论文地址:带轴向注意的多尺度时域频率卷积网络语音增强
论文代码:https://github.com/echocatzh/MTFAA-Net
引用:Zhang G, Yu L, Wang C, et al. Multi-scale temporal frequency convolutional network with axial attention for speech enhancement[C]//ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022: 9122-9126.
摘要
语音质量经常因回声、背景噪声和混响而降低。在本文中,我们提出了一个由深度学习和信号处理组成的系统,同时抑制回声、噪声和混响。对于深度学习,我们设计了一种新的语音密集预测backbone。在信号处理中,利用线性回声消除器作为条件信息进行深度学习。为了提高语音密集预测(speech dense-prediction)主干的性能,设计了麦克风和参考相位编码器、多尺度时频处理和流式轴向注意(streaming axial attention)等策略。该系统在ICASSP 2022年AEC和DNS挑战赛(非个人赛道)中均排名第一。此外,该backbone还被扩展到多通道语音增强任务,并在ICASSP 2022 L3DAS22挑战赛中获得第二名。
索引术语:语音密集预测,语音增强,多尺度,轴向注意
1 引言
在语音通信应用中,如语音交互或视频会议系统,语音质量往往会受到回声、背景噪声和混响的影响。为了抑制声学回声,可以使用一种称为线性声学回声消除器(Linear Acoustic Echo Canceller,LAEC)的音频处理组件[1]。
然而,由于扬声器的非线性失真和振动效应的存在,LAEC的性能严重下降。因此,通常需要一个基于信号处理(signal processing,SP)[2]或深度神经网络(DNN)的残余回声抑制器(RES)来进一步抑制声回声。基于DNN的RES方法比基于SP的[3]方法具有更好的性能。此外,DNN在去除背景噪声和抑制混响[4]方面也取得了显著的效果。
在这项工作中,我们提出了一个同时去噪,去混响和回声消除系统。该系统是SP和DNN的组合。SP部分由基于广义相关[5]的简单时延补偿器( time delay compensator,TDC)和基于双回声路径模型[6]和带PNLMS自适应滤波器[7]的LAEC组成。在DNN部分,我们提出了一种新的语音密度预测backbone,称为轴向自注意多尺度时间频率卷积网络(Multi-scale Temporal Frequency Convolutional Network with Axial self-Attention,MTFAA-Net)。在这项工作中,我们的贡献包括:
- 为了消除回声,我们设计了一种新的组合SP和DNN。与以往的LAEC与DNN拼接不同,我们只使用LAEC作为DNN的条件信息,避免了LAEC引起的失真引入到估计的目标语音中。
- 提出了一种用于各种语音密度预测任务的主干。设计了相位编码器(Phase encoder,PE)、多尺度时频处理和流式轴向自关注力(ASA)来提高backbone的性能。相位编码后采用等效矩形带宽(ERB)的频频带合并模块对全频带信号进行处理,计算复数度较低。
在ICASSP 2022 AEC Challenge[8]和ICASSP 2022 DNS Challenge[9]的评估集和盲测试集上的结果表明,该方案在回声消除、去噪和去混响方面具有良好的性能。
本文的其余部分组织如下。第2节介绍问题的表述。第3节提供了用于语音增强的拟议主干的细节。第4节展示了数据集和实验结果。最后,我们在第5节得出结论。
2 问题公式化
让我们考虑短时傅里叶变换(STFT)域中的信号模型。麦克风信号$Y(t,f)$由回声$E(t, f)$、背景噪声$N(t, f)$和带混响的近端语音$s(t,f)H^e(f)+s(t,f)H^l(l)$组成。我们称这个模型为:
$$公式1:Y(t, f)=s(t, f) H^{e}(f)+s(t, f) H^{l}(f)+E(t, f)+N(t, f)$$
