Pytorch构建神经网络三(29-33节)——笔记
Pytorch构建神经网络三(29-33节)——笔记
- 官方博客链接
- 4.1&4.2 使用tensorboard可视化CNN训练指标
-
- 报错
- Starting out with TensorBoard (Network Graph and Images)
-
- 如何进入可视化的界面
- 如何在可视化的界面中写入数据
- 一次完整训练的全部代码和相应的可视化操作
- 对多层的偏置,权重及其梯度进行访问的原理
- 更简单的方法对要更改的参数进行访问
- 4.3 RunBuilder类的编写
- 4.4 如何试验大量的超参数
- 4.5 使用DataLoader的多进程功能加速神经网络训练
-
- 报错:RuntimeError: DataLoader worker (pid(s) 22524) exited unexpectedly
官方博客链接
deeplizard.com
4.1&4.2 使用tensorboard可视化CNN训练指标
pytorch1.1.0以上的版本已经自动增加了tensorboard
在终端输入“tensorboard --version”可查看tensorboard的版本
在终端输入“tensorboard --logdir=runs”进入tensorboard(在写了tensorboard数据的路径下,否则找不到数据)
(本节课的笔记很少,如果需要用到tensorboard,可以专门再看第30节课,看30节课相关的博客,再查找相关函数的使用方法进行)
详解PyTorch项目使用TensorboardX进行训练可视化
这个链接详细介绍了三种初始化 SummaryWriter 的方法和如何添加数据的方法:
from tensorboardX import SummaryWriter
# Creates writer1 object.
# The log will be saved in 'runs/exp'
writer1 = SummaryWriter('runs/exp')
# Creates writer2 object with auto generated file name
# The log directory will be something like 'runs/Aug20-17-20-33'
writer2 = SummaryWriter()
# Creates writer3 object with auto generated file name, the comment will be appended to the filename.
# The log directory will be something like 'runs/Aug20-17-20-33-resnet'
writer3 = SummaryWriter(comment='resnet')
- 提供一个路径,将使用该路径来保存日志
- 无参数,默认将使用 runs/日期时间 路径来保存日志
- 提供一个 comment 参数,将使用 runs/日期时间-comment 路径来保存日志
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
torch.set_printoptions(linewidth=120)
torch.set_grad_enabled(True)
# out:
print(torch.__version__)
print(torchvision.__version__)
# out:
# 1.9.0
# 0.10.0
def get_num_correct(preds,labels):
return preds.argmax(dim=1).eq(labels).sum().item()
class Network(nn.Module):
def __init__(self):
super(Network,self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12*4*4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
t = t
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
t = t.reshape(-1, 12*4*4) # t.flatten(start_dim=1)
t = F.relu(self.fc1(t))
t = F.relu(self.fc2(t))
t = self.out(t)
return t
train_set = torchvision.datasets.FashionMNIST(
root = './data/FashionMNIST',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor()
])
)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
报错
导入的代码没有提示错误,但是执行之后说没有这个模块
from torch.utils.tensorboard import SummaryWriter
out:
No module named 'tensorboard'
from torch.utils.tensorboard import SummaryWriter导入不成功问题
这个链接解决了这个问题
#由于pytorch本身不自带tensorboard包,一般这样报错都是由于未安装tensorboard包导致的。
#可以通过pip 加载清华镜像源进行安装
sudo pip install -i https://mirrors.aliyun.com/pypi/simple/ tensorboard
Starting out with TensorBoard (Network Graph and Images)
详解PyTorch项目使用TensorboardX进行训练可视化
这是一个类似的链接
如何进入可视化的界面
在cmd中进行操作:
tensorboard --version
out:
TensorFlow installation not found - running with reduced feature set.
