论文翻译 || 模型剪枝(1)—— PRUNING FILTERS FOR EFFICIENT CONVNETS
ABSTRACT
在各种应用中的成功伴随着计算和参数存储成本的显著增加。最近为减少这些开销所做的努力包括在不损害原有精度的情况下修剪和压缩各层的权重。
- 然而,基于大小的权重剪枝 从完全连通的层中减少了大量的参数,由于剪枝后的网络具有不规则的稀疏性,可能不能充分降低卷积层的计算成本。我们提出了一种cnn的加速方法,我们从被识别为对输出精度影响很小的cnn中删除滤波器。通过去除网络中所有的过滤器及其连接的特征映射,大大降低了计算成本。
- 与修剪权值相反,这种方法 (滤波器剪枝)不会导致稀疏连接模式。因此,它不需要稀疏卷积库的支持,并且可以使用现有的高效BLAS库进行密集矩阵乘法。我们表明,即使是简单的过滤器修剪技术也可以在CIFAR10上降低高达34%的VGG-16和高达38%的ResNet-110的推理成本,同时通过重新训练网络恢复接近原始的准确性。
1 本论文,提出的方法,基本在于【基于大小的权重剪枝】的方式进行对比
2 这里翻译的 ”滤波器 F“,也就是卷积核的意思, F i ∈ R n i × n i + 1 × k × k F_{i}∈R^{n_i×n_{i+1}×k×k} Fi∈Rni×ni+1×k×k
1 INTRODUCTION
【网络越来越深,计算成本相应增高】
ImageNet的挑战在探索CNNs的各种架构选择方面带来了重大进展。过去几年的总体趋势是,随着参数数量和卷积运算的总体增加,网络变得越来越深。这些高容量网络具有显著的推理成本,特别是当与嵌入式传感器或移动设备一起使用时,计算和电力资源可能是有限的。
对于这些应用,除了精度之外,计算效率和小网络规模也是关键的实现因素(Szegedy等人(2015b))。此外,对于提供图像搜索和图像分类api的web服务(操作时间预算通常为每秒数十万张图像),可以从较低的推断时间中获益良多。
【开始了模型压缩工作】
在通过模型压缩来降低存储和计算成本方面已经做了大量的工作。
最近,Han等人(2015;2016b)在AlexNet (Krizhevsky et al.(2012))和VGGNet (Simonyan & Zisserman(2015))上报告了令人印象深刻的压缩率,方法是在不影响总体精度的情况下对权重进行小幅度修剪,然后再进行训练。
然而,修剪参数不一定减少计算时间,因为大部分的参数删除完全连接层的计算成本低。例如,全连接层参数VGG-16占据总数的90%,但只占比重不到1%的总体浮点运算(FLOP)。它们还证明了卷积层可以被压缩和加速(Iandola等人(2016)),但还需要稀疏的BLAS库甚至专用硬件(Han等人(2016a))。在cnn上使用稀疏操作提供加速的现代库通常是有限的(Szegedy等人(2015a);Liu等人(2015))和维护稀疏的数据结构也会产生额外的存储开销,这对于低精度权重来说是非常重要的。
【卷积的计算成本依然占主导】
最近关于cnn的工作已经产生了具有更有效设计的深层架构 (Szegedy等人(2015a;b);He与Sun(2015);He等(2016)),将全连通层替换为平均池化层(Lin等(2013);He等(2016)),显著减少了参数的数量。通过在早期对图像进行降采样,减小feature map的大小,降低了计算成本(He & Sun(2015))。然而,随着网络的不断深入,卷积层的计算成本继续占据主导地位。
【该论文提出的 “滤波器剪枝”】