其中$s(t,f)H^e(f)$,$s(t,f)H^l(f)$分别是与房间脉冲响应(RIR)早期$H^e(f)$和晚期反射$H^l(f)$卷积的近端语音。$t$,$f$分别是时间索引和频率索引。$s(t, f)H^e(f)$将作为要估计的目标。
LAEC的输出$Y_{laec}(t,f)$可以看作是纯净语音、残余回声、混响和背景噪声的混合。与之前[3]方案只将$Y_{laec}(t,f)$和远端参考信号输入网络不同,本文提出的网络也将$Y(t, f)$作为输入,可以避免LAEC引入的失真带来的性能下降。它还有助于网络识别哪些T-F区域由于回声的存在而被LAEC抑制。
3 一种用于语音密集预测的backbone算法
在本节中,我们将展示提议的体系结构的细节。图1显示了包含线性回声消除(LAEC)和时延补偿器(TDC)的MTFAA-Net的总体结构。MTFAA-Net由相位编码器(PE)、频带合并(band merging, BM)和频带分割(band splitting, BS)模块、掩码估计和应用(Mask Estimating and Applying, MEA)模块和主网模块(Main-Net module)组成。主网包括几个相似的部分,每个部分由频率下采样(frequency downsampling,FD)或频率上采样(frequency upsampling,FU)、T-F卷积和流式轴向自关注力(axial self attention, ASA)组成。稍加调整,MTFAA-Net就可以应用于各种语音密度预测任务。
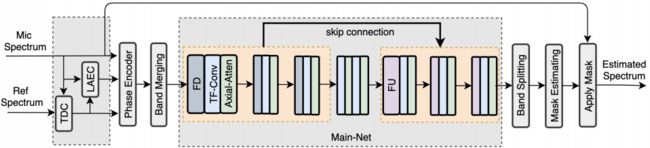
图1:提出的MTFAA-Net体系结构
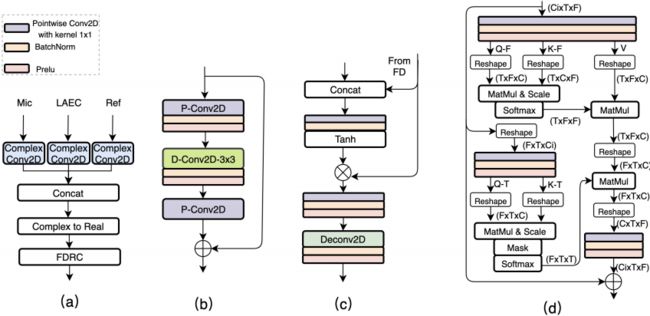
图2所示:(a) 相位编码器(PE);(b) TF卷积模块(TFCM );(c) 频率上采样(FU );(d) 轴向自注意力(ASA)
3.1 相位编码器
real的语音增强网络更容易实现,并在许多数据集[4]上实现最先进的结果。backbone的主要部分也是一个real的网络。为了将复数频谱特征映射到real,我们设计了一个PE模块,如图2 (a)所示。在PE模块中,有三个复数卷积层,分别接收麦克风信号、LAEC输出和远端参考信号。复数卷积层的kernel size和stride分别为(3,1)和(1,1)。此外,PE还包含complex 到real层(complex modulo)和特征动态范围压缩(feature dynamic range compression, FDRC)层。FDRC的目的是减小语音特征的动态范围,使模型具有更强的鲁棒性。
3.2 频段合并与分割
语音有有价值信息在频率维度上的分布是不均匀的,特别是在全频带信号中。在高频段中存在着大量的冗余特征。高频特性合并可以减少冗余。BS是BM的逆过程。本文将频带合并(BM)和频带分割(BS)按照ERB刻度[10]进行分割。
3.3 TF卷积模块
我们在时间卷积网络(TCN)[11]中使用2D深度可分离卷积(depthwise convolutions,D-Conv)来代替1D D-Conv。D-Conv还被设计为时间维度上的扩张卷积,可以看作是沿时间域的多尺度建模。TF卷积模块(TFCM)使用的卷积块如图2.(b)所示,它由两个点卷积(pointwise convolutional,P-Conv)层和一个核大小为(3,3)的D-Conv层组成。使用B个卷积块将串接在一起形成TFCM,感受野从1扩张到$2^{B-1}$。多尺度建模改进了TFCM的感受野,同时使用小卷积核。
3.4 轴向(Axial) Self-Attention
自注意可以提高网络捕捉远距离特征之间关系的能力。与计算机视觉[12]中的pixel or patch level注意力不同,本文提出了一种语音识别的ASA机制。ASA可以减少对内存和计算的需求,更适合于语音等长序列信号。图2(d)是ASA的结构,$C_i$和$C$分别代表输入通道数和注意力通道数。ASA的注意力得分矩阵沿频率轴和时间轴计算,分别称为F-attention和T-attention。分数矩阵可以表示为::
