【10.1算法理论部分(2)概率计算问题(前向-后向算法)】Hidden Markov Algorithm——李航《统计学习方法》公式推导
10.2 概率计算方法(解决Evaluation:Given λ ,求 P(O|λ))
10.2.1直接计算法
1.给定HMM模型 λ = ( A , B , π ) \lambda = (A,B,\pi) λ=(A,B,π)和观测序列 O = ( o 1 , o 2 , ⋅ ⋅ ⋅ , o T ) O = (o_{1},o_{2}, \cdot \cdot \cdot , o_{T}) O=(o1,o2,⋅⋅⋅,oT),概率计算问题需要计算在模型λ下观测序列O出现的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ).
2.最直接的方法是按照概率公式直接计算:通过列举所有可能的、长度为T的状态序列 S = ( s 1 , s 2 , ⋅ ⋅ ⋅ , s T ) S = (s_{1},s_{2}, \cdot \cdot \cdot , s_{T}) S=(s1,s2,⋅⋅⋅,sT),求各个状态序列 I 与观测序列 O = ( o 1 , o 2 , ⋅ ⋅ ⋅ , o T ) O = (o_{1},o_{2}, \cdot \cdot \cdot , o_{T}) O=(o1,o2,⋅⋅⋅,oT)的联合概率 P ( O , S ∣ λ ) P(O,S|\lambda) P(O,S∣λ),然后对所有可能的状态序列求和,得到 P ( O ∣ λ ) P(O|\lambda) P(O∣λ).
(1)状态序列 S = ( s 1 , s 2 , ⋅ ⋅ ⋅ , s T ) S = (s_{1},s_{2}, \cdot \cdot \cdot , s_{T}) S=(s1,s2,⋅⋅⋅,sT)的概率为:
P ( S ∣ λ ) = π s 1 , a s 1 s 2 , π s 2 , a s 2 s 3 , ⋅ ⋅ ⋅ , a s T − 1 s T − − − − ( 10.10 ) P(S|\lambda) = \pi_{s_{1}},a_{s_{1}s_{2}},\pi_{s_{2}},a_{s_{2}s_{3}},\cdot \cdot \cdot ,a_{s_{T-1}s_{T}}----(10.10) P(S∣λ)=πs1,as1s2,πs2,as2s3,⋅⋅⋅,asT−1sT−−−−(10.10)
(2)给定状态序列 S = ( s 1 , s 2 , ⋅ ⋅ ⋅ , s T ) S = (s_{1},s_{2}, \cdot \cdot \cdot , s_{T}) S=(s1,s2,⋅⋅⋅,sT),观测序列 O = ( o 1 , o 2 , ⋅ ⋅ ⋅ , o T ) O = (o_{1},o_{2}, \cdot \cdot \cdot , o_{T}) O=(o1,o2,⋅⋅⋅,oT)的条件概率为:
P ( O ∣ S , λ ) = b s 1 ( o 1 ) , b s 2 ( o 2 ) , ⋅ ⋅ ⋅ , b s T ( o T ) − − − − ( 10.11 ) P(O|S,\lambda) = b_{s_{1}}(o_{1}),b_{s_{2}}(o_{2}),\cdot \cdot \cdot ,b_{s_{T}}(o_{T})----(10.11) P(O∣S,λ)=bs1(o1),bs2(o2),⋅⋅⋅,bsT(oT)−−−−(10.11)
(3)O 和 I 同时出现的联合概率为:
P ( O , S ∣ λ ) = P ( O ∣ S , λ ) P ( S ∣ λ ) = π s 1 a s 1 s 2 a s 2 s 3 , ⋅ ⋅ ⋅ , a s T − 1 s T b s 1 ( o 1 ) , b s 2 ( o 2 ) , ⋅ ⋅ ⋅ , b s T ( o T ) − − − − ( 10.12 ) P(O,S|\lambda) = P(O|S,\lambda)P(S|\lambda) = \pi_{s_{1}}a_{s_{1}s_{2}}a_{s_{2}s_{3}},\cdot \cdot \cdot ,a_{s_{T-1}s_{T}}b_{s_{1}}(o_{1}),b_{s_{2}}(o_{2}),\cdot \cdot \cdot ,b_{s_{T}}(o_{T})----(10.12) P(O,S∣λ)=P(O∣S,λ)P(S∣λ)=πs1as1s2as2s3,⋅⋅⋅,asT−1sTbs1(o1),bs2(o2),⋅⋅⋅,bsT(oT)−−−−(10.12)
(4)对所有可能的状态序列 I 求和,得到观测序列 O 的概率:
P ( S ∣ λ ) = ∑ S P ( O ∣ S , λ ) P ( S ∣ λ ) = ∑ S P ( O , S ∣ λ ) = ∑ s 1 , s 1 , ⋅ ⋅ ⋅ , s T π s 1 a s 1 s 2 a s 2 s 3 , ⋅ ⋅ ⋅ , a s T − 1 s T b s 1 ( o 1 ) , b s 2 ( o 2 ) , ⋅ ⋅ ⋅ , b s T ( o T ) − − − − ( 10.13 ) P(S|\lambda) = \sum_{S} P(O|S,\lambda)P(S|\lambda) = \sum_{S} P(O,S|\lambda) = \sum_{s_{1},s_{1}, \cdot \cdot \cdot ,s_{T}} \pi_{s_{1}}a_{s_{1}s_{2}}a_{s_{2}s_{3}},\cdot \cdot \cdot ,a_{s_{T-1}s_{T}}b_{s_{1}}(o_{1}),b_{s_{2}}(o_{2}),\cdot \cdot \cdot ,b_{s_{T}}(o_{T})----(10.13) P(S∣λ)=S∑P(O∣S,λ)P(S∣λ)=S∑P(O,S∣λ)=s1,s1,⋅⋅⋅,sT∑πs1as1s2as2s3,⋅⋅⋅,asT−1sTbs1(o1),bs2(o2),⋅⋅⋅,bsT(oT)−−−−(10.13)
这里就是对S求积分,然后就可以把S积掉,然后得到 P ( O ∣ λ ) P(O|\lambda) P(O∣λ).
