使用Disentangling形式的损失函数回归2D和3D目标框
本文介绍一篇 ICCV 2019 的论文『 Disentangling Monocular 3D Object Detection』。详细信息如下:

论文链接:https://arxiv.org/abs/1905.12365
项目链接:https://research.mapillary.com/publication/MonoDIS/
01
动机
相比于较为成熟的2D目标检测技术,3D目标检测尚处于发展之中。而在3D目标检测领域,基于单目相机的方法又远远落后于基于多传感器融合的方法。使用单目相机做3D目标检测是个“ill-posed”问题,因为三维场景到二维图像的映射过程引入了模糊性。
当前使用神经网络解决单目相机3D检测问题大多存在两个特性:1.需要对3D目标框的长、宽、高、深度、角度、位置进行编码,这些属性的单位、范围不统一,若直接使用它们构造损失函数,一定程度上会影响网络的收敛过程;2.首先训练2D目标检测器,然后将3D目标检测模块集成进来,这种分阶段训练的方式并不是最优的。
基于上述问题,作者将3D目标框的属性参数在损失函数层面上分组,解耦它们之间的依赖关系,解决了这些属性在单位、范围上的不一致问题,减轻了网络收敛难度,使得2D目标检测网络和3D目标检测网络能够一起训练,达到端到端训练的目的。
针对2D目标检测任务,作者还引入了一种基于sIOU(signed Interp-over-Union)的损失函数提高性能;针对3D目标检测任务,作者引入了一个损失项用于得到3D目标框的检测置信度。
02
网络结构
基于单目相机的3D检测任务,即输入单张RGB图片,输出目标在相机坐标系下的3D框属性,如下图所示:

作者提出的MonoDIS网络可以分为Backbone、2D检测器和3D检测器3部分,下面分别介绍。
2.1 Backbone
Backbone的结构如下图所示:
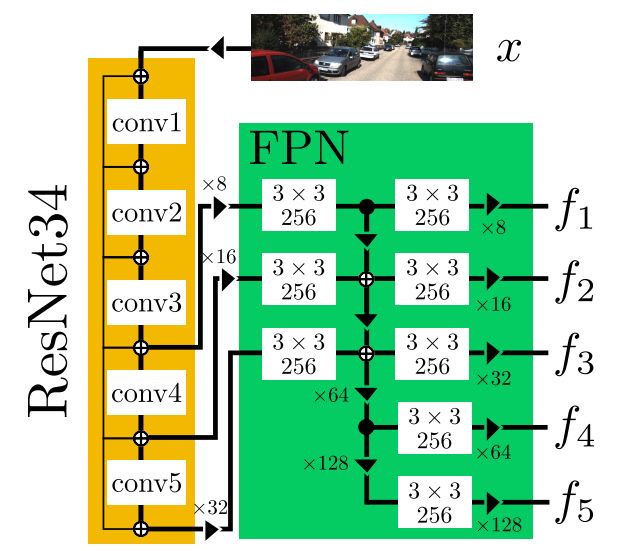
由上图可以看出,Backbone由ResNet34和FPN(Feature Pyramid Network)组成。在ResNet34中,使用InPlaceABN( iABNsync)+LeakyReLU替代BatchNorm+ReLU结构,其中LeakyReLU的negative slope为0.01。
这么做的目的是在不影响网络性能的前提下降低GPU显存的消耗,从而可以尝试较大的batch size或者较大的输入图片分辨率。Backbone的输入为RGB图像,输出为5种尺度的特征,分别记作 {f1,…,f5}。
2.2 2D目标检测
与RetinaNet中的检测部分类似,在Backbone输出的每个 后面接一个2D检测模块,2D检测模块的结构如下图所示:
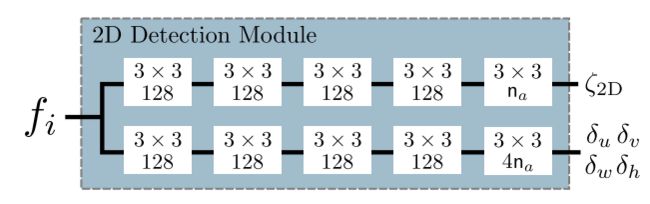
对于每个anchor输出5个信息,记作 ,使用这些信息构造预测框的属性:
表示2D预测框的置信度,记作 ;
表示预测框的中心点坐标,记作 , 表示这个anchor对应的cell在图像坐标系下的坐标, 表示这个anchor的预定义尺寸;
表示预测框的尺寸,记作 。
取网络输出的置信度高于0.05且置信度排名前5000的预测框,进行IoU阈值为0.5的NMS操作,最后选取置信度最高的100个预测框作为2D检测结果。
2.2.1损失函数
Focal Loss
使用focal loss损失函数训练分类分支,对于grid中给定cell的某个anchor,定义目标置信度为 ,预测到的置信度为 ,损失函数表示如下:
上式中的 和 是超参数,且 , 。
目标置信度 取决于anchor和ground-truth,若anchor和gound-truth对应框的IoU超过给定阈值 ,则令目标置信度 。
Detection Loss
若存在两个框 和 ,将sIoU定义为:
令表示框的四个元素中前两个元素为第一个坐标,后两个元素为第二个坐标。当第一个坐标在第二个坐标的左上角时, 的值为框的面积;否则 的值为框的面积的相反数。
举例如下:
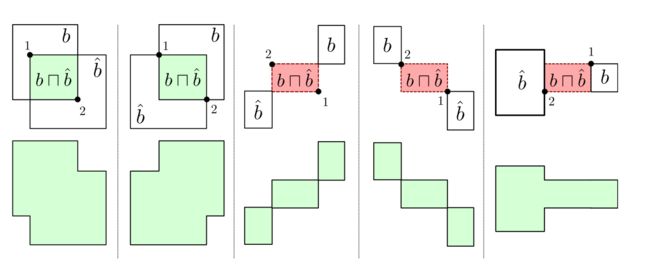
上图中第一行带颜色的部分为sIoU公式中的分子部分,绿色代表正值,红色代表负值;第二行代表sIoU公式中的分母部分。
对于gound-truth框 和预测框 ,定义检测损失函数为:
2.3 3D目标检测
对于网络最终输出的每个2D框,都要预测一个与之对应的3D框。对于每个2D框,使用ROIAlign从FPN中抽取特征,特征尺寸为14x14。FPN中共有5个尺度的特征 ,尺寸为 的2D预测框使用FPN中的 , 的选取策略如下:
3D目标检测模块的结构如下图所示:

上图中FC代表全连接层,除了最右侧的2个FC层外,其余FC层后面均带有iABN操作。3D目标检测模块的输入为backbone输出的 以及2D目标检测模块输出的2D预测框 ,3D目标检测模块的输出为 和,使用这些信息构造3D预测框的属性:
表示给定2D预测框的条件下3D预测框的置信度;
表示3D预测框中心点的深度,其中 和 是预定义值;
表示3D预测框中心点在图像平面上的坐标;
表示3D预测框的尺寸,即宽、高、长,其中 是预定义值;
表示allocentric的四元数,表示3D预测框的姿态信息。
根据 和 可以得到3D目标框的置信度:
置信度大于阈值 即认为存在3D目标,对于3D检测,作者并没有使用NMS。
2.3.1损失函数
3D目标框回归损失
若相机内参已知,根据上文提到的 、 、 、 可以得到3D预测框的8个顶点。
设相机内参为
根据透视变换的原理,可以根据网络输出的3D目标框中心点的深度 、3D目标框中心点在图像平面上的投影 ,得到3D目标框中心点在相机坐标系中的位置
再根据四元数 、3D目标框的宽高长 ,可以得到3D目标框的8个顶点在相机坐标系中坐标:
上式中矩阵 是由 组成的对角矩阵,
,
是对应于 的旋转矩阵。
综上所述,根据3D目标检测模块输出的,可以求得3D目标框的8个顶点,记作 。
令 表示相机坐标系下3D目标的ground truth。构造3D目标框回归损失函数
上式中 表示参数为 的Huber损失。
3D目标框置信度损失函数
令,其中 为温度系数,使用交叉熵损失构造3D目标框的置信度损失函数(式中省略了下标)
03
Disentangling形式的Loss
3.1 Disentangling的原理
将Disentangling Loss应用于2D目标框和3D目标框的回归损失中,目的是将多组参数对于损失函数的贡献隔离开,同时保留这些参数的原始含义,利于网络训练时的优化过程。在2D目标框的回归损失中,包含用于确定目标框的2组参数,一组用于确定目标框的长和宽;
另外一组用于确定目标框的中心点位置。在3D目标框的回归损失中,包含用于确定目标框的4组参数,它们分别是与深度有关的参数、与3D目标框中心在图像平面投影有关的参数、与旋转角度有关的参数和与目标长宽高有关的参数。
令 表示第 组参数, 表示除第 组以外的其他参数。若使用 表示从网络输出的参数到目标框的映射过程:即对于2D目标检测, 表示从网络输出的 到目标框的映射过程;对于3D目标检测, 表示从网络输出的到目标框的映射过程。
令 表示网络输出的用于估计目标框的参数,令 表示根据ground truth利用 的反过程求出的参数,即 ,则可以构造如下损失函数:
上式中的 表示ground truth, 表示利用网络输出的第 组参数 和根据ground truth推出的除第 组以外的参数 得到的目标框。上式仅仅是针对网络输出的第 组参数构造的损失函数。对网络输出的共 组参数构造损失函数,表示如下:
在2D目标检测中k=2;在3D目标检测中k=4。
简而言之,在构造每个损失函数时,只使用一部分网络输出的参数,其余的参数从ground truth中利用 得到。在实验过程中,作者在构造2D目标回归和3D目标回归的损失函数时均用到了Disentangling Loss。
3.2 Disentangling Loss的优势
为了形象地展示出Disentangling Loss的优势,作者做了一个实验。作者分别使用原始的 以及 的Disentangling Loss形式,训练网络完成KITTI3D数据集中的3D目标检测任务。
训练时的学习率为0.001,momentum为0.9,迭代了3000次,结果如下图所示:

为便于进一步观察使用Disentangling Loss与否在训练过程中的差异,作者画出来4组参数以及 的迭代过程,如下图所示:

上图从左到右依次代表长宽高、表示方向的四元数、3D目标框中心在图像平面上的投影、3D目标框中心的深度、 在2种损失函数形式下的迭代过程。
图中粉红色代表使用了原始的 ,蓝色代表使用了 的Disentangling Loss形式。从图中可以看出,使用了Disentangling Loss形式的损失函数训练模型迭代更快。
04
实验
4.1 实验设置
在进行2D目标检测时,共使用了由5种长宽比 、3种尺寸 组合而成15种anchor,其中 是FPN中不同尺度特征的下采样率。若某个anchor与ground truth的IoU大于阈值 ,则认为这是一个positive anchor。
在进行3D目标检测时,预定义如下先验: 、 、 、 、 。在测试阶段置信度阈值为 。
对于2D检测的损失函数权重设置为1,对于3D检测的损失函数权重设置为0.5。在3D检测的目标框回归损失函数中,设置 ,在3D检测的置信度损失函数中,设置 。
在训练时使用了水平翻转作为数据增强的唯一方法。使用学习率为0.01的SGD优化方法在4个NVIDIA V-100 GPU上进行训练,batch size设置为96,共迭代了20k次,在第12k次迭代和第16k次迭代时将学习率降低为原来的0.1倍。
4.2 在KITTI3D数据集上测试
实验结果如下表所示:
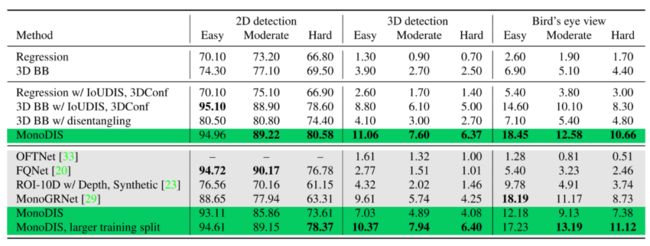
上表中第一行和第二行对比了在训练3D目标检测网络时,直接回归和回归由 解算出的3D bounding box的性能,显然在训练时回归3D bounding box能提高网络性能。
第三、四行表示使用了Signed IoU、使用Disentangling Loss形式的2D检测损失和3D检测的置信度,对比第三、四行和第一、二行,使用上述方法能提高网络的性能。使用本文提到的所有技巧训练,测试结果为上表中第五行MonoDIS的结果。上表中的阴影部分为在KITTI3D测试集上的结果。
05
总结
对于2D目标检测,提出了使用Signed IoU的方法构造目标框回归损失函数;对于3D目标检测,使用了在2D检测结果上的条件概率构造损失函数。
提出了Disentangling Loss,将其应用于2D目标检测和3D目标检测的目标框回归损失函数中,简化训练过程,提高网络收敛速度和网络性能。
基于上述方法构建网络,同时进行2D目标检测和3D目标检测,通过实验证明这些方法的有效性。

备注:目标检测

目标检测交流群
2D、3D目标检测等最新资讯,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 