$$公式2:\mathbf{M}_{F}(t)=\operatorname{Softmax}\left(\mathbf{Q}_{f}(t) \mathbf{K}_{f}^{T}(t)\right)$$
$$公式3:\mathbf{M}_{T}(f)=\operatorname{Softmax}\left(\operatorname{Mask}\left(\mathbf{Q}_{t}(f) \mathbf{K}_{t}^{T}(f)\right)\right)$$
其中$Q_f(t)$、$K_f(t)\in R^{T*C}$、$M_F(t)\in R^{F*F}$表示key、query以及F-attention在帧$t$的得分矩阵。$Q_t(f)$、$K_t(f)\in R^{F*C}$、$M_T(F)\in R^{T*T}$表示key、query以及T-attention在频带$f$的得分矩阵。$T$,$F$表示帧数和频带数。Softmax将沿着最后一个维度计算。T-attention中的Mask(*)用来调整ASA捕获多长时间的时序依赖性。对于MTFAA-Net-Streaming,使用了掩蔽输入矩阵的上三角部分,这导致了因果 ASA。
3.5 频率上下采样
设计了FD和FU采样来提取多尺度特征。在每个尺度上,采用TFCM和ASA进行特征建模,提高了网络对特征的描述能力。
- FD是一个卷积块,它包含一个Conv 2D层、一个batchnorm (BN)层和一个PReLU激活层。
- FU如图2.(c)所示,其中Deconv 2D为转置卷积。
Conv2D和Deconv2D的内核大小为(1,7),stride为(1,4),分组为2。FU[4]中使用了门控机制。
3.6 Mask估计与应用
掩模估计与应用(mask estimating and applying,MEA)模块由两个阶段组成。第一阶段估计的real mask size为$(2V + 1, 2U + 1)$,并以Deepfilter[13]的形式将其应用于幅度谱。第二阶段估计complex mask,并将其应用于幅度谱和相位谱。形式上,增强频谱的实部$R^{s2}(t,f)$和虚部$I^{s2}(t,f)$部分可以表示为:
$$公式4:A^{s 1}(t, f)=\sum_{u=-U}^{U} \sum_{v=-V}^{V}|Y(t+u, f+v)| \cdot M^{s 1}(t, f, u, v)$$
$$公式5:R^{s 2}(t, f)=A^{s 1}(t, f) * M_{A}^{s 2}(t, f) * \cos \left(\theta_{Y}(t, f)+M_{\theta}^{s 2}(t, f)\right)$$
$$公式6:I^{s 2}(t, f)=A^{s 1}(t, f) * M_{A}^{s 2}(t, f) * \sin \left(\theta_{Y}(t, f)+M_{\theta}^{s 2}(t, f)\right)$$
式中,$M^{s1}(t,f,u,v)$、$A^{s1}(t,f)$分别为第1阶段估计的mask和增强的幅度谱。$\theta _Y(t,f)$表示带噪语音的相位谱。$M_A^{s2}(t,f)$、$M_\theta ^{s2}(t,f)$分别表示阶段2中幅度和相位部分的Mask。
4 实验
4.1 数据集
训练集和评估集都使用纯净语音、背景噪声、回声和RIR set进行合成。我们使用 DNS4 的语音和噪声片段进行训练。采用VCTK语料库和DEMAND[14]分别作为评价语音集和噪声集。ICASSP 2022年AEC挑战赛训练和开发远端单个谈话片段被用作训练和评估回声集[8]。对于RIR,我们采用镜像源方法分别获取10万对和1000对混响时间在0.1s到0.8s[15]的RIR进行训练和评估。所有设备都以48kHz采样。训练时,信噪比(SNR)和回声信号比(SER)分别为[-5,15]dB和[-10,10]dB,评估时,分别为[0,10]dB和[-5,5]dB。
