yolov5画框重复、大框包小框问题解决,c++、python代码调用onnx
yolov5在训练完成后,获取模型(pt)文件,或者转为onnx文件,对图片进行推理时,会出现以下情况,大框包小框,会导致,明明场景中只有一个目标物而识别出两个或者更多目标物,且画出的框均标记在目标物上,在单张图目标物较多的场景该现象更为严重,具体情况如下图所示。

如上图所示,右上角帽子的标签就出现了,大框包小框的现象。
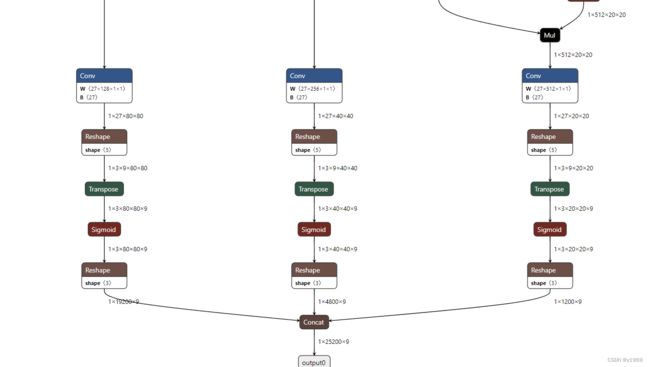
通过查找资料,发现是由于最新的代码,在生成模型,及导出onnx模型时,将anchor box decode过程包含在内。导出的onnx模型如下图所示(仅展示anchor box decode过程)。

用opencv的dnn模块做yolov5目标检测_nihate的博客-CSDN博客_opencv yolov5
这里有(上面链接),更改代码处理模型的详细过程,总结其中与之相关部分的代码及处理步骤如下所示(或有不同,是在使用时由于报错,对代码做了一点修改)。
models/yolo.py中的detect类中做一下修改(sigmoid可加可不加)
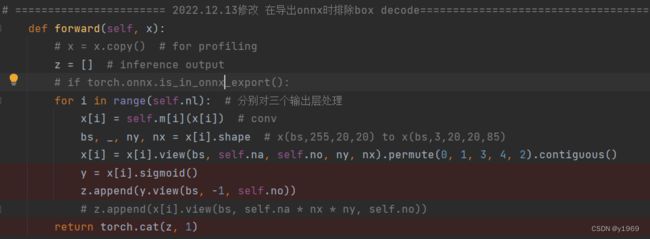
代码片段(可以复制代码片段)
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
# if torch.onnx.is_in_onnx_export():
for i in range(self.nl): # 分别对三个输出层处理
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
y = x[i].sigmoid()
z.append(y.view(bs, -1, self.no))
# z.append(x[i].view(bs, self.na * nx * ny, self.no))
return torch.cat(z, 1)在export.py文件中添加 def my_export_onnx
@try_export
def my_export_onnx(model, im, file, opset, dynamic, prefix=colorstr('ONNX:')):
print('anchors:', model.yaml['anchors'])
wtxt = open('class.names', 'w')
for name in model.names:
wtxt.write(name+'\n')
wtxt.close()
# YOLOv5 ONNX export
# print(im.shape)
if not dynamic:
f = os.path.splitext(file)[0] + '.onnx'
torch.onnx.export(model, im, f, verbose=False, opset_version=12, input_names=['images'], output_names=['output'])
else:
f = os.path.splitext(file)[0] + '_dynamic.onnx'
torch.onnx.export(model, im, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['output'], dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
})
try:
import cv2
net = cv2.dnn.readNet(f)
except:
exit(f'export {f} failed')
exit(f'export {f} sucess')同时修改export.py文件中的 def export_onnx 。 代码如下所示
@try_export
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx')
# ============== 2022.12.14剪枝yolov5的decode部分添加判断代码========================
my_export_onnx(model, im, file, opset, False, simplify)
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')修改完成后,使用下述命令生成onnx模型文件
python export.py --weights yolov5s.pt --img 640 --batch 1 --include=onnx --simplify 改过得onnx模型文件,anchor box decode过程如下图所示
同时,模型推理代码也需要进行更改,python代码如下
import cv2
import argparse
import numpy as np
class yolov5():
def __init__(self, modelpath, confThreshold=0.5, nmsThreshold=0.5, objThreshold=0.5):
with open(r'F:\XunLeiDownLoad\yolov5-v6.1-opencv-onnxrun-main\opencv/safetyclass.names', 'rt') as f:
self.classes = f.read().rstrip('\n').split('\n')
self.num_classes = len(self.classes)
if modelpath.endswith('6.onnx'):
self.inpHeight, self.inpWidth = 1280, 1280
anchors = [[19, 27, 44, 40, 38, 94], [96, 68, 86, 152, 180, 137], [140, 301, 303, 264, 238, 542],
[436, 615, 739, 380, 925, 792]]
self.stride = np.array([8., 16., 32., 64.])