上式的算法复杂度为 O ( T ∗ Q T ) O(T*Q^{T}) O(T∗QT),太复杂,实际应用中不太可行。
上式中的时间复杂度 O ( T ∗ Q T ) O(T*Q^{T}) O(T∗QT)是怎么计算的呢?
对于式子 P ( O , S ∣ λ ) = P ( O ∣ S , λ ) P ( S ∣ λ ) = π s 1 a s 1 s 2 a s 2 s 3 , ⋅ ⋅ ⋅ , a s T − 1 s T b s 1 ( o 1 ) , b s 2 ( o 2 ) , ⋅ ⋅ ⋅ , b s T ( o T ) P(O,S|\lambda) = P(O|S,\lambda)P(S|\lambda) = \pi_{s_{1}}a_{s_{1}s_{2}}a_{s_{2}s_{3}},\cdot \cdot \cdot ,a_{s_{T-1}s_{T}}b_{s_{1}}(o_{1}),b_{s_{2}}(o_{2}),\cdot \cdot \cdot ,b_{s_{T}}(o_{T}) P(O,S∣λ)=P(O∣S,λ)P(S∣λ)=πs1as1s2as2s3,⋅⋅⋅,asT−1sTbs1(o1),bs2(o2),⋅⋅⋅,bsT(oT)本身的时间复杂度为T,然后由于需要计算 ∑ s 1 , s 1 , ⋅ ⋅ ⋅ , s T \sum_{s_{1},s_{1}, \cdot \cdot \cdot ,s_{T}} ∑s1,s1,⋅⋅⋅,sT,这里就相当于是 N T N^{T} NT,所以最终的时间复杂度就为 O ( T N T ) O(TN^{T}) O(TNT).
10.2.2前向算法
- 定义10.2(前向概率) 给定隐马尔可夫模型 λ ,定义到时刻 t 部分观测序列为 o 1 , o 2 , ⋅ ⋅ ⋅ , o T o_{1},o_{2}, \cdot \cdot \cdot , o_{T} o1,o2,⋅⋅⋅,oT 且状态为 q i q_{i} qi 的概率为前向概率,记作:
α t ( i ) = P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t = q i ∣ λ ) − − − − ( 10.14 ) \alpha_{t}(i) = P(o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t} = q_{i}|\lambda)----(10.14) αt(i)=P(o1,o2,⋅⋅⋅,ot,st=qi∣λ)−−−−(10.14)
可以递推的求得前向概率 α t ( i ) \alpha_{t}(i) αt(i)及观测序列概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ). - 算法10.2(观测序列概率的前向算法)
输入:HMM的参数 λ ,观测序列O;
输出:观测序列概率 P(O|λ).
(1)初值
α 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , ⋅ ⋅ ⋅ , N − − − − ( 10.15 ) \alpha_{1}(i) = \pi_{i}b_{i}(o_{1}), i = 1,2, \cdot \cdot \cdot , N----(10.15) α1(i)=πibi(o1),i=1,2,⋅⋅⋅,N−−−−(10.15)
(2)递推 对 t = 1 , 2 , ⋅ ⋅ ⋅ , T − 1 t = 1,2, \cdot \cdot \cdot , T-1 t=1,2,⋅⋅⋅,T−1,
α t + 1 ( i ) = [ ∑ j = 1 N α t ( j ) a j i ] b i ( o t + 1 ) , i = 1 , 2 , ⋅ ⋅ ⋅ , N − − − − ( 10.16 ) \alpha_{t+1}(i) = \left [ \sum_{j=1}^{N}\alpha_{t}(j)a_{ji} \right ] b_{i}(o_{t+1}), i = 1,2, \cdot \cdot \cdot , N----(10.16) αt+1(i)=[j=1∑Nαt(j)aji]bi(ot+1),i=1,2,⋅⋅⋅,N−−−−(10.16)
(10.16)推导
α t ( i ) − − − − ( 10.16.1 ) \alpha_{t}(i)----(10.16.1) αt(i)−−−−(10.16.1)
= P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t = q i ∣ λ ) − − − − ( 10.16.2 ) =P(o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t} = q_{i}|\lambda)----(10.16.2) =P(o1,o2,⋅⋅⋅,ot,st=qi∣λ)−−−−(10.16.2)
= ∑ j = 1 N P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t − 1 = q j , s t = q i ∣ λ ) − − − − ( 10.16.3 ) =\sum_{j=1}^{N}P(o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t-1} = q_{j},s_{t} = q_{i}|\lambda)----(10.16.3) =∑j=1NP(o1,o2,⋅⋅⋅,ot,st−1=qj,st=qi∣λ)−−−−(10.16.3)
