机器学习方法往往不尽如人意,不过终于催生出了很多非常成功的现代方法,这些进步最终将惠及数十亿人的生活。
他把2021年机器学习进展总结成五大趋势,另外还给读者送上一份大礼包——
一年来谷歌发布的27个开源工具和数据集汇总。
涵盖多语言文本、医学、建筑、舞蹈动作、电影标题、文本到表格生成等众多领域。
如果你有需要可在公众号后台回复关键词“姐夫2021”获取。
下面就先来看一下,这个被誉为行业风向标,Jeff眼中的机器学习五大趋势都有哪些。
简单速览:
趋势1:模型更大让AI能力更通用
趋势2:机器学习效率持续提高
趋势3:AI应用对个人更有益
趋势4:AI推动科学研究和医学健康
趋势5:对机器学习的理解加深
趋势1:模型更大让AI能力更通用
过去一年中,语言模型的参数规模仍在不断增长,纷纷超过1750亿的GPT-3。
例如DeepMind的Gopher有2800亿,微软英伟达联合推出的威震天-图灵到了5300亿。
谷歌自己的GShard和GLaM模型更是达到6千亿和1.2万亿。
训练这些模型用到的数据集规模也在同步增长。
数据集和模型大小的增加让AI在传统NLP任务上的准确性显著提高,还在更多新能力上有所突破。
代表性的研究有Quoc Le团队提出新的微调方法Instruction Tuning。
新模型FLAN在没训练过的任务上的零样本学习能力超过GPT-3少样本版本的表现。
以及谷歌I/O大会上所演示的LaMDA模型,在开放式多轮对话上有所突破。

除了语言模型,图像、视频方面这一年都被Transformer架构同时刷新了模型规模和性能基准。
谷歌在这方面代表性的研究便是Vision Transformer(ViT)以及Video ViT。
另外还有一个重要的结论是,同时用图像和视频数据训练可以提高模型在视频任务的性能。

图像生成上,这一年里扩散模型 (Difusion Model)成了GAN的有力竞争对手。
级联(Cacade)扩散模型SR3以低分辨率图像为输入,便可从纯噪声中构建出对应的高分辨率图像。
多模态模型方面,模型规模的增大还让机器人get新能力。
机械臂只需要学会自然语言描述的“把葡萄放在碗中”这项任务,便可执行“把水瓶放在托盘中”的全新任务。
Jeff总结到,这些大模型通常使用自监督学习方法,这个趋势令人兴奋。
一方面可以大大减少工作量,另一方面在长尾任务中也能取得更好表现。
谷歌AI下一步的努力方向是研发一个叫Pathway的稀疏模型新架构,把它训练成可以执行成千上万种任务的通用模型。
趋势2:机器学习效率持续提高
参数规模和数据量的扩大,对模型的训练效率提出了新的挑战。
作为应对,谷歌在加速芯片、编译器、模型架构和算法方面分别取得了进展。
芯片方面,新发布的TPUv4与上一代相比性能提高2.7倍,用高速网络连接在一起可以支持超大模型的训练。
移动设备上,新一代Pixel6手机上搭载全新的Tensor处理器,在手机上做到4k60帧视频处理,以及实时机器翻译。

编译器方面,谷歌推出基于XLA编译器的自动并行化系统GSPMD。
即使硬件没有进步,也能做到在150种模型上性能全面提高5%-15%,甚至个别情况下提高了2.4倍。

这一成果已经用在了GShard-M4、LaMDA、ViT等多个大模型上。
架构方面,一种提升效率的方法是靠人类的创造力设计。
这里还是要说到Transformer的各类变体在这一年中大放异彩,同时在NLP和CV领域频频刷榜。
另一种方法便是机器驱动的神经架构搜索(NAS),大大减少算法开发的工作量。
虽然NAS本身的计算量很大、成本高昂,但总体上可以显著降低下游开发和生产环境中的计算量。
如NAS方法搜索出来的Evovled Transformer,在参数减少37.6%的情况下获得0.7%的英德翻译性能提升。
视觉任务上,NAS方法得到的Efficientnetv2模型训练速度比之前的SOTA模型提高了5-11倍。
除了模型架构,AutoML-Zero还使用NAS方法来寻找新的、更有效的强化学习/监督学习算法。
算法方面,增加对稀疏性(Sparsity)的利用是一个重要进展。
谷歌稀疏的Switch Transformers与密集的T5模型相比,训练效率提高了7倍。
GLaM模型把Transformer与Mixer of Expert风格的层结合起来,训练和推理成本与GPT-3相比分别减少了3倍和2倍。
另外,BigBird模型用稀疏性降低了Transformer的核心机制——注意力模块的计算成本。

尽管稀疏性取得如此多成绩,Jeff Dean还是认为目前的研究仅触及了这个方向上的皮毛。
未来更继续深入研究还有更高的潜在回报。
趋势3:AI应用对个人更有益
除此之外,Jeff Dean还关注到移动设备上的个性化AI应用。
得益于ML的发展与处理器的创新,手机可以更加连续有效地感知周围环境,用户体验也更加丰富。
对一些日常使用的功能,比如计算摄影、实时翻译等都带来了改变。与此同时,还加强了隐私保护。
以计算摄影HDR+功能为例,即便在非常暗的光线下拍照,也能展现更真实的情况。

跨语言实时交流也成为一大趋势。由于自监督学习、noisy student training自训练算法等技术的发展,语音识别的准确性继续取得重大进展,嘈杂、重叠语音等环境以及跨语言的效果有了明显改善。
日常交互也变得越来越自然,比如自动呼叫、机器学习代理,即使经常执行的简短任务,也可通过智能文本选择工具进行改进。
还有一些小例子也体现出AI的有益之处,比如注视识别技术,防止你看手机屏幕时变暗。

