病理组织切片公开代码在运行过程中出现的一些错误
一、DSMIL方法
1.在配置环境时遇到的相关问题
(1).AttributeError: ‘version_info’ object has no attribute ‘version’
解决办法: pip install pyparsing==2.4.7
(2).解决GPU上运行pytorch代码的错误
python: symbol lookup error: /home/daichuangchuang/anaconda2/envs/dsmil/lib/python3.6/site-packages/torch/lib/libtorch_python.so: undefined symbol: PySlice_Unpack
解决办法:
a.首先原有的环境:pip freeze>requirements.txt
b.创建一个新的环境:conda create -n DSMIL python==3.6.2
c.激活新建的环境:conda activate DSMIL
d.安装原有环境中的所有包:pip install -r requirement.txt
e.原有的错误问题的得到解决。
注:在运行conda create -n DSMIL python==3.6.2遇到了如下问题conda._vendor.auxlib.exceptions.ValidationError: Value for sha256 cannot be None.
(3).torch版本问题
Traceback (most recent call last):
File “train_tcga.py”, line 204, in
main()
File “train_tcga.py”, line 160, in main
state_dict_weights = torch.load(‘init.pth’)
File “/home/daichuangchuang/anaconda2/envs/DSMIL/lib/python3.6/site-packages/torch/serialization.py”, line 527, in load
with _open_zipfile_reader(f) as opened_zipfile:
File “/home/daichuangchuang/anaconda2/envs/DSMIL/lib/python3.6/site-packages/torch/serialization.py”, line 224, in init
super(_open_zipfile_reader, self).init(torch.C.PyTorchFileReader(name_or_buffer))
RuntimeError: version <= kMaxSupportedFileFormatVersion INTERNAL ASSERT FAILED at /pytorch/caffe2/serialize/inline_container.cc:132, please report a bug to PyTorch. Attempted to read a PyTorch file with version 3, but the maximum supported version for reading is 2. Your PyTorch installation may be too old. (init at /pytorch/caffe2/serialize/inline_container.cc:132)
frame #0: c10::Error::Error(c10::SourceLocation, std::string const&) + 0x33 (0x7f03dc263193 in /home/daichuangchuang/anaconda2/envs/DSMIL/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #1: caffe2::serialize::PyTorchStreamReader::init() + 0x1f5b (0x7f02aca0e9eb in /home/daichuangchuang/anaconda2/envs/DSMIL/lib/python3.6/site-packages/torch/lib/libtorch.so)
frame #2: caffe2::serialize::PyTorchStreamReader::PyTorchStreamReader(std::string const&) + 0x64 (0x7f02aca0fc04 in /home/daichuangchuang/anaconda2/envs/DSMIL/lib/python3.6/site-packages/torch/lib/libtorch.so)
frame #3: + 0x6c53a6 (0x7f03dd12d3a6 in /home/daichuangchuang/anaconda2/envs/DSMIL/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #4: + 0x2961c4 (0x7f03dccfe1c4 in /home/daichuangchuang/anaconda2/envs/DSMIL/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #38: __libc_start_main + 0xe7 (0x7f03e2273c87 in /lib/x86_64-linux-gnu/libc.so.6)
解决方法:
pip install torch==1.8.0
pip install torchvision==0.9.0
(4).运行错误
RuntimeError: CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling cublasCreate(handle)
解决办法:需要重新安装对应的版本:
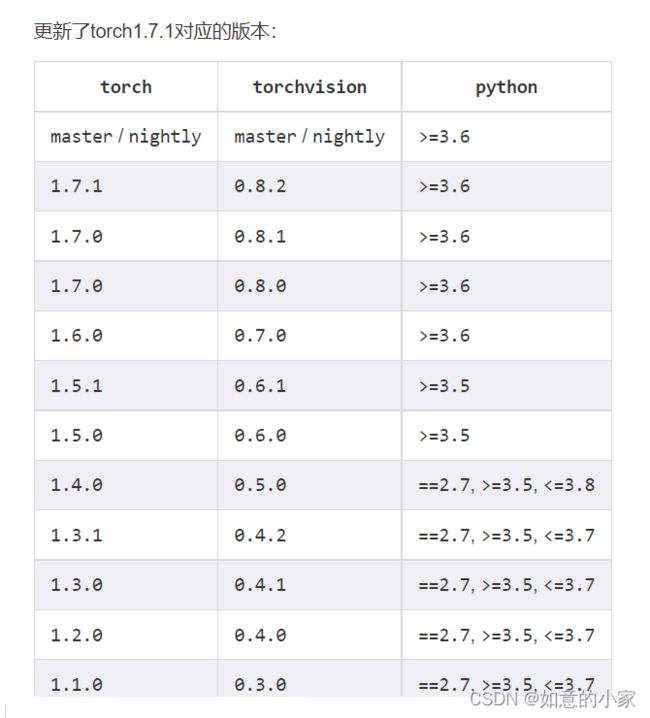
具体命令:
pip install torchvision==0.8.2
pip install torch==1.7.1
(5).针对运行过程中出现的断网情况,可通过来修改代码来进行改进,主要实现从上一次的断开的处理地方接着进行处理:
import json
from multiprocessing import Process, JoinableQueue
import argparse
import os
import re
import shutil
import sys
import glob
import numpy as np
import math
from unicodedata import normalize
from skimage import io
from skimage.color import rgb2hsv
from skimage.util import img_as_ubyte
from skimage import filters
from PIL import Image, ImageFilter, ImageStat
Image.MAX_IMAGE_PIXELS = None
import openslide
from openslide import open_slide, ImageSlide
from openslide.deepzoom import DeepZoomGenerator
VIEWER_SLIDE_NAME = 'slide'
class TileWorker(Process):
"""A child process that generates and writes tiles."""