else:
self.inpHeight, self.inpWidth = 640, 640
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
self.stride = np.array([8., 16., 32.])
self.nl = len(anchors)
self.na = len(anchors[0]) // 2
self.grid = [np.zeros(1)] * self.nl
self.anchor_grid = np.asarray(anchors, dtype=np.float32).reshape(self.nl, -1, 2)
self.net = cv2.dnn.readNet(modelpath)
self.confThreshold = confThreshold
self.nmsThreshold = nmsThreshold
self.objThreshold = objThreshold
self._inputNames = ''
def resize_image(self, srcimg, keep_ratio=True, dynamic=False):
top, left, newh, neww = 0, 0, self.inpWidth, self.inpHeight
if keep_ratio and srcimg.shape[0] != srcimg.shape[1]:
hw_scale = srcimg.shape[0] / srcimg.shape[1]
if hw_scale > 1:
newh, neww = self.inpHeight, int(self.inpWidth / hw_scale)
img = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)
if not dynamic:
left = int((self.inpWidth - neww) * 0.5)
img = cv2.copyMakeBorder(img, 0, 0, left, self.inpWidth - neww - left, cv2.BORDER_CONSTANT,
value=(114, 114, 114)) # add border
else:
newh, neww = int(self.inpHeight * hw_scale), self.inpWidth
img = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)
if not dynamic:
top = int((self.inpHeight - newh) * 0.5)
img = cv2.copyMakeBorder(img, top, self.inpHeight - newh - top, 0, 0, cv2.BORDER_CONSTANT,
value=(114, 114, 114))
else:
img = cv2.resize(srcimg, (self.inpWidth, self.inpHeight), interpolation=cv2.INTER_AREA)
return img, newh, neww, top, left
def _make_grid(self, nx=20, ny=20):
xv, yv = np.meshgrid(np.arange(ny), np.arange(nx))
return np.stack((xv, yv), 2).reshape((-1, 2)).astype(np.float32)
def preprocess(self, img):
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
return img
def postprocess(self, frame, outs, padsize=None):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
newh, neww, padh, padw = padsize
ratioh, ratiow = frameHeight / newh, frameWidth / neww
# Scan through all the bounding boxes output from the network and keep only the
# ones with high confidence scores. Assign the box's class label as the class with the highest score.
confidences = []
boxes = []
classIds = []
for detection in outs:
if detection[4] > self.objThreshold:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId] * detection[4]
if confidence > self.confThreshold:
center_x = int((detection[0] - padw) * ratiow)
center_y = int((detection[1] - padh) * ratioh)
width = int(detection[2] * ratiow)
height = int(detection[3] * ratioh)
left = int(center_x - width * 0.5)
top = int(center_y - height * 0.5)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
classIds.append(classId)
