PRML读书会第五期——概率图模型(Graphical Models)【上】
PRML读书会第五期——概率图模型(Graphical Models)
前言
本人系浙江大学人工智能协会(ZJUAI)会员。本学期协会正在举办PRML读书会系列活动,笔者在活动中负责部分记录工作。
下文为本人关于概率图模型的相关整理,内容涵盖PRML书本内容、B站知名人工智能白板推导系列对应的概率图模型部分、读书会内容及本人的一些思考。
参考内容包括但不限于:
- Pattern Recognition and Machine Learning英文原版及民间翻译版
- 机器学习-白板推导系列(九)-概率图模型基础及评论区热心小伙伴提供的字迹工整的笔记
- Hammersley-Clifford定理证明及评论区热心网友对其作者的两个疑惑一针见血的解答
- PRML读书会中学长提纲挈领的分享
由于本人高中毕业不久,相关知识储备并不丰富,加上本人专业方向为CS,AI作为本人额外的兴趣爱好,难免会有纰漏,还望懂行的大佬在评论区批评指正,即时遏制错误信息在网路上传播。
笔者尝试扮演了南瓜书的角色,对几乎所有核心公式尽可能详细的推导,相信任何一个念过小学三年级的人(学过乘法分配律)只要有足够的耐心都可以看懂文中的绝大部分运算(当然大佬们请尽情跳过啰嗦的中间步骤)。此外,本文涵盖了初学者能够接触到的几乎全部的概率图模型的知识,如果您对概率图模型抑或是人工智能感兴趣的话,相信您一定可以从本文中获得新的灵感。
通过这些大型公式的演算,本人对 ∑ \sum ∑运算有了新的认识。如果您正苦于线性代数的折磨,不妨从这个角度切入,锻炼自己的运算能力。
如果您觉得量太大无法一口气全部看完,可以按Ctrl+D进行收藏,以便在看完以后移出收藏夹,这样我就不会获得收藏数的提升,还能排除骗赞骗收藏的嫌疑。
如果您觉得从中收获到了些许知识,也请您不要吝啬将知识分享出去。也恳求各位自动整合网站的站长把原文链接放到更显眼的位置上,某些被自动转载的文章在搜索引擎中的排序已经跑到原文的前面去了。
为了更好的阅读体验,建议不熟悉联合概率分布的读者先浏览一下百度百科中的相关基本概念。
注:由于CSDN限制文章字数在3w字以下,故本文将分三个部分发出。
后文传送门:
PRML读书会第五期——概率图模型(Graphical Models)【中】
PRML读书会第五期——概率图模型(Graphical Models)【下】
问题的提出
概率论的基本规则
研究对象
高维随机变量: x ⃗ = ( x 1 , x 2 , ⋯ , x p ) \vec x=(x_1,x_2,\cdots,x_p) x=(x1,x2,⋯,xp),下文记作 X X X(其中p为随机变量的维数)
基本记号
联合概率密度: p ( x 1 , x 2 , ⋯ , x p ) p(x_1,x_2,\cdots,x_p) p(x1,x2,⋯,xp)(下文简称联合概率)
边缘概率: p ( x i ) p(x_i) p(xi)
条件概率: p ( x j ∣ x i ) p(x_j|x_i) p(xj∣xi)
基本规则
- Sum Rule: p ( x 1 ) = ∫ p ( x 1 , x 2 ) d x 2 p(x_1)=\int p(x_1,x_2)dx_2 p(x1)=∫p(x1,x2)dx2
对于离散变量,只需用求和替代积分即可;下文默认采用积分符号
- Product Rule: p ( x 1 , x 2 ) = p ( x 1 ) p ( x 2 ∣ x 1 ) = p ( x 2 ) p ( x 1 ∣ x 2 ) p(x_1,x_2)=p(x_1)p(x_2|x_1)=p(x_2)p(x_1|x_2) p(x1,x2)=p(x1)p(x2∣x1)=p(x2)p(x1∣x2)