def __init__(self, queue, slidepath, tile_size, overlap, limit_bounds,
quality, threshold):
Process.__init__(self, name='TileWorker')
self.daemon = True
self._queue = queue
self._slidepath = slidepath
self._tile_size = tile_size
self._overlap = overlap
self._limit_bounds = limit_bounds
self._quality = quality
self._threshold = threshold
self._slide = None
def run(self):
self._slide = open_slide(self._slidepath)
last_associated = None
dz = self._get_dz()
while True:
data = self._queue.get()
if data is None:
self._queue.task_done()
break
associated, level, address, outfile = data
if last_associated != associated:
dz = self._get_dz(associated)
last_associated = associated
try:
tile = dz.get_tile(level, address)
edge = tile.filter(ImageFilter.FIND_EDGES)
edge = ImageStat.Stat(edge).sum
edge = np.mean(edge)/(self._tile_size**2)
w, h = tile.size
if edge > self._threshold:
if not (w==self._tile_size and h==self._tile_size):
tile = tile.resize((self._tile_size, self._tile_size))
tile.save(outfile, quality=self._quality)
except:
pass
self._queue.task_done()
def _get_dz(self, associated=None):
if associated is not None:
image = ImageSlide(self._slide.associated_images[associated])
else:
image = self._slide
return DeepZoomGenerator(image, self._tile_size, self._overlap,
limit_bounds=self._limit_bounds)
class DeepZoomImageTiler(object):
"""Handles generation of tiles and metadata for a single image."""
def __init__(self, dz, basename, target_levels, mag_base, format, associated, queue):
self._dz = dz
self._basename = basename
self._format = format
self._associated = associated
self._queue = queue
self._processed = 0
self._target_levels = target_levels
self._mag_base = int(mag_base)
def run(self):
self._write_tiles()
def _write_tiles(self):
target_levels = [self._dz.level_count-i-1 for i in self._target_levels]
mag_list = [int(self._mag_base/2**i) for i in self._target_levels]
mag_idx = 0
for level in range(self._dz.level_count):
if not (level in target_levels):
continue
tiledir = os.path.join("%s_files" % self._basename, str(mag_list[mag_idx]))
if not os.path.exists(tiledir):
os.makedirs(tiledir)
cols, rows = self._dz.level_tiles[level]
for row in range(rows):
for col in range(cols):
tilename = os.path.join(tiledir, '%d_%d.%s' % (
col, row, self._format))
if not os.path.exists(tilename):
self._queue.put((self._associated, level, (col, row),
tilename))
self._tile_done()
mag_idx += 1
def _tile_done(self):
self._processed += 1
count, total = self._processed, self._dz.tile_count
if count % 100 == 0 or count == total:
print("Tiling %s: wrote %d/%d tiles" % (
self._associated or 'slide', count, total),
end='\r', file=sys.stderr)
if count == total:
print(file=sys.stderr)
class DeepZoomStaticTiler(object):
"""Handles generation of tiles and metadata for all images in a slide."""
def __init__(self, slidepath, basename, mag_levels, base_mag, objective, format, tile_size, overlap,
limit_bounds, quality, workers, threshold):
self._slide = open_slide(slidepath)
self._basename = basename
self._format = format
self._tile_size = tile_size
self._overlap = overlap
self._mag_levels = mag_levels
self._base_mag = base_mag
self._objective = objective
self._limit_bounds = limit_bounds
self._queue = JoinableQueue(2 * workers)
self._workers = workers
self._dzi_data = {}
for _i in range(workers):
TileWorker(self._queue, slidepath, tile_size, overlap,
limit_bounds, quality, threshold).start()
def run(self):
self._run_image()
self._shutdown()
def _run_image(self, associated=None):
"""Run a single image from self._slide."""