# Perform non maximum suppression to eliminate redundant overlapping boxes with
# lower confidences.
indices = cv2.dnn.NMSBoxes(boxes, confidences, self.confThreshold, self.nmsThreshold).flatten()
for i in indices:
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
frame = self.drawPred(frame, classIds[i], confidences[i], left, top, left + width, top + height)
return frame
def drawPred(self, frame, classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), thickness=4)
label = '%.2f' % conf
label = '%s:%s' % (self.classes[classId], label)
# Display the label at the top of the bounding box
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
# cv.rectangle(frame, (left, top - round(1.5 * labelSize[1])), (left + round(1.5 * labelSize[0]), top + baseLine), (255,255,255), cv.FILLED)
cv2.putText(frame, label, (left, top - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), thickness=2)
return frame
def detect(self, srcimg):
img, newh, neww, padh, padw = self.resize_image(srcimg)
blob = cv2.dnn.blobFromImage(img, scalefactor=1 / 255.0, swapRB=True)
# blob = cv2.dnn.blobFromImage(self.preprocess(img))
# Sets the input to the network
self.net.setInput(blob, self._inputNames)
# Runs the forward pass to get output of the output layers
outs = self.net.forward(self.net.getUnconnectedOutLayersNames())[0].squeeze(axis=0)
# inference output
row_ind = 0
for i in range(self.nl):
h, w = int(self.inpHeight / self.stride[i]), int(self.inpWidth / self.stride[i])
length = int(self.na * h * w)
if self.grid[i].shape[2:4] != (h, w):
self.grid[i] = self._make_grid(w, h)
outs[row_ind:row_ind + length, 0:2] = (outs[row_ind:row_ind + length, 0:2] * 2. - 0.5 + np.tile(
self.grid[i], (self.na, 1))) * int(self.stride[i])
outs[row_ind:row_ind + length, 2:4] = (outs[row_ind:row_ind + length, 2:4] * 2) ** 2 * np.repeat(
self.anchor_grid[i], h * w, axis=0)
row_ind += length
srcimg = self.postprocess(srcimg, outs, padsize=(newh, neww, padh, padw))
return srcimg
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--imgpath', type=str, default=r'E:\code\detect\yolov5\dataset\safety_clothing\test_safety_clothing\images1\398404624-1-16_6675.jpg', help="image path")
parser.add_argument('--modelpath', type=str, default=r'E:\code\detect\yolov5\runs\train\all_safetly\best_all_che.onnx')
parser.add_argument('--confThreshold', default=0.3, type=float, help='class confidence')
parser.add_argument('--nmsThreshold', default=0.5, type=float, help='nms iou thresh')
parser.add_argument('--objThreshold', default=0.3, type=float, help='object confidence')
args = parser.parse_args()
yolonet = yolov5(args.modelpath, confThreshold=args.confThreshold, nmsThreshold=args.nmsThreshold,
objThreshold=args.objThreshold)
srcimg = cv2.imread(args.imgpath)
srcimg = yolonet.detect(srcimg)
winName = 'Deep learning object detection in OpenCV'
cv2.namedWindow(winName, 0)
cv2.imshow(winName, srcimg)
cv2.waitKey(0)
cv2.destroyAllWindows()safetyclass.names 为标签文件,下图是截图展示

c++推理代码如下
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace dnn;
using namespace std;
struct Net_config
{
float confThreshold; // Confidence threshold
float nmsThreshold; // Non-maximum suppression threshold
float objThreshold; //Object Confidence threshold
string modelpath;
};
//int endsWith(const string& s, const string& sub) {
// return s.rfind(sub) == (s.length() - sub.length()) ? 1 : 0;
//}
const float anchors_640[3][6] = { {10.0, 13.0, 16.0, 30.0, 33.0, 23.0},
{30.0, 61.0, 62.0, 45.0, 59.0, 119.0},
{116.0, 90.0, 156.0, 198.0, 373.0, 326.0} };