4.2 实现细节
我们使用32ms 帧长,8ms 帧移的 STFT 复数谱作为输入。 1/2 功率压缩用于 FDRC [16]。 PE中复数卷积层的输出通道数为4。三个FD的输出通道数分别为48、96和192。一个TFCM中的卷积块数为6。ASA中的注意通道数为1/4 的输入通道号。 ERB 波段的数量设置为 256。MEA 中的实际掩码大小配置为 (3, 1)。 对于 MTFAA-Net -Streaming,卷积层和 ASA 也被配置为因果关系,总系统延迟为 40 ms。 目标语音 RIR 的加权函数被配置为与 [17] 中的相同。
具有 STFT 一致性 [18] 的幂律压缩频谱(power-law compressed spectrum)的均方误差用作损失函数。我们使用Adam优化器,学习率为5e-4。 我们将 MTFAA-Net 训练了 300k 步,batch size为 16。
4.3 结果
4.3.1 消融实验
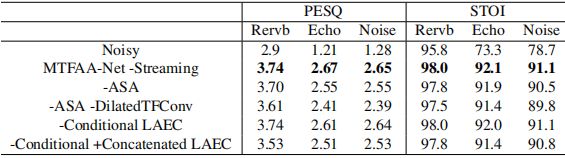
我们首先评估了MTFAA-Net 不同模块的有效性。消融结果见表1。去掉ASA后,模型在三个任务上的性能都下降了,echo任务上的PESQ下降了0.12。当同时去除ASA并将TFCM的 dilation 设置为1时,回声任务的PESQ降低了0.26。通过从LAEC中引入附加的条件信息,可以进一步提高模型对回声任务的性能。但是,如果将LAEC与模型简单地连接在一起,由于LAEC引入的失真会降低系统的性能。
表1 消蚀研究的去everberation (Rervb),回波消除(Echo)和去噪(Noise)任务
4.3.2 与最先进技术的比较
表2 AEC full band 盲测试集与其他方法的比较

表3 DNS full band 盲集方法与其他方法的比较

表2和表3分别显示了主观和单词准确性(WAcc)的结果,由AEC和DNS挑战组织者提供。结果表明,该方法在主观评价上明显优于其他方法。在AEC挑战赛中,与团队4相比,可以观察到主观mos的0.072增益。对于DNS Challenge,我们的系统在BAK-MOS上获得了0.47的相当大的增益,与Team14相比。该系统在两项挑战中排名第一,证明了所提出的主干的健壮性能。
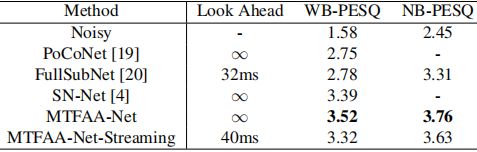
我们还去掉了SP部分,并对DNS宽带非盲测试集进行了对比评估。训练和评价集与SN-Net[4]相同。结果如表4所示。MTFAA-Net的表现大大超过了其他所有网络。
表4 DNS宽带非盲测试集与其他方法的比较。未来的展望表明该模型是非流的
我们还计算了推理时间。在4.2节的配置下,MTFAA-Net的乘法累积操作数量约为每秒2.4G。采用Python实现的系统实时性因子约为0.6(在Intel Core i5内核的MacBook Pro上),满足了实时性处理的要求。
5 结论
提出了一种新的语音密集预测中枢MTFAA-Net。在引入LAEC的条件信息后,MTFAA-Net在AEC和ICASSP 2022的DNS挑战中都达到了最先进的性能。我们希望MTFAA-Net的强大性能将鼓励统一建模更多语音密度预测任务。未来,我们将改进所提出的backbone的能力,并将backbone扩展到其他各种任务,如个人语音增强、源分离等。
6 参考文献
[1] Jacob Benesty, Tomas G ansler, Dennis R Morgan, M Mohan Sondhi, Steven L Gay, et al., Advances in network and acoustic echo cancellation, 2001.
[2] Amit S Chhetri, Arun C Surendran, Jack W Stokes, and John C Platt, Regression-based residual acoustic echo suppression, in Proc. IWAENC, 2005, vol. 5.