2.7.0

(pytorch_1.9) C:\Users\liu>tensorboard --logdir=runs
out:
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.7.0 at http://localhost:6006/ (Press CTRL+C to quit)
然后再浏览器中输入http://localhost:6006/ ,下面是打开的界面,下面的界面是没有数据的界面

这是因为tensorboard 没看找到记录,因为我们在 C:\Users\liu路径下运行了上面的代码,但是这个路径下并没有runs文件夹。但是在代码执行(test-1.py是我们执行的代码)所在的文件夹下有一个runs文件夹,runs文件夹下就是代码运行之后的记录

所以我们首先需要将cmd进入到项目所在的文件夹路径,然后输入命令行:
tensorboard --logdir=runs
此时会得到我们需要的数据图


如何在可视化的界面中写入数据
tb = SummaryWriter()
network = Network()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100)
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images)
# 向tb中写入图片
tb.add_image('images', grid)
# 向tb中写入网络
tb.add_graph(network, images)
tb.close()
一次完整训练的全部代码和相应的可视化操作
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import itertools
from sklearn.metrics import confusion_matrix # 生成混淆矩阵函数
import matplotlib.pyplot as plt
# from resources.plotcm import plot_confusion_matrix
import numpy as np
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
torch.set_printoptions(linewidth=120) # 这里告诉pytorch如何显示输出
torch.set_grad_enabled(True) # 这里并不是必须的,默认情况下是打开的,pytorch的梯度跟踪功能
print(torch.__version__)
print(torchvision.__version__)
train_set = torchvision.datasets.FashionMNIST(
root = './data/FashionMNIST',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor()
])
)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
# Input Layer
t = t
# Conv1
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
# Conv2
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
# FC1
t = t.reshape(-1, 12 * 4 * 4)
t = F.relu(self.fc1(t))
# FC2
t = F.relu(self.fc2(t))
# Output
t = self.out(t)
return t
# 定义函数用于计算预测正确的数目
def get_num_correct(preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
# 创建网络实例
network = Network()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100)
optimizer = optim.Adam(network.parameters(), lr=0.01)
flag_sum = 0 # 记录总共训练的次数
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images)
tb = SummaryWriter()
tb.add_image('images', grid)
tb.add_graph(network, images)
# 多次epoch
for epoch in range(10):
total_loss = 0
total_correct = 0
flag_epoch = 0 # 记录一次epoch的训练次数
# 一次epoch
for batch in train_loader: # Get batch,从所有的数据中得到一个bach,一个bach是100张图片
images, labels = batch
preds = network(images)
loss = F.cross_entropy(preds, labels)
# 这里梯度归零是因为当我们对损失函数进行逆向调用时(loss.backward()),新的梯度将会被计算出来,它们会添加到这些当前值中,如果不将当前值归零,就会累积梯度,
optimizer.zero_grad() # 告诉优化器把梯度属性中权重的梯度归零,否则pytorch会累积梯度
loss.backward() # 计算梯度
# 使用梯度和学习率,梯度告诉我们走那条路,(哪个方向时损失函数的最小值),学习率告诉我们在这个方向上走多远
optimizer.step() # 更新权重,更新所有参数
flag_sum += 1
flag_epoch += 1
total_loss += loss.item()
total_correct += get_num_correct(preds, labels)
# 向tb中添加loss,number correct,accduracy的数据
tb.add_scalar("Loss", total_loss, epoch)
tb.add_scalar("Number Correct", total_correct, epoch)
tb.add_scalar("Accuracy", total_correct / len(train_set), epoch)
#向tb中添加偏置,权重,及其梯度的数据
# 这种表达方式只能看单个层的偏置,权重,及其梯度的变化趋势,无法看到全部的。用来创建直方图的值
tb.add_histogram('conv1.bias', network.conv1.bias, epoch)
tb.add_histogram('conv1.weight', network.conv1.weight, epoch)
tb.add_histogram('conv1.weight.grad', network.conv1.weight.grad, epoch)
