基于深度学习的医学图像分析(一)
译者简介:ASCE1885, 《Android 高级进阶》作者。 原文链接:https://medium.com/@taposhdr/medical-image-analysis-with-deep-learning-i-23d518abf531

基于深度学习技术对图像和视频进行分析,并将其应用到自动驾驶,无人机等各种领域中,已经成为新的研究前沿。最近的一篇研究论文 “A Neural Algorithm of Artistic Style”(https://arxiv.org/abs/1508.06576),展示了如何将一个艺术家的风格经过转换后,应用到一张图像中,从而生成一张具备这个风格的新的图像。其他的论文例如 “Generative Adversarial Networks”(GAN,生成式对抗网络,https://arxiv.org/abs/1406.2661) 和 “Wasserstein GAN”(https://arxiv.org/pdf/1701.07875) 为我们开发能够基于输入数据自我学习创造新数据的模型铺平了道路。从而开启了半监督学习的时代并为未来的无监督学习铺平道路。
这些研究领域着重点仍然在通用图像上,而我们的目标是将这些研究成果应用到医学图像中,以帮助医疗保健行业。我们会从基础知识开始介绍。本文首先以图像处理的基础知识为切入点,接着介绍医学图像数据格式,最后以可视化的方式对医学数据进行展示。在下一篇文章,我们将深入介绍一些卷积神经网络算法并使用 Keras(https://keras.io/) 来预测肺癌。
图像处理基础(基于 Python)
虽然有很多图像处理函数库,但 OpenCV(open computer vision,https://opencv.org/)以其庞大的社区支持和对 C++,Java 和 Python 的可用性支持,已然成为主流的选择。我个人喜欢在 Jupyter notebook(http://jupyter.org/index.html)中使用 OpenCV。
OpenCV 的安装有两种方式:
命令行中执行命令:
pip install opencv-python从 opencv.org 下载源码进行安装

现在打开 Jupyter notebook 并确定你导入了 cv2 函数库,同时你还需要导入 numpy 和 matplotlib 函数库从而在 Jupyter 中可以看到绘制出来的图像。

