【第二周】卷积神经网络
卷积神经网络基本组成结构
卷积层
卷积是对两个实变函数的一种数学操作。给定一个图像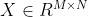 和滤波器
和滤波器![]() ,则
,则![]() ,输出的特征图大小为
,输出的特征图大小为![]() 。输出通道数等于卷积核的个数,卷积核通道数与输入通道数保持相同。
。输出通道数等于卷积核的个数,卷积核通道数与输入通道数保持相同。

池化层
池化层保留了输入的主要特征的同时减少了参数和计算量,防止过拟合,提高模型泛化能力。
它一般处于卷积层与卷积层之间,全连接层与全连接层之间。池化层主要分为最大值池化(Max pooling)和平均池化(Average pooling)两种。
池化不改变通道数。

全连接层
全连接层的两层之间所有神经元都有权重链接,往往接在卷积神经网络尾部,并通常具有最大的参数量。
卷积神经网络典型结构
AlexNet
AlexNet 是具有历史意义的一个网络结构,它在2012年的ImageNet图像分类竞赛中错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。

| 层数 | 说明 | 节点数量 | 参数数量 |
| C1 | 96个11x11x3卷积核 | 55x55x48x2=290400 | 11x11x3x96+96=34848 |
| C2 | 2组128个5x5x48卷积核 | 27x27x128x2=186624 | (5x5x48x128+128)x2=307456 |
| C3 | 384个3x3x256卷积核 | 13x13x192x2=64896 | 3x3x256x384+384=885120 |
| C4 | 2组192个3x3x192卷积核 | 13x13x192x2=64896 | (3x3x192x192+192)x2=663936 |
| C5 | 2组128个3x3x192卷积核 | 13x13x128x2=43264 | (3x3x192x128+128)x2=442624 |
| FC6 | 4096个神经元 | 4096 | (6x6x128x2)x4096+4096=37752832 |
| FC7 | 4096个神经元 | 4096 | 4096x4096+4096=16781312 |
| Output layer | 1000个神经元 | 1000 | 4096x1000+1000=4097000 |
AlexNet 之所以能够成功,深度学习之所以能够重回历史舞台,原因在于以下几点。
1、大数据训练:百万级ImageNet图像数据
2、非线性激活函数:ReLU
ReLU激活函数解决了梯度消失的问题(在正区间),且其计算速度特别快,只需要判断输入是否大于0,收敛速度远快于sigmoid。
3、防止过拟合:Dropout,Data augmentation
DropOut(随机失活):训练时随机关闭部分神经元,测试时整合所有神经元
Data augmentation(数据增强):对输出图像进行平移、翻转、对称和随机crop,改变RGB通道强度,对RGB空间做一个高斯扰动。
4、双GPU实现
ZFNet
ZFNet网络结构与AlexNet相同,将卷积层1中的感受野大小由![]() 改为了
改为了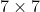 ,步长由4改为2;卷积层3,4,5中的滤波器个数由384,384,256改为512,512,1024。作者认为更小的感受野和步长能提取到更详细的信息。
,步长由4改为2;卷积层3,4,5中的滤波器个数由384,384,256改为512,512,1024。作者认为更小的感受野和步长能提取到更详细的信息。
VGG
VGG是一个更深网络,它从AlexNet的8层网络提升到了16-19层。它首先训练了网络的前11层,在参数固定后再训练后面的层。
GoogleNet
GoogleNet网络包含22个带参数的层(如果考虑pooling层就是27层),独立成块的层总共有约有100个。其参数量大概是Alexnet的1/12,除了最后的类别输出层外没有额外的FC层。
GoogleNet采用inception模块的初衷是希望多卷积核增加特征多样性。
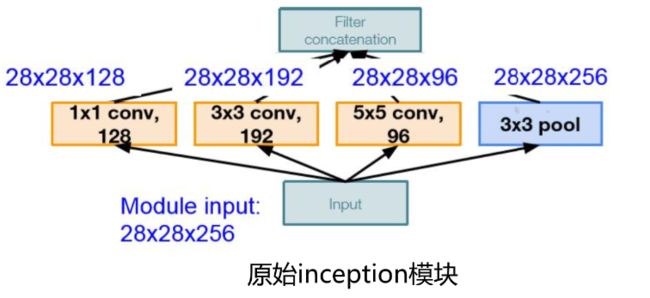
堆叠导致计算复杂度过高,Inception v2中插入1*1卷积核进行降维