# for name, weight in network.named_parameters():
# tb.add_histogram(name, weight, epoch)
# tb.add_histogram(f'{name}.grad', weight.grad, epoch)
# # 下面的代码打印我们储存到tb中的数据名称和形似
# print(name, weight.shape)
# print(f'{name}.grad', weight.grad.shape)
print("epoch:", epoch, "loss:", total_loss, "total_correct:", total_correct)
tb.close()
print("flag_sum: ",flag_sum,"flag_epoch",flag_epoch)
accuracy = total_correct/len(train_set)
print("accuracy:",accuracy)
# 在3.13训练后网络的基础上进行分析
len(train_set)
len(train_set.targets)
# 获得所有的预测结果
def get_all_preds(model,loader):
all_preds = torch.tensor([])
for batch in loader:
images,labels = batch
preds = model(images)
all_preds = torch.cat((all_preds,preds), dim=0)
return all_preds
# 定义绘制混淆矩阵函数
def plot_confusion_matrix(cm, labels_name, title):
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] # 归一化
plt.imshow(cm, interpolation='nearest') # 在特定的窗口上显示图像
plt.title(title) # 图像标题
plt.colorbar()
num_local = np.array(range(len(labels_name)))
plt.xticks(num_local, labels_name, rotation=90) # 将标签印在x轴坐标上
plt.yticks(num_local, labels_name) # 将标签印在y轴坐标上
plt.ylabel('True label')
plt.xlabel('Predicted label')
# 定义绘制混淆矩阵函数
def plot_confusion_matrix_1(cm, labels_name, title):
#cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] # 归一化
plt.imshow(cm, interpolation='nearest') # 在特定的窗口上显示图像
plt.title(title) # 图像标题
plt.colorbar()
num_local = np.array(range(len(labels_name)))
plt.xticks(num_local, labels_name, rotation=90) # 将标签印在x轴坐标上
plt.yticks(num_local, labels_name) # 将标签印在y轴坐标上
plt.ylabel('True label')
plt.xlabel('Predicted label')
def plot_confusion_matrix_2(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
prediction_loader = torch.utils.data.DataLoader(train_set, batch_size=10000)
train_preds = get_all_preds(network, prediction_loader)
print(train_preds.shape)
print(train_preds.requires_grad) #查看训练预测张量的梯度属性
print(train_preds.grad)
# 即使训练中关于梯度张量的跟踪已打开,但在没有进行反向传播的情况下依旧不会有梯度的值
print(train_preds.grad_fn) # 由于train_preds是经过函数产生的,故具有该属性
# 局部关闭梯度跟踪以减小内存损耗,也可使用torch.set.grad.enabled(False)进行全局关闭
with torch.no_grad():
prediction_loader = torch.utils.data.DataLoader(train_set, batch_size=1000)
train_preds = get_all_preds(network, prediction_loader)
len(train_preds)
print(train_preds.requires_grad)
print(train_preds.grad)
print(train_preds.grad_fn)
preds_correct = get_num_correct(train_preds, train_set.targets)
print("total_correct:",preds_correct)
print("accuracy:",preds_correct/len(train_set))
print(train_set.targets)
print(train_set.targets.shape)
print(train_preds.argmax(dim=1))
print(train_preds.argmax(dim=1).shape)
stack = torch.stack((train_set.targets, train_preds.argmax(dim=1)),dim=1)
print(stack)
# 使用tolist方法可访问【target,pred】对
print(stack[0].tolist())
# 创建一个混淆矩阵(初始)
cmt = torch.zeros(10,10,dtype=torch.int32)
# 遍历所有的对,并计算每个组合发生的次数
for p in stack:
tl,pl = p.tolist()
cmt[tl,pl] = cmt[tl,pl] + 1
print(cmt)
cm = confusion_matrix(train_set.targets, train_preds.argmax(dim=1))
names = (
'T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot')
plt.figure(figsize=(10, 10))
plot_confusion_matrix(cm, names, "pred")
plt.show()
plt.figure(figsize=(10, 10))
plot_confusion_matrix_1(cmt, names, "haha")
plt.show()
plt.figure(figsize=(10, 10))
plot_confusion_matrix_2(cmt, names)
plt.show()
对多层的偏置,权重及其梯度进行访问的原理