- Chain Rule: p ( x 1 , x 2 , ⋯ , x p ) = ∏ i = 1 p p ( x i ∣ x 1 , ⋯ , x i − 1 ) p(x_1,x_2,\cdots,x_p)=\prod\limits_{i=1}^pp(x_i|x_1,\cdots,x_{i-1}) p(x1,x2,⋯,xp)=i=1∏pp(xi∣x1,⋯,xi−1)
- Bayesian Rule: p ( x 2 ∣ x 1 ) = p ( x 1 , x 2 ) p ( x 1 ) = p ( x 2 ) p ( x 1 ∣ x 2 ) ∫ p ( x 1 , x 2 ) d x 2 = p ( x 2 ) p ( x 1 ∣ x 2 ) ∫ p ( x 2 ) p ( x 1 ∣ x 2 ) d x 2 p(x_2|x_1)=\dfrac{p(x_1,x_2)}{p(x_1)}=\dfrac{p(x_2)p(x_1|x_2)}{\int p(x_1,x_2)dx_2}=\dfrac{p(x_2)p(x_1|x_2)}{\int p(x_2)p(x_1|x_2)dx_2} p(x2∣x1)=p(x1)p(x1,x2)=∫p(x1,x2)dx2p(x2)p(x1∣x2)=∫p(x2)p(x1∣x2)dx2p(x2)p(x1∣x2)
注:
四条法则内在的逻辑关系:加法法则与乘法法则为基本法则,链式法则为乘法法则高维形式的推广,贝叶斯法则为反复利用加法法则与乘法法则求后验概率
链式法则的推导:
法一:从后向前
记 x 1 , x 2 , ⋯ , x p − 1 x_1,x_2,\cdots,x_{p-1} x1,x2,⋯,xp−1为 X ∖ x p X\setminus x_p X∖xp,将 X ∖ x p X\setminus x_p X∖xp看作 x 1 x_1 x1, x p x_p xp看作 x 2 x_2 x2,利用乘法法则得:
p ( X ∖ x p , x p ) = p ( X ∖ x p ) p ( x p ∣ X ∖ x p ) = p ( x 1 , x 2 , … , x p − 1 ) p ( x p ∣ x 1 , x 2 , … , x p − 1 ) p(X\setminus x_p,x_p)=p(X\setminus x_p)p(x_p|X\setminus x_p)=p(x_1,x_2,\dots,x_{p-1})p(x_p|x_1,x_2,\dots,x_{p-1}) p(X∖xp,xp)=p(X∖xp)p(xp∣X∖xp)=p(x1,x2,…,xp−1)p(xp∣x1,x2,…,xp−1)
对于联合概率 p ( x 1 , x 2 , ⋯ , x p − 1 ) p(x_1,x_2,\cdots,x_{p-1}) p(x1,x2,⋯,xp−1),重复上述操作,向前递推即可。*本文所有形如 X ∖ x p X\setminus x_p X∖xp的记号含义与 X ∖ { x p } X\setminus \{x_p\} X∖{xp}一致
法二:从前向后
从条件概率的本质出发:在已有变量的条件下的概率。
这样,我们先考虑 x 1 x_1 x1,概率为 p ( x 1 ) p(x_1) p(x1);在此基础上,我们再考虑 x 2 x_2 x2,由于此时处于已有 x 1 x_1 x1的条件下,故概率为 p ( x 2 ∣ x 1 ) p(x_2|x_1) p(x2∣x1);利用乘法法则将两步操作连接起来,即有 p ( x 1 , x 2 ) = p ( x 1 ) p ( x 2 ∣ x 1 ) p(x_1,x_2)=p(x_1)p(x_2|x_1) p(x1,x2)=p(x1)p(x2∣x1).按同样的方式依次考察剩余的变量,即得:
p ( x 1 , x 2 , … , x p ) = p ( x 1 ) p ( x 2 ∣ x 1 ) p ( x 3 ∣ x 1 , x 2 ) … p ( x p ∣ x 1 , x 2 , … , x p − 1 ) = ∏ i = 1 p p ( x i ∣ x 1 , … , x i − 1 ) p(x_1,x_2,\dots,x_p)=p(x_1)p(x_2|x_1)p(x_3|x_1,x_2)\dots p(x_p|x_1,x_2,\dots,x_{p-1})=\prod\limits_{i=1}^pp(x_i|x_1,\dots,x_{i-1}) p(x1,x2,…,xp)=p(x1)p(x2∣x1)p(x3∣x1,x2)…p(xp∣x1,x2,…,xp−1)=i=1∏pp(xi∣x1,…,xi−1)
特别的,当 i = 1 i=1 i=1时, p ( x 1 ∣ ϕ ) ≜ p ( x 1 ) p(x_1|\phi)\triangleq p(x_1) p(x1∣ϕ)≜p(x1)
困境与模型简化
以计算联合概率为例,我们会发现这样一个问题:当随机变量维度过高时,计算将变得非常复杂, p ( x 1 , x 2 , ⋯ , x p ) p(x_1,x_2,\cdots,x_p) p(x1,x2,⋯,xp)计算量太大。
计算复杂的根本原因是变量间的依赖关系过于复杂。针对这一问题,我们可以提出以下假设:
-
相互独立
我们认为所有变量之间相互独立,意味着 ∀ x i ∈ X , X s ⊂ X ∖ x i , p ( x i ∣ X s ) = p ( x i ) \forall x_i\in X,X_s\subset X\setminus x_i,p(x_i|X_s)=p(x_i) ∀xi∈X,Xs⊂X∖xi,p(xi∣Xs)=p(xi),即对于任何一个变量,其它变量的存在并不会影响到它的边缘概率。那么联合概率的计算可以简化为:
p ( x 1 , x 2 , … , x p ) = ∏ i = 1 p p ( x i ) p(x_1,x_2,\dots,x_p)=\prod\limits_{i=1}^pp(x_i) p(x1,x2,…,xp)=i=1∏pp(xi)
典型的应用有朴素贝叶斯算法(Naive Bayes),其核心假设为 p ( x ∣ y ) = ∏ i = 1 p p ( x i ∣ y ) p(x|y)=\prod\limits_{i=1}^pp(x_i|y) p(x∣y)=i=1∏pp(xi∣y).可是这种假设太强,我们需要适当的引入变量之间的依赖关系来增强模型的表达能力。
-
(齐次)马尔可夫假设

如图,我们向相互独立的模型中引入这样的依赖关系:所有的变量都唯一地依赖于前一个变量,再往前的变量都与之无关,例如 p ( x 3 ∣ x 1 , x 2 ) = p ( x 3 ∣ x 2 ) p(x_3|x_1,x_2)=p(x_3|x_2) p(x3∣x1,x2)=p(x3∣x2),当 x 2 x_2 x2被观测后, x 1 x_1 x1对 x 3 x_3 x3不造成影响,换句话说在确定(观测) x 2 x_2 x2的条件下, x 1 x_1 x1与 x 3 x_3 x3独立,记作 x 1 ⊥ ⊥ x 3 ∣ x 2 x_1\perp \!\!\! \perp x_3|x_2 x1⊥⊥x3∣x2.(其中 ⊥ ⊥ \perp \!\!\! \perp ⊥⊥为条件独立符号)
注:齐次马尔可夫假设的原始表述为:t+1时刻的状态只依赖于t时刻的状态,与观测状态无关
更一般的,我们可以将该假设中的条件独立性记为:
x j ⊥ ⊥ x i + 1 ∣ x i , i < j x_j\perp\!\!\!\perp x_{i+1}|x_i,ixj⊥⊥xi+1∣xi,i<j
当 x i x_i xi被观测后,下一个状态 x i + 1 x_{i+1} xi+1将与 x i x_i xi之前的状态都独立,即 x i + 1 x_{i+1} xi+1只与 x i x_i xi有关,而与 x 1 , x 2 , ⋯ , x i − 1 x_1,x_2,\cdots,x_{i-1} x1,x2,⋯,xi−1无关。该假设中的条件独立性被称为马尔可夫性(Markov Property).典型的应用有隐马尔可夫模型(HMM),其核心假设即为齐次马尔可夫假设。