//const float anchors_1280[4][6] = { {19, 27, 44, 40, 38, 94},{96, 68, 86, 152, 180, 137},{140, 301, 303, 264, 238, 542},
// {436, 615, 739, 380, 925, 792} };
class YOLO
{
public:
explicit YOLO(const Net_config& config);
void detect(Mat& frame);
private:
float* anchors;
int num_stride;
int inpWidth;
int inpHeight;
vector class_names;
// int num_class;
float confThreshold;
float nmsThreshold;
float objThreshold;
const bool keep_ratio = true;
Net net;
void drawPred(float conf, int left, int top, int right, int bottom, Mat& frame, int classid);
Mat resize_image(const Mat& srcimg, int *newh, int *neww, int *top, int *left) const;
};
YOLO::YOLO(const Net_config& config)
{
this->confThreshold = config.confThreshold;
this->nmsThreshold = config.nmsThreshold;
this->objThreshold = config.objThreshold;
this->net = readNet(config.modelpath);
// ifstream ifs("F:\\XunLeiDownLoad\\yolov5-v6.1-opencv-onnxrun-main\\opencv/class.names");
ifstream ifs(R"(F:\XunLeiDownLoad\yolov5-v6.1-opencv-onnxrun-main\opencv/safetyclass.names)");
string line;
while (getline(ifs, line)) this->class_names.push_back(line);
// this->num_class = class_names.size();
// if (endsWith(config.modelpath, "6.onnx"))
// {
// anchors = (float*)anchors_1280;
// this->num_stride = 4;
// this->inpHeight = 1280;
// this->inpWidth = 1280;
// }
// else
// {
anchors = (float*)anchors_640;
this->num_stride = 3;
this->inpHeight = 640;
this->inpWidth = 640;
// }
}
Mat YOLO::resize_image(const Mat& srcimg, int *newh, int *neww, int *top, int *left) const
{
int srch = srcimg.rows, srcw = srcimg.cols;
*newh = this->inpHeight;
*neww = this->inpWidth;
Mat dstimg;
if (this->keep_ratio && srch != srcw) {
float hw_scale = (float)srch / srcw;
if (hw_scale > 1) {
*newh = this->inpHeight;
*neww = int(this->inpWidth / hw_scale);
resize(srcimg, dstimg, Size(*neww, *newh), INTER_AREA);
*left = int((this->inpWidth - *neww) * 0.5);
copyMakeBorder(dstimg, dstimg, 0, 0, *left, this->inpWidth - *neww - *left, BORDER_CONSTANT, 114);
}
else {
*newh = (int)this->inpHeight * hw_scale;
*neww = this->inpWidth;
resize(srcimg, dstimg, Size(*neww, *newh), INTER_AREA);
*top = (int)(this->inpHeight - *newh) * 0.5;
copyMakeBorder(dstimg, dstimg, *top, this->inpHeight - *newh - *top, 0, 0, BORDER_CONSTANT, 114);
}
}
else {
resize(srcimg, dstimg, Size(*neww, *newh), INTER_AREA);
}
return dstimg;
}
void YOLO::drawPred(float conf, int left, int top, int right, int bottom, Mat& frame, int classid) // Draw the predicted bounding box
{
//Draw a rectangle displaying the bounding box
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 0, 255), 2);
//Get the label for the class name and its confidence
string label = format("%.2f", conf);
label = this->class_names[classid] + ":" + label;
//Display the label at the top of the bounding box
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
//rectangle(frame, Point(left, top - int(1.5 * labelSize.height)), Point(left + int(1.5 * labelSize.width), top + baseLine), Scalar(0, 255, 0), FILLED);
putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.75, Scalar(0, 255, 0), 1);
}
void YOLO::detect(Mat& frame)
{
int newh = 0, neww = 0, padh = 0, padw = 0;
Mat dstimg = this->resize_image(frame, &newh, &neww, &padh, &padw);
Mat blob = blobFromImage(dstimg, 1 / 255.0, Size(this->inpWidth, this->inpHeight), Scalar(0, 0, 0), true, false);
this->net.setInput(blob);
vector outs;
this->net.forward(outs, this->net.getUnconnectedOutLayersNames());
int num_proposal = outs[0].size[1];
int nout = outs[0].size[2];
if (outs[0].dims > 2)
{