for name,weight in network.named_parameters():
print(name, weight.shape)
out:
conv1.weight torch.Size([6, 1, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([12, 6, 5, 5])
conv2.bias torch.Size([12])
fc1.weight torch.Size([120, 192])
fc1.bias torch.Size([120])
fc2.weight torch.Size([60, 120])
fc2.bias torch.Size([60])
out.weight torch.Size([10, 60])
out.bias torch.Size([10])
for name,weight in network.named_parameters():
print(f'{name}.grad', weight.grad.shape)
out:
conv1.weight.grad torch.Size([6, 1, 5, 5])
conv1.bias.grad torch.Size([6])
conv2.weight.grad torch.Size([12, 6, 5, 5])
conv2.bias.grad torch.Size([12])
fc1.weight.grad torch.Size([120, 192])
fc1.bias.grad torch.Size([120])
fc2.weight.grad torch.Size([60, 120])
fc2.bias.grad torch.Size([60])
out.weight.grad torch.Size([10, 60])
out.bias.grad torch.Size([10])
更简单的方法对要更改的参数进行访问
# 下面的函数允许我们计算所有参数类型的笛卡尔积
from itertools import product
# 定义了一个字典,对于每个参数我们提供了我们想要尝试的值的列表
parameters = dict(
lr = [.01, .001],
batc_size = [10, 100, 1000],
shuffle = [True, False]
)
# 接下来,我们将通过在参数字典中返回每个V的值列表V来获得参数值的列表
param_values = [v for v in parameters.values()]
print(param_values)
# 我们通过参数值列表传递给product函数,进行笛卡尔乘积
# 星号告诉乘积函数把列表中的每个值作为参数,而不是把列表本身当作参数来对待
# 所以我们有三个参数传递给product函数而不是一个,对于每个参数的组合,我们有一组参数值,我们可以将其解包并传递到训练过程中
for lr, batch_size, shuffle in product(*param_values):
print(lr, batch_size, shuffle)
out:
# 一共有12中可能,2*3*2=12
[[0.01, 0.001], [10, 100, 1000], [True, False]]
0.01 10 True
0.01 10 False
0.01 100 True
0.01 100 False
0.01 1000 True
0.01 1000 False
0.001 10 True
0.001 10 False
0.001 100 True
0.001 100 False
0.001 1000 True
0.001 1000 False
将上面提到的笛卡尔乘积的更简单改变参数的方法应用到我们的训练中
下面的代码一共进行了12次独立的完整训练(完整训练是指每次训练都得到最终的结果,独立是指12次训练时相互无关的,参数之间没有影响,每次都是重新开始)
#batch_size = 100
#lr =0.01
# 对不同的batchsize,lr的训练情况进行比较
# 方法2:只需一层循环
from itertools import product
parameters = dict(
lr = [.01, .001],
batch_size = [10, 100],
shuffle = [True, False]
)
param_values = [v for v in parameters.values()]
print(param_values)
for lr, batch_size, shuffle in product(*param_values):
network = Network()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True)
images, labels = next(iter(train_loader))
grid = torchvision.utils.make_grid(images) # 创建能在tensorboard中查看的图像网格
comment = f'batch_size={batch_size} lr ={lr} shuffle={shuffle}'
tb = SummaryWriter(comment=comment) # 在Summary Writer添加该注释,可帮助我们在tensorboard中唯一地识别该表示
tb.add_image('images', grid) # 将一批图像放在grid中进行显示
tb.add_graph(network, images) # 在tensorboard中看见网络结构的可视化图
optimizer = optim.Adam(network.parameters(), lr=lr)
for epoch in range(5):
total_loss = 0
total_correct = 0
for batch in train_loader: # Get Batch
images, labels = batch
preds = network(images) # Pass Batch
loss = F.cross_entropy(preds, labels) # Calculate loss
optimizer.zero_grad() # 梯度清零,否则会累加
loss.backward() # Calculate Gradients
optimizer.step() # Update Weights
#total_loss += loss.item()
total_loss += loss.item()*batch_size # 在对不同批次下的训练进行比较时,这样做可使结果更具有可比性
total_correct += get_num_correct(preds, labels)
tb.add_scalar("Loss", total_loss, epoch)
tb.add_scalar("Number Correct", total_correct, epoch)
tb.add_scalar("Accuracy", total_correct/len(train_set), epoch)
'''
这种表达方式只能看单个层的偏置,权重,及其梯度的变化趋势,无法看到全部的