可是这种假设依赖关系较单调,表达能力仍有提升空间。
条件独立性
进一步讨论马尔可夫假设。我们可以对上述齐次马尔可夫假设进行泛化处理,将条件独立性作用在变量集合上:
X A ⊥ ⊥ X B ∣ X C X_A\perp\!\!\!\perp X_B|X_C XA⊥⊥XB∣XC
其中 X A , X B , X C X_A,X_B,X_C XA,XB,XC为变量集合,且互不相交。式子的含义简单明了:在观测到变量集合 X C X_C XC中的全部变量的条件下,变量集合 X A X_A XA与 X B X_B XB中的变量将变得相互独立。
事实上,概率图模型正是将图作为可视化的工具,将抽象的条件独立性以图的形式形象地表达出来。
概率图模型的基本概念
概率图,顾名思义,我们需要研究其中概率的成分与图的成分。上文中,我们已经充分讨论了有关概率的部分。再进一步探讨图的成分前,先建立对概率图模型研究的基本思路。
在概率图模型中,我们主要研究以下三个问题:概率图模型的表示、推断与学习,如图所示:
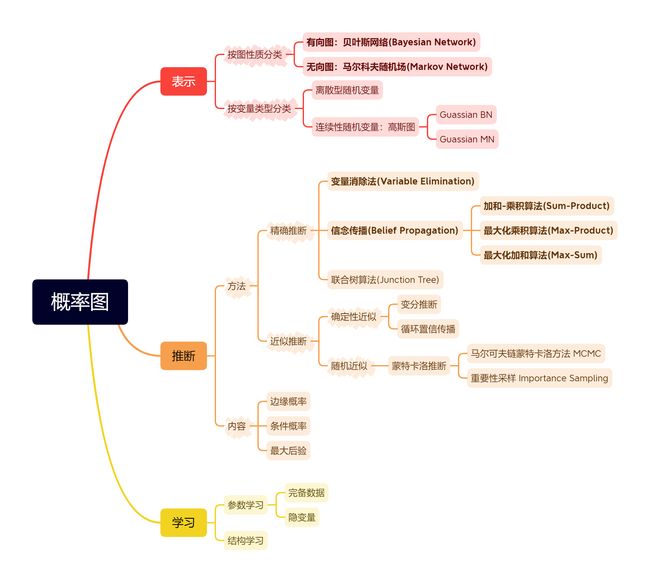
本章中,我们将重点讨论加粗部分的内容。接下来,我们先讨论概率图的表示。
贝叶斯网络(Bayesian Network)
基本概念
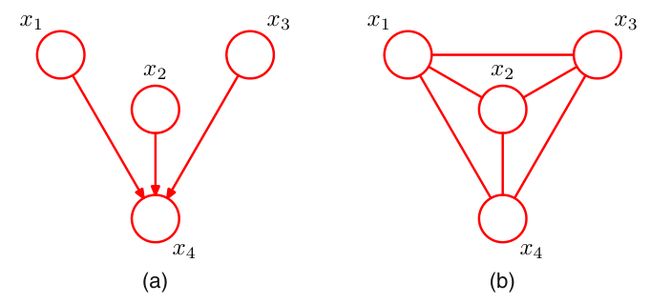
贝叶斯网络即用有向图表示变量的联合概率,其中有向图的节点代表随机变量,而箭头的方向是对条件概率进行描述。
由于贝叶斯网络是对变量的联合概率进行描述,我们先从变量的联合概率入手。假设我们有三个变量 a , b , c a,b,c a,b,c,利用链式法则,我们可以写出它们的联合概率:
p ( a , b , c ) = p ( a ) p ( b ∣ a ) p ( c ∣ a , b ) p(a,b,c)=p(a)p(b|a)p(c|a,b) p(a,b,c)=p(a)p(b∣a)p(c∣a,b)
注:在涉及概率图模型的探讨中,默认不在记号上对变量 x a x_a xa与节点 a a a做区分,二者含义一致
观察联合概率的表达式,我们发现,计算b的概率时“依赖”于a,计算c的概率时“依赖”于a,b。我们可以作出它对应的贝叶斯网络:

如图,节点a为节点b的父节点,当且仅当变量b“依赖”于变量a.为了清晰的描述所谓的“依赖”关系,我们将联合概率写作如下形式:
p ( x 1 , x 2 … , x p ) = ∏ i = 1 p p ( x i ∣ p a i ) p(x_1,x_2\dots,x_p)=\prod\limits_{i=1}^pp(x_i|pa_i) p(x1,x2…,xp)=i=1∏pp(xi∣pai)
链式法则: p ( x 1 , x 2 , ⋯ , x p ) = ∏ i = 1 p p ( x i ∣ x 1 , ⋯ , x i − 1 ) p(x_1,x_2,\cdots,x_p)=\prod\limits_{i=1}^pp(x_i|x_1,\cdots,x_{i-1}) p(x1,x2,⋯,xp)=i=1∏pp(xi∣x1,⋯,xi−1)
并称之为因子分解。因子分解形式中, x i x_i xi“依赖”于它的因子中以条件形式出现的所有变量。对应的,这些被“依赖”的变量就会成为 x i x_i xi的父节点, p a i pa_i pai即为 x i x_i xi的父节点集合。
为了从联合概率的因子分解形式得到对应的贝叶斯网络,我们首先要明确“依赖”关系,确定谁是谁的父节点。在此基础上,我们对这些节点进行拓扑排序,即可做出对应的贝叶斯网络。
