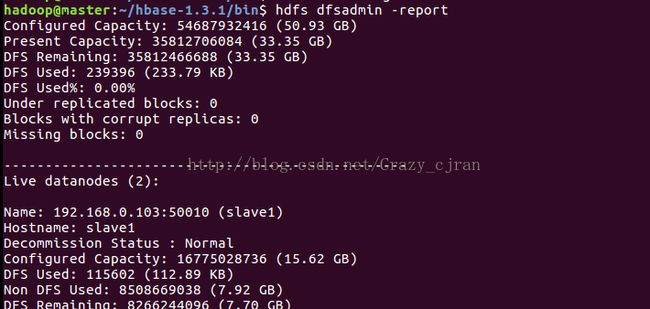
hadoop2.6.5+zookeeper3.4.10+hbase1.3.1分布式集群搭建
一、配置环境
1.三台虚拟机ubuntu16.04
相关软件包
1. jdk1.8.0_112
2. hadoop2.6.5
3.zookeper3.4.10
4.hbase1.3.1
注:此处采用了三台虚拟机,为方便维护,此处采取了相同的用户名,用户密码,相同的目录结构
二、安装Java环境
1.下载jdk1.8.0_112压缩包,解压(作者采用的解压路径为:/usr/lib/jvm/)
2.配置/etc/profile文件:
sudo vim /etc/profile
在文档末尾追加:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_112
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
保存配置文件退出
应用更新后的配置文件source /etc/profile
执行java -version
查看是否安装成功
三、搭建hadoop集群
三台虚拟机都需要进行以下配置
1.分别修改三台主机的主机名,分别为:master,slave1,slave2
注:master为主节点,slave1,slave2为从节点
修改主机名命令:
sudo /etc/hostname
将里面的ubuntu(ubuntu默认主机名)改成各自对应的主机名,保存退出
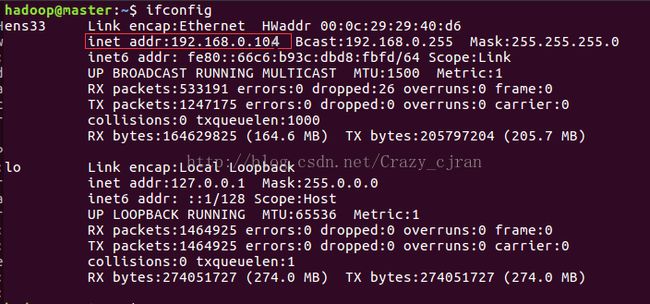
2.配置hosts文件(主机ip映射)
使用ifconfig可查看当前主机ip
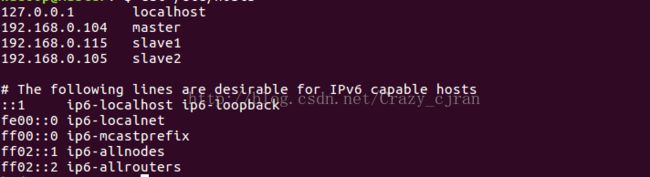
sudo vim /etc/hosts
添加主机映射:(作者使用的动态ip,每当ip发生更改时都要修改本文件)
3.创建hadoop用户并加入到组hadoop中
a.创建用户组hadoop
sudo groupadd hadoop
b.创建用户名为hadoop的用户并添加到组群hadoop中
sudo useradd -s /bin/bash -d /home/hadoop -m -g hadoop
c.重置新增hadoop用户密码(在上述创建用户过程中未设置密码,会导致无法登录)
sudo passwd hadoop
输入新密码
d.将新用户hadoop加入到组群sudo
sudo adduser hadoop sudo
c.切换到用户hadoop
su hadoop
4.配置ssh免秘钥登录(ssh安装略)
a.执行ssh-keygen -t rsa一路回车什么都不要输入
b.cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
修改权限(很重要!!!)
sudo chmod 755 /home/hadoop
sudo chmod 700 /home/hadoop/.ssh
sudo chmod 600 /home/hadoop/.ssh/authorized_keys
测试是否配置成功:ssh localhost
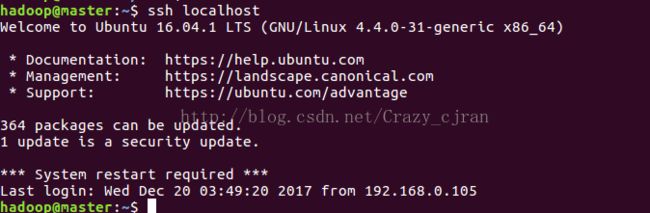
使用exit退出
d.各主机互相能免密码登录(确保三台主机能互相ping通)
此处以master主机为例将本机的公钥发送到另外两台主机的家目录下:
scp ~/.ssh/id_rsa.pub [email protected]:~/
scp ~/.ssh/id_rsa.pub [email protected]:~/
(此处的hadoop就是另外两台主机前面所创建的新用户的用户名,后面是其对应的ip)
将另外两台主机发送过来的公钥追加到authorized_keys中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
注:发送时不要覆盖了其他主机发送的公钥
测试是否配置成功ssh slave1(不需要输入密码,记得退出exit)
以下只在主节点master上配置,配置完拷贝到另外两台从节点上
5.下载并解压hadoop文件到家目录下