tb.add_histogram('conv1.bias', network.conv1.bias, epoch)
tb.add_histogram('conv1.weight', network.conv1.weight, epoch)
tb.add_histogram('conv1.weight.grad', network.conv1.weight.grad, epoch)
'''
for name, weight in network.named_parameters():
tb.add_histogram(name, weight, epoch)
tb.add_histogram(f'{name}.grad', weight.grad, epoch)
print("epoch:", epoch, "total_correct:", total_correct, "loss", total_loss)
tb.close()
out:
[[0.01, 0.001], [10, 100], [True, False]]
4.3 RunBuilder类的编写
该类的编写允许我们使用不同的参数值生成多个运行
from collections import OrderedDict
from collections import namedtuple
from itertools import product
class RunBuilder():
# 静态方法
# 这意味着我们可以用这个类来调用它,不需要类的实例来调用该方法
# 例如:runs = RunBuilder.get_runs(params),没有创建实例
@staticmethod
def get_runs(params):
Run = namedtuple('Run', params.keys())
print(params.keys())
print(params.values())
runs = []
for v in product(*params.values()):
runs.append(Run(*v))
return runs
params = OrderedDict(
lr = [.01, .001],
batch_size = [1000, 10000]
)
runs = RunBuilder.get_runs(params)
runs
out:
[Run(lr=0.01, batch_size=1000),
Run(lr=0.01, batch_size=10000),
Run(lr=0.001, batch_size=1000),
Run(lr=0.001, batch_size=10000)]
for run in runs:
print(run, run.lr, run.batch_size)
out:
Run(lr=0.01, batch_size=1000) 0.01 1000
Run(lr=0.01, batch_size=10000) 0.01 10000
Run(lr=0.001, batch_size=1000) 0.001 1000
Run(lr=0.001, batch_size=10000) 0.001 10000
# 创建RunBuilder类以后,comment表示为:
for run in RunBuilder.get_runs(params):
comment = f'-{run}'
print(comment)
out:
odict_keys(['lr', 'batch_size'])
odict_values([[0.01, 0.001], [1000, 10000]])
-Run(lr=0.01, batch_size=1000)
-Run(lr=0.01, batch_size=10000)
-Run(lr=0.001, batch_size=1000)
-Run(lr=0.001, batch_size=10000)
4.4 如何试验大量的超参数
CNN训练循环重构-同时进行超参数测试(pytorch系列-28)
CNN训练循环重构——超参数测试 | PyTorch系列(二十八)
上面的两个链接非常的讲解了本节课的内容
构建RunManager类可实现对大量超参数的试验
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from IPython.display import display, clear_output
import pandas as pd
import time
import json
from itertools import product
from collections import namedtuple
from collections import OrderedDict
import numpy as np
import time
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
class RunManager():
def __init__(self):
self.epoch_count = 0
self.epoch_loss = 0
self.epoch_num_correct = 0
self.epoch_start_time = None
self.run_params = None
self.run_count = 0
self.run_data = []
self.run_start_time = None
self.network = None
self.loader = None
self.tb = None
def begin_run(self, run, network, loader):
self.run_start_time = time.time()
self.run_params = run
self.run_count += 1
self.network = network
self.loader = loader
self.tb = SummaryWriter(comment=f'-{run}')
images,labels = next(iter(self.loader))
grid = torchvision.utils.make_grid(images)
self.tb.add_image('images', grid)
self.tb.add_graph(self.network, images)
def end_run(self):
self.tb.close()
self.epoch_count = 0
def begin_epoch(self):
self.epoch_start_time = time.time()
self.epoch_count += 1
self.epoch_loss = 0
self.epoch_num_correct = 0
def end_epoch(self):
epoch_duration = time.time() - self.epoch_start_time
run_duration = time.time() - self.run_start_time
loss = self.epoch_loss / len(self.loader.dataset)
accuracy = self.epoch_num_correct / len(self.loader.dataset)
