(机器学习深度学习常用库、框架|Pytorch篇)第(待定)节:卷积神经网络CNN中一些经典网络结构写法
文章目录
- 一:LeNet-5
- 二:AlexNet
- 三:VGG
- 四:ResNet
- 五:MobileNetV1
- 六:InceptionNet
一:LeNet-5
LeNet-5:LeNet-5是一个较简单的卷积神经网络。下图显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层

网络结构
class LeNet5(nn.Module):
""" 使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起 """
def __init__(self, in_channel, output):
super(LeNet5, self).__init__()
"""
卷积核5×5
卷积核数目 6
步幅1
填充2
池化层2×2
步幅2
"""
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=in_channel, out_channels=6, kernel_size=5, stride=1, padding=2), # (6, 28, 28)
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2, padding=0)) # (6, 14, 14))
"""
卷积核5×5
卷积核数目 16
步幅1
填充0
池化层2×2
步幅2
"""
self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0),
# (16, 10, 10)
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2, padding=0)) # (16, 5, 5)
# 全连接层1(可用卷积层代替)
self.layer3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5) # (120, 1, 1)
# 全连接层2、3
self.layer4 = nn.Sequential(nn.Linear(in_features=120, out_features=84),
nn.Tanh(),
nn.Linear(in_features=84, out_features=output))
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
# 进入全连接层前展平
x = torch.flatten(input=x, start_dim=1)
x = self.layer4(x)
return x
二:AlexNet
AlexNet:Alex网络结构如下图所示,其设计理念和LeNet-5非常相似,主要区别如下
- 网络结构要比LeNet5深很多
- 由5个卷积层、两个全连接层隐藏层和一个全连接输出层组成
- AlexNet使用ReLU作为激活函数
- AlexNet第一层的卷积核比较大,为11×11,这是因为ImageNet中大多图像要比MNIST图像多10倍以上
- AlexNet使用dropout算法来控制全连接层复杂程度,而LeNet5只使用了权重衰减
- AlexNet对图像数据进行了增广(例如对一张图像翻转、裁切和变色相等于有了3张以上的图像),这增大了样本量,减少了过拟合

网络结构
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as F
class AlexNet(nn.Module):
"""
out_dim:最终分类的数目
init_weights:设置是否初始化权重,默认为False
"""
def __init__(self, num_classes, init_weights=False):
super(AlexNet, self).__init__()
# 标准AlexNet
self.conv = nn.Sequential(
# [224, 224, 3] -> [55, 55, 96]
# [55, 55, 96] -> [27, 27, 96]
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(), # 可以载入更大的模型
nn.MaxPool2d(kernel_size=3, stride=2),
# [27, 27, 96] -> [27, 27, 256]
# [27, 27, 256] -> [13, 13, 256]
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# [13, 13, 256] -> [13, 13, 384]
# [13, 13, 384] -> [13, 13, 384]
# [13, 13, 384] -> [13, 13, 256]
# [13, 13, 256] -> [6, 6, 256]
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.fc = nn.Sequential(
# 到这里需要使用dropout减少过拟合
nn.Dropout(p=0.5),
nn.Linear(6 * 6 * 256, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, num_classes)
)
# 如果设置了初始化权重,那么就调用对应方法
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.conv(x)
# 进入全连接层前展平
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
# 权重初始化(KaiMing)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
三:VGG

# 给定字典选择模型
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
#'vgg16': [16, 16, 'M', 32, 32, 'M', 64, 64, 64, 'M', 128, 128, 128, 'M', 128, 128, 128, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# 生成卷积层
def create_conv(cfg):
layers = []
in_chaneels = parametes.init_in_chaneels
# 遍历列表
for c in cfg:
# 如果遇到"M",则增加一个最大池化层,其kernel_size=2, stride=2
if c == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
# 如果是数字,则代表该卷积核输出,卷积核统一为3×3,填充为1
else:
Conv2d = nn.Conv2d(in_channels=in_chaneels, out_channels=c, kernel_size=3, padding=1)
layers += [Conv2d, nn.ReLU(True)]
# 下一个输入通道等于现在的输出通道
in_chaneels = c
return nn.Sequential(*layers)
# VGG16网络
class VGG16(nn.Module):
def __init__(self, conv, num_classes, init_weights=False):
super(VGG16, self).__init__()
