Token裁剪总结
Transformer在处理大图片的时候,由于其二次复杂度,在token数目过多的情况下效率会很低,所以一些研究者开始尝试做Token裁剪工作,这里做一下总结。
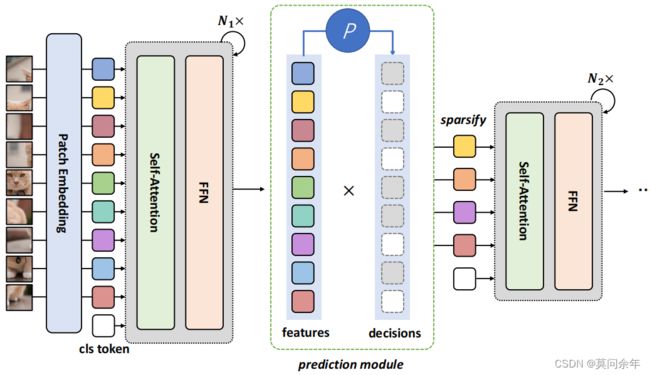
DynamicViT
paper:https://arxiv.org/abs/2106.02034
核心思想是通过一个小的网络结构,根据输入生成各个token保留或丢弃的概率,然后利用Gumbel-Softmax采样概率,进行端到端训练,为了保证在裁剪的时候减少精度掉点,使用教师网络进行监督学习。核心结构如下:
EViT
paper https://arxiv.org/abs/2208.14657
ViT在最终分类时只使用class token,class token同其余token关系如下:
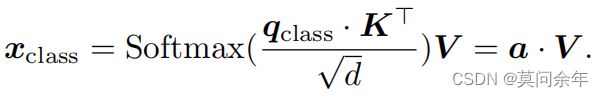
class token其实就是各个token的线性组合,所以可以使用其作为判断其余token重要性的指标。本文立足与此,在每个阶段使用class token筛选topk个token进行保留,余下的token直接丢弃,并且为了防止丢弃过量信息,将所有丢弃的token加权生成新的token进行后续操作。核心结构如下:
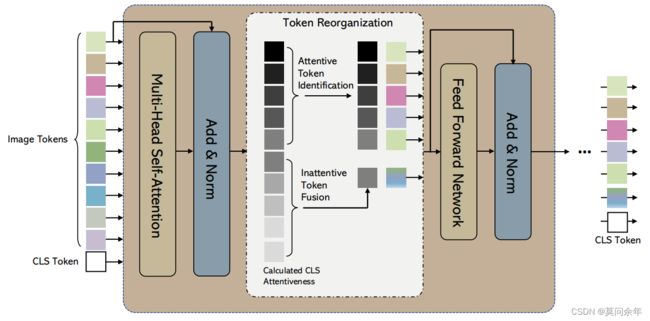
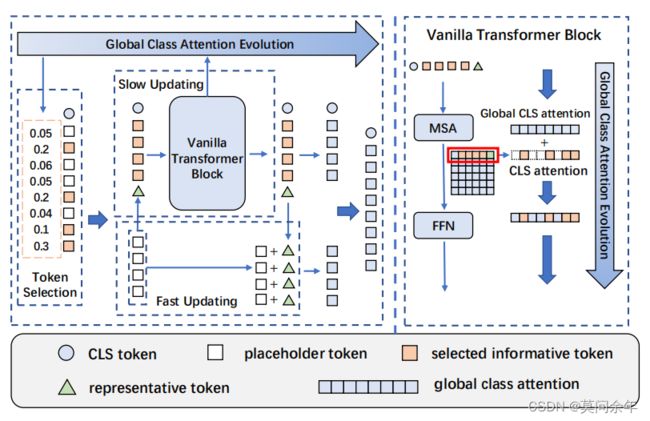
Evo-ViT
paper https://arxiv.org/abs/2108.01390
这篇论文同上一篇EViT类似,都是采样class token来区分token重要性,不同之处在于使用了全局注意力,更新方式如下:
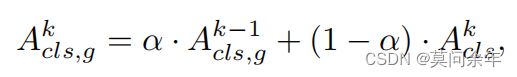
并且为了防止丢弃token后破坏图片空间结构,本文并没有直接丢弃所有不重要token,而是对重要token和不重要token分别进行慢快更新。核心结构如下:
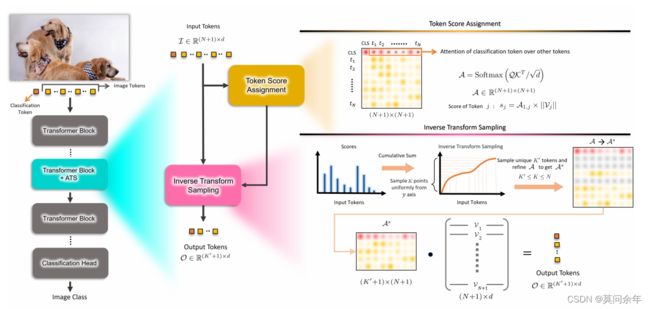
ATS
paper https://arxiv.org/abs/2111.15667
这篇文章也是使用class token来评价token重要性,与前几篇文章的不同在于不是直接选取topk个token,而是使用累积分布函数进行采样,这样可以避免在前期网络不稳定导致重要的token被丢弃的情况,同时也能够针对不同输入得到不同数目的token。核心思想如下:
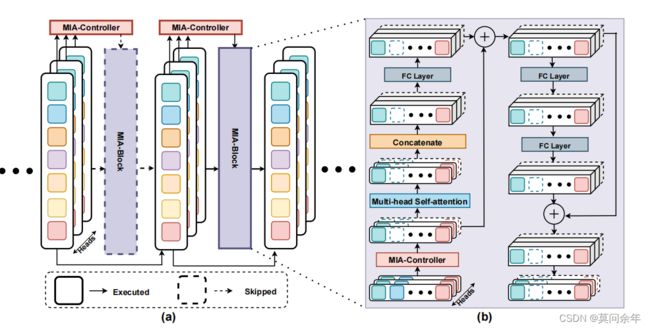
MIA-Former
paper https://arxiv.org/abs/2112.11542
这篇文章从block数量、head数量、token数量三个方面减少ViT的计算量,通过一个MIA-Controller来决定是否跳过该block,如果不跳过该block的话再对head和token实行掩码操作来决定head和token是否被保留,还引入了强化学习进一步优化网络。核心结构如下:
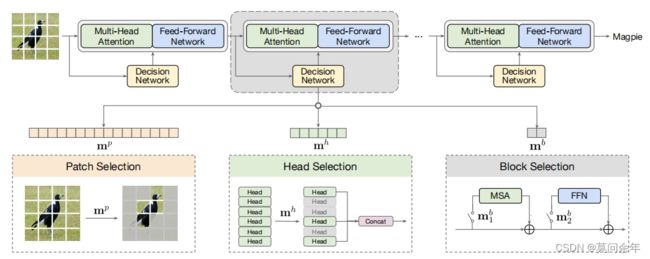
Ada-ViT
paper https://arxiv.org/abs/2111.15668
这篇文章也是从block、head、token三方面入手,通过去除冗余加快模型运算,对block、head、token分别使用二进制掩码来判断保留还是丢弃。核心结构如下:
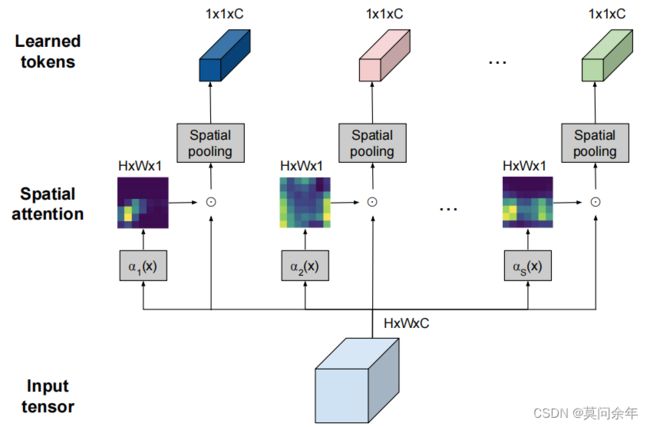
TokenLearner
paper https://arxiv.org/abs/2106.11297
本文同上面那些根据重要性分数决定token重要性的方法不同,对于输入使用若干个(文章选择8个)函数得到相应的空间注意力图,再将这些空间注意力图同输入相乘并且做空间池化,会得到一系列代表token,对这些token做后续操作,文中还提出了一个TokenFuser的结构,用于将8个token转换成原始数目的token。核心结构如下:
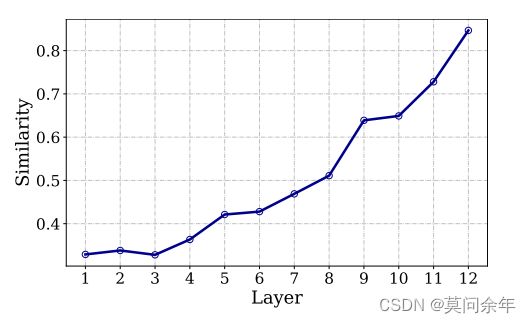
Patch Slimming
paper https://arxiv.org/abs/2106.02852
作者通过观察不同深度block中token的相似性,得出越深层次block的token相似度越高的结论,图示如下:
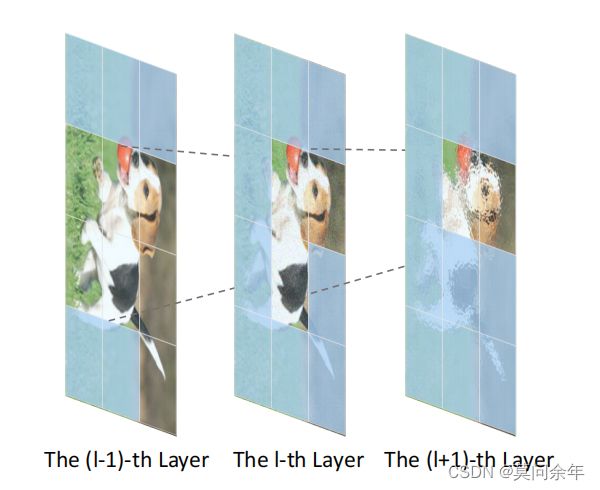
所以作者使用自深向浅的token裁剪方法,具体来说,就是在后一层根据重要性裁剪掉大部分token,为了保证信息流的传递,前一层要包含后一层保留的对应token信息,一直不断迭代,直到首层。核心思想如下:
还有一些比较有代表性的工作:
Self-slimmed Vision Transformer:https://arxiv.org/abs/2111.12624
PS-ViT:https://arxiv.org/abs/2108.03428
A-ViT:https://arxiv.org/abs/2112.07658
此外,还有一些8、9月份新发表在arXiv上的论文,各位同学感兴趣的话可以读一下,论文题目如下:
Number of Attention Heads vs. Number of Transformer-Encoders in Computer Vision
PatchDropout: Economizing Vision Transformers Using Patch Dropout
Accelerating Vision Transformer Training via a Patch Sampling Schedule
CLUSTR: EXPLORING EFFICIENT SELF-ATTENTION VIA CLUSTERING FOR VISION TRANSFORMERS
以上。