self.tb.add_scalar('Loss', loss, self.epoch_count)
self.tb.add_scalar('Accuracy', accuracy, self.epoch_count)
for name, param in self.network.named_parameters():
self.tb.add_histogram(name, param, self.epoch_count)
self.tb.add_histogram(f'{name}.grad', param.grad, self.epoch_count)
results = OrderedDict()
results["run"] = self.run_count
results["epoch"] = self.epoch_count
results["loss"] = loss
results["accuracy"] = accuracy
results["epoch duration"] = epoch_duration
results["run duration"] = run_duration
for k, v in self.run_params._asdict().items(): results[k] = v
self.run_data.append(results)
df = pd.DataFrame.from_dict(self.run_data, orient='columns')
# 接下来的两行是Jupyter notebook特有的。我们清除当前的输出,并显示新的数据框架。
clear_output(wait=True)
display(df)
def track_loss(self, loss):
self.epoch_loss += loss.item() * self.loader.batch_size
def track_num_correct(self, preds, labels):
self.epoch_num_correct += self._get_num_correct(preds, labels)
# 这个函数的定义前面有一个下划线,表示它有点像一个私有的方法,并不打算被外部调用者使用
@torch.no_grad()
def _get_num_correct(self, preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
def save(self, fileName):
pd.DataFrame.from_dict(
self.run_data,
orient='columns').to_csv(f'{fileName}.csv')
with open(f'{fileName},json', 'w', encoding='utf-8') as f:
json.dump(self.run_data, f, ensure_ascii=False, indent=4)
class RunBuilder():
@staticmethod
def get_runs(params):
Run = namedtuple('Run', params.keys())
runs = []
for v in product(*params.values()):
runs.append(Run(*v))
return runs
train_set = torchvision.datasets.FashionMNIST(
root = './data/FashionMNIST',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor()
])
)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
# Input Layer
t = t
# Conv1
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
# Conv2
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
# FC1
t = t.reshape(-1, 12 * 4 * 4)
t = F.relu(self.fc1(t))
# FC2
t = F.relu(self.fc2(t))
# Output
t = self.out(t)
return t
# 使用RunManager和RunBuilder类可以使得程序更易扩展
params = OrderedDict(
lr=[.01],
batch_size=[1000, 2000],
# 这里添加了shuffle
# 在训练之前,一般均会对数据集做shuffle,打乱数据之间的顺序,让数据随机化,这样可以避免过拟合。
shuffle=[True, False]
)
m = RunManager()
for run in RunBuilder.get_runs(params):
network = Network()
# 这里使用了shuffle:shuffle=run.shuffle
# 在训练之前,一般均会对数据集做shuffle,打乱数据之间的顺序,让数据随机化,这样可以避免过拟合。
loader = DataLoader(train_set, batch_size=run.batch_size, shuffle=run.shuffle)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(5):
m.begin_epoch()
for batch in loader:
images, labels = batch
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('resuls')
out:
run epoch loss accuracy ... run duration lr batch_size shuffle
0 1 1 0.976744 0.624900 ... 19.091466 0.01 1000 True
1 1 2 0.524863 0.795667 ... 31.813530 0.01 1000 True
2 1 3 0.434542 0.840350 ... 41.206531 0.01 1000 True
3 1 4 0.391014 0.856400 ... 50.557536 0.01 1000 True
4 1 5 0.352655 0.868650 ... 59.941545 0.01 1000 True
5 2 1 0.976362 0.630917 ... 9.974009 0.01 1000 False
6 2 2 0.533491 0.792733 ... 19.494014 0.01 1000 False
7 2 3 0.441023 0.838600 ... 28.901019 0.01 1000 False
8 2 4 0.374183 0.863033 ... 38.352034 0.01 1000 False
9 2 5 0.343161 0.873083 ... 47.751039 0.01 1000 False
10 3 1 1.355159 0.473650 ... 10.573343 0.01 2000 True