= ∑ j = 1 N P ( o t ∣ o 1 , o 2 , ⋅ ⋅ ⋅ , o t − 1 , s t − 1 = q j , s t = q i , λ ) P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t − 1 , s t − 1 = q j , s t = q i ∣ λ ) − − − − ( 10.16.4 ) =\sum_{j=1}^{N}P( o_{t}|o_{1},o_{2}, \cdot \cdot \cdot,o_{t-1} ,s_{t-1} = q_{j},s_{t} = q_{i},\lambda)P(o_{1},o_{2}, \cdot \cdot \cdot,o_{t-1} ,s_{t-1} = q_{j},s_{t} = q_{i}|\lambda)----(10.16.4) =∑j=1NP(ot∣o1,o2,⋅⋅⋅,ot−1,st−1=qj,st=qi,λ)P(o1,o2,⋅⋅⋅,ot−1,st−1=qj,st=qi∣λ)−−−−(10.16.4)
= ∑ j = 1 N P ( o t ∣ s t = q i , λ ) P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t − 1 , s t − 1 = q j , s t = q i ∣ λ ) P ( s t = q i ∣ o 1 , o 2 , ⋅ ⋅ ⋅ , o t − 1 , s t − 1 = q j , λ ) − − − − ( 10.16.5 ) =\sum_{j=1}^{N}P(o_{t}|s_{t} = q_{i},\lambda)P(o_{1},o_{2}, \cdot \cdot \cdot,o_{t-1} ,s_{t-1} = q_{j},s_{t} = q_{i}|\lambda)P(s_{t} = q_{i}|o_{1},o_{2}, \cdot \cdot \cdot,o_{t-1} ,s_{t-1} = q_{j},\lambda)----(10.16.5) =∑j=1NP(ot∣st=qi,λ)P(o1,o2,⋅⋅⋅,ot−1,st−1=qj,st=qi∣λ)P(st=qi∣o1,o2,⋅⋅⋅,ot−1,st−1=qj,λ)−−−−(10.16.5)
= P ( o t ∣ s t = q i , λ ) ∑ j = 1 N P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t − 1 , s t − 1 = q j ∣ λ ) P ( s t = q i ∣ s t − 1 = q j , λ ) − − − − ( 10.16.6 ) =P(o_{t}|s_{t} = q_{i},\lambda)\sum_{j=1}^{N}P(o_{1},o_{2}, \cdot \cdot \cdot,o_{t-1} ,s_{t-1} = q_{j}|\lambda)P(s_{t} = q_{i}|s_{t-1} = q_{j},\lambda)----(10.16.6) =P(ot∣st=qi,λ)∑j=1NP(o1,o2,⋅⋅⋅,ot−1,st−1=qj∣λ)P(st=qi∣st−1=qj,λ)−−−−(10.16.6)
= b s ( o t ) ∑ j = 1 N α t − 1 ( j ) a j i − − − − ( 10.16.7 ) =b_{s}(o_{t})\sum_{j=1}^{N}\alpha_{t-1}(j)a_{ji}----(10.16.7) =bs(ot)∑j=1Nαt−1(j)aji−−−−(10.16.7)
这个用的是 α t ( i ) \alpha_{t}(i) αt(i)和 α t − 1 ( j ) \alpha_{t-1}(j) αt−1(j)的递推,与(10.16)的 α t + 1 ( i ) \alpha_{t+1}(i) αt+1(i)和 α t ( j ) \alpha_{t}(j) αt(j)递推类似,改改下标就行
其中,(10.16.4)-(10.16.5)用到了观测独立性假设和条件概率,(10.16.5)-(10.16.6)用到了齐次马尔可夫性假设
(3)终止
P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) − − − ( 10.17 ) P(O|λ) = \sum_{i=1}^{N}\alpha_{T}(i)---(10.17) P(O∣λ)=i=1∑NαT(i)−−−(10.17)
这个公式该如何理解嘞?
就相当于 P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) = ∑ i = 1 N P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t = q i ∣ λ ) P(O|λ) = \sum_{i=1}^{N}\alpha_{T}(i) = \sum_{i=1}^{N}P(o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t} = q_{i}|\lambda) P(O∣λ)=∑i=1NαT(i)=∑i=1NP(o1,o2,⋅⋅⋅,ot,st=qi∣λ)对i进行积分,就可以直接得到 P ( O ∣ λ ) P(O|λ) P(O∣λ).
