机器学习(十):机器学习训练速度的提升技巧
这是一篇机器学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:机器学习初学者,转AI的开发人员。
编程语言:Python
操作系统:Windows
机器学习中最耗时也是最核心的两个阶段,一个就是特征工程,另一个就是训练过程了,训练过程,少则几个小时,多则几天,这个总是会占用不少时间,如果赶在向领导汇报或者业务方需要结果的是,这个真的是时间就是金钱。
我在机器学习过程中一直使用的scikit-learn包(简称sklearn),外加xgboost算法包,对于前者没有gpu的支持,后者所幸有gpu的支持,下面会介绍一下训练过程中提升速度的几个技巧(这里不讨论深度学习方面的训练速度提升问题,毕竟自己没有实测过深度学习的不同框架等的性能对比):
找到合适的训练的数据量及算法
训练集的数据量是最直接决定训练速度的因素,再者不同的算法,性能(速度这一方面)也表现的各不相同:
数据量——学习曲线
在数据充足的情况下,如何选择用多少数据量的训练集呢?比如我有100万条样本,以9:1划分训练集、测试集,总不能直接将90w条数据直接塞进训练集进行训练(如果你机器有几百个cpu,并且能多线程并行化处理,完全可以忽略这个),而且,你的指标(比如accuracy)会在某个数据量出现平稳,之后不会再提升,比如20w数据量的时候,这时,增加训练样本量,实在没有什么改善。
如何来找到这个合适的数据量呢?借助学习曲线(Learning curve),学习曲线是随着训练样本的逐渐增多,算法训练出的模型的表现能力(即各种指标、accuracy\recall\auc等)的变化曲线图,学习曲线经常用来判断模型是否存在过拟合、欠拟合的情况,在我的使用过程中,我经常用它来决定训练集的数据量,学习曲线会在后面的篇章详细介绍,并给出代码示例。
算法
其实回顾机器学习的发展史,就可以明显看出不同算法在性能上是有优劣之分的(可参照深度学习之前:机器学习简史),这里以分类算法为例,一般情况下,几万到几十万左右的训练量,xgboost是优于svm,svm是优于逻辑回归的(自己项目中亲测,无论训练速度还是指标得分上),尤其是xgboost相比与svm,在10-20w左右的训练量的时候,采用5折交叉验证,时间将近减少了一半,想想这也是为什么keras作者在机器学习领域,极力推崇xgboost的原因了。
CPU与GPU
GPU与CPU比较
CPU是一个有多种功能的优秀领导者。它的优点在于调度、管理、协调能力强,计算能力则位于其次。而GPU相当于一个接受CPU调度的“拥有大量计算能力”的员工。
当需要对大数据bigdata做同样的事情时,GPU更合适,当需要对同一数据做很多事情时,CPU正好合适。
sklearn的多CPU训练
很可惜,sklearn没有提供GPU支持,这是官网给出的官方回答,毕竟与深度学习相比,按照机器学习的处理任务,机器学习一般处理数据量不是特别多的结构化数据,似乎也没有必要提供GPU支持。
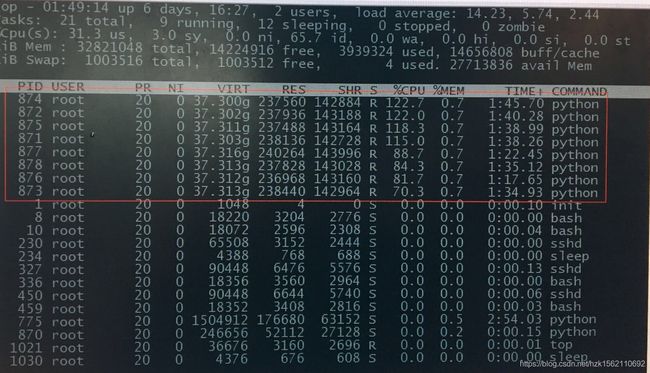
那么提升sklearn训练速度的核心在于什么?如何使用多个\多核cpu,网格搜索给出了API,指定n_jobs参数:
n_jobs指定了训练时的并行数
● int:个数
● -1:跟CPU核数一致
★ 1:默认值
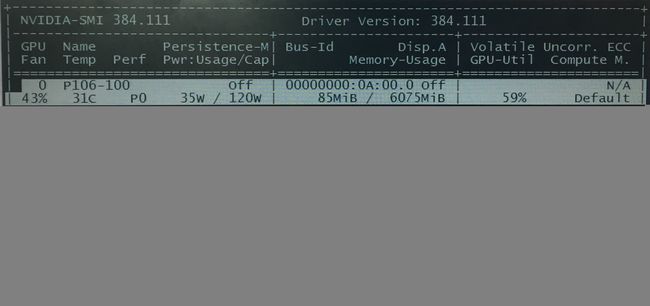
所以在,训练的时候,指定n_jobs个数或者直接赋值-1,cpu的使用情况在linux下可以通过top命令查看(8核cpu的情况):
xgboost的GPU支持
xgboost属于机器学习算法,是独立于sklearn机器学习包的,即便是cpu版本,xgboost也表现出了良好的性能,为了更大程度上提高训练速度,可以使用xgboost的gpu版本,下面通过anaconda来使用xgboost-gpu:
xgboost-gpu安装
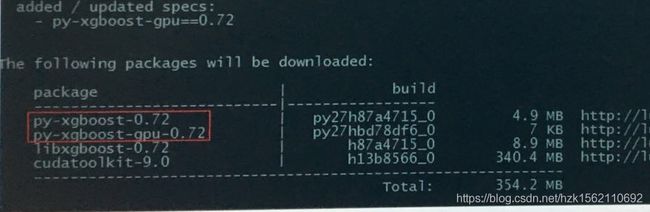
#anaconda安装xgboost的gpu版本
conda install py-xgbost-gpu
安装过程中会发现,先安装xgboost和gpu的驱动,再安装xgboost-gpu:
xgboost-gpu使用
xgboost-gpu支持
贴一下自己在使用中的代码,核心在于指定tree_method参数,tree_method=‘gpu_hist’:
cv=StratifiedKFold(n_splits=5,shuffle=True,random_state=7)
clf = GridSearchCV(estimator=XGBClassifier(
learning_rate=0.1,
n_estimators=1000,
max_depth=3,
min_child_weight=1,
gamma=0.5,
subsample=0.6,
objective='binary:logistic',
nthread=4,
scale_pos_weiht=1,
seed=27,
tree_method='gpu_hist' #使用gpu
),
param_grid=param_test,
cv=cv,
scoring='accuracy',
n_jobs=-1 #使用所有gpu)
linux下可以通过nvidia-smi查看gpu使用情况(确定先安装gpu驱动):