大容量的cnn通常在不同的滤波器和特征通道之间具有显著的冗余。在这项工作中,我们关注的是通过剪枝滤波器来降低训练良好的cnn的计算成本。
- 与【网络上的剪枝权重】相比,【滤波器剪枝】是一种自然结构化的剪枝方式,无需引入稀疏性,因此不需要使用稀疏库或任何专门的硬件。
- 【剪枝滤波器的数量】通过减少矩阵乘法的数量,直接与加速相关,这很容易调优目标加速。
- 此外,我们没有采用分层迭代的微调(再训练),而是采用了【一次剪枝和再训练策略】,以节省多层间剪枝过滤器的再训练时间,这对于非常深入的网络剪枝是至关重要的。
最后,我们观察到,即使对于与AlexNet或VGGNet相比具有更少的参数和推理成本的ResNets,在不牺牲太多准确性的情况下,仍然有大约30%的 FLOP减少。我们对 ResNets中的卷积层进行敏感性分析,以提高对 ResNets的理解。
2 RELATED WORK
略
3 剪枝过滤器和特征映射
- 设ni为第 n i n_i ni 个卷积层的输入通道数, h i / w i h_{i}/w_{i} hi/wi 为输入特征映射的高度/宽度。
- 卷积层将输入特征映射 x i ∈ R n i × h i × w i x_i∈R_{n_i×h_i×w_i} xi∈Rni×hi×wi转换成输出特征映射 x i + 1 ∈ R n i + 1 × h i + 1 × w i + 1 x_{i+1}∈R^{n_{i+1}×h_{i+1}×w_{i+1}} xi+1∈Rni+1×hi+1×wi+1,作为下一个卷积层的输入特征映射。
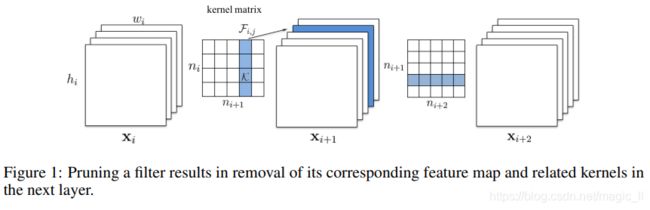
- 这是通过在 n i n_i ni 输入通道上应用 n i + 1 n_{i+1} ni+1 3D滤波器 F i , j ∈ R n i × k × k F_{i,j}∈R^{n_i×k×k} Fi,j∈Rni×k×k 来实现的,其中一个滤波器生成一个feature map。
- 每个滤波器由 n i n_i ni 2D核 K ∈ R k × k K∈R^{k×k} K∈Rk×k (例如,3 × 3)组成。所有滤波器共同构成 F i ∈ R n i × n i + 1 × k × k F_{i}∈R^{n_i×n_{i+1}×k×k} Fi∈Rni×ni+1×k×k 的核矩阵。卷积层的运算次数为 n i + 1 n i k 2 h i + 1 w i + 1 n_{i+1}n_ik^2h_{i+1}w_{i+1} ni+1nik2hi+1wi+1 。
如图1所示,当对滤波器 F i , j F_{i,j} Fi,j 进行修剪时,去除其对应的特征图 x i + 1 , j x_{i+1,j} xi+1,j ,减少了 n i k 2 h i + 1 w i + 1 n_ik^2h_{i+1}w_{i+1} nik2hi+1wi+1 的操作。
应用于从下一个卷积层的过滤器中移除的特征映射的内核也被移除,这节省了额外的 n i + 2 k 2 h i + 2 w i + 2 n_{i+2}k^2h_{i+2}w_{i+2} ni+2k2hi+2wi+2 操作。
对第 i i i 层的 m m m 个过滤器进行剪枝,将使第 i i i 层和第 i + 1 i+1 i+1 层的计算成本减少 m / n i + 1 m/n_{i+1} m/ni+1。
3.1 决定在单个图层中修剪哪个过滤器
我们的方法:从一个训练良好的模型中剔除无用的过滤器,以提高计算效率,同时最小化精度下降。
