Low-Light Image Enhancement via Edge-Enhanced Multi-Exposure Fusion Network阅读札记
Low-Light Image Enhancement via Edge-Enhanced
Multi-Exposure Fusion Network阅读札记
Multi-Exposure Fusion Network阅读札记
论文发表于2020年的AAAI Technical Track : Vision。
Abstract
本文目标:
恢复弱光图像细节,减少噪声和颜色偏差,保持锐利的边缘。
现存问题:
(1)无法从极暗/亮的区域恢复曝光良好的图像细节。
(2)若没有良好曝光的图像信息,现有的模型可能会由于弱光图像和 g t gt gt之间的颜色偏差而遭受颜色失真。
(3)在弱光图像中,当物体边缘不清晰时,像素级 l o s s loss loss会使边缘模糊,破坏图像细节。
本文提出: 边缘增强多曝光融合网络(EEMEFN)
第一阶段:采用多重曝光融合(MEF)模块来解决高对比度和色偏问题。
第二阶段:引入一个边缘增强(EE)模块,在边缘信息的帮助下锐化initial image。
贡献:
(1)提出了一种新的具有融合块的多曝光融合模型,与不同光照条件的生成图像相结合,从而解决高对比度和颜色偏差问题。
(2)引入一个边缘增强模块来增强具有锐利边缘和精细结构的图像。
Method
算法框架图
EEMEFN包括两个阶段:
(1)多曝光融合——首先在不同的光照条件下生成多幅图像,然后将图像融合成一幅高质量initial image。
(2)边缘增强——从iitial image获得边缘映射,并结合边缘信息生成final image。
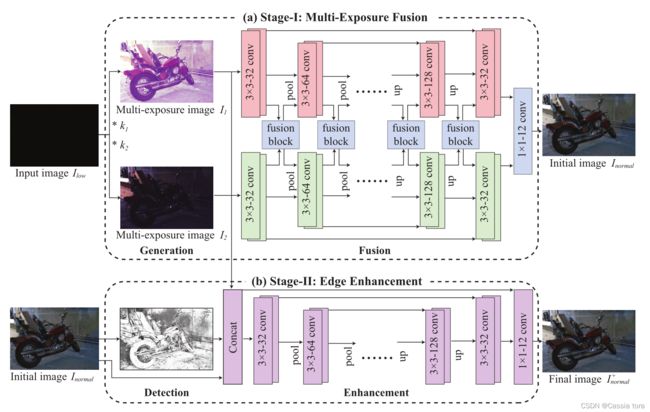
1、第一阶段:多曝光融合
多曝光融合(MEF)模块包括两个主要步骤:生成和融合。
(1)生成——将raw image在不同的光照条件下生成一组多曝光图像。
(2)融合——将生成图像的曝光良好区域融合到一个initial image中。
生成
给定一张raw image I l o w ∈ R ( H × W × 1 ) I_{low}∈R^{(H×W×1)} Ilow∈R(H×W×1)和一组曝光率 k 1 , k 2 , … , k N {k_1,k_2,…,k_N} k1,k2,…,kN,生成一组多曝光图像 I = I 1 , I 2 , … , I N I={I_1,I_2,…,I_N} I=I1,I2,…,IN。第 i i i个图像定义为:
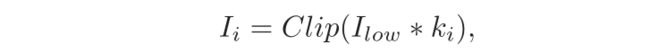
C l i p ( x ) Clip(x) Clip(x): C l i p ( x ) = m i n ( x , 1 ) Clip(x) = min(x,1) Clip(x)=min(x,1),如果像素值超过最大值1,则进行像素剪裁。
融合
MEF模块将生成的一组多曝光图像 I = I 1 , I 2 , … , I N I={I_1,I_2,…,I_N} I=I1,I2,…,IN的曝光良好区域进行融合,以获得initial image I n o r m a l I_{normal} Inormal:

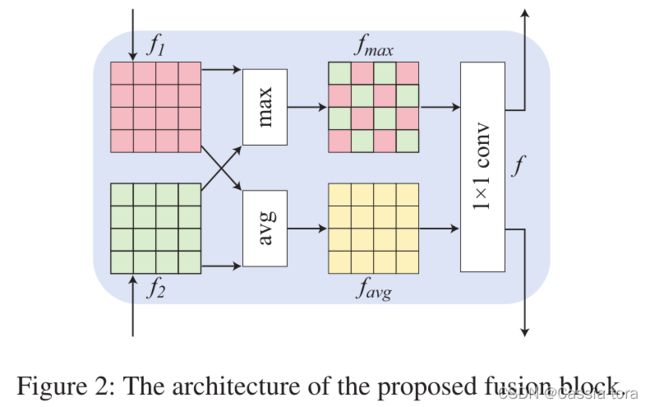
具体步骤如下:
第一步: 每个图像由具有相同架构的U-net分支处理(在U-net中添加了跳跃连接,以帮助在不同尺度下重建细节)。
第二步: 融合模块将不同分支获得的图像特征结合起来,以互补的方式充分利用有价值的信息(如上图所示)。融合块采用排列不变技术[1]构建,在特征之间进行更多聚合操作。因此,MEF模块可以从黑暗区域恢复精确的图像细节,并使颜色分布更接近地面真相。每个融合块从 N N N个分支中提取 N N N个图像特征 f 1 , f 2 , … , f N ∈ R ( c × h × w ) f_1,f_2 ,…,f_N∈R^{(c×h×w)} f1,f2,…,fN∈R(c×h×w)作为输入,并执行最大和平均运算以提取有价值的信息。
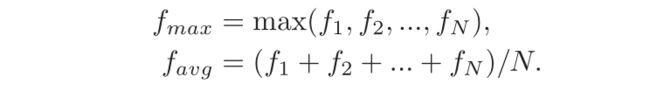
第三步: 将特征 f m a x f_{max} fmax和 f a v g f_{avg} favg转换为输入特征空间,并将它们重新输入到每个分支。