接着使用下面的代码,让我们来看看在 Jupyter 中是否可以打开一张图片并显示它。

基本的人脸检测
接下来让我们做一些有趣的实验,例如人脸检测。人脸检测中我们将使用一个开源的 xml stump-based 20x20 的 gentle adaboost 正脸检测器,它是由 Rainer Lienhart 所创建的。关于 Haar 级联检测的细节可以参见这篇文章:https://docs.opencv.org/trunk/d7/d8b/tutorialpyface_detection.html。
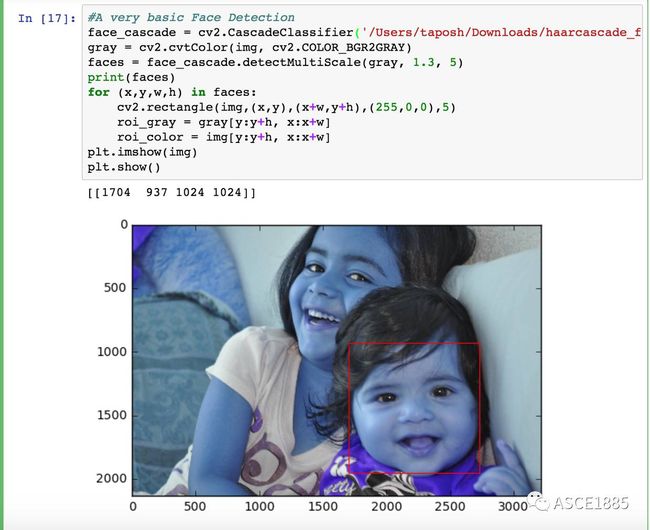
关于更多使用 OpenCV 进行图像处理的例子可以参见这份文档:http://docs.opencv.org/trunk/d6/d00/tutorialpyroot.html。读者可以自己尝试其他的例子。现在我们已经了解基本的图像处理,接下来我们来认识下医学图像数据格式。
医学图像数据格式
医学图像遵循医学数字成像和通信(DICOM)标准(https://en.wikipedia.org/wiki/DICOM),实现图像数据的存储和交换。该标准的第一个版本发布于 1985 年,从那以后经历了几次改进,这个标准使用了自定义的文件格式和通信协议。
文件格式:所有患者的医学图像都以 DICOM 文件格式进行存储。这个格式包含关于患者的 PHI(protected health information,https://en.wikipedia.org/wiki/Protectedhealthinformation)信息,例如姓名,性别,年龄,以及其他图像相关信息比如捕获并生成图像的设备信息,医疗的一些上下文相关信息等。医学图像设备生成 DICOM 文件,医生使用 DICOM 阅读器(能够显示 DICOM 图像的计算机软件)阅读并对图像中发现的问题进行诊断。
通信协议:DICOM 通信协议用于检索存档中的包含检查信息的图像数据,并将这个数据还原到工作站上予以显示。所有连接到医院网络中的医学图像应用都使用 DICOM 协议来进行信息的交换,这些信息大部分是 DICOM 图像数据,当然也会包含一些患者和流程相关的信息。DICOM 通信协议还包含更高级的网络命令,可以用来控制和跟踪治疗,调度流程,报告状态和分担医生和影像设备之间的工作量。
关于 DICOM 标准细节可以参见这个博客:http://dicomiseasy.blogspot.com/。
解析 DICOM 文件
pydicom(https://pypi.python.org/pypi/pydicom) 是一个用来解析 DICOM 图像的很棒的 python 函数库。本节我们来看看如何利用它在 Jupyter notebook 中渲染 DICOM 图像。
使用命令 pip install pydicom 安装 pydicom,安装完成后,打开 Jupyter notebook,如下代码所示导入 dicom 函数库和其他需要的一些函数库:
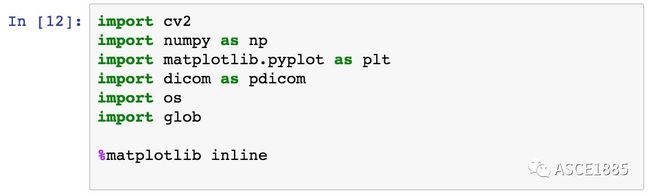
We also use other packages such as pandas, scipy, skimage, mpl_toolkit for data processing and analysis.
同时我们也需要用到像 pandas,scipy,skimage,mpl_toolkit 等函数库来进行数据的处理和解析。

网上有大量免费可用的 DICOM 数据集,但这里有一些可以帮助你入门的数据集:
Kaggle 竞赛和数据集(https://www.kaggle.com/):我个人的最爱,从这里(https://www.kaggle.com/c/data-science-bowl-2017/data)可以获取肺癌和糖尿病视网膜病变竞赛的数据集。
DICOM Library(https://www.dicomlibrary.com/):免费的在线医学 DICOM 图像和视频文件共享服务,为了教育和科研目的。
Osirix 数据集(http://www.osirix-viewer.com/resources/dicom-image-library/):通过多种成像方式提供大量的人体 DICOM 图像数据集。
可视化人体数据集(https://mri.radiology.uiowa.edu/visiblehumandatasets.html):作为可视化人体项目(http://www.nlm.nih.gov/research/visible/visiblehuman.html)的一部分,这个地址的数据集可以自由下载和发布,这点显得有点奇怪,因为整个可视化人体项目的数据获取不是免费的,而且也很麻烦,详情可以参见这里:https://www.nlm.nih.gov/research/visible/gettingdata.html。
The Zubal Phantom(http://noodle.med.yale.edu/zubal/):这个网站提供了两个人类男性关于 CT 和 MRI 的多个数据集,这些数据是可以自由下载和发布的。
从上面这些地方可以下载 DICOM 文件,下载完成后可以使用 jupyter notebook 进行加载,代码如下所示:

接着将 DICOM 图像加载进一个列表中:
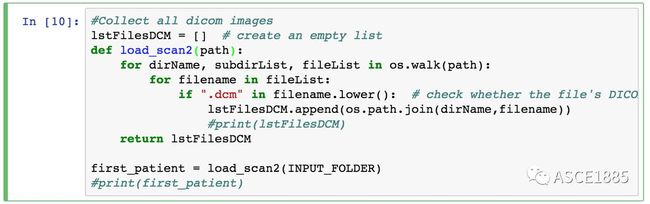
步骤一:在 Jupyter 中进行 DICOM 图像的基本阅读