[3] Jean-Marc Valin, Srikanth Tenneti, Karim Helwani, Umut Isik, and Arvindh Krishnaswamy, Lowcomplexity, real-time joint neural echo control and speech enhancement based on percepnet, in ICASSP. IEEE, 2021, pp. 7133 7137.
[4] Chengyu Zheng, Xiulian Peng, Yuan Zhang, Sriram Srinivasan, and Yan Lu, Interactive speech and noise modeling for speech enhancement, AAAI, 2020. [5] Charles Knapp and Glifford Carter, The generalized correlation method for estimation of time delay, IEEE transactions on acoustics, speech, and signal processing, vol. 24, no. 4, pp. 320 327, 1976.
[6] Kazuo Ochiai, Takashi Araseki, and Takasi Ogihara, Echo canceler with two echo path models, IEEE Transactions on Communications, vol. 25, no. 6, pp. 589 595, 1977.
[7] Donald L Duttweiler, Proportionate normalized leastmean-squares adaptation in echo cancelers, IEEE Transactions on speech and audio processing, vol. 8, no. 5, pp. 508 518, 2000.
[8] Ross Cutler, Ando Saabas, Tanel Parnamaa, Marju Purin, Hannes Gamper, Sebastian Braun, Karsten Sorensen, and Robert Aichner, Icassp 2022 acoustic echo cancellation challenge, in ICASSP, 2022.
[9] Harishchandra Dubey, Vishak Gopal, Ross Cutler, Sergiy Matusevych, Sebastian Braun, Emre Sefik Eskimez, Manthan Thakker, Takuya Yoshioka, Hannes Gamper, and Robert Aichner, Icassp 2022 deep noise suppression challenge, in ICASSP, 2022.
[10] Jean-Marc Valin, Umut Isik, Neerad Phansalkar, Ritwik Giri, Karim Helwani, and Arvindh Krishnaswamy, A perceptually-motivated approach for low-complexity, real-time enhancement of fullband speech, 2020.
[11] Yi Luo and Nima Mesgarani, Conv-tasnet: Surpassing ideal time frequency magnitude masking for speech separation, IEEE/ACM transactions on audio, speech, and language processing, vol. 27, no. 8, pp. 1256 1266, 2019.
[12] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo, Swin transformer: Hierarchical vision transformer using shifted windows, International Conference on Computer Vision (ICCV), 2021.
[13] Wolfgang Mack and Emanu el AP Habets, Deep filtering: Signal extraction and reconstruction using complex time-frequency filters, IEEE Signal Processing Letters, vol. 27, pp. 61 65, 2019.
[14] J Thiemann, N Ito, and E Vincent, Demand: a collection of multi-channel recordings of acoustic noise in diverse environments (2013), URL http://parole. loria. fr/DEMAND.
[15] David Diaz-Guerra, Antonio Miguel, and Jose R. Beltran, gpuRIR: A Python Library for Room Impulse Response Simulation with GPU Acceleration, Multimed Tools Applx, 2020.
[16] Andong Li, Chengshi Zheng, Renhua Peng, and Xiaodong Li, On the importance of power compression and phase estimation in monaural speech dereverberation, JASA Express Letters, vol. 1, no. 1, pp. 014802, 2021.
[17] Sebastian Braun, Hannes Gamper, Chandan KA Reddy, and Ivan Tashev, Towards efficient models for realtime deep noise suppression, in ICASSP. IEEE, 2021, pp. 656 660.
[18] Sebastian Braun and Ivan Tashev, Data augmentation and loss normalization for deep noise suppression, in International Conference on Speech and Computer. Springer, 2020, pp. 79 86.
[19] Umut Isik, Ritwik Giri, Neerad Phansalkar, Jean-Marc Valin, Karim Helwani, and Arvindh Krishnaswamy, Poconet: Better speech enhancement with frequencypositional embeddings, semi-supervised conversational data, and biased loss, in INTERSPEECH, 2020.
[20] Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li, Fullsubnet: A full-band and sub-band fusion model for real-time single-channel speech enhancement, in ICASSP. IEEE, 2021, pp. 6633 6637.