Inception V3 进一步对 V2的参数数量进行降低,并增加非线性激活函数,使网络产生更多独立特,表征能力更强,训练更快。

ResNet
残差学习网络(deep residual learning network)
残差的思想: 去掉相同的主体部分,从而突出微小的变化,可以被用来训练非常深的网络。
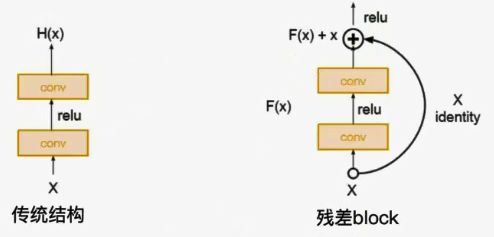
![]() ,即使函数求导为零或函数本身就为零,但加上一之后就不会存在梯度消失的情况。
,即使函数求导为零或函数本身就为零,但加上一之后就不会存在梯度消失的情况。
Pytorch代码练习
加载数据
torch.Tensor — PyTorch 1.12 documentation
torchvision — Torchvision 0.13 documentation (pytorch.org)
PyTorch创建了一个叫做 totchvision 的包,该包含有支持加载类似Imagenet,CIFAR10,MNIST 等公共数据集的数据加载模块 torchvision.datasets 和支持加载图像数据数据转换模块 torch.utils.data.DataLoader。
Tensor
Tensor是n维的数组,在概念上与numpy数组是一样的,不同的是Tensor可以跟踪计算图和计算梯度。
A Tensor Image is a tensor with (C, H, W) shape, where C is a number of channels, H and W are image height and width. A batch of Tensor Images is a tensor of (B, C, H, W) shape, where B is a number of images in the batch.
transform
transforms是Pytorch的图像预处理包,包含了很多种对图像数据进行变换的函数,是加载数据时必不可少的。


DataLoader

MNIST

CIFAR10

创建网络
torch.nn — PyTorch 1.12 documentation
torch.nn.functional — PyTorch 1.12 documentation
定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数init中。只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。
创建网络方法一:

创建网络方法二:
训练和测试
torch.nn.functional — PyTorch 1.12 documentation
torch.nn.Module有train和eval两种模式,在train模式下启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为True;在eval模式下不启用 BatchNormalization 和 Dropout,将BatchNormalization和Dropout置为False。
# 训练函数
def train(model):
model.train()
# 主里从train_loader里,64个样本一个batch为单位提取样本进行训练
for batch_idx, (data, target) in enumerate(train_loader):
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
# 负对数似然损失
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
# 把数据送入模型,得到预测结果
output = model(data)
# 计算本次batch的损失,并加到 test_loss 中
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability,最后一层输出10个数,
# 值最大的那个即对应着分类结果,然后把分类结果保存在 pred 里
pred = output.data.max(1, keepdim=True)[1]
# 将 pred 与 target 相比,得到正确预测结果的数量,并加到 correct 中
# 这里需要注意一下 view_as ,意思是把 target 变成维度和 pred 一样的意思
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))代码练习结果
练习一
在小型全连接网络上训练