给一张图片可以更直观的感受这个公式的意思:
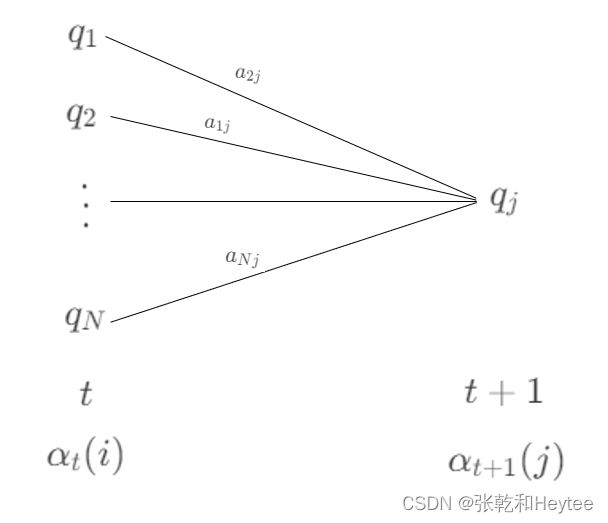
这里我习惯从 i 到 j 可能和公式中的 a j i a_{ji} aji 正好反过来了,看的时候可以注意一下,其实都是一个道理,只是一个符号而已。
同时借着这张图和前向算法的递推式来聊一聊时间复杂度的问题:
由于前向算法的递推公式,所以每一步的计算都用到了上一步的结果,所以使得时间复杂度大大的降低,我们来算一算前向算法的具体的时间复杂度:每一个时刻 t 都有 N 个可能的状态,每一个状态需要运用前向算法的递推公式要计算 N 2 N^2 N2次,一共有T个时刻,所以最终的时间复杂度为 O ( T N 2 ) O(TN^2) O(TN2),提前说一句,当你看完后向算法的时候你会发现,后向算法的时间复杂度也是 O ( T N 2 ) O(TN^2) O(TN2),后面还会提这个问题。
都看到这里了,也是一大堆理论的东西,没有例子终究觉得理解的不够深刻,那我建议去看一看书中的例10.2,自己算一遍,理解肯定非常深刻
10.2.3后向算法
- **定义10.3(后向概率)**给定隐马尔可夫模型 λ,定义在时刻 t 状态为 q i q_{i} qi的条件下,从 t+1 到 T 的部分观测序列为 o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T} ot+1,ot+2,⋅⋅⋅,oT 的概率为后向概率,记作:
β t ( i ) = P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T ∣ s t = q i , λ ) − − − − ( 10.18 ) \beta_{t}(i) = P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T}|s_{t} = q_{i},\lambda)----(10.18) βt(i)=P(ot+1,ot+2,⋅⋅⋅,oT∣st=qi,λ)−−−−(10.18) - 算法10.3(观测序列概率的后向算法)
输入:HMM的参数 λ ,观测序列O;
输出:观测序列概率P(O|λ).
(1)计算初值:
β T ( i ) = 1 , i = 1 , 2 , ⋅ ⋅ ⋅ , N − − − − ( 10.19 ) \beta_{T}(i) = 1 , i = 1,2, \cdot \cdot \cdot , N----(10.19) βT(i)=1,i=1,2,⋅⋅⋅,N−−−−(10.19)
这个地方你可能有问题,就是为什么 β T ( i ) \beta_{T}(i) βT(i)要等于1 ?
解答这个问题可以从后向概率的定义说起,对于 β T ( i ) \beta_{T}(i) βT(i)是什么意思嘞,就是说在 T 时刻状态为KaTeX parse error: Undefined control sequence: \q at position 1: \̲q̲_{i}的条件下,从 T+1 到最后的观测序列,但是我们的观测就知道 T ,所以T+1 时刻可以观测到任意值,所以概率就是1。
同样的在网上我也看到了相应问题的数学推导,见下图,可以跟着推导理解一下。

(2)递推:对 t = T − 1 , T − 2 , ⋅ ⋅ ⋅ , 1 t = T-1,T-2,\cdot \cdot \cdot ,1 t=T−1,T−2,⋅⋅⋅,1
β t ( i ) = ∑ j = 1 N α t ( j ) a b i ( o t + 1 ) , i = 1 , 2 , ⋅ ⋅ ⋅ , N − − − − ( 10.20 ) \beta_{t}(i) = \sum_{j=1}^{N}\alpha_{t}(j)a_{} b_{i}(o_{t+1}), i = 1,2, \cdot \cdot \cdot , N----(10.20) βt(i)=j=1∑Nαt(j)abi(ot+1),i=1,2,⋅⋅⋅,N−−−−(10.20)
(10.20)推导
β t ( i ) − − − − ( 10.20.1 ) \beta_{t}(i)----(10.20.1) βt(i)−−−−(10.20.1)
= P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T ∣ s t = q i , λ ) − − − − ( 10.20.2 ) =P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T}|s_{t} = q_{i},\lambda)----(10.20.2) =P(ot+1,ot+2,⋅⋅⋅,oT∣st=qi,λ)−−−−(10.20.2)
= ∑ j = 1 N P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T , s t + 1 = q j ∣ s t = q i , λ ) − − − − ( 10.20.3 ) =\sum_{j=1}^{N}P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T},s_{t+1} = q_{j}|s_{t} = q_{i},\lambda)----(10.20.3) =∑j=1NP(ot+1,ot+2,⋅⋅⋅,oT,st+1=qj∣st=qi,λ)−−−−(10.20.3)
= ∑ j = 1 N P ( s t + 1 = q j ∣ s t = q i , λ ) P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T ∣ s t + 1 = q j , s t = q i , λ ) − − − − ( 10.20.4 ) =\sum_{j=1}^{N}P( s_{t+1}=q_{j}|s_{t}=q_{i},\lambda)P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T}|s_{t+1} = q_{j},s_{t} = q_{i},\lambda)----(10.20.4) =∑j=1NP(st+1=qj∣st=qi,λ)P(ot+1,ot+2,⋅⋅⋅,oT∣st+1=qj,st=qi,λ)−−−−(10.20.4)