我们通过计算每个层的绝对权重 ∑ ∣ F i , j ∣ \sum|F_{i,j} | ∑∣Fi,j∣,即其1范数 ∣ ∣ F i , j ∣ ∣ 1 ||F_{i,j} ||_1 ∣∣Fi,j∣∣1,来测量滤波器的相对重要性。由于输入通道的数量 n i n_i ni 在滤波器中是相同的,所以 ∑ ∣ F i , j ∣ \sum|F_{i,j} | ∑∣Fi,j∣ 也表示其卷积核权重的平均大小(/等级)。这个值给出了输出特征图大小(/等级)的期望。与该层的其他过滤器相比,具有较小核权值的过滤器倾向于产生具有弱激活的特征映射。
【滤波器剪枝的特点】
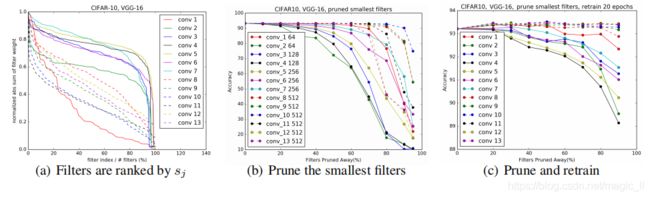
图2(a)展示了在CIFAR-10数据集上训练的VGG-16网络中,每个卷积层的滤波器的绝对权值总和的分布情况,其分布在层间差异很大。我们发现
- 修剪最小的滤波器比修剪相同数量的 随机的或最大的过滤器效果更好(章节4.4)。
- 与其他基于激活的特征映射剪剪标准相比(章节4.5),我们发现 L1-norm是一个很好的无数据滤波器选择标准 。
【滤波器剪枝的操作流程】
从第 i i i 个卷积层剪去 m m m 个滤波器的过程如下:
- 1 对于每个滤波器 F i , j F_{i,j} Fi,j,计算其绝对核权值 s j = ∑ l = 1 n i ∑ ∣ K l ∣ s_j=\sum_{l=1}^{n_i}\sum|K_{l}| sj=∑l=1ni∑∣Kl∣ 的和。
- 2 按 s j s_j sj 对过滤器排序。
- 3 对和值最小的滤波器及其对应的特征映射进行修剪。下一个卷积层对应修剪后的特征映射的核也被删除
- 4 为第 i i i 层和第 i + 1 i + 1 i+1 层创建一个新的核矩阵,并将剩余的核权值复制到新的模型中。
图2
(a) CIFAR-10上VGG-16 用每一层的绝对权重总和对过滤器排序。x轴是过滤器索引除以过滤器的总数。
(b) 在CIFAR-10上,对绝对权值和最小的滤波器进行剪枝,并对其测试精度进行剪枝。
(c) CIFAR-10上对VGG-16的每一层进行修剪再训练。有些图层是敏感的,在修剪后很难恢复精度。
【剪枝权值】
剪枝滤波器的权重的绝对值总和 与 较低的剪枝权重类似(Han等(2015))。当滤波器的所有核权值都低于给定的阈值时,【基于幅度的权重剪枝】可能会剪掉整个滤波器。然而,这需要对阈值进行仔细的调整,并且很难预测最终将被修剪的过滤器的确切数量。此外,它生成稀疏卷积核,由于缺乏有效的稀疏库,很难加速,特别是在低稀疏的情况下。
【群稀疏正则化的滤波器】
最近的研究(Zhou et al. (2016);Wen et al.(2016))在卷积滤波器上( ∑ j = 1 n i ∣ ∣ F i , j ∣ ∣ 2 \sum_{j=1}^{n_i}||F_{i,j}||_2 ∑j=1ni∣∣Fi,j∣∣2 or L 2 , 1 L_{2,1} L2,1-范数),这也有利于 L2范数小的滤波器取零,即 F i , j = 0 F_{i,j} = 0 Fi,j=0。在实践中,我们没有在滤波器选择的“L2范数”和“L1范数”之间观察到明显的差异,因为重要的滤波器对于这两种测量都有较大的值(附录6.1)。在训练期间将多个滤波器的权重归零与使用3.4节中介绍的迭代修剪和再训练策略对滤波器进行修剪具有类似的效果。
3.2 确定单层剪枝的敏感性
为了理解每一层的敏感性,我们独立地对每一层进行修剪,并评估修剪后的网络在验证集上的精度。