机器学习在确保个人和社区安全上也提供新方法。
比如“可疑信息警告”来应对疑似网络钓鱼攻击,“安全路线”可以帮助识别和检测什么时候该踩刹车,提示备用路线。
鉴于构成这些新功能的数据具有敏感性,隐私计算也就搬到了台前。
安卓系统可确保私有计算核心处理的数据不被任何APP共享,与此同时还阻止了其内部的任何功能直接访问网络。

趋势4:AI推动科学研究和医学健康
近年来,我们已经看到机器学习对基础科学的影响越来越大,从物理学到生物学,有很多令人兴奋的实际应用。
计算机视觉作为典型,已经应用于解决个人和全球范围的问题。
它既可以帮助医生进行日常工作,扩展对神经生理学的理解,也可以提供天气预报预测以及救灾工作的优化。
去年,谷歌与哈佛合作展开了第一个大规模人类大脑皮层突触连接的研究,重建了人类大脑组织成像。
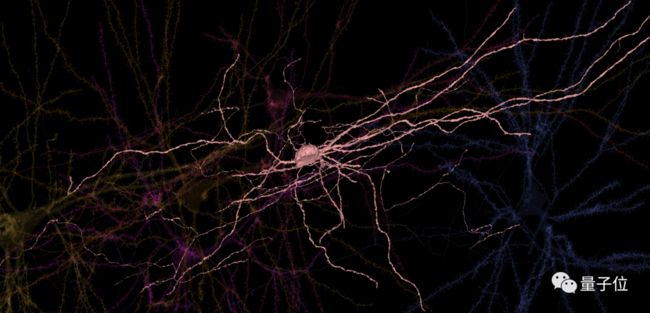
ps:图中显示了成人大脑860亿个神经元中的6个
而若向外延伸,计算机视觉在应对全球挑战上也有突出的作用,比如基于深度学习的天气预测,预报12小时内的天气和降水,比传统的物理模型更准确。

还有像在文档、游戏,包括芯片上的自动化设计布局,以及在医学、人类健康、应对气候变化上的关键作用也不容忽视。
以医学健康为例,在基因组学的研究中机器学习可以帮助处理序列数据,看到基因组数据的隐藏特征,还能加速对个性化、健康的基因组信息的使用。
Jeff Dean还强调在疾病诊断,尤其是在医学成像上的应用,比如在改善乳腺癌筛检、检测肺癌、加速癌症的放射治疗、标记异常X射线和前列腺癌期活检等领域。

另一个值得关注的方向就是利用NLP技术来分析结构化数据与医疗记录,辅助临床医生提供更准确的诊断护理。
尽管机器学习对于扩大获取途径和提高临床诊断的准确性非常重要,但我们看到一个同样重要的新趋势正在出现:智能手机上的健康功能,帮助用户对自己的健康状况进行评估。
趋势5:做负责任的人工智能
随着机器学习越来越广泛地应用于社会中去,保证其更公平公正的使用正成为下一个技术出发点。
一个重点领域就是基于用户活动的推荐系统,最近工作揭示了如何提高单个组件和整个推荐系统的公平性。
在机器翻译上的应用也同样重要,因为大多数机器翻译系统是孤立地翻译单个句子的,没有附加的语境。
它们往往会加强与性别、年龄或其他领域有关的偏见。去年谷歌发布了个数据集,用于研究翻译维基百科传记时的性别偏见。

部署机器学习模型的另一个常见问题是分布转移。如果模型所依据的数据统计分布与所输入的数据统计分布不一致,那么模型的行为可能是不可预测的。
在最近的工作中,谷歌Deep Bootstrap框架可以帮助比较、理解模型在这两种情况下的表现,使得模型更好适应未知环境,并对固定的训练数据集不会产生太大的偏见。
除此之外在机器学习上游——数据收集和数据集管理上,也有相应的探索。
还有像处理网上辱骂行为、模型的交互式分析和调试、机器学习的可解释性(以AlphaZero国际象棋系统为典型),以及改善社区生活等维度都是谷歌解决的方向。
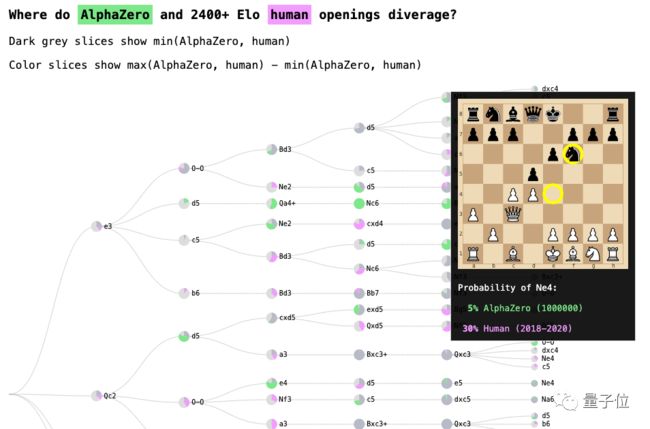
总之,再三强调一个愿景:做负责任的人工智能。
One More Thing
在这篇博文下互动区,看到了熟悉的身影。
那就是让Jeff Dean陷入歧视风波的那位前员工Timnit Gebru,她也转发了一波~
不过,这画风……嗯,就有点尴尬。

好了,感兴趣的旁友,可戳下方链接看详细报告~
以及别忘了到公众号后台回复“姐夫2021”,获取27个谷歌开源工具及数据集汇总。
直达链接:
https://ai.googleblog.com/2022/01/google-research-themes-from-2021-and.html