= ∑ j = 1 N P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T ∣ s t + 1 = q j , s t = q i , λ ) a i j − − − − ( 10.20.5 ) =\sum_{j=1}^{N}P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T}|s_{t+1} = q_{j},s_{t} = q_{i},\lambda)a_{ij}----(10.20.5) =∑j=1NP(ot+1,ot+2,⋅⋅⋅,oT∣st+1=qj,st=qi,λ)aij−−−−(10.20.5)
= ∑ j = 1 N P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T ∣ s t + 1 = q j , λ ) a i j − − − − ( 10.20.6 ) =\sum_{j=1}^{N}P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T}|s_{t+1} = q_{j},\lambda)a_{ij}----(10.20.6) =∑j=1NP(ot+1,ot+2,⋅⋅⋅,oT∣st+1=qj,λ)aij−−−−(10.20.6)
= ∑ j = 1 N P ( o t + 1 ∣ o t + 2 , o t + 3 , ⋅ ⋅ ⋅ , o T , s t + 1 = q j , λ ) P ( o t + 2 , o t + 3 , ⋅ ⋅ ⋅ , o T ∣ s t + 1 = q j , λ ) a i j − − − − ( 10.20.7 ) =\sum_{j=1}^{N}P(o_{t+1}|o_{t+2},o_{t+3}, \cdot \cdot \cdot , o_{T},s_{t+1} = q_{j},\lambda)P(o_{t+2},o_{t+3}, \cdot \cdot \cdot , o_{T}|s_{t+1} = q_{j},\lambda)a_{ij}----(10.20.7) =∑j=1NP(ot+1∣ot+2,ot+3,⋅⋅⋅,oT,st+1=qj,λ)P(ot+2,ot+3,⋅⋅⋅,oT∣st+1=qj,λ)aij−−−−(10.20.7)
= ∑ j = 1 N P ( o t + 1 ∣ s t + 1 = q j , λ ) P ( o t + 2 , o t + 3 , ⋅ ⋅ ⋅ , o T ∣ s t + 1 = q j , λ ) a i j − − − − ( 10.20.8 ) =\sum_{j=1}^{N}P(o_{t+1}|s_{t+1} = q_{j},\lambda)P(o_{t+2},o_{t+3}, \cdot \cdot \cdot , o_{T}|s_{t+1} = q_{j},\lambda)a_{ij}----(10.20.8) =∑j=1NP(ot+1∣st+1=qj,λ)P(ot+2,ot+3,⋅⋅⋅,oT∣st+1=qj,λ)aij−−−−(10.20.8)
= ∑ j = 1 N b j ( o t + 1 ) β t + 1 ( j ) a i j − − − − ( 10.20.9 ) =\sum_{j=1}^{N}b_{j}(o_{t+1})\beta_{t+1}(j)a_{ij}----(10.20.9) =∑j=1Nbj(ot+1)βt+1(j)aij−−−−(10.20.9)
这个用的是 β t ( i ) \beta_{t}(i) βt(i)和 β t + 1 ( j ) \beta_{t+1}(j) βt+1(j)的递推,与公式保持一致
(10.20.5)-(10.20.6)用到的是齐次马尔科夫性假设,(10.20.6)-(10.20.7)用到的是观测独立性假设。
(3)终止:
P ( O ∣ λ ) = ∑ i = 1 Q π i b i ( o 1 ) β 1 ( i ) − − − − ( 10.21 ) P(O|λ) = \sum_{i=1}^{Q}\pi_{i}b_{i}(o_{1})\beta_{1}(i)----(10.21) P(O∣λ)=i=1∑Qπibi(o1)β1(i)−−−−(10.21)
(10.21)推导
P ( O ∣ λ ) − − − − ( 10.21.1 ) P(O|λ)----(10.21.1) P(O∣λ)−−−−(10.21.1)
= P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o T ∣ λ ) − − − − ( 10.21.2 ) = P(o_{1},o_{2},\cdot \cdot \cdot ,o_{T}|λ)----(10.21.2) =P(o1,o2,⋅⋅⋅,oT∣λ)−−−−(10.21.2)
= ∑ N i = 1 P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o T , s 1 = q i ∣ λ ) − − − − ( 10.21.3 ) = \sum_{N}^{i=1}P(o_{1},o_{2},\cdot \cdot \cdot ,o_{T},s_{1} = q_{i}|λ)----(10.21.3) =∑Ni=1P(o1,o2,⋅⋅⋅,oT,s1=qi∣λ)−−−−(10.21.3)
= ∑ N i = 1 P ( o 1 ∣ o 2 , o 3 , ⋅ ⋅ ⋅ , o T , s 1 = q i , λ ) P ( o 2 , o 3 , ⋅ ⋅ ⋅ , o T , s 1 = q i ∣ λ ) − − − − ( 10.21.4 ) =\sum_{N}^{i=1}P(o_{1}|o_{2},o_{3},\cdot \cdot \cdot ,o_{T},s_{1} = q_{i},λ)P(o_{2},o_{3},\cdot \cdot \cdot ,o_{T},s_{1} = q_{i}|λ)----(10.21.4) =∑Ni=1P(o1∣o2,o3,⋅⋅⋅,oT,s1=qi,λ)P(o2,o3,⋅⋅⋅,oT,s1=qi∣λ)−−−−(10.21.4)