- 图2(b)显示,在过滤器被修剪后仍保持其精度的层对应于图2(a)中斜率较大的层。相反,坡面相对平坦的层对修剪更为敏感。我们根据每一层的过滤器对剪枝的敏感性,经验地确定要剪枝的过滤器数量。
- 对于深度网络,如VGG-16或ResNets,我们观察到在同一阶段(具有相同feature map size)的层具有类似的剪枝敏感性。为了避免引入分层元参数,我们在同一阶段对所有层使用相同的剪枝比例。对于那些对修剪很敏感的层,我们修剪较小比例的这些层或完全跳过修剪它们。
3.3 多层修剪滤波器器
【多层修剪滤波器】
我们现在讨论如何在网络上修剪过滤器。之前的工作在一层一层的基础上删减权重,然后迭代地再训练并补偿任何精度损失(Han等人(2015))。然而,理解如何一次修剪多层滤波器是有用:
- 1)对于深网络,一层层的修剪、再训练是非常耗时
- 2)在小网络上,层上的剪枝在网络结果稳定性方面给出了整体的view
- 3)对于复杂网络,全面的方法可能是必要的。例如,对于ResNet,对标识特征映射或每个剩余块的第二层进行修剪,会导致对其他层进行额外的修剪
【多层修剪滤波器 策略】
为了【多层修剪滤波器】,我们考虑两种分层滤波器选择策略:
- 独立剪枝 决定了滤波器应该在每一层独立其他层剪枝
- 根据前一层删减的滤波器进行贪婪修剪。此策略在计算权重绝对值和时,不会考虑之前修剪的特征图。
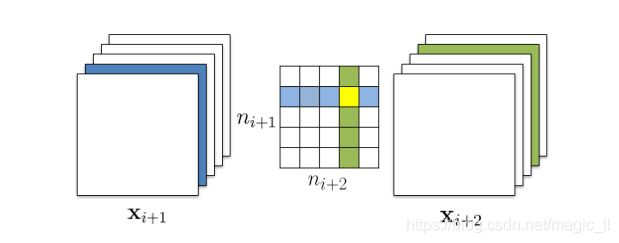
图3说明了计算绝对权重总和的两种方法之间的区别。贪婪算法虽然不是全局最优,但它具有全局的优点,尤其是在多个滤波器都被修剪的情况下,能够得到更高的精度。
贪婪算法虽然不是全局最优,但具有整体性,特别是在多个滤波器都被修剪的情况下,能够得到更高的修剪精度。
图3:连续层的滤波器修剪。
【独立剪枝策略】计算滤波器的和(绿色列),不考虑上一层移除的特征映射(蓝色列),因此黄色列的核权值仍然包括在内。
【贪婪剪枝策略】不计算已经剪枝的特征映射的核的数值。
这两种方法都得到 ( n i + 1 − 1 ) × ( n i + 2 − 1 ) (n_{i+1} -1) × (n_{i+2}-1) (ni+1−1)×(ni+2−1) 核矩阵。
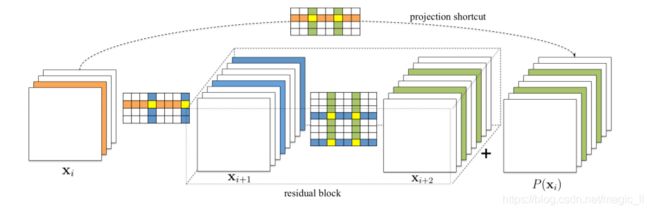
图4:使用投影shortcut来裁剪残差模块。
残差模块的第二层(绿色标记)需要修剪的过滤器由投影shortcut的修剪结果决定。
残差模块的第一层可以不受限制地进行修剪。
【残差模块的剪枝】
对于像VGGNet或AlexNet这样简单的cnn,我们可以很容易地在任何卷积层中删除任何过滤器。
然而,对于复杂的网络结构,如残差网络,剪枝滤波器可能不是简单的。ResNet的体系结构施加了限制,过滤器需要仔细修剪。我们在图4中展示了用投影映射对剩余块进行滤波器修剪。
- 残差块的第一层过滤器可以被任意修剪,因为它不改变块输出的特征映射的数量。
- 但由于第二层卷积层的输出 feature maps 与 identity feature maps 之间的对应关系,使得对其进行修剪较为困难。因此,为了对残差块的第二层卷积层进行修剪,也必须对相应的 identity feature maps 进行修剪。由于 identity feature maps 比添加的残差图更重要,所以需要剪枝的特征图应由shortcut的剪枝结果来决定。为了确定哪些 identity feature maps 要被修剪,我们使用相同的选择准则,基于shortcut卷积层的滤波器(1 × 1核)。残差模块的第二层用与shortcut修剪所选择的滤波器索引相同的滤波器索引进行修剪。
