【论文解读】VDN( Variational Denoising Network )变分去噪网络
之前一直对各种机器学习算法的推导比较感兴趣,又希望了解一些机器学习和深度学习模型相结合的处理方法,最近看到的这篇文章就是一个比较好的例子。文章名为 Variational Denoising Network: Toward Blind Noise Modeling and Removal 可从arXiv:1908.11314 获取。
一、背景知识介绍
文章目的是图像盲去噪,首先进行了领域相关工作的总结,认为主要存在两种主流解决思路,一种是大多数传统方法所基于的概率模型的方法、一种是数据驱动的深度学习模型。前者优势在于可解释性强,但劣势在于,对噪声生成方式的预先假设可能导致模型效果受限,并且算法需要对新图像进行调整,导致应用不方便。后者优势在于利用了大量 噪声图-干净图 的数据中的信息,并且测试图像处理速度快,但可能存在过拟合训练集,导致没有很好的处理测试图像中其他类型噪声的能力。
文章陈述的主要贡献:
- 该模型能同时对图像去噪并进行噪声估计,一般的工作中会假设图像中存在高斯白噪声,但本文模型不局限于此。(但有必要提到的是,文章说前者处理的属于 i.i.d. 的噪声,而本文的模型则可以处理 non-i.i.d. 这一点有待考究,因为“非高斯白噪声”并不等价于“non i.i.d.”。甚至从图片数据空间来说,对所有图像使用同样的模型来处理,相当于依然是认为各个图像的噪声是独立同分布的)
- 所提出的生成模型具有良好的泛化能力,对测试集未出现的噪声,也能表现比较好的性能。
- 去噪的同时能估计噪声分布,具有更全面的解释性。
- 这个模型能够对利用MSEloss进行训练的深度学习方法中出现的过拟合现象做出解释,出现的问题归因于过拟合了潜在干净图像的先验,而忽视了噪声的变化,本文的模型显式地对噪声的产生建模,避免了深度学习方法的这个弊端。
二、模型结构
首先说明数据表示方式, D D D 表示训练数据,形式为 D = { y j , x j } j = 1 n D=\{y_j,x_j\}_{j=1}^{n} D={yj,xj}j=1n 其中 y j y_j yj 和 x j x_j xj 表示第 j 个训练数据对,n 代表训练数据的数量。y表示噪声图,x表示相同条件下多次采集取平均得到的”近似”的干净图,这里需要注意,真实的无噪声图无法获取,数据集的干净图实际上是取平均后的近似干净图。这就是为什么不能直接将x作为label的原因,本文将x作为潜在干净图的先验。
1. 由训练数据建模
令 y = [ y 1 , . . . , y d ] T y=[y_1, ..., y_d]^T y=[y1,...,yd]T 和 x = [ x 1 , . . . , x d ] T x=[x_1, ..., x_d]^T x=[x1,...,xd]T 表示图像对的一维展开, d = w i d t h ∗ h e i g h t d=width*height d=width∗height 用z表示潜在的干净图,将噪声的产生表示成
y i ∼ N ( z i , σ i 2 ) , i = 1 , 2 , . . . , d y_i \sim N(z_i, \sigma_i^2), i=1,2,...,d yi∼N(zi,σi2),i=1,2,...,d
这里可以看出,并没有对噪声的整体分布进行限制,而是单独可以单独考虑每个像素点。然后基于训练数据给出该高斯分布两个参数的先验:
z i ∼ N ( x i , ϵ 0 2 ) z_i \sim N(x_i, \epsilon_0^2) zi∼N(xi,ϵ02)
σ i 2 ∼ I G ( p 2 2 − 1 , p 2 ξ i 2 ) \sigma_i^2 \sim IG(\frac{p^2}{2}-1,\frac{p^2\xi_i}{2}) σi2∼IG(2p2−1,2p2ξi)
其中 ϵ 0 \epsilon_0 ϵ0 设置为一个较小的值,IG表示 inverse Gamma分布,其中 ξ = G ( ( y ^ − x ^ ) 2 ; p ) \xi = G((\hat y-\hat x)^2;p) ξ=G((y^−x^)2;p) 表示对残差平方图像用大小为p*p的高斯核进行卷积之后的结果。这里的x和y是形状为width * height的矩阵而不是一维展开。
关于IG分布确实有一些麻烦,但对整体结构的理解不会有太大影响,但是这里IG分布的构造确实有精巧之处,可以计算出,在这种参数设置下,逆伽马分布的均值就是 ξ i \xi_i ξi 也就是直接用噪声图和“近似的”干净图之差作为其分布的均值,并且p越大,卷积核越大,分布的方差就越小。从逆gama分布的图像也可以看出来,它的分布形状相当于高斯分布砍掉左侧的尾巴,这保证了方差恒正,更符合实际情况。
2. 变分后验的formulation
上面介绍了先验的情况,下面用变分的形式给出后验,我们的目标就是根据噪声图得到潜在的干净图,实际上就是求潜在干净图的后验。这个后验是用卷积网络来表示的:

数学的表示形式为

其中 W D W_D WD 表示上面的去噪网络的参数, W S W_S WS 表示下面的噪声参数估计网络的参数。
网络的结构比较容易理解,总之是直接将噪声图作为输入,两个网络分别输出同样大小的两个输出,一个表示潜在干净图的均值和方差,另一个表示噪声的两个参数,都是对每个像素点单独而言的。利用模型输出计算loss,其中涉及到的三项loss下面介绍。
3. loss构建
这一部分的推导与EM算法的推导如出一辙,只有几个细微的地方有差别。我们训练网络要使用损失函数,EM算法实际上是最大化log边缘likelihood,在这里,也就是 l o g p ( y ∣ z , σ 2 ) log p(y|z,\sigma^2) logp(y∣z,σ2) 然后将其表示为:

其中的第二项是变分后验和真实后验的KL散度,真实的后验无法获得,只能通过一次次迭代逼近,第一项就是lower bound
具体推导在supp,也贴到这里:

然后继续处理lower bound得到:
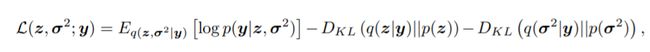
需要注意的是,与一般的EM算法推导不同的是,这里隐变量有两个,分别是 z 和 σ \sigma σ ,这两个是相互独立的,所以可以拆开写到两项中。
进而对lower bound的三项分别进行计算,过程较为繁琐,尤其是涉及到逆伽马分布的期望,确实不易计算,supp给出了如下过程,利用结果即可:

(注:其中的 Ψ \Psi Ψ 函数代表digamma函数)
利用上面计算公式,即可利用网络的输出来算出log似然函数的下界,进而
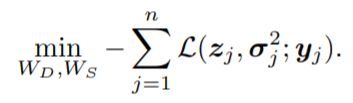
利用优化算法训练网络即可。
三、讨论
- 模型参数在整个训练集上训练,所以期望它能够学习到不同的噪声分布情况下的情形,所以能够处理不同噪声分布下的去噪问题。
- 当模型将 ϵ 0 \epsilon_0 ϵ0 设置为非常接近0的值,则整体的loss被lower bound的第一项所主导,退化成了MSE loss。从这里,作者认为利用近似的干净图训练深度模型会导致过分拟合潜在真是图的先验,没有很好的考虑到噪声的变化。
- 生成式MAP使得模型具有很强的可解释性和可泛化性。
四、实验
本文的实验为了表现VDN的效果,利用了特殊的噪声生成方式:

对于训练图像,就使用简单的高斯随机噪声(a),对于测试图像,使用了多种形式的噪声 (b2)-(d2) ,目的是测试模型对不同于训练数据的噪声的效果。图中不同分布的噪声表示,对应各个像素点,取对应位置的噪声,使得整个图的噪声具有图中所示的不同分布。
不同算法在测试图表现如下:

结语
VDN可以看作传统机器学习算法与神经网络结合的一个典型例子,这里主要使用神经网络来拟合了变分后验,其中涉及的,对边缘似然函数的理论下界的推导也属于EM算法推导的变形,具有一定的学习意义。