= ∑ N i = 1 P ( o 1 ∣ s 1 = q i , λ ) P ( o 2 , o 3 , ⋅ ⋅ ⋅ , o T , s 1 = q i ∣ λ ) − − − − ( 10.21.5 ) =\sum_{N}^{i=1}P(o_{1}|s_{1} = q_{i},λ)P(o_{2},o_{3},\cdot \cdot \cdot ,o_{T},s_{1} = q_{i}|λ)----(10.21.5) =∑Ni=1P(o1∣s1=qi,λ)P(o2,o3,⋅⋅⋅,oT,s1=qi∣λ)−−−−(10.21.5)
= ∑ N i = 1 b i ( o 1 ) P ( o 2 , o 3 , ⋅ ⋅ ⋅ , o T , s 1 = q i ∣ λ ) − − − − ( 10.21.6 ) =\sum_{N}^{i=1}b_{i}(o_{1})P(o_{2},o_{3},\cdot \cdot \cdot ,o_{T},s_{1} = q_{i}|λ)----(10.21.6) =∑Ni=1bi(o1)P(o2,o3,⋅⋅⋅,oT,s1=qi∣λ)−−−−(10.21.6)
= ∑ N i = 1 b i ( o 1 ) P ( o 2 , o 3 , ⋅ ⋅ ⋅ , o T ∣ s 1 = q i , λ ) P ( s 1 = q i ∣ λ ) − − − − ( 10.21.7 ) =\sum_{N}^{i=1}b_{i}(o_{1})P(o_{2},o_{3},\cdot \cdot \cdot ,o_{T}|s_{1} = q_{i},λ)P(s_{1}=q_{i}|\lambda)----(10.21.7) =∑Ni=1bi(o1)P(o2,o3,⋅⋅⋅,oT∣s1=qi,λ)P(s1=qi∣λ)−−−−(10.21.7)
= ∑ N i = 1 π i b i ( o 1 ) β 1 ( i ) − − − − ( 10.21.8 ) =\sum_{N}^{i=1}\pi_{i}b_{i}(o_{1})\beta_{1}(i)----(10.21.8) =∑Ni=1πibi(o1)β1(i)−−−−(10.21.8)
这里(10.21.4)-(10.21.5)用到了观测独立性假设
同样的继续画一张后向算法的图,感受一下上面公式的意思:
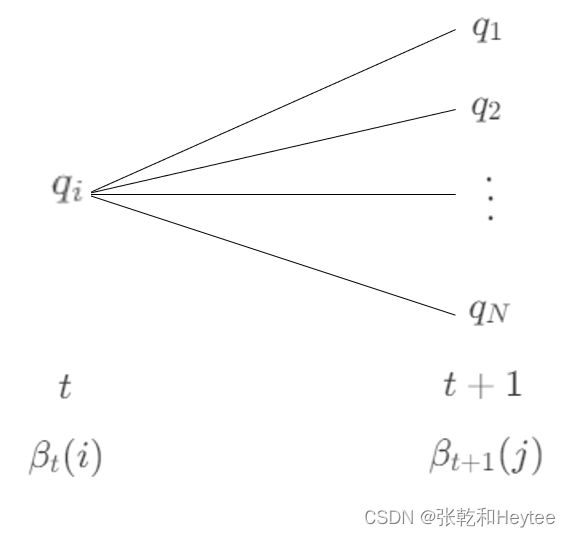
用这张图再来看一下后向算法的时间复杂度
现在你会发现后向算法是不是和前向算法一样,都是每次迭代都可以用到上一步的计算结果,使得计算大大的简化,这里后向算法的时间复杂度还是 O ( T N 2 ) O(TN^2) O(TN2),这里就不赘述了,可以参考前向算法。
10.2.3 对前向算法和后向算法的统一进行的补充
- 前向概率
P ( O ∣ λ ) = ∑ i = 1 N α T ( i ) P(O|λ) = \sum_{i=1}^{N}\alpha_{T}(i) P(O∣λ)=i=1∑NαT(i) - 后向概率
P ( O ∣ λ ) = ∑ Q i = 1 π i b i ( o 1 ) β 1 ( i ) P(O|λ) = \sum_{Q}^{i=1}\pi_{i}b_{i}(o_{1})\beta_{1}(i) P(O∣λ)=Q∑i=1πibi(o1)β1(i) - 结合
P ( O ∣ λ ) = ∑ i = 1 N ∑ j = 1 N α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) , t = 1 , 2 , ⋅ ⋅ ⋅ , T − 1 − − − − ( 10.22 ) P(O|λ) = \sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_{t}(i)a_{ij}b_{j}(o_{t+1})\beta_{t+1}(j), t = 1,2, \cdot \cdot \cdot ,T-1----(10.22) P(O∣λ)=i=1∑Nj=1∑Nαt(i)aijbj(ot+1)βt+1(j),t=1,2,⋅⋅⋅,T−1−−−−(10.22)
(10.22)推导
(1)当 t = 1 时:
P ( O ∣ λ ) − − − − ( 10.22.1.1 ) P(O|λ)----(10.22.1.1) P(O∣λ)−−−−(10.22.1.1)
= ∑ i = 1 N ∑ j = 1 N α 1 ( i ) a i j b j ( o 2 ) β 2 ( j ) − − − − ( 10.22.1.2 ) = \sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_{1}(i)a_{ij}b_{j}(o_{2})\beta_{2}(j)----(10.22.1.2) =∑i=1N∑j=1Nα1(i)aijbj(o2)β2(j)−−−−(10.22.1.2)
= ∑ i = 1 N π i β 1 ( i ) − − − − ( 10.22.1.3 ) = \sum_{i=1}^{N}\pi_{i}\beta_{1}(i)----(10.22.1.3) =∑i=1Nπiβ1(i)−−−−(10.22.1.3)
这里(10.22.1.2)-(10.22.1.3)用到了后向算法的递推公式可以直接得到,所以当 t = 1 时,这个就是后向算法。
(2)当t = T-1时:
P ( O ∣ λ ) − − − − ( 10.22.2.1 ) P(O|λ)----(10.22.2.1) P(O∣λ)−−−−(10.22.2.1)
= ∑ i = 1 N ∑ j = 1 N α T − 1 ( i ) a i j b j ( o T ) β T ( j ) − − − − ( 10.22.2.2 ) = \sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_{T-1}(i)a_{ij}b_{j}(o_{T})\beta_{T}(j)----(10.22.2.2) =∑i=1N∑j=1NαT−1(i)aijbj(oT)βT(j)−−−−(10.22.2.2)
= ∑ j = 1 N [ ∑ i = 1 N α T − 1 ( i ) a i j ] b j ( o T ) − − − − ( 10.22.2.3 ) = \sum_{j=1}^{N} \left [ \sum_{i=1}^{N}\alpha_{T-1}(i)a_{ij} \right ] b_{j}(o_{T})----(10.22.2.3) =∑j=1N[∑i=1NαT−1(i)aij]bj(oT)−−−−(10.22.2.3)