3.4 再训练修剪后的网络以恢复准确性
【操作方法】
在修剪滤波器之后,性能下降应该通过重新训练网络来补偿。有两种策略可以在多个图层上修剪过滤器:
- 1 【一次剪枝和再训练】一次多层过滤器的剪枝和再训练他们,直到原来的准确性恢复。
- 2 【迭代地修剪和再培训】逐层对滤波器进行剪枝,然后迭代地再训练。在对下一层进行修剪之前,对模型进行再训练,以获取权重,以适应修剪过程中的变化。
【实验发现】
- 对于那些能够适应修剪的层(不敏感层),可以使用修剪和再训练一次策略来修剪掉网络的重要部分,任何准确性的损失都可以通过短时间(少于最初的训练时间)再训练来恢复。
- 然而,当来自敏感层的一些滤波器被删除或大部分网络被删除时,可能不可能恢复原始的准确性。迭代修剪和再训练可能会产生更好的结果,但迭代过程需要更多的时间,特别是对于深度非常深的网络。
4 EXPERIMENTS
- 我们修剪了两种类型的网络:简单的cnn (CIFAR-10上的VGG-16)和残差网络(CIFAR-10上的ResNet-56/110和ImageNet上的ResNet-34)。
与经常用于演示模型压缩的AlexNet或VGG (ImageNet上)不同,VGG (cifar -10上)和残差网络在完全连接的层中参数都更少。因此,从这些网络中删除大量的参数是具有挑战性的。我们在Torch7中实现了滤波器剪枝方法(Collobert等人(2011))。- 当过滤器被修剪时,一个新的模型将创建较少的滤波器,修改层的剩余参数以及未受影响的层将被复制到新的模型中。
- 此外,如果对卷积层进行修剪,则后续批处理归一化层的权值也被删除。
为了获得每个网络的基本精度,我们从零开始训练每个模型,并遵循与ResNet相同的预处理和超参数。对于再训练,我们使用一个恒定的学习率0.001,并为CIFAR-10再训练40个epoch,为ImageNet再训练20个epoch,这代表了原始训练epoch的四分之一。过去的研究报告了多3倍的原始训练时间,来重新训练修剪后的网络(Han等人(2015))。
总体的结果。在再训练过程中最好的测试/验证准确性被报告。从零开始训练剪枝模型的效果不如再训练剪枝模型,这可能表明在小容量下训练网络是困难的。

4.1 VGG-16 ON CIFAR-10
【VGG-16 在ImageNet上】
VGG-16是最初为 ImageNet 数据集设计的大容量网络。最近,Zagoruyko(2015)在CIFAR-10上应用了略微修改的模型版本,并取得了最先进的结果。
【VGG-16 在CIFAR-10上】
如表2所示,CIFAR-10上的vgg-16由13个卷积层和2个全连通层组成,其中全连通层由于输入量小、隐藏单元少,并不占大部分参数。
我们使用Zagoruyko(2015)中描述的模型,但在每个卷积层和第一个线性层之后添加 批处理归一化层,没有使用Dropout。注意,当最后一个卷积层被修剪时,对线性层的输入被改变,连接也被删除。
【实验发现】
- 如图2(b)所示,每一个包含512个特征图的卷积层,都可以去掉至少60%的滤波器而不影响精度。
图2(c)显示,通过再训练,这些层的几乎90%的滤波器可以被安全地移除。
- 一种可能的解释是,这些滤波器作用于4×4 或 2×2 feature maps,这些图在如此小的维度中可能没有任何有意义的空间连接。例如,CIFAR-10的resnet不会对低于8 × 8维的特征图执行任何卷积。