反过来,利用因子分解,我们也可以轻易地得到这些变量对应的联合概率。

例如上图,我们可以直观的看到 x 4 x_4 x4的父节点是 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3, x 5 x_5 x5的父节点是 x 1 , x 3 x_1,x_3 x1,x3,以此类推,按照因子分解的形式,我们可以写出它的联合概率:
p ( x 1 , x 2 , … , x 7 ) = p ( x 1 ) p ( x 2 ) p ( x 3 ) p ( x 4 ∣ x 1 , x 2 , x 3 ) p ( x 5 ∣ x 1 , x 3 ) p ( x 6 ∣ x 4 ) p ( x 7 ∣ x 4 , x 5 ) p(x_1,x_2,\dots,x_7)=p(x_1)p(x_2)p(x_3)p(x_4|x_1,x_2,x_3)p(x_5|x_1,x_3)p(x_6|x_4)p(x_7|x_4,x_5) p(x1,x2,…,x7)=p(x1)p(x2)p(x3)p(x4∣x1,x2,x3)p(x5∣x1,x3)p(x6∣x4)p(x7∣x4,x5)
注:当存在相同形式的依赖关系(如多个变量都唯一的依赖于同一个变量)时,我们可以引入板的记号来进一步简化表达:
如图,左图表示的关系与右图一致。
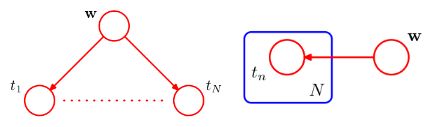
基本结构
为了高效的分析更加复杂的贝叶斯网络,我们需要对构成贝叶斯网络的基本结构进行研究。
为了明确的称呼这些基本结构,我们做如下规定:
![]()
如图,我们将有向边即箭头的箭镞称为head,将箭头的箭杆成为tail。
tail-to-tail
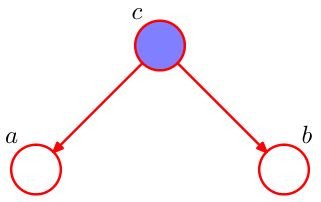
如图,节点c与两边的tail相连。写出它的因子分解,可以得到:
p ( a , b , c ) = p ( a ∣ c ) p ( b ∣ c ) p ( c ) p(a,b,c)=p(a|c)p(b|c)p(c) p(a,b,c)=p(a∣c)p(b∣c)p(c)
我们有两种方法可以得出背后蕴含的条件独立性。
法一:考虑链式法则给出的联合概率 p ( a , b , c ) = p ( c ) p ( b ∣ c ) p ( a ∣ b , c ) p(a,b,c)=p(c)p(b|c)p(a|b,c) p(a,b,c)=p(c)p(b∣c)p(a∣b,c),注意,此处的联合概率并未考虑任何的条件独立性。
两式联立,得:
p ( c ) p ( b ∣ c ) p ( a ∣ b , c ) = p ( a ∣ c ) p ( b ∣ c ) p ( c ) p(c)p(b|c)p(a|b,c)=p(a|c)p(b|c)p(c) p(c)p(b∣c)p(a∣b,c)=p(a∣c)p(b∣c)p(c)
两边同除 p ( c ) p ( b ∣ c ) p(c)p(b|c) p(c)p(b∣c),即得 p ( a ∣ b , c ) = p ( a ∣ c ) p(a|b,c)=p(a|c) p(a∣b,c)=p(a∣c).这意味着在给定c的条件下,b对a并未产生任何影响,即
a ⊥ ⊥ b ∣ c a\perp\!\!\!\perp b|c a⊥⊥b∣c
法二:倘若没有任何一个变量被观测,利用加法法则,我们可以求出边缘概率 p ( a , b ) = ∫ p ( a ∣ c ) p ( b ∣ c ) p ( c ) d c p(a,b)=\int p(a|c)p(b|c)p(c)dc p(a,b)=∫p(a∣c)p(b∣c)p(c)dc,而等式右边往往难以被分解为 p ( a ) p ( b ) p(a)p(b) p(a)p(b),因此, a ̸ ⊥ ⊥ b ∣ ϕ a\not\!\perp\!\!\!\perp b|\phi a⊥⊥b∣ϕ.