self.conv = conv
self.fc = nn.Sequential(
# 图片输入为224×224的前提下
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.conv(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
# 参数初始化(KAIMING)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# 初始化网络
cfg = model.cfgs['vgg16']
net = model.VGG16(model.create_conv(cfg), parametes.num_classes, True)
net = net.to(parametes.device)
如下是VGG13,这种写法比较臃肿但清晰
import torch
import torch.nn as nn
import torch.nn.functional as F
class VGG13(nn.Module):
def __init__(self):
super(VGG13, self).__init__()
# N * 3 * 32 * 32
self.conv1_1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.conv1_2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.max_pooling1 = nn.MaxPool2d(kernel_size=2, stride=2)
# N * 64 * 16 * 16
self.conv2_1 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.conv2_2 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.max_pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)
# N * 128 * 8 * 8
self.conv3_1 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.conv3_2 = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.max_pooling3 = nn.MaxPool2d(kernel_size=2, stride=2)
# N * 256 * 4 * 4
self.conv4_1 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.conv4_2 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.max_pooling4 = nn.MaxPool2d(kernel_size=2, stride=2)
# N * 512 * 2 * 2
self.conv5_1 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.conv5_2 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.max_pooling5 = nn.MaxPool2d(kernel_size=2, stride=2)
# N * 512 * 1 * 1
# 全连接层
self.fc = nn.Sequential(
nn.Linear(512 * 1 * 1, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 10)
)
def forward(self, x):
out = self.conv1_1(x)
out = self.conv1_2(out)
out = self.max_pooling1(out)
out = self.conv2_1(out)
out = self.conv2_2(out)
out = self.max_pooling2(out)
out = self.conv3_1(out)
out = self.conv3_2(out)
out = self.max_pooling3(out)
out = self.conv4_1(out)
out = self.conv4_2(out)
out = self.max_pooling4(out)
out = self.conv5_1(out)
out = self.conv5_2(out)
out = self.max_pooling5(out)
out = torch.flatten(out, start_dim=1)
out = self.fc(out)
return out
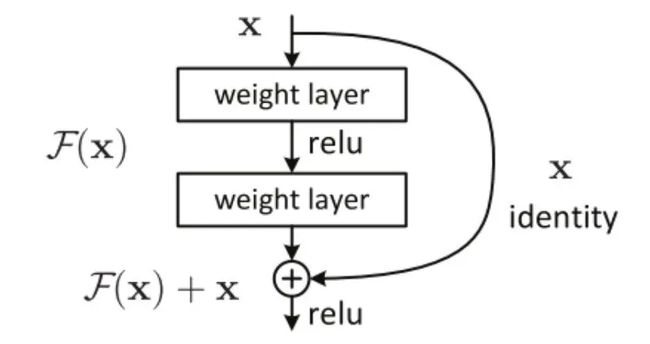
四:ResNet
import torch
import torch.nn as nn
import torch.nn.functional as F
# 基本跳连单元
class ResBlock(nn.Module):
def __init__(self, in_channel, out_channel, stride=1):
super(ResBlock, self).__init__()
# 主干分支
self.layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channel),
)
# 跳连分支
self.shortcut = nn.Sequential()
# 如果输入通道和输出通道不相等或者步长不是1,那么跳连分支必须再进行卷积
if in_channel != out_channel or stride > 1:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(out_channel),
)
def forward(self, x):
# 主干
out1 = self.layer(x)
# 分支
out2 = self.shortcut(x)
# 最终结果 = 主干+分支
out = out1 + out2
out = F.relu(out)
class ResNet(nn.Module):
def make_layer(self, block, out_channel, stride, num_block):
layer_list = []
for i in range(num_block):
if i == 0:
in_stride = stride
else:
in_stride = 1
layer_list.append(block(self.in_channel, out_channel, in_stride))
self.in_channel = out_channel
return nn.Sequential(*layer_list)
def __init__(self):
super(ResNet, self).__init__()
# 第一层采用普通卷积
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU
)
# 四层ResNet
self.in_channel = 32
self.layer1 = self.make_layer(ResBlock, 64, 2, 2)
self.layer2 = self.make_layer(ResBlock, 128, 2, 2)
self.layer3 = self.make_layer(ResBlock, 256, 2, 2)