- 不像以前的作品(Zeiler & Fergus (2014));Han et al.(2015)),我们观察到第一层比接下来的几层对剪枝更加稳健。
- 这有可能是 对于简单的数据集比如CIFAR-10,模型的滤波器不像ImageNet滤波器学到尽可能多的有用参数(如图5)。即使80%的滤波器是从第一层是修剪,剩下的滤波器(12)的数量仍超过原始输入通道的数量。但是,当去掉第二层80%的滤波器时,这一层对应的是一个64到12的映射,这可能会丢失前一层的重要信息,从而影响精度。50%的滤波器在第1层被修剪,从第8层修剪到第13层,我们在相同的精度下实现了34%的FLOP的减少

4.2 RESNET-56/110 ON CIFAR-10
CIFAR-10的ResNets有三个阶段的剩余块大小为 32×32、16×16和 8×8 的特征地图。每个阶段的残差模块数相同。当特征图的数量增加时,shortcut 层提供了一个带有额外零填充的 identity mapping 来增加的维度。由于没有投影映射来选择 identity feature maps,所以我们只考虑对残差块的第一层进行修剪。 如图6所示,大多数层对于修剪都是健壮的。对于ResNet-110,在不进行再训练的情况下删除一些单一的层,甚至可以提高性能。
- 此外,我们发现对剪枝敏感的层(38和ResNet-56 54层20日,36层,38 resnet - 110年和74年),位于残差模块的feature maps数量发生变化的层。例如,每个残差模块的第一层和最后一层。我们认为这是因为精确的残差对于新添加的空特征映射是必需的。
训练的性能可以通过跳过这些敏感的层次来提高。如表1所示,resnet-56-pruna 通过修剪10%的滤波器,跳过敏感层16、20、38和54,提高了性能。- 此外,我们发现较深的层次比网络earlier stages的层次对剪枝更为敏感。
【实验发现】
因此,我们对每个阶段使用不同的修剪率。我们用 p i pi pi 表示第 i i i 阶段各层的剪枝率。
- ResNet-56-pruned-B 在 p 1 = 60 % p1=60\% p1=60%、 p 2 = 30 % p2=30\% p2=30%、 p 3 = 10 % p3=10\% p3=10% 的情况下,跳过更多的修剪层(16、18、20、34、38、54)和修剪层。
- 对于ResNet-110,第一个修剪后的模型在 p 1 = 50 p1=50% p1=50,跳过36层时得到了更好的结果。
- ResNet-110-pruned-B 跳过36、38、74和prune, p 1 = 50 p1=50% p1=50, p 2 = 40 p2=40% p2=40, p 3 = 30 p3=30% p3=30。当每个阶段的残差模块超过两个时,中间的残差可能是多余的,可以很容易地进行修剪。这也许可以解释为什么ResNet-110比ResNet-56更容易修剪。

4.3 RESNET-34 ON ILSVRC2012
略…
略个头,到这里其实已经翻译不动了,想着能跳过一节是一节,但强迫症吧应该,还是给继续翻译了。
ImageNet的ResNets有四个阶段的残差块,大小分别为56 × 56、28 × 28、14 × 14和7 × 7。当 feature maps 被下采样时,ResNet-34使用 shortcut 方式。
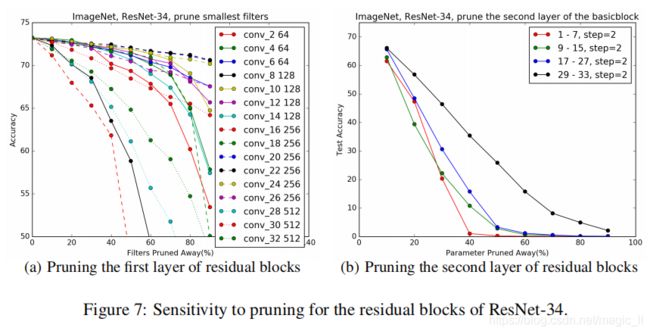