进入hadoop-2.6.5下
在该目录下创建tmp文件夹
修改以下文件:
etc/hadoop/hadoop-env.sh

etc/hadoop/core-site.xml
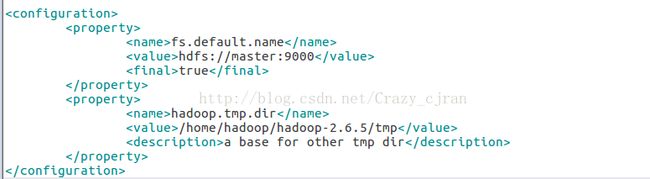
etc/hadoop/hdfs-site.xml
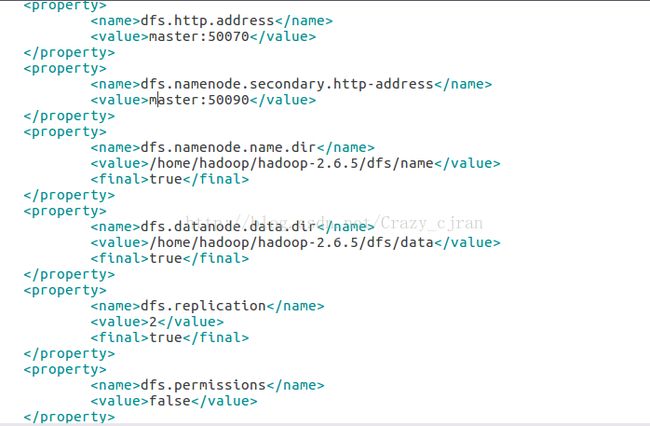
etc/hadoop/mapred-site.xml

etc/hadoop/slaves
![]()
etc/hadoop/yarn-site.xml
以下为三台主机都需要进行的配置:
修改/etc/profile文件:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_112
export HADOOP_HOME=/home/hadoop/hadoop-2.6.5
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
source /etc/profile
以下只在主节点上master进行
将master主机上配置好的hadoop-2.6.5发送到另外两台从节点
scp -r ~/hadoop-2.6.5 [email protected]:~/
scp -r ~/hadoop-2.6.5 [email protected]:~/
输入hadoop version可以查看当前hadoop版本
在主节点master上初始化hadoop
进入hadoop目录hadoop-2.6.5/bin/
执行:hadoop namenode -format
切换到hadoop-2.6.5的sbin目录下
执行:bash start-all.sh启动hadoop集群
启动完成后查看进程:jps
master节点上:

slave节点上:

四、搭建zookeper集群
以下只在主节点上配置:
下载zookeper3.4.10并解压到家目录下
进入zookeper3.4.10目录下:
将conf/zoo_example.cfg复制一份并重命名为zoo.cfg
修改/conf/zoo.cfg

在zookeper-3.4.10目录下新建data文件夹,在data文件夹下创建文件myid
master上该文件内容为1,slave1为2,slave2为3
将zookeper文件夹发送到从节点上
scp -r ~/zookeper-3.4.10 [email protected]:~/
scp -r ~ /zookeper-3.4.10 [email protected]:~/
修改前面提到的myid的值
以下需要在三台主机上都执行:
启动zookeper集群
进入zookeper-3.4.10目录下的bin目录下
执行:./zkServer.sh start启动zookeper

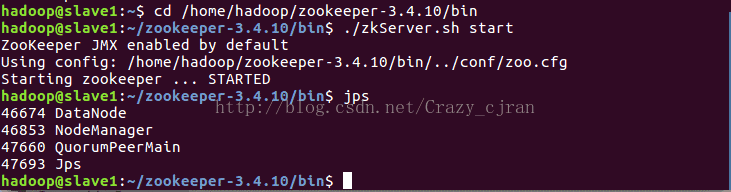
执行:./zkServer.sh status可查看启动状态,三台主机中有一台会成为leader,其余为follower
五、搭建hbase集群
以下只在master节点上配置:
1.下载hbase1.3.1并解压到家目录下
进入hbase-1.3.1目录下修改以下文件:
conf/hbase-env.sh
![]()
conf/hase.site.xml

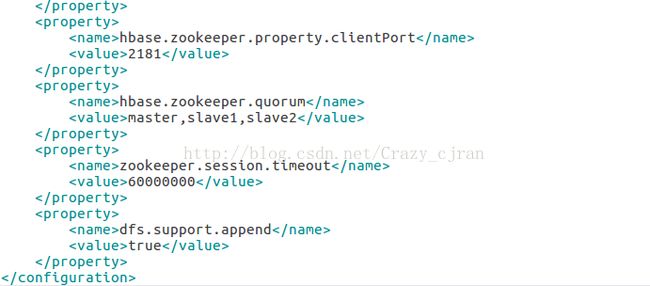
conf/regionservers
将hbase1.3.1文件夹发送到从节点上
scp -r ~/hbase-1.3.1 [email protected]:~/
scp -r ~/hbase-1.3.1 [email protected]:~/
以下为三台主机都要进行的配置
修改/etc/profile

source /etc/profile
在主节点的hbase-1.3.1目录下的bin目录中执行:
bash start-hbase.sh

查看各节点启动情况:


在主节点master上查看各从节点状况: