python爬取动态加载页面,selenium实现滚动到底
最近的写爬虫的时候遇到一些问题,就是页面是动态加载的,抓包的时候发现页码不规律,于是想到用selenium控制浏览器自动拖拽滚动到底,找了好多方法直接是加载js的不太好用,看到一个博主的能用方法,我把他贴一下。
selenium实现无限滚动、循环滚动到底
这是我自己更新的代码,我发现一个小问题,尽管拖拽了页面到底部不再加载了,但是我请求返回的数据还是最初没有(点击加载)的页面的数据,获取不到动态加载后的数据,之前我遇到过解决方法,现在忘记了
import time
import lxml.html
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url='https://www.nanjixiong.com/forum-228-1.html')
# 页面最大
driver.maximize_window()
# 定义一个初始值
temp_height = 0
while True:
# 循环将滚动条下拉
driver.execute_script("window.scrollBy(0,1000)")
# sleep一下让滚动条反应一下
time.sleep(0.05)
# 获取当前滚动条距离顶部的距离
check_height = driver.execute_script(
"return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")
# 如果两者相等说明到底了
if check_height == temp_height:
driver.refresh()
# 在这里获取网页源代码
html_data = driver.page_source
time.sleep(1)
# print(html_data)
break
temp_height = check_height
print(check_height)
driver.quit()
metree = lxml.html.etree
# 获取数据对象
parser = metree.HTML(html_data, metree.HTMLParser())
# 解析数据
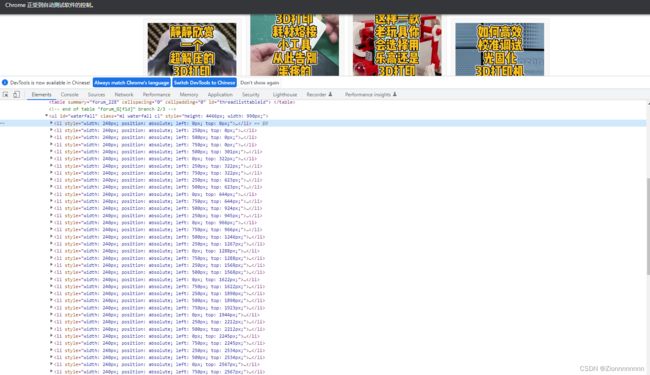
element_list = parser.xpath('//ul[@class="ml waterfall cl"]/li')
print(len(element_list))
看li标签新加载的元素已经不止18个了
先留着,后续有解决方法了再更新本文