在给定c的条件下,利用贝叶斯法则,我们可以得到后验概率 p ( a , b ∣ c ) p(a,b|c) p(a,b∣c):
p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ∣ c ) p ( b ∣ c ) p(a,b|c)=\dfrac{p(a,b,c)}{p(c)}=p(a|c)p(b|c) p(a,b∣c)=p(c)p(a,b,c)=p(a∣c)p(b∣c)
很显然,我们有
a ⊥ ⊥ b ∣ c a\perp\!\!\!\perp b|c a⊥⊥b∣c
为了记住最终结论,我们可以认为,对c的观测,阻断了无向路径 a − b − c a-b-c a−b−c.
head-to-tail
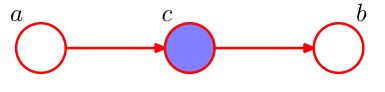
如图,节点c与a的head相连,与b的tail相连。写出它的因子分解,可以得到:
p ( a , b , c ) = p ( a ) p ( b ∣ c ) p ( c ∣ a ) p(a,b,c)=p(a)p(b|c)p(c|a) p(a,b,c)=p(a)p(b∣c)p(c∣a)
仿照head-to-head中的讨论,我们同样可以采用这两种做法来寻找背后的条件独立性:
法一:
p ( a , b , c ) = p ( a ) p ( c ∣ a ) p ( b ∣ a , c ) = p ( a ) p ( b ∣ c ) p ( c ∣ a ) ⇒ p ( b ∣ a , c ) = p ( b ∣ c ) ⇒ a ⊥ ⊥ b ∣ c p(a,b,c)=p(a)p(c|a)p(b|a,c)=p(a)p(b|c)p(c|a)\\ \Rightarrow p(b|a,c)=p(b|c)\Rightarrow a\perp\!\!\!\perp b|c p(a,b,c)=p(a)p(c∣a)p(b∣a,c)=p(a)p(b∣c)p(c∣a)⇒p(b∣a,c)=p(b∣c)⇒a⊥⊥b∣c
法二:
p ( a , b ) = ∫ p ( a ) p ( b ∣ c ) p ( c ∣ a ) d c = p ( a ) ∫ p ( b ∣ c ) p ( c ∣ a ) d c ≠ p ( a ) p ( b ) ⇒ a ̸ ⊥ ⊥ b ∣ ϕ p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ) p ( c ∣ a ) p ( c ) p ( b ∣ c ) = p ( a , c ) p ( c ) p ( b ∣ c ) = p ( a ∣ c ) p ( b ∣ c ) ⇒ a ⊥ ⊥ b ∣ c p(a,b)=\int p(a)p(b|c)p(c|a)dc=p(a)\int p(b|c)p(c|a)dc\not=p(a)p(b)\Rightarrow a\not\!\perp\!\!\!\perp b|\phi\\ p(a,b|c)=\dfrac{p(a,b,c)}{p(c)}=\dfrac{p(a)p(c|a)}{p(c)}p(b|c)=\dfrac{p(a,c)}{p(c)}p(b|c)=p(a|c)p(b|c)\Rightarrow a\perp\!\!\!\perp b|c p(a,b)=∫p(a)p(b∣c)p(c∣a)dc=p(a)∫p(b∣c)p(c∣a)dc=p(a)p(b)⇒a⊥⊥b∣ϕp(a,b∣c)=p(c)p(a,b,c)=p(c)p(a)p(c∣a)p(b∣c)=p(c)p(a,c)p(b∣c)=p(a∣c)p(b∣c)⇒a⊥⊥b∣c
类似的,对c的观测,阻断了无向路径 a − c − b a-c-b a−c−b.
head-to-head
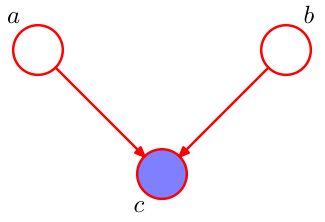
如图,节点c与两边的head相连。写出它的因子分解,可以得到:
p ( a , b , c ) = p ( a ) p ( b ) p ( c ∣ a , b ) p(a,b,c)=p(a)p(b)p(c|a,b) p(a,b,c)=p(a)p(b)p(c∣a,b)
同样的,我们有两种做法:
法一:
p ( a , b , c ) = p ( a ) p ( b ∣ a ) p ( c ∣ a , b ) = p ( a ) p ( b ) p ( c ∣ a , b ) ⇒ p ( b ∣ a ) = p ( b ) ⇒ a ⊥ ⊥ b ∣ ϕ p(a,b,c)=p(a)p(b|a)p(c|a,b)=p(a)p(b)p(c|a,b)\\ \Rightarrow p(b|a)=p(b)\Rightarrow a\perp\!\!\!\perp b|\phi p(a,b,c)=p(a)p(b∣a)p(c∣a,b)=p(a)p(b)p(c∣a,b)⇒p(b∣a)=p(b)⇒a⊥⊥b∣ϕ