if associated is None:
image = self._slide
basename = self._basename
else:
image = ImageSlide(self._slide.associated_images[associated])
basename = os.path.join(self._basename, self._slugify(associated))
dz = DeepZoomGenerator(image, self._tile_size, self._overlap,
limit_bounds=self._limit_bounds)
MAG_BASE = self._slide.properties.get(openslide.PROPERTY_NAME_OBJECTIVE_POWER)
if MAG_BASE is None:
MAG_BASE = self._objective
first_level = int(math.log2(float(MAG_BASE)/self._base_mag)) # raw / input, 40/20=2, 40/40=0
target_levels = [i+first_level for i in self._mag_levels] # levels start from 0
target_levels.reverse()
tiler = DeepZoomImageTiler(dz, basename, target_levels, MAG_BASE, self._format, associated,
self._queue)
tiler.run()
def _url_for(self, associated):
if associated is None:
base = VIEWER_SLIDE_NAME
else:
base = self._slugify(associated)
return '%s.dzi' % base
def _copydir(self, src, dest):
if not os.path.exists(dest):
os.makedirs(dest)
for name in os.listdir(src):
srcpath = os.path.join(src, name)
if os.path.isfile(srcpath):
shutil.copy(srcpath, os.path.join(dest, name))
@classmethod
def _slugify(cls, text):
text = normalize('NFKD', text.lower()).encode('ascii', 'ignore').decode()
return re.sub('[^a-z0-9]+', '_', text)
def _shutdown(self):
for _i in range(self._workers):
self._queue.put(None)
self._queue.join()
def nested_patches(img_slide, out_base, level=(0,), ext='jpeg'):
print('\n Organizing patches')
img_name = img_slide.split(os.sep)[-1].split('.')[0]
img_class = img_slide.split(os.sep)[-2]
n_levels = len(glob.glob('WSI_temp_files/*'))
bag_path = os.path.join(out_base, img_class, img_name)
os.makedirs(bag_path, exist_ok=True)
if len(level)==1:
patches = glob.glob(os.path.join('WSI_temp_files', '*', '*.'+ext))
for i, patch in enumerate(patches):
patch_name = patch.split(os.sep)[-1]
shutil.move(patch, os.path.join(bag_path, patch_name))
sys.stdout.write('\r Patch [%d/%d]' % (i+1, len(patches)))
print('Done.')
else:
level_factor = 2**int(level[1]-level[0])
levels = [int(os.path.basename(i)) for i in glob.glob(os.path.join('WSI_temp_files', '*'))]
levels.sort()
low_patches = glob.glob(os.path.join('WSI_temp_files', str(levels[0]), '*.'+ext))
for i, low_patch in enumerate(low_patches):
low_patch_name = low_patch.split(os.sep)[-1]
shutil.move(low_patch, os.path.join(bag_path, low_patch_name))
low_patch_folder = low_patch_name.split('.')[0]
high_patch_path = os.path.join(bag_path, low_patch_folder)
os.makedirs(high_patch_path, exist_ok=True)
low_x = int(low_patch_folder.split('_')[0])
low_y = int(low_patch_folder.split('_')[1])
high_x_list = list( range(low_x*level_factor, (low_x+1)*level_factor) )
high_y_list = list( range(low_y*level_factor, (low_y+1)*level_factor) )
for x_pos in high_x_list:
for y_pos in high_y_list:
high_patch = glob.glob(os.path.join('WSI_temp_files', str(levels[1]), '{}_{}.'.format(x_pos, y_pos)+ext))
if len(high_patch)!=0:
high_patch = high_patch[0]
shutil.move(high_patch, os.path.join(bag_path, low_patch_folder, high_patch.split(os.sep)[-1]))
try:
os.rmdir(os.path.join(bag_path, low_patch_folder))
os.remove(low_patch)
except:
pass
sys.stdout.write('\r Patch [%d/%d]' % (i+1, len(low_patches)))
print('Done.')