11 3 2 0.711923 0.725067 ... 21.749933 0.01 2000 True
12 3 3 0.570347 0.777350 ... 32.124940 0.01 2000 True
13 3 4 0.512582 0.804017 ... 43.609567 0.01 2000 True
14 3 5 0.462824 0.826550 ... 65.107142 0.01 2000 True
15 4 1 1.152557 0.568633 ... 16.576952 0.01 2000 False
16 4 2 0.616844 0.755017 ... 34.007000 0.01 2000 False
17 4 3 0.505694 0.802017 ... 51.311929 0.01 2000 False
18 4 4 0.451951 0.829367 ... 69.817310 0.01 2000 False
19 4 5 0.410377 0.847433 ... 85.494321 0.01 2000 False
[20 rows x 9 columns]
在本地存储了训练的记录results.csv和results.json还有tensorboard的可视化数据


4.5 使用DataLoader的多进程功能加速神经网络训练
PyTorch DataLoader Num_workers-深度学习限速提升(pytorch系列-29)
这个链接是这节课程的讲解、
使用data loader类的num_workers可选属性可加速神经网络的训练
num_workers属性告诉data loader实例有多少个单元处理器用于数据加载
num_workers值的选择的最好方式是进行试验
本节课的实验结论:从这些结果中得到的主要结论是,在所有三个批次规模中,除了主流程外,拥有一个单一的工作流程可使速度提高约百分之二十。此外,在第一个流程之后增加额外的工作流程并没有真正显示出任何进一步的改进。
# 使用RunManager和RunBuilder类可以使得程序更易扩展
params = OrderedDict(
lr=[.01]
, batch_size=[100, 1000, 10000]
, num_workers=[0, 1, 2, 4, 8, 16]
#,shuffle = [True, False]
)
m = RunManager()
for run in RunBuilder.get_runs(params):
network = Network()
# 这里使用了shuffle:shuffle=run.shuffle
# 在训练之前,一般均会对数据集做shuffle,打乱数据之间的顺序,让数据随机化,这样可以避免过拟合。
# num_workers可选属性可加速神经网络的训练
# num_workers属性告诉data loader实例有多少个单元处理器用于数据加载
# loader = DataLoader(train_set, batch_size=run.batch_size, shuffle=run.shuffle)
loader = DataLoader(train_set, batch_size=run.batch_size, num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(1):
m.begin_epoch()
for batch in loader:
images, labels = batch
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('resuls')
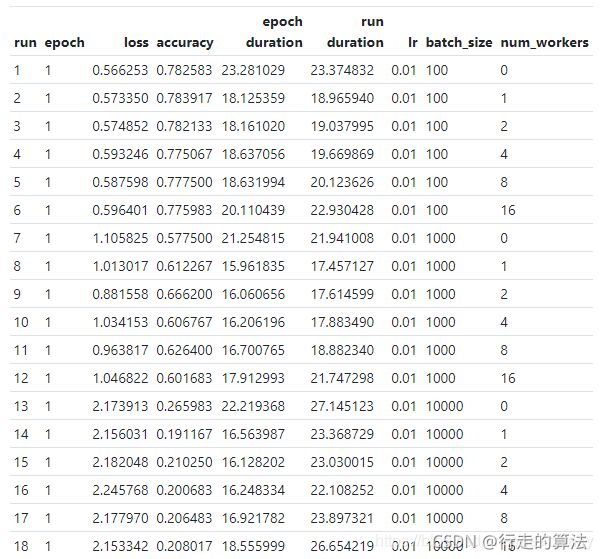
从这些结果中得到的主要结论是,在所有三个批次规模中,除了主流程外,拥有一个单一的工作流程可使速度提高约百分之二十。
此外,在第一个流程之后增加额外的工作流程并没有真正显示出任何进一步的改进。
报错:RuntimeError: DataLoader worker (pid(s) 22524) exited unexpectedly
将num_workers改为0即可,并且我在实际使用的时候,也是num_workers=0的时候没有报错,num_workers=1之后报错了。经过测试和网上搜索,基本确定了问题是内存不足造成的。
Pytorch:RuntimeError: DataLoader worker (pid 9119)
[解决方案] pytorch中RuntimeError: DataLoader worker (pid(s) 27292) exited unexpectedly
全部运行的代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from IPython.display import display, clear_output
import pandas as pd
import time
import json
from itertools import product
from collections import namedtuple
from collections import OrderedDict
import numpy as np
import time
import torchvision
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
class RunManager():
def __init__(self):
self.epoch_count = 0
self.epoch_loss = 0
self.epoch_num_correct = 0
self.epoch_start_time = None
self.run_params = None
self.run_count = 0
self.run_data = []
self.run_start_time = None
self.network = None
self.loader = None
self.tb = None
def begin_run(self, run, network, loader):
self.run_start_time = time.time()
self.run_params = run
self.run_count += 1
self.network = network
self.loader = loader
self.tb = SummaryWriter(comment=f'-{run}')
images, labels = next(iter(self.loader))
grid = torchvision.utils.make_grid(images)
self.tb.add_image('images', grid)
self.tb.add_graph(self.network, images)
def end_run(self):
self.tb.close()
self.epoch_count = 0
def begin_epoch(self):
self.epoch_start_time = time.time()
self.epoch_count += 1
self.epoch_loss = 0