outs[0] = outs[0].reshape(0, num_proposal);
}
/generate proposals
vector confidences;
vector boxes;
vector classIds;
float ratioh = (float)frame.rows / newh, ratiow = (float)frame.cols / neww;
int n = 0, q = 0, i = 0, j = 0, row_ind = 0; ///xmin,ymin,xamx,ymax,box_score,class_score
auto* pdata = (float*)outs[0].data;
for (n = 0; n < this->num_stride; n++) ///特征图尺度
{
const float stride = pow(2, n + 3);
int num_grid_x = (int)ceil((this->inpWidth / stride));
int num_grid_y = (int)ceil((this->inpHeight / stride));
for (q = 0; q < 3; q++) ///anchor
{
const float anchor_w = this->anchors[n * 6 + q * 2];
const float anchor_h = this->anchors[n * 6 + q * 2 + 1];
for (i = 0; i < num_grid_y; i++)
{
for (j = 0; j < num_grid_x; j++)
{
float box_score = pdata[4];
if (box_score > this->objThreshold)
{
Mat scores = outs[0].row(row_ind).colRange(5, nout);
Point classIdPoint;
double max_class_socre;
// Get the value and location of the maximum score
minMaxLoc(scores, 0, &max_class_socre, 0, &classIdPoint);
max_class_socre *= box_score;
if (max_class_socre > this->confThreshold)
{
const int class_idx = classIdPoint.x;
float cx = (pdata[0] * 2.f - 0.5f + j) * stride; ///cx
float cy = (pdata[1] * 2.f - 0.5f + i) * stride; ///cy
float w = powf(pdata[2] * 2.f, 2.f) * anchor_w; ///w
float h = powf(pdata[3] * 2.f, 2.f) * anchor_h; ///h
int left = int((cx - padw - 0.5 * w)*ratiow);
int top = int((cy - padh - 0.5 * h)*ratioh);
confidences.push_back((float)max_class_socre);
// boxes.push_back(Rect(left, top, (int)(w*ratiow), (int)(h*ratioh)));
boxes.emplace_back(left, top, (int)(w*ratiow), (int)(h*ratioh));
classIds.push_back(class_idx);
}
}
row_ind++;
pdata += nout;
}
}
}
}
// Perform non maximum suppression to eliminate redundant overlapping boxes with
// lower confidences
vector indices;
/*dnn::NMSBoxes
* 作用:根据给定的检测boxes和对应的scores进行NMS(非极大值抑制)处理
* NMSBoxes(bboxes,
scores,
score_threshold,
nms_threshold,
eta=None,
top_k=None)
参数:
boxes: 待处理的边界框 bounding boxes
scores: 对于于待处理边界框的 scores
score_threshold: 用于过滤 boxes 的 score 阈值
nms_threshold: NMS 用到的阈值
indices: NMS 处理后所保留的边界框的索引值
eta: 自适应阈值公式中的相关系数:
* */
dnn::NMSBoxes(boxes, confidences, this->confThreshold, this->nmsThreshold, indices);
// for (size_t i = 0; i < indices.size(); ++i)
// {
// int idx = indices[i];
// Rect box = boxes[idx];
// this->drawPred(confidences[idx], box.x, box.y,
// box.x + box.width, box.y + box.height, frame, classIds[idx]);
// }
for (int idx : indices)
{
Rect box = boxes[idx];
this->drawPred(confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame, classIds[idx]);
}
}
int main()
{
// Net_config yolo_nets = { 0.3, 0.5, 0.3, "F:\\XunLeiDownLoad\\yolov5-v6.1-opencv-onnxrun-main\\opencv/weights/yolov5s.onnx" };
Net_config yolo_nets = { 0.3, 0.5, 0.3, R"(E:\code\detect\yolov5\runs\train\all_safetly\best_all_che.onnx)" };
YOLO yolo_model(yolo_nets);
string imgpath = R"(E:\code\detect\yolov5\dataset\safety_clothing\test_safety_clothing\images1\398404624-1-16_6675.jpg)";
Mat srcimg = imread(imgpath);
yolo_model.detect(srcimg);
string saveimg_path= R"(E:\code\detect\yolov5\testsave\safety2.jpg)";
imwrite(saveimg_path, srcimg);
// static const string kWinName = "Deep learning object detection in OpenCV";
// namedWindow(kWinName, WINDOW_NORMAL);
// imshow(kWinName, srcimg);
// waitKey(5000);
// destroyAllWindows();
}
经过上述过程后图片的推理结果如下所示

可以看出,大框包小框的现象消失。
参考文章:
用opencv的dnn模块做yolov5目标检测_nihate的博客-CSDN博客_opencv yolov5windows下最新yolov5转ncnn教程(支持u版yolov5(ultralytics版)v5.0)_五四三两幺-发射!的博客-CSDN博客_yolov5转换xnno
原代码地址:https://github.com/hpc203/yolov5-v6.1-opencv-onnxrun