- 首先对每个残差块的第一层进行剪枝。图7为各残差块第一层的灵敏度。与ResNet-56/110类似,每一阶段的第一个和最后一个残余块比中间块(即层2、8、14、16、26、28、30、32)对剪枝更敏感。
- 我们跳过这些层,并在每个阶段同等地修剪剩余的层。
在表1中,我们比较了前三个阶段的两种剪枝比例配置:
- (A) p1=30%, p2=30%, p3=30%;
- (B) p1=50%, p2=60%, p3=40%。选项b提供了24%的FLOP减少,约1%的准确性损失。从resnet / 50/110的修剪结果中可以看出,我们可以预测ResNet-34相对于更深层次的resnet来说更难于修剪。
我们还修剪了 identity shortcuts 和残差块的第二个卷积层。由于这些层具有相同数量的滤波器,它们被同等地修剪。
- 如图7(b)所示,这些层比第一层对修剪更加敏感。通过再训练,resnet-34-prune-c对 p 3 = 20 % p3=20\% p3=20% 的第三阶段进行了修剪,结果FLOP减少7.5%,准确率损失0.75%。
因此,修剪残差模块的第一层比修剪第二层更能有效地减少整体FLOP。这一发现也与更深层次resnet的瓶颈模块设计有关,该设计首先降低残差层的输入特征映射的维数,然后增加维数以匹配身份映射。
4.4 与剪枝随机过滤器/最大过滤器的比较
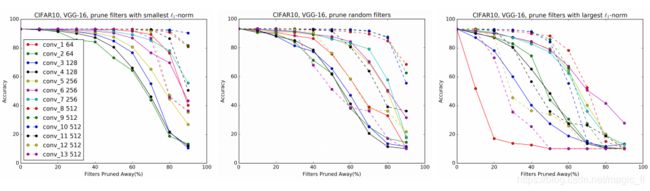
我们比较了我们的方法与【随机滤波器剪枝】和【最大滤波器剪枝】。如图8所示,对于大多数层来说,在不同的修剪比率下,最小的滤波器剪枝的效果 要优于随机滤波器剪枝。例如,最小滤波器剪枝比随机滤波器剪枝对所有层次的剪枝精度更高,当剪枝率达到90%。
随着剪枝比的增加,具有最大L1范数的剪枝滤波器的精度迅速下降,这表明了较大1-范数的剪枝滤波器的重要性。
图8:CIFAR-10上VGG-16的三种剪枝方法的比较:
最小的滤波器剪枝 smallest L1-norms、随机滤波器剪枝random filters、最大的滤波器剪枝 largest L1-norms。在随机滤波器修剪中,被修剪的滤波器顺序是随机排列的。
4.5 与基于激活的特征图剪枝的比较
【特征图剪枝的介绍】
【基于激活的特征图剪枝】方法去除了具有弱激活模式的特征图及其对应的filter和kernel (Polyak & Wolf(2015)),该方法需要样本数据作为输入来确定哪些feature map需要进行修剪。
- 对前一层 feature map x i ∈ R n i × w i × h i x_{i}∈R^{n_i×w_i×h_i} xi∈Rni×wi×hi ,应用滤波器 F i , j ∈ R n i × k × k F_{i,j}∈R^{n_i×k×k} Fi,j∈Rni×k×k ,生成 feature map x i + 1 , j ∈ R w i + 1 × h i + 1 x_{i+1,j}∈R^{w_{i+1}×h_{i+1}} xi+1,j∈Rwi+1×hi+1,即 x i + 1 , j = F i , j ∗ x i x_{i+1,j} = F_{i,j}∗x_i xi+1,j=Fi,j∗xi。
- 给定从训练集中随机选取的N幅图像 { x 1 n } n = 1 N \{x_1^n\}_{n=1}^N {x1n}n=1N,对N个采样数据进行一次epoch的前向传递,即可估计出每个特征图的统计量。注意,在批处理归一化或非线性激活之前,我们对卷积操作生成的特征映射进行统计计算。