= ∑ j = 1 N α T ( j ) − − − − ( 10.22.2.4 ) = \sum_{j=1}^{N} \alpha_{T}(j)----(10.22.2.4) =∑j=1NαT(j)−−−−(10.22.2.4)
这里(10.22.2.2)-(10.22.2.3)中 β T ( j ) = 1 \beta_{T}(j) = 1 βT(j)=1,所以当 t = T - 1 时,这个就是前向算法。 - 前向-后向算法的继续推导
P ( O ∣ λ ) P(O|λ) P(O∣λ)
= ∑ i = 1 N ∑ j = 1 N α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) = \sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_{t}(i)a_{ij}b_{j}(o_{t+1})\beta_{t+1}(j) =∑i=1N∑j=1Nαt(i)aijbj(ot+1)βt+1(j)
= ∑ j = 1 N [ ∑ i = 1 N α t ( i ) a i j ] b j ( o t + 1 ) β t + 1 ( j ) = \sum_{j=1}^{N}\left[\sum_{i=1}^{N}\alpha_{t}(i)a_{ij} \right ] b_{j}(o_{t+1})\beta_{t+1}(j) =∑j=1N[∑i=1Nαt(i)aij]bj(ot+1)βt+1(j)
= ∑ j = 1 N α t + 1 ( j ) β t + 1 ( j ) = \sum_{j=1}^{N}\alpha_{t+1}(j)\beta_{t+1}(j) =∑j=1Nαt+1(j)βt+1(j)
= ∑ j = 1 N P ( O , s t = q j ∣ λ ) = \sum_{j=1}^{N}P(O,s_{t} = q_{j}|\lambda) =∑j=1NP(O,st=qj∣λ)
10.2.4 一些概率与期望值的计算
利用前向概率和后向概率,可以得到关于单个状态和两个状态概率的计算公式。
-
给定模型参数 λ 和观测O,在时刻 t 处于状态 q i q_{i} qi的概率,记
γ t ( i ) = P ( s i = q i ∣ O , λ ) = P ( s i = q i , O ∣ λ ) P ( O ∣ λ ) − − − − ( 10.23 ) \gamma_{t}(i) = P(s_{i} = q_{i}|O,\lambda) = \frac{P(s_{i} = q_{i},O|\lambda)}{P(O|\lambda)}----(10.23) γt(i)=P(si=qi∣O,λ)=P(O∣λ)P(si=qi,O∣λ)−−−−(10.23)
由前向概率和后向概率定义可知:
α t ( i ) β t ( i ) = P ( s t = q i , O ∣ λ ) \alpha_{t}(i)\beta_{t}(i) = P(s_{t} = q_{i},O|\lambda) αt(i)βt(i)=P(st=qi,O∣λ)
上面这个公式是怎么推导的呢?
(1)前向概率
α t ( i ) = P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t = q i ∣ λ ) \alpha_{t}(i) = P(o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t} = q_{i}|\lambda) αt(i)=P(o1,o2,⋅⋅⋅,ot,st=qi∣λ)
(2)后向概率
β t ( i ) = P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T ∣ s t = q i , λ ) \beta_{t}(i) = P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T}|s_{t} = q_{i},\lambda) βt(i)=P(ot+1,ot+2,⋅⋅⋅,oT∣st=qi,λ)
(3)推导
α t ( i ) β t ( i ) \alpha_{t}(i)\beta_{t}(i) αt(i)βt(i)
= P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t = q i ∣ λ ) P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T , s t = q i ∣ s t = q i , λ ) = P(o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t} = q_{i}|\lambda)P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T},s_{t} = q_{i}|s_{t} = q_{i},\lambda) =P(o1,o2,⋅⋅⋅,ot,st=qi∣λ)P(ot+1,ot+2,⋅⋅⋅,oT,st=qi∣st=qi,λ)
= P ( o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t = q i ∣ λ ) P ( o t + 1 , o t + 2 , ⋅ ⋅ ⋅ , o T , s t = q i ∣ o 1 , o 2 , ⋅ ⋅ ⋅ , o t , s t = q i , λ ) = P(o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t} = q_{i}|\lambda)P(o_{t+1},o_{t+2}, \cdot \cdot \cdot , o_{T},s_{t} = q_{i}|o_{1},o_{2}, \cdot \cdot \cdot , o_{t},s_{t} = q_{i},\lambda) =P(o1,o2,⋅⋅⋅,ot,st=qi∣λ)P(ot+1,ot+2,⋅⋅⋅,oT,st=qi∣o1,o2,⋅⋅⋅,ot,st=qi,λ)