self.layer4 = self.make_layer(ResBlock, 512, 2, 2)
self.fc = nn.Linear(512, 10)
def farward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
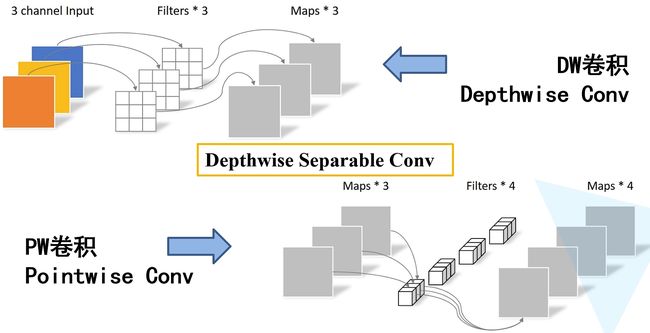
五:MobileNetV1
import torch
import torch.nn as nn
import torch.nn.functional as F
class MobileNet(nn.Module):
# 深度可分离卷积由分组卷积和点卷积构成(基本单元)
def conv_dw(self, in_channel, out_channel, stride):
return nn.Sequential(
# 分组卷积
nn.Conv2d(in_channel, in_channel, kernel_size=3, stride=stride, padding=1, groups=in_channel,
bias=False),
nn.BatchNorm2d(in_channel),
nn.ReLU(),
# 点卷积
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(),
)
def __init__(self):
super(MobileNet, self).__init__()
# 标准卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU()
)
# 深度可分离卷积
self.convdw2 = self.conv_dw(32, 32, 1)
self.convdw3 = self.conv_dw(32, 64, 2)
self.convdw4 = self.conv_dw(64, 64, 1)
self.convdw5 = self.conv_dw(64, 128, 2)
self.convdw6 = self.conv_dw(128, 128, 1)
self.convdw7 = self.conv_dw(128, 256, 2)
self.convdw8 = self.conv_dw(256, 256, 1)
self.convdw9 = self.conv_dw(256, 512, 2)
# 全连接层
self.fc = nn.Linear(512, 10)
def forward(self, x):
out = self.conv1(x)
out = self.convdw2(out)
out = self.convdw3(out)
out = self.convdw4(out)
out = self.convdw5(out)
out = self.convdw7(out)
out = self.convdw8(out)
out = self.convdw9(out)
out = F.avg_pool2d(out, 2)
out = out.view(-1, 512)
out = self.fc(out)
return out
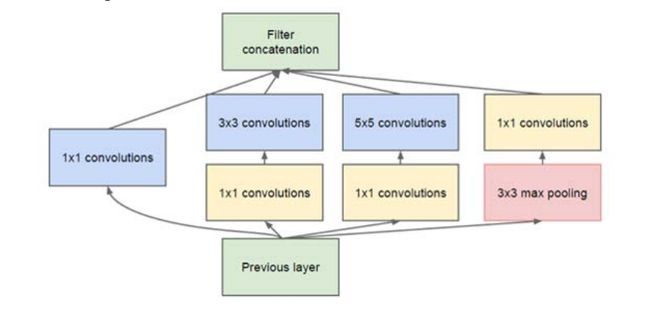
六:InceptionNet
import torch
import torch.nn as nn
import torch.nn.functional as F
"""
InceptionNet属于网中网结构,对输入进行
不同分支的卷积,最后进行concat
"""
def ConvBNRelu(in_channel, out_channel, kernel_size):
return nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=1, padding=kernel_size//2),
nn.BatchNorm2d(out_channel),
nn.ReLU()
)
class BaseInception(nn.Module):
def __init__(self, in_channel, out_channel_list, reduce_channel_list):
super(BaseInception, self).__init__()
# 定义4个分支
# 第1个分支
self.branch1_conv = ConvBNRelu(in_channel, out_channel_list[0], 1)
# 剩余分支为减少计算量必须先进行压缩
self.branch2_conv1 = ConvBNRelu(in_channel, reduce_channel_list[0], 1)
self.branch2_conv2 = ConvBNRelu(reduce_channel_list[0], out_channel_list[1], 3)
self.branch3_conv1 = ConvBNRelu(in_channel, reduce_channel_list[1], 1)
self.branch3_conv2 = ConvBNRelu(reduce_channel_list[1], out_channel_list[2], 5)
self.branch4_pool = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.branch4_conv = ConvBNRelu(in_channel, out_channel_list[3], 3)
def forward(self, x):
out1 = self.branch1_conv(x)
out2 = self.branch2_conv1(x)
out2 = self.branch3_conv2(out2)
out3 = self.branch3_conv1(x)
out3 = self.branch3_conv2(out3)
out4 = self.branch4_pool(x)
out4 = self.branch4_conv(out4)
out = torch.cat([out1, out2, out3, out4], dim=1)
return out
class InceptionNet(nn.Module):
def __init__(self):
super(InceptionNet, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
)
self.block3 = nn.Sequential(
BaseInception(in_channel=128, out_channel_list=[64, 64, 64, 64], reduce_channel_list=[16, 16]),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.block4 = nn.Sequential(
BaseInception(in_channel=256, out_channel_list=[96, 96, 96, 96], reduce_channel_list=[32, 32]),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.fc = nn.Linear(384, 10)
def forward(self, x):
out = self.block1(x)
out = self.block1(out)
out = self.block1(out)
out = self.block1(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out