文本向量化-计算文本相似的的方法-基于python语言的实现
本节主要讨论三种方法实现中文文本的向量化,编程环境python3.6.
- TF 词频的方法
- TFIDF 词频-逆文档频率
- Word2Vec
第一种TF方式,即是基于词频的方式,举一个最简单的例子:
1:今天天气不错!
2:今天天气很好。针对英文,我们可以直接跑程序,计算文本向量,英文单词都是以空格分割好的,但是对于中文,我们需要进行如下的几个处理步骤,分词、去停用词(使用在word2vec里,不然对于标点符号、少见的字符,会报word ‘x’not in vocabulary)、然后才到文本向量化,结果输出
我们先来看一下分词代码,分词调用的是结巴分词工具,根据最后机器学习模型,接收的文本参数是一个个独立的词。上代码,这个是定义的分词的函数。
#结巴分词,切开之后,有分隔符
def jieba_function(sent):
import jieba
sent1 = jieba.cut(sent)
s = []
for each in sent1:
s.append(each)
return ' '.join(str(i) for i in s)本文对于文本相似度采用余弦相似度计算,余弦相似度在论坛上有很多介绍,同样也可以用来计算向量之间的余弦相似度,给出计算余弦相似度的函数,直接调用就好
def count_cos_similarity(vec_1, vec_2):
if len(vec_1) != len(vec_2):
return 0
s = sum(vec_1[i] * vec_2[i] for i in range(len(vec_2)))
den1 = math.sqrt(sum([pow(number, 2) for number in vec_1]))
den2 = math.sqrt(sum([pow(number, 2) for number in vec_2]))
return s / (den1 * den2)接下来给出TF模型的代码:
#计算文本向量,传入文本,接受的是字符串
def tf(sent1, sent2):
from sklearn.feature_extraction.text import CountVectorizer
sent1 = jieba_function(sent1)
sent2 = jieba_function(sent2)
#:Convert a collection of text documents to a matrix of token counts(计算词汇的数量)
# http: // blog.csdn.net / mmc2015 / article / details / 46866537 对于参数不了解的话,可以看这个博客内容介绍的比较详细。
count_vec = CountVectorizer()
sentences = [sent1, sent2]
print(count_vec.fit_transform(sentences).toarray())## 输出特征向量化后的表示
print(count_vec.get_feature_names())#输出的是切分的词, 输出向量各个维度的特征含义
#转换成维度相同的
vec_1 = count_vec.fit_transform(sentences).toarray()[0]
vec_2 = count_vec.fit_transform(sentences).toarray()[1]
print(len(vec_1), len(vec_2))
print(count_cos_similarity(vec_1, vec_2))传进去的参数是,
1. sent1 = 我喜欢看电视,也喜欢看电影,
2. sent2 = 我不喜欢看电视,也不喜欢看电影
,输出的模型结果:

对于TFIDF针对TF不同之处,引入了逆文档频率,因此在导入函数时引入的是TfidfVectorizer,从代码上比较直观的看出区别,整体的思路完全一致。
def tfidf(sent1, sent2):
from sklearn.feature_extraction.text import TfidfVectorizer
sent1 = jieba_function(sent1)
sent2 = jieba_function(sent2)
tfidf_vec = TfidfVectorizer()
sentences = [sent1, sent2]
print(tfidf_vec.fit_transform(sentences).toarray())
print(tfidf_vec.get_feature_names())
vec_1 = tfidf_vec.fit_transform(sentences).toarray()[0]
vec_2 = tfidf_vec.fit_transform(sentences).toarray()[1]
print(count_cos_similarity(vec_1, vec_2))
输出的结果在这里:
第三钟方法,在开始的时候有介绍,因为在前期的预处理时候,需要多加一步去停用词,因此我们再这里对前面写的分词函数做一下 稍微的改动,依然可以复用原来的函数,但是比较尴尬的是,word2vec和以上两种方法,又存在着细节的不同,word2vec模型接受的是参数是字符串列表,而前两者接受的是字符串数据,因此在定义的jieba_function()函数时,我们直接返回列表s就好了,这是一个小小的不同。
最后附上最后的代码:
def word2vec1(sent1,sent2):
import gensim
def jieba_fun(sent):
import jieba
stopword = r"C:\Users\zss0330816\Desktop\stopwords.txt"#给停用词的路径
file = open(stopword, 'r', encoding='utf-8')
data = file.read()
sent1 = jieba.cut(sent)
s = []
for each in sent1:
#打开文件,对文本去停用词
if each not in data:
s.append(each)
file.close()
return s
sent1 = jieba_fun(sent1)
sent2 = jieba_fun(sent2)
#加载模型
model = gensim.models.Word2Vec.load(r'D:\study_on_w2v\data\zhwiki_model\word2vec_gensim')
try:
return model.n_similarity(sent1, sent2)
except Exception as e:
print(e)最后输出的模型结果如下:
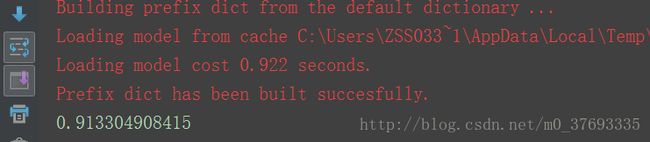
这两句,随便写的字,
1. sent1 = 我喜欢看电视,也喜欢看电影,你觉得尼
2. sent2 = 我不喜欢看电视,也不喜欢看电影,你感觉如何
其实在我们主观的感觉是,差别其实还是蛮大,我们看出余弦相似度值是word2vec>TF>TFIDF的值,word2vec最高,达到了0.91基本上可以认为两者含义一样了,但是此句确是完全表达的是相反的含义,这主要是因为模型本身对算法的设置,这个我不在这里详细讲解,关于word2vec的核心架构CBOW和Skip-gram,网上有很多具体的讲解,希望大家主动研究学习。TF就是通过词语的相似度,先找出文档中所有的词语,也就是维度,然后根据出现的次数,得到这个向量,来判断这二者之间的程度,以及TFIDF,他们都忽略了深层的语义信息,而只有表层的统计学含义,因此在计算上结果会存在误差,如果把上面这一句话改一下,如下:
sent1 = 我喜欢看电视,不喜欢看电影,
sent2 = 我不喜欢看电视,喜欢看电影以TF计算,余弦相似度必然为1,但是表达含义确实有区别,但是目前确实没有一个完美的算法解决所有的难题。
希望大家一起交流多发现问题把