= P ( s t = q i , o 1 , o 2 , ⋅ ⋅ ⋅ , o T ∣ λ ) = P(s_{t} = q_{i},o_{1},o_{2}, \cdot \cdot \cdot , o_{T}|\lambda) =P(st=qi,o1,o2,⋅⋅⋅,oT∣λ)
= P ( s t = q i , O ∣ λ ) = P(s_{t} = q_{i},O|\lambda) =P(st=qi,O∣λ)
最终得到:
γ t ( i ) = α t ( i ) β t ( i ) P ( O ∣ λ ) = α t ( i ) β t ( i ) ∑ j = 1 N α t ( j ) β t ( j ) − − − − ( 10.24 ) \gamma_{t}(i) = \frac{\alpha_{t}(i)\beta_{t}(i)}{P(O|\lambda)} = \frac{\alpha_{t}(i)\beta_{t}(i)}{\sum_{j=1}^{N}\alpha_{t}(j)\beta_{t}(j)}----(10.24) γt(i)=P(O∣λ)αt(i)βt(i)=∑j=1Nαt(j)βt(j)αt(i)βt(i)−−−−(10.24) -
给定模型参数 λ 和观测 O,在时刻 t 处于状态 q i q_{i} qi且在时刻 t+1 处于状态 q j q_{j} qj的概率,记
ξ t ( i , j ) = P ( s t = q i , s t + 1 = q j ∣ O , λ ) − − − − ( 10.25 ) \xi_{t}(i,j) =P(s_{t} = q_{i},s_{t+1} = q_{j}|O,\lambda)----(10.25) ξt(i,j)=P(st=qi,st+1=qj∣O,λ)−−−−(10.25)
可以通过前后向概率计算:
ξ t ( i , j ) = P ( s t = q i , s t + 1 = q j ∣ O , λ ) P ( O ∣ λ ) = P ( s t = q i , s t + 1 = q j , O ∣ λ ) ∑ i = 1 N ∑ j = 1 N P ( s t = q i , s t + 1 = q j , O ∣ λ ) \xi_{t}(i,j) = \frac{P(s_{t} = q_{i},s_{t+1} = q_{j}|O,\lambda)}{P(O|\lambda)} = \frac{P(s_{t} = q_{i},s_{t+1} = q_{j},O|\lambda)}{\sum_{i=1}^{N}\sum_{j=1}^{N}P(s_{t} = q_{i},s_{t+1} = q_{j},O|\lambda)} ξt(i,j)=P(O∣λ)P(st=qi,st+1=qj∣O,λ)=∑i=1N∑j=1NP(st=qi,st+1=qj,O∣λ)P(st=qi,st+1=qj,O∣λ)
而
P ( s t = q i , s t + 1 = q j , O ∣ λ ) = α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) P(s_{t} = q_{i},s_{t+1} = q_{j},O|\lambda) = \alpha_{t}(i)a_{ij}b_{j}(o_{t+1})\beta_{t+1}(j) P(st=qi,st+1=qj,O∣λ)=αt(i)aijbj(ot+1)βt+1(j)
所以
ξ t ( i , j ) = α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) ∑ i = 1 N ∑ j = 1 N α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) − − − − ( 10.26 ) \xi_{t}(i,j) = \frac{\alpha_{t}(i)a_{ij}b_{j}(o_{t+1})\beta_{t+1}(j)}{\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_{t}(i)a_{ij}b_{j}(o_{t+1})\beta_{t+1}(j)}----(10.26) ξt(i,j)=∑i=1N∑j=1Nαt(i)aijbj(ot+1)βt+1(j)αt(i)aijbj(ot+1)βt+1(j)−−−−(10.26) -
将 γ t ( i ) \gamma_{t}(i) γt(i)和 ξ t ( i , j ) \xi_{t}(i,j) ξt(i,j)对各个时刻 t 求和,可以得到一些有用的期望值。
(1)在观测 O 下状态 i 出现的期望值:
∑ t = 1 T γ t ( i ) − − − − ( 10.27 ) \sum_{t=1}^{T}\gamma_{t}(i)----(10.27) t=1∑Tγt(i)−−−−(10.27)
(2)在观测 O 下状态 i 转移的期望值:
∑ t = 1 T − 1 γ t ( i ) − − − − ( 10.28 ) \sum_{t=1}^{T-1}\gamma_{t}(i)----(10.28) t=1∑T−1γt(i)−−−−(10.28)
(3)在观测 O 下由状态 i 转移到状态 j 的期望值:
∑ t = 1 T − 1 ξ t ( i , j ) − − − − ( 10.29 ) \sum_{t=1}^{T-1}\xi_{t}(i,j)----(10.29) t=1∑T−1ξt(i,j)−−−−(10.29)
参考文献
以下是HMM系列文章的参考文献:
- 李航——《统计学习方法》
- YouTube——shuhuai008的视频课程HMM
- YouTube——徐亦达机器学习HMM、EM
- *[https://www.huaxiaozhuan.com/%E7%BB%9F%E8%AE%A1%E5%AD%A6%E4%B9%A0/chapters/15_HMM.html]:隐马尔可夫模型
- [https://sm1les.com/2019/04/10/hidden-markov-model/]:隐马尔可夫模型(HMM)及其三个基本问题
- 例子可以看这个[https://www.cnblogs.com/skyme/p/4651331.html]:一文搞懂HMM(隐马尔可夫模型)
- [https://www.zhihu.com/question/55974064]:南屏晚钟的解答
感谢以上作者对本文的贡献,如有侵权联系后删除相应内容。