法二:
p ( a , b ) = ∫ p ( a , b , c ) d c = ∫ p ( a ) p ( b ) p ( c ∣ a , b ) d c = p ( a ) p ( b ) ∫ p ( c ∣ a , b ) d c = p ( a ) p ( b ) ⇒ a ⊥ ⊥ b ∣ ϕ p ( a , b ∣ c ) = p ( a , b , c ) p ( c ) = p ( a ) p ( b ) p ( c ∣ a , b ) p ( c ) ≠ p ( a ) p ( b ) ⇒ a ̸ ⊥ ⊥ b ∣ c p(a,b)=\int p(a,b,c)dc=\int p(a)p(b)p(c|a,b)dc=p(a)p(b)\int p(c|a,b)dc=p(a)p(b)\Rightarrow a\perp\!\!\!\perp b|\phi\\ p(a,b|c)=\dfrac{p(a,b,c)}{p(c)}=p(a)p(b)\dfrac{p(c|a,b)}{p(c)}\not=p(a)p(b)\Rightarrow a\not\!\perp\!\!\!\perp b|c p(a,b)=∫p(a,b,c)dc=∫p(a)p(b)p(c∣a,b)dc=p(a)p(b)∫p(c∣a,b)dc=p(a)p(b)⇒a⊥⊥b∣ϕp(a,b∣c)=p(c)p(a,b,c)=p(a)p(b)p(c)p(c∣a,b)=p(a)p(b)⇒a⊥⊥b∣c
这里我们得出了非常不同的结论,默认情况下a,b独立,但在对c进行观测后,a,b反而不一定独立,变得有关了。这是贝叶斯网络的独特之处。
当我们利用法一来寻找背后的条件独立性时,我们并不能从正面严谨地得到 a ̸ ⊥ ⊥ b ∣ c a\not\!\perp\!\!\!\perp b|c a⊥⊥b∣c的结论。我们可以采取举反例的方式来说明这一点。事实上,从法二中我们可以看到,造成条件独立性被破坏的根本原因在于 p ( c ∣ a , b ) ≠ p ( c ) p(c|a,b)\not=p(c) p(c∣a,b)=p(c),由于c会受到a,b的影响,当我们观测c时,得到的观测值的分布并不一定与让 a , b a,b a,b“自由”地影响c时具有的概率分布一致。
众多反例表明, p ( a ∣ c ) > p ( a ∣ c , b ) p(a|c)>p(a|c,b) p(a∣c)>p(a∣c,b),在此意义上同样能够说明a,b的独立性被破坏。
作为该结论的一个推广,当c的任何子孙节点被观测到时(c可以不被观测),a,b之间的独立性同样会消失。
注:主讲人提到的“不太恰当”的例子为将其理解为亲人关系。特别的,上述head-to-head结构中,将a理解为父亲,将b理解为母亲,而c为二者的孩子,并将观测过程直观的理解为确定孩子的存在。在孩子尚未出生时,男女双方并无亲人关系,而孩子的降临将男女双方以亲人的身份联系在一起。
猜测主讲人认为该比喻不恰当的地方如下:该比喻中,是孩子的出现影响了父母的关系,而法二中指出是节点a,b对c的影响造成了独立性的消失。我认为换一种理解方式可以使该例变得恰当:正是父母想要一个孩子的行为决定了孩子的出现。在此意义上,是a,b对c造成了影响。事实上,这两种理解是相通的。
这是一个十分形象的例子,在不考虑普世道德限制的前提上,该比喻亦能很好的解释该结论的推广形式。
条件独立性
D-划分(D-separation)
回到最初的目的上,我们向一般的联合概率中引入图,是为了形象的表示这些变量之间的条件独立性。具体的来说,是为了确定变量集合 X A , X B , X C X_A,X_B,X_C XA,XB,XC,使得
X A ⊥ ⊥ X B ∣ X C X_A\perp\!\!\!\perp X_B|X_C XA⊥⊥XB∣XC
我们有两个探讨的角度:在整体层面确定 X A , X B , X C X_A,X_B,X_C XA,XB,XC(全局马尔可夫性);在个体层面判断具体的a,b在给定观测下是否独立(局部马尔可夫性)。
先从个体层面进行讨论。对于给定节点a,b之间的任意联通路径 P P P( P P P为路径上节点的集合),若 ∃ c ∈ P \exist c\in P ∃c∈P满足以下两个规则之一
- c ∈ { t a i l − t o − t a i l , h e a d − t o − t a i l } c\in\{tail-to-tail,head-to-tail\} c∈{tail−to−tail,head−to−tail}且 c c c被观测
- c ∈ { h e a d − t o − h e a d } c\in\{head-to-head\} c∈{head−to−head}且 ∀ d \forall d ∀d为 c c c及其子孙, d d d未被观测
则 a ⊥ ⊥ b a\perp\!\!\!\perp b a⊥⊥b.