在卷积神经网络上训练

打乱像素顺序在全连接网络上训练与测试

打乱像素顺序在卷积神经网络上训练与测试
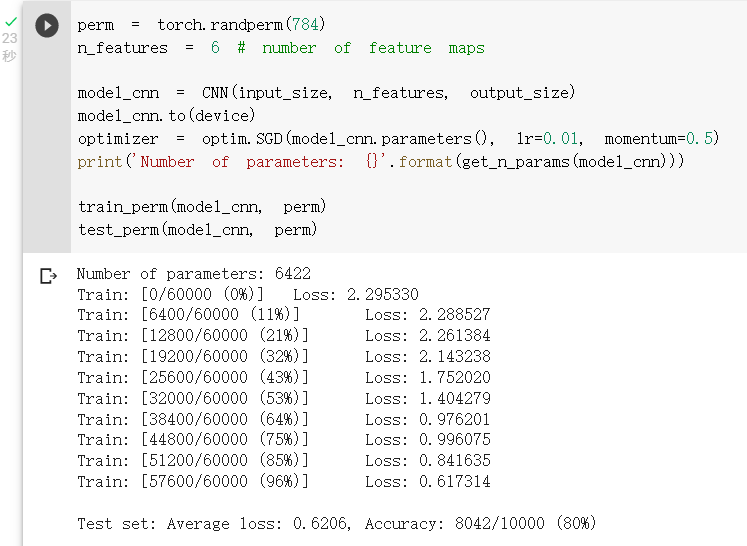
从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是卷积神经网络的性能明显下降。这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
练习二


练习三

简化版的 VGG 网络就能够显著地将CNN的准确率从62%提升至82.92%。
问题
1、dataloader 里面 shuffle 取不同值有什么区别?
shuffle取True时每轮训练取得图片是随机的;取False时不会打乱图片顺序。
2、transform 里,取了不同值,这个有什么区别?
Transforming and augmenting images — Torchvision 0.13 documentation (pytorch.org)
3、epoch 和 batch 的区别?
batch指一次喂进网络的图片数量
epoch指网络进行正向传播+反向传播+优化的次数
4、1x1的卷积和 FC 有什么区别?主要起什么作用?
1x1卷积核能改变通道数,将原本的数据量进行增加或者减少;同时在保持feature map尺度不变的前提下通过增加激活层来增加网络非线性特性。
FC层通常接在网络的最后,可以整合卷积层或者池化层中具有类别区分性的局部信息并用于分类。
5、residual leanring 为什么能够提升准确率?
残差块缓解了梯度消失问题,使得网络深度可以大幅度提升。
6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
| 层 \ 参数 | 输入 | 卷积核 | 输出 | 激活函数 |
|---|---|---|---|---|
| C1 | 3*32*32 | 6*5*5 | 6*28*28 | ReLU |
| MaxPool | 6*28*28 | 2*2 s=2 | 6*14*14 | |
| C2 | 6*14*14 | 16*5*5 | 16*10*10 | ReLU |
| MaxPool | 16*10*10 | 2*2 s=2 | 16*5*5 | |
| FC1 | 16*5*5 | 120 | ReLU | |
| FC2 | 120 | 84 | ReLU | |
| FC3 | 84 | 10 |
| 层 \ 参数 | 输入 | 卷积核 | 输出 | 激活函数 |
|---|---|---|---|---|
| C1 | 1*32*32 | 6*5*5 | 6*28*28 | |
| Pool | 6*28*28 | 2*2 s=2 | 6*14*14 | Sigmoid |
| C2 | 6*14*14 | 16*5*5 | 16*10*10 | |
| Pool | 16*10*10 | 2*2 s=2 | 16*5*5 | Sigmoid |
| FC1 | 16*5*5 | 120 | ||
| FC2 | 120 | 84 | ||
| FC3 | 84 | 10 |
1、代码二中输入为3通道,LeNet5输入为1通道
2、代码二采用MaxPool池化,LeNet5使用带有可训练参数的池化
3、代码二中激活函数处在卷积和池化之间,LeNet5激活函数处在池化后
4、代码二采用交叉熵损失函数,LeNet5采用径向基损失函数
7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
1、对输入x进行池化降维,尺寸拆分堆叠在通道上等操作,使得输入x的尺寸变为和F(x)相同
2、对输出F(x)进行填充,缩小通道数拼接在尺寸上等操作,使得F(x)的尺寸变为和输入x相同
8、有什么方法可以进一步提升准确率?
1、增加数据集中样本的数量,多样性。
2、增加训练次数。
3、改善网络结构,加深网络深度。
4、使用更好的反向传播算法,激活函数和损失函数。