因果分析系列6--相关,回归与因果
因果分析系列6--相关,回归与因果
- 相关与因果
- 相关与回归
- 回归与因果
-
- 回归理论
- 非随机数据的回归分析
相关,回归和因果这些是统计和机器学习中经常提到的一些术语,它们均可通过观测数据定义定义不同变量之间的基本关系。这三个术语在定义上是完全不同的,但现实中相关和因果经常被混淆使用,回归和相关也常被严重曲解。当这些术语在一个熟悉的相似空间出现时,经常令人产生困惑。前面第一节提到了 相关与因果,第五节从偏差角度侧面提到了 因果与回归
相关与因果
相关性和因果性之间的联系,从统计学教材到大数据著作,都有着广泛的探讨,甚至争议不断。迈尔舍恩伯格在《大数据时代》里说,“要相关,不要因果”,在大数据时代,有相关,就够了。而周涛则在《为数据而生》一书中说,放弃对因果关系的追寻,就是人类的自我堕落,相关性分析是寻找因果关系的利器,能够为因果关系的发现提供一点思路。但两个变量之间存在相关关系,不一定说明两者之间存在着因果关系。因果关系,是指一个变量的存在一定会导致另一个变量的产生。而相关性是统计学上的一个概念,是指一个变量变化的同时,另一个因素也会伴随发生变化,但不能确定一个变量变化是不是另一个变量变化的原因。比如天气冷和下雪通常一起发生,说明两者有很强的相关性,但不能肯定是谁导致了谁,所以不确定两者是够有因果关系。
相关与回归
联系:1.无相关就无回归,相关程度越高,回归方程的拟合程度就越好;2.相关系数和回归系数的方向一致,可以相互推算。
区别:1.相关分析中x和y对等,回归分析中x和y要确定自变量和因变量;2.相关分析中x、y均为随机变量,回归分析中只有因变量为随机变量;3.相关分析测定相关程度和方向,回归分析用回归模型进行预测和控制。
续
回归与因果
在处理因果推断时,我们看到了每个个体有两种可能的结果: Y 0 Y_0 Y0是个体不接受处理时的结果, Y 1 Y_1 Y1是个体接受处理后的结果。现实中我们只能观测到个体的处理状态 T T T为0或1的一个潜在的结果,而不可能知道另一个结果。这就导致了个体处理效应是不可知的。
Y i = Y 0 i + T i ( Y 1 i − Y 0 i ) = Y 0 i ( 1 − T i ) + T i Y 1 i Y_i = Y_{0i} + T_i(Y_{1i} - Y_{0i}) = Y_{0i}(1-T_i) + T_i Y_{1i} Yi=Y0i+Ti(Y1i−Y0i)=Y0i(1−Ti)+TiY1i
所以,现实中通常是估计平均因果关系。如假设有些个体接受处理后的结果比其他人好,但我们不知道他们具体是谁。相反,我们只想看看这种处理方式平均而言是否有效。
A T E = E [ Y 1 − Y 0 ] ATE = E[Y_1 - Y_0] ATE=E[Y1−Y0]
这将给我们一个简化的模型,具有恒定的处理效应 Y 1 i = Y 0 i + κ Y_{1i} = Y_{0i} + \kappa Y1i=Y0i+κ。如果 κ \kappa κ是正值,则平均来看,处理有积极效应。即使部分个体存在负向处理效应,但平均来说,效应也是积极的。
由于存在偏差,无法简单地用均值差异 E [ Y 1 − Y 0 ] E[Y_1 - Y_0] E[Y1−Y0]来估计 E [ Y ∣ T = 1 ] − E [ Y ∣ T = 0 ] E[Y|T=1] - E[Y|T=0] E[Y∣T=1]−E[Y∣T=0]。当处理组和未处理组由于处理本身以外的原因而不同时,往往会产生偏差。一种方法是看它们在潜在结果上的差异
E [ Y ∣ T = 1 ] − E [ Y ∣ T = 0 ] = E [ Y 1 − Y 0 ∣ T = 1 ] ⏟ A T T + { E [ Y 0 ∣ T = 1 ] − E [ Y 0 ∣ T = 0 ] } ⏟ B I A S E[Y|T=1] - E[Y|T=0] = \underbrace{E[Y_1 - Y_0|T=1]}_{ATT} + \underbrace{\{ E[Y_0|T=1] - E[Y_0|T=0]\}}_{BIAS} E[Y∣T=1]−E[Y∣T=0]=ATT E[Y1−Y0∣T=1]+BIAS {E[Y0∣T=1]−E[Y0∣T=0]}
通过随机对照试验(RCT)可消除偏差。我们研究了在线课堂和面对面课堂的对比,其中 T = 0 T=0 T=0代表面对面授课, T = 1 T=1 T=1代表在线授课。学生被随机分配到这两种类型的中的一种,然后对他们的考试成绩进行评估。我们已经建立了一个A/B测试函数,可以比较两组,得到平均处理效应,借助线性回归 在其在得到对应的置信区间。