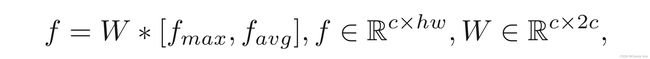
[ ⋅ , ⋅ ] [·,·] [⋅,⋅]:串联操作
f f f:输出特征
W W W:学习的权重矩阵。
第四步: 将所有分支的最后一个特征连接在一起,并输入 1 × 1 1×1 1×1 的Conv层,通过联合学习所有分支来产生所需的输出。
⭐损失函数定义为MEF模块输出 I n o r m a l I_{normal} Inormal与 g t gt gt之间的 l 1 l1 l1损失:
![]()
2、第二阶段:边缘增强
边缘增强(EE)模块包含两个主要步骤:检测和增强。
(1)检测——从initial image生成边缘映射。
(2)增强——利用边缘信息,生成颜色一致的更平滑的目标表面,并恢复丰富的纹理和锐利的边缘。
检测
使用边缘检测网络[2]来预测 I n o r m a l I_{normal} Inormal的边缘 E ∈ R ( H × W × 1 ) E∈R^{(H×W×1)} E∈R(H×W×1), E = D e t e c t i o n ( I n o r m a l ) E=Detection(I_{normal}) E=Detection(Inormal),再利用边缘信息指导高质量图像的重构。边缘检测网络由五个阶段组成,每个阶段利用卷积层的所有激活函数来执行像素级预测 ( E 1 , E 2 , E 3 , E 4 , E 5 ) (E_1,E_2,E_3,E_4,E_5) (E1,E2,E3,E4,E5)。最后,采用融合层对各个阶段的CNN特征进行仔细的融合。边缘检测网络可以获得精确的边缘图 E E E。
使用两个类平衡权 α α α和 β β β来抵消边缘/非边缘像素的分布的严重不平衡。预测的边缘图 E i E_i Ei和地面真值 E g t = ( e j , j = 1 , … , ∣ E g t ∣ ) , e j = 0 , 1 E_{gt}=(e_j,j=1,…,|E_{gt} |),e_j={0,1} Egt=(ej,j=1,…,∣Egt∣),ej=0,1之间的边缘损失被定义为相对于像素标签的加权交叉熵损失:
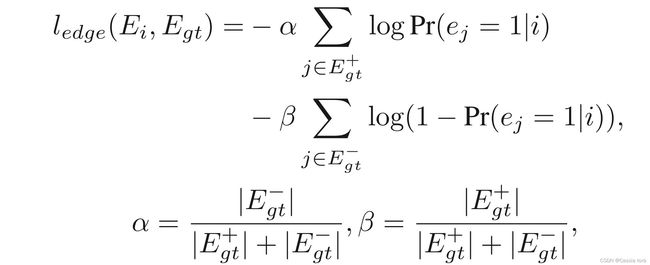
∣ E g t + ∣ , ∣ E g t − ∣ |E_{gt}^+ |,|E_{gt}^- | ∣Egt+∣,∣Egt−∣:边缘和非边缘 E g t E_{gt} Egt标签集的大小
e j = 1 e_j=1 ej=1:像素 j j j处的边缘点
P r ( e j = 1 ∣ i ) Pr(e_j=1|i) Pr(ej=1∣i):阶段 i i i处像素 j j j的预测值。
通过聚合不同阶段和融合层的损失函数计算损失函数: 
增强
采用U-Net架构,以多曝光图像 I = I 1 , I 2 , . . . , I N I = {I_1,I_2,...,I_N } I=I1,I2,...,IN、initial image I n o r m a l I_{normal} Inormal和边缘图 E E E作为输入,将这些图像融合生成最终的增强图像 I n o r m a l + I_{normal}^+ Inormal+。
![]()
损失函数定义为EE模块输出 I n o r m a l + I_{normal}^+ Inormal+与 g t gt gt之间的 l 1 l1 l1损失:
![]()
Experiment
数据集 :See-in-the-Dark数据集由两个图像集组成(Sony集和Fuji集)。
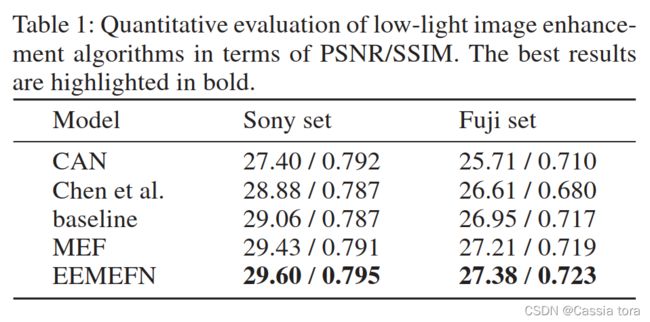
1、定量评估
2、定性评估
References
[1] Aittala M , Durand F . Burst Image Deblurring Using Permutation Invariant Convolutional Neural Networks[J]. Springer, Cham, 2018.
[2] Liu Y, Cheng M M, Hu X, et al. Richer convolutional features for edge detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 3000-3009.