第一行代码我们加载数组中第一张 DICOM 文件,并将其引用保存在变量 RefDs 中,进而利用它获取元数据,它的文件名位于 lstFilesDCM 列表的开头。

我们接着沿着 x,y 和 z 笛卡尔坐标轴计算三维 NumPy 数组的总尺寸,等于:(一张切片中像素行的数量)x (一张切片中像素列的数量)x(切片的数量)。最后使用 DICOM 文件中的 PixelSpacing 和 SliceThickness 属性计算三个坐标轴中像素的间距(spacing)。我们将数组的尺寸存放在 ConstPixelDims 变量中,将像素间距存放在 ConstPixelSpacing 中。
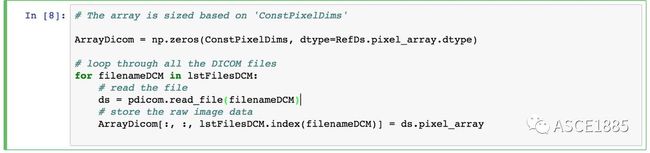
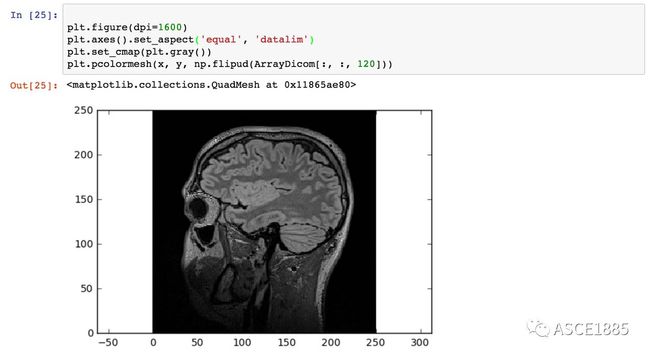

步骤二:深入 DICOM 文件格式的细节
CT 扫描中的测量单位是亨氏单位(Hounsfield Unit,HU),它是用来衡量放射密度的。为了得到精确的测量结果,CT 扫描仪需要经过严格的校准。关于 CT 扫描测量的细节内容可以在这里找到:https://web.archive.org/web/20070926231241/http://www.intl.elsevierhealth.com/e-books/pdf/940.pdf。
每一个像素都被赋予了一个数值(CT 值),它是包含在相应体素(voxel)中的所有衰减值的平均值。这个数字是和水的衰减值相比较得到的,并按比例进行显示,单位是 Hounsfield units(HU),为纪念亨斯菲尔德爵士,以他的名字命名。
这个测量方式将水的衰减值设定为零(HU)。CT 取值范围一般是 2000 HU,虽然一些现代扫描仪有更大的范围能达到 4000 HU。每个数值代表一种灰度阴影,这个光谱的两端分别是 +1000(白色)和 -1000(黑色)。
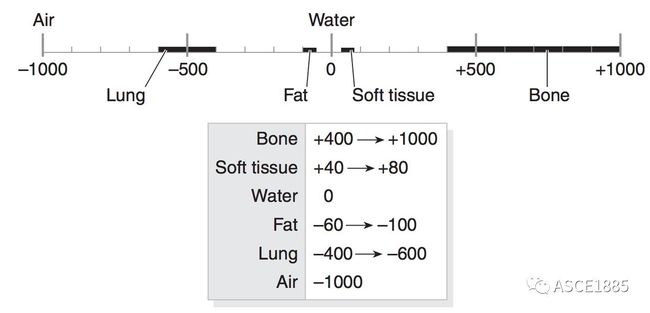
有些扫描仪有柱面扫描边界,但输出的图像是正方形的。在这些边界之外的像素将被设置为固定的值 -2000。

第一步通常是将这些值设置为 0。接下来,把这些值乘以重新调节过的斜率,再加上截距(通常方便的存储在扫描得到的元数据中),就得到以 HU 为单位的取值。
在下一篇文章中,我们将使用 Kaggle 的肺癌数据集和并使用 Keras 提供的卷积神经网络。我们将在本文介绍的知识基础上进行下一篇文章的讲解。