【特征图剪枝的规则】
我们比较【基于 L1范数滤波器修剪】和【使用特征图的修剪】。后者使用的规则:
- σ m e a n − m e a n ( x i , j ) = 1 N ∑ n = 1 N m e a n ( x i , j n ) σ_{mean-mean}(x_{i,j})=\frac{1}{N}\sum_{n=1}^{N}mean(x_{i,j}^{n}) σmean−mean(xi,j)=N1∑n=1Nmean(xi,jn)
- σ m e a n − s t d ( x i , j ) = 1 N ∑ n = 1 N s t d ( x i , j n ) σ_{mean-std}(x_{i,j})=\frac{1}{N}\sum_{n=1}^{N}std(x_{i,j}^{n}) σmean−std(xi,j)=N1∑n=1Nstd(xi,jn)
- σ m e a n − l 1 ( x i , j ) = 1 N ∑ n = 1 N ∣ ∣ x i , j n ∣ ∣ 1 σ_{mean-l_1}(x_{i,j})=\frac{1}{N}\sum_{n=1}^{N}||x_{i,j}^n||_1 σmean−l1(xi,j)=N1∑n=1N∣∣xi,jn∣∣1
- σ m e a n − l 2 ( x i , j ) = 1 N ∑ n = 1 N ∣ ∣ x i , j n ∣ ∣ 2 σ_{mean-l_2}(x_{i,j})=\frac{1}{N}\sum_{n=1}^{N}||x_{i,j}^n||_2 σmean−l2(xi,j)=N1∑n=1N∣∣xi,jn∣∣2
- σ v a r − l 2 ( x i , j ) = v a r ( { ∣ ∣ x i , j n ∣ ∣ 2 } n = 1 N ) σ_{var-l_2}(x_{i,j})=var(\{||x_{i,j}^n||_2\}_{n=1}^N) σvar−l2(xi,j)=var({∣∣xi,jn∣∣2}n=1N)
其中,
【mean、std、var】是输入的标准统计结果
【 σ v a r − l 2 σ_{var-l_2} σvar−l2】是 通道准则的贡献方差(the contribution variance of channel criterion),指的是一个不重要的特征图,在整个训练数据中有着相似的输出,像一个额外的偏差。
【特征图剪枝的结果】
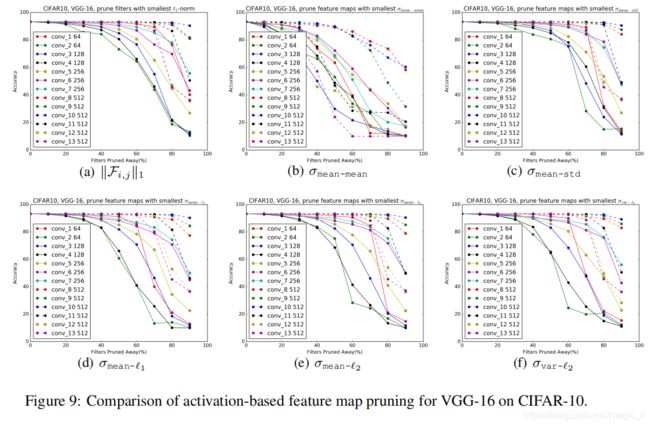
当使用更多的样本数据时,准则的估计会更加准确。这里我们使用整个训练集(CIFAR-10的N = 50,000)来计算统计数据。图9显示了采用上述标准对每一层进行特征映射剪枝的性能。
- 最小滤波器的剪枝优于以 σ m e a n − m e a n σ_{mean-mean} σmean−mean, σ m e a n − l 1 σ_{mean- l_1} σmean−l1, σ m e a n − l 2 σ_{mean-l_2} σmean−l2 和 σ v a r − l 2 σ_{var- l_2} σvar−l2 为标准的特征映射剪枝。
- 当剪枝率达到60%时, σ m e a n − s t d σ_{mean-std} σmean−std的性能优于或近似于 L1-norm。 然而,它的性能在此之后迅速下降,特别是对于conv 1, conv 2和conv 3层。我们发现L1范数是一个很好的滤波器选择,由于它不依赖数据。