self.epoch_num_correct = 0
def end_epoch(self):
epoch_duration = time.time() - self.epoch_start_time
run_duration = time.time() - self.run_start_time
loss = self.epoch_loss / len(self.loader.dataset)
accuracy = self.epoch_num_correct / len(self.loader.dataset)
self.tb.add_scalar('Loss', loss, self.epoch_count)
self.tb.add_scalar('Accuracy', accuracy, self.epoch_count)
for name, param in self.network.named_parameters():
self.tb.add_histogram(name, param, self.epoch_count)
self.tb.add_histogram(f'{name}.grad', param.grad, self.epoch_count)
results = OrderedDict()
results["run"] = self.run_count
results["epoch"] = self.epoch_count
results["loss"] = loss
results["accuracy"] = accuracy
results["epoch duration"] = epoch_duration
results["run duration"] = run_duration
for k, v in self.run_params._asdict().items(): results[k] = v
self.run_data.append(results)
df = pd.DataFrame.from_dict(self.run_data, orient='columns')
# 接下来的两行是Jupyter notebook特有的。我们清除当前的输出,并显示新的数据框架。
clear_output(wait=True)
display(df)
def track_loss(self, loss):
self.epoch_loss += loss.item() * self.loader.batch_size
def track_num_correct(self, preds, labels):
self.epoch_num_correct += self._get_num_correct(preds, labels)
# 这个函数的定义前面有一个下划线,表示它有点像一个私有的方法,并不打算被外部调用者使用
@torch.no_grad()
def _get_num_correct(self, preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item()
def save(self, fileName):
pd.DataFrame.from_dict(
self.run_data,
orient='columns').to_csv(f'{fileName}.csv')
with open(f'{fileName},json', 'w', encoding='utf-8') as f:
json.dump(self.run_data, f, ensure_ascii=False, indent=4)
class RunBuilder():
@staticmethod
def get_runs(params):
Run = namedtuple('Run', params.keys())
runs = []
for v in product(*params.values()):
runs.append(Run(*v))
return runs
train_set = torchvision.datasets.FashionMNIST(
root = './data/FashionMNIST',
train = True,
download = True,
transform = transforms.Compose([
transforms.ToTensor()
])
)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):
# Input Layer
t = t
# Conv1
t = F.relu(self.conv1(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
# Conv2
t = F.relu(self.conv2(t))
t = F.max_pool2d(t, kernel_size=2, stride=2)
# FC1
t = t.reshape(-1, 12 * 4 * 4)
t = F.relu(self.fc1(t))
# FC2
t = F.relu(self.fc2(t))
# Output
t = self.out(t)
return t
# 使用RunManager和RunBuilder类可以使得程序更易扩展
params = OrderedDict(
lr=[.01]
, batch_size=[100, 1000, 10000]
, num_workers=[0, 1, 2, 4, 8, 16]
#,shuffle = [True, False]
)
m = RunManager()
for run in RunBuilder.get_runs(params):
network = Network()
# 这里使用了shuffle:shuffle=run.shuffle
# 在训练之前,一般均会对数据集做shuffle,打乱数据之间的顺序,让数据随机化,这样可以避免过拟合。
# num_workers可选属性可加速神经网络的训练
# num_workers属性告诉data loader实例有多少个单元处理器用于数据加载
# loader = DataLoader(train_set, batch_size=run.batch_size, shuffle=run.shuffle)
loader = DataLoader(train_set, batch_size=run.batch_size, num_workers=run.num_workers)
optimizer = optim.Adam(network.parameters(), lr=run.lr)
m.begin_run(run, network, loader)
for epoch in range(1):
m.begin_epoch()
for batch in loader:
images, labels = batch
preds = network(images)
loss = F.cross_entropy(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
m.track_loss(loss)
m.track_num_correct(preds, labels)
m.end_epoch()
m.end_run()
m.save('resuls')