在下面可通过简单的代码进行示例,我们希望运行完全相同的分析来比较在线类和面对面类。但是我们没有做所有置信区间的数学运算,我们只是做一个回归。更具体地说,我们估计以下模型:
e x a m i = β 0 + κ O n l i n e i + u i exam_i = \beta_0 + \kappa \ Online_i + u_i exami=β0+κ Onlinei+ui
注意: O n l i n e Online Online是二值0,1处理特征,是一个虚拟变量。 T = 0 T=0 T=0表示面对面教学, T = 1 T=1 T=1表示在线教学。考虑到这一点,我们可以看到线性回归将恢复 E [ Y ∣ T = 0 ] = β 0 E[Y|T=0] = \beta_0 E[Y∣T=0]=β0和 E [ Y ∣ T = 1 ] = β 0 + κ E[Y|T=1] = \beta_0 + \kappa E[Y∣T=1]=β0+κ。 κ \kappa κ即为ATE。
线上标准考试数据online_classroom.csv下载
#加载包
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
import graphviz as gr
%matplotlib inline
data = pd.read_csv("data/online_classroom.csv").query("format_blended==0")
result = smf.ols('falsexam ~ format_ol', data=data).fit()
result.summary().tables[1]

上文结果中不仅能够估计ATE,而且还可以获得置信区间和P值。而且回归正在比较 E [ Y ∣ T = 0 ] E[Y | T=0] E[Y∣T=0]和 E [ Y ∣ T = 1 ] E[Y | T=1] E[Y∣T=1]。截距正好是当 T = 0 T=0 T=0时的样本平均数, E [ Y ∣ T = 0 ] E[Y | T=0] E[Y∣T=0],而在线的系数正好是样本平均数差 E [ Y ∣ T = 1 ] − E [ Y ∣ T = 0 ] E[Y | T=1]-E[Y | T=0] E[Y∣T=1]−E[Y∣T=0]。不相信我?没问题。你可以亲眼看到:
(data.groupby("format_ol")["falsexam"].mean())
format_ol
0 78.547485
1 73.635263
Name: falsexam, dtype: float64
和预期一致,如果将ATE(即在线形式的参数估计)添加到截距中,则得到处理后的样本均值:78.5475+(−4.9122)=73.635263 。
回归理论
此处不深入研究线性回归是如何构造和估计的。仅学习其在因果推理中有用的理论。首先,回归是解决理论上线性预测问题的最好方法之一。设 β ∗ \beta^* β∗为参数向量:
β ∗ = a r g m i n β E [ ( Y i − X i ′ β ) 2 ] \beta^* =\underset{\beta}{argmin} \ E[(Y_i - X_i'\beta)^2] β∗=βargmin E[(Yi−Xi′β)2]
线性回归找出使均方误差(MSE)最小的参数。
若将它微分并设为零,则这个问题的线性解为
β ∗ = E [ X i ′ X i ] − 1 E [ X i ′ Y i ] \beta^* = E[X_i'X_i]^{-1}E[X_i' Y_i] β∗=E[Xi′Xi]−1E[Xi′Yi]
我们可以使用等效样本来估计:
β ^ = ( X ′ X ) − 1 X ′ Y \hat{\beta} = (X'X)^{-1}X' Y β^=(X′X)−1X′Y
可通过代码对上面的公式进行验证:
X = data[["format_ol"]].assign(intercep=1)
y = data["falsexam"]
def regress(y, X):
return np.linalg.inv(X.T.dot(X)).dot(X.T.dot(y))
beta = regress(y, X)
beta
array([-4.9122215 , 78.54748458])
在因果推理中,我们经常要估计变量T对结果y的因果效应。所以,可用单变量回归来估计这个效应。即使在模型中加入其它变量,它们通常也只是辅助变量。添加其他变量可以帮助我们估计处理的因果关系,但并不是我们关注的重点。
对于单个回归变量T,与其相关的参数将由