if __name__ == '__main__':
Image.MAX_IMAGE_PIXELS = None
parser = argparse.ArgumentParser(description='Patch extraction for WSI')
parser.add_argument('-d', '--dataset', type=str, default='CPTAC', help='Dataset name')
parser.add_argument('-e', '--overlap', type=int, default=0, help='Overlap of adjacent tiles [0]')
parser.add_argument('-f', '--format', type=str, default='jpeg', help='Image format for tiles [jpeg]')
parser.add_argument('-v', '--slide_format', type=str, default='svs', help='Image format for tiles [svs]')
parser.add_argument('-j', '--workers', type=int, default=4, help='Number of worker processes to start [4]')
parser.add_argument('-q', '--quality', type=int, default=70, help='JPEG compression quality [70]')
parser.add_argument('-s', '--tile_size', type=int, default=224, help='Tile size [224]')
parser.add_argument('-b', '--base_mag', type=float, default=20, help='Maximum magnification for patch extraction [20]')
parser.add_argument('-m', '--magnifications', type=int, nargs='+', default=(0,), help='Levels for patch extraction [0]')
parser.add_argument('-o', '--objective', type=float, default=20, help='The default objective power if metadata does not present [20]')
parser.add_argument('-t', '--background_t', type=int, default=15, help='Threshold for filtering background [15]')
args = parser.parse_args()
levels = tuple(args.magnifications)
assert len(levels)<=2, 'Only 1 or 2 magnifications are supported!'
path_base = os.path.join('WSI', args.dataset)
if len(levels) == 2:
out_base = os.path.join('WSI', args.dataset, 'pyramid')
else:
out_base = os.path.join('WSI', args.dataset, 'single')
path_base = "/mnt/data/CPTAC/CCRCC"
all_slides = glob.glob(os.path.join(path_base, '*.'+args.slide_format)) #'/mnt/data/CPTAC/CCRCC/C3N-01989-23.svs'
img_class = path_base.split(os.sep)[-1]
path_test=os.path.join(out_base,img_class)
processed_slide_name=os.listdir(path_test)
# pos-i_pos-j -> x, y
for idx, c_slide in enumerate(all_slides):
print('Process slide {}/{}'.format(idx+1, len(all_slides)))
#img_class = c_slide.split(os.sep)[-2]
img_class = c_slide.split(os.sep)[-1][:-4]
if img_class in processed_slide_name:
continue
DeepZoomStaticTiler(c_slide, 'WSI_temp', levels, args.base_mag, args.objective, args.format, args.tile_size, args.overlap, True, args.quality, args.workers, args.background_t).run()
nested_patches(c_slide, out_base, levels, ext=args.format)
shutil.rmtree('WSI_temp_files')
print('Patch extraction done for {} slides.'.format(len(all_slides)))
(6).安装apex,混合精度训练->Install apex for mixed-precision training
git clone https://github.com/NVIDIA/apex
cd apex
(7).如何安装openslide软件包
pip install openslide-python
(8).如何实现存在公共存储空间内的数据挂载在虚拟机内?
在虚拟机内进行运行:
a.新建文件夹:mkdir -p /mnt/lhj
b.对数据进行挂载:sshfs -o StrictHostKeyChecking=no -o allow_other hejiayin@vmIpHost:/public/data/20220303 /mnt/lhj
2.如何将训练好的模型在自己的数据集上进行相关的操作呢?
(1).将 WSI 文件放置为WSI[DATASET_NAME][CATEGORY_NAME][SLIDE_FOLDER_NAME] (optional)\SLIDE_NAME.svs.
对于二元分类器,负类在按字母顺序排序时应具有[CATEGORY_NAME]索引。0对于多类分类器,如果您有一个负类(不属于任何正类),则该文件夹应[CATEGORY_NAME]在按字母顺序排序时位于最后一个索引处。如果您没有否定类,则类文件夹的命名无关紧要。
将数据集以下面这种方式进行组织:
(2).Patch的裁剪
python deepzoom_tiler_lhj.py -m 0 -b 20 -d /mnt/data/Nature/dsmil-wsi/WSI/CPTAC/
(3).训练嵌入器
python run.py --multiscale=1 --dataset=/mnt/data/Nature/dsmil-wsi/WSI/CPTAC/
在进行嵌入器的训练时,会出现如下错误:RuntimeError: CUDA out of memory. Tried to allocate 450.00 MiB (GPU 0; 11.91 GiB total capacity; 10.83 GiB already allocated; 55.25 MiB free; 11.05 GiB reserved in total by PyTorch)。
详见链接:https://blog.csdn.net/weixin_57234928/article/details/123556441
**ImportError: /lib64/libstdc++.so.6: versionGLIBCXX_3.4.21’ not found**
https://blog.csdn.net/lbj23hao1/article/details/106050410
AttributeError: module ‘torch.nn’ has no attribute ‘GELU’
https://github.com/facebookresearch/fairseq/issues/2510
3.【踩坑】RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)
在使用create_heatmaps_TransformerMIL.py 和create_heatmaps_TransMIL.py对病理组织切片进行热图绘制时会出现这个错误,可能不是网上说的各种原因,仅仅是因为显存不够了。