β 1 = C o v ( Y i , T i ) V a r ( T i ) \beta_1 = \dfrac{Cov(Y_i, T_i)}{Var(T_i)} β1=Var(Ti)Cov(Yi,Ti)
若T是随机分配的,则 β 1 \beta_1 β1即为ATE。
kapa = data["falsexam"].cov(data["format_ol"]) / data["format_ol"].var()
kapa
-4.912221498226952
若为多元线性回归,则回归方程为如下形式。设自变量中除处理变量T之外,其它变量均为控制变量,我们希望估计与 T T T相关的参数 κ \kappa κ。
y i = β 0 + κ T i + β 1 X 1 i + . . . + β k X k i + u i y_i = \beta_0 + \kappa T_i + \beta_1 X_{1i} + ... +\beta_k X_{ki} + u_i yi=β0+κTi+β1X1i+...+βkXki+ui
κ \kappa κ可通过以下公式获得
κ = C o v ( Y i , T i ~ ) V a r ( T i ~ ) \kappa = \dfrac{Cov(Y_i, \tilde{T_i})}{Var(\tilde{T_i})} κ=Var(Ti~)Cov(Yi,Ti~)
其中 T i ~ \tilde{T_i} Ti~ 是所有其他协变量 X 1 i + . . . + X k i X_{1i} + ... + X_{ki} X1i+...+Xki在 T i T_i Ti上的回归残差。这意味着多元回归的系数是在考虑了模型中其他变量的影响后,同一回归变量的二元系数。在因果推理术语中, κ \kappa κ是在使用所有其他变量进行预测之后,T的二元系数。
这背后有一个很好的直觉。如果我们可以用其他变量来预测T,那就意味着它不是随机的。但是,一旦我们控制了其他可用变量,我们就可以使T和随机变量一样好。为此,我们使用线性回归从其他变量中进行预测,然后取回归的残差 T ~ \tilde{T} T~ 。根据定义, T ~ \tilde{T} T~ 不能由我们已经用来预测T的其他变量X来预测。 T ~ \tilde{T} T~是处理的一个版本,它与X中的任何其他变量都没有关联。
顺便说一下,这也是线性回归的一个性质。残差始终与创建它的模型中的任何变量正交或不相关:
e = y - X.dot(beta)
print("Orthogonality imply that the dot product is zero:", np.dot(e, X))
X[["format_ol"]].assign(e=e).corr()

更酷的是,这些属性并不依赖于任何东西!不管你的数据看起来如何,它们都是数学真理。
非随机数据的回归分析
到目前为止,我们使用的是随机实验数据,但据我们所知,这些数据很难获得。实验费用很高,或者根本不可行。很难说服麦肯锡公司随机免费提供他们的服务,这样我们就可以一劳永逸地将他们的咨询服务带来的价值与那些支付得起的公司已经非常富裕的事实区分开来。
因此,我们现在将深入研究非随机或观测数据。在下面的例子中,我们将试图估计额外一年的教育对小时工资的影响。正如你可能已经猜到的,进行教育实验是极其困难的。你不能简单地把人们随机分为4年,8年或12年的教育。在这种情况下,我们只有观测数据。
首先,让我们估计一个非常简单的模型。我们将把每小时工资按受教育年限递减。我们在这里使用log,以便我们的参数估计有一个百分比解释。有了它,我们就可以说多受一年的教育,工资就增加了x%。
l o g ( h w a g e ) i = β 0 + β 1 e d u c i + u i log(hwage)_i = \beta_0 + \beta_1 educ_i + u_i log(hwage)i=β0+β1educi+ui
wage = pd.read_csv("./data/wage.csv").dropna()
model_1 = smf.ols('np.log(wage) ~ educ', data=wage).fit()
model_1.summary().tables[1]

β 1 \beta_1 β1的点估计值为0.0529,95%置信区间下其区间预测结果为(0.040,0.066)。这意味着该模型预测,每增加一年的教育,工资就会增加5.3%。这个百分比的增长与教育以指数方式影响工资的观点是一致的:我们预计8到9年这一年的教育增加比2到3年这一年的教育回报更高。
from matplotlib import pyplot as plt
from matplotlib import style
style.use("fivethirtyeight")
x = np.array(range(1, 25))
plt.plot(x, np.exp(2.2954 + 0.0529 * x))
plt.xlabel("Years of Education")
plt.ylabel("Hourly Wage")
plt.title("Impact of Education on Hourly Wage")
plt.show()
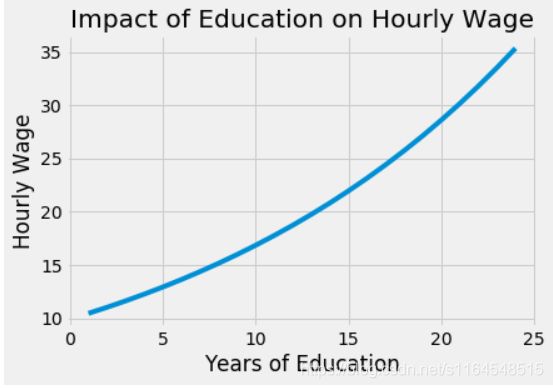
当然,并不是因为这个简单的模型可估计,它就是正确的。我们说它利用教育年限预测工资,但从未说过这个预测是因果关系。事实上,到现在为止,你可能有非常充分的理由相信这个模型是有偏差的。因为我们的数据不是来自随机实验,所以我们不知道那些受教育程度高的人和受教育程度低的人是否具有可比性。更进一步地说,依据我们对世界的理解,可以确定它们是不可比的。也就是说,那些受教育年限较长的人可能有更富有的父母,而随着教育程度的提高,我们看到的工资增长只是家庭财富与受教育年限增加之间关系的反映。用数学术语表达,即 E [ Y 0 ∣ T = 0 ] < E [ Y 0 ∣ T = 1 ] E[Y_0|T=0] < E[Y_0|T=1] E[Y0∣T=0]<E[Y0∣T=1],也就是说,即使没有这么多年的教育,那些受过更多教育的人也会有更高的收入。如果你真的对教育持悲观态度,你可以争辩说教育甚至可以通过减少人们的工作年限、减少他们的工作经验来降低工资。
幸运的是,在我们的数据中,我们可以访问许多其他变量。我们可以看到父母的教育程度,智商,经验年限,以及在他或她现在公司的任职年限。我们甚至还有一些关于婚姻和黑人种族的虚拟变量。
wage.head()
我们可以在模型中包含所有这些额外的变量,并对其进行估计:
l o g ( h w a g e ) i = β 0 + κ e d u c i + β X i + u i log(hwage)_i = \beta_0 + \kappa \ educ_i + \pmb{\beta}X_i + u_i log(hwage)i=β0+κ educi+βββXi+ui
为了理解这如何帮助解决偏差问题,让我们回顾一下多元线性回归的二元分解。
κ = C o v ( Y i , T i ~ ) V a r ( T i ~ ) \kappa = \dfrac{Cov(Y_i, \tilde{T_i})}{Var(\tilde{T_i})} κ=Var(Ti~)Cov(Yi,Ti~)
这个公式说我们可以从父母的受教育程度、智商、经验等等来预测教育程度。完成后,我们将得到一个版本的 e d u c ~ \tilde{educ} educ~,它与前面包含的所有变量都不相关。这将打破诸如“受教育年限较长的人之所以受教育是因为他们的智商较高”之类的论点。教育导致更高的工资并非如此。它只是与智商相关,并不是驱动工资变化。如果我们在模型中加入智商,那么 κ \kappa κ就变成了保持智商不变的条件下,每增加一年教育额外增加的教育回报。这意味着即使我们不能使用随机对照试验来保持处理组和未处理组的其他因素相等,回归也可以通过在模型中包含这些相同的因素来做到这一点,即使数据不是随机的!
controls = ['IQ', 'exper', 'tenure', 'age', 'married', 'black',
'south', 'urban', 'sibs', 'brthord', 'meduc', 'feduc']
X = wage[controls].assign(intercep=1)
t = wage["educ"]
y = wage["lhwage"]
beta_aux = regress(t, X)
t_tilde = t - X.dot(beta_aux)
kappa = t_tilde.cov(y) / t_tilde.var()
kappa
0.04114719101006202
上面的这个系数 κ \kappa κ告诉我们,对于智商、经验、任期、年龄等都相同的人,我们预测其每增加一年的教育会使小时工资增加4.11%。这证实了我们的怀疑,即第一个只有“educ”的简单模型具有偏差。这也证实了这种偏差高估了教育的影响。一旦我们控制了其他因素,教育的影响就会下降。
model_2 = smf.ols('lhwage ~ educ +'+"+".join(controls), data=wage).fit()
model_2.summary().tables[1]