再从整体层面进行讨论。对于给定的变量集合 X A , X B X_A,X_B XA,XB, ∀ a ∈ X a , b ∈ X b , ∀ P s . t . a − P − b \forall a\in X_a,b\in X_b,\forall P\ s.t.a-P-b ∀a∈Xa,b∈Xb,∀P s.t.a−P−b,按如下规则对 ∀ c ∈ P \forall c\in P ∀c∈P进行划分
- c ∈ { t a i l − t o − t a i l , h e a d − t o − t a i l } c\in\{tail-to-tail,head-to-tail\} c∈{tail−to−tail,head−to−tail},则 c ∈ X c c\in X_c c∈Xc
- c ∈ { h e a d − t o − h e a d } c\in\{head-to-head\} c∈{head−to−head},则 ∀ d \forall d ∀d为 c c c及其子孙, d ∉ X c d\notin X_c d∈/Xc
换言之,所有能够通过观测以阻断a,b间联系,使得a,b独立的点c都在 X C X_C XC中,如图所示:
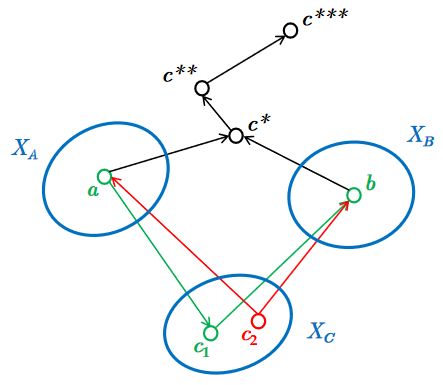
下面给出D划分的具体示例。如图,标出的为观测节点,判断a,b在观测节点的条件下是否具有独立性。

图中a,b之间具有唯一的路径 P = { e , f } P=\{e,f\} P={e,f}.
如左图,e作为head-to-head型节点,其子孙c被观测,故不具有阻碍作用;而具备阻碍能力的tail-to-tail型节点f并未被观测,故并不具有阻碍作用,因此a,b并不独立,即 a ̸ ⊥ ⊥ b ∣ c a\not\!\perp\!\!\!\perp b|c a⊥⊥b∣c;如右图,情况刚好完全相反,e,f均起到阻碍作用,故a,b独立,即 a ⊥ ⊥ b ∣ f a\perp\!\!\!\perp b|f a⊥⊥b∣f.
马尔可夫毯(Markov blanket)
进一步探讨变量之间的条件独立性。在相互独立的简化模型中,我们假设 p ( x i ∣ X ∖ x i ) = p ( x i ) p(x_i|X\setminus x_i)=p(x_i) p(xi∣X∖xi)=p(xi).既然现在我们引入了贝叶斯网络,在此基础上再考虑条件概率 p ( x i ∣ X ∖ x i ) p(x_i|X\setminus x_i) p(xi∣X∖xi),利用贝叶斯法则与贝叶斯网络的因子分解可以写作
p ( x i ∣ X ∖ x i ) = p ( x 1 , … , x p ) ∫ p ( x 1 , … , x p ) d x i = ∏ i = 1 p p ( x i ∣ p a i ) ∫ ∏ i = 1 p p ( x i ∣ p a i ) d x i p(x_i|X\setminus x_i)=\dfrac{p(x_1,\dots,x_p)}{\int p(x_1,\dots,x_p)dx_i}=\dfrac{\prod\limits_{i=1}^pp(x_i|pa_i)}{\int \prod\limits_{i=1}^pp(x_i|pa_i)dx_i} p(xi∣X∖xi)=∫p(x1,…,xp)dxip(x1,…,xp)=∫i=1∏pp(xi∣pai)dxii=1∏pp(xi∣pai)
记 ∏ i = 1 p p ( x i ∣ p a i ) = Δ Δ ˉ \prod\limits_{i=1}^pp(x_i|pa_i)=\Delta\bar\Delta i=1∏pp(xi∣pai)=ΔΔˉ,其中 Δ \Delta Δ为与 x i x_i xi有关的因子之积,而 Δ ˉ \bar\Delta Δˉ为与 x i x_i xi无关的因子之积,则上式可进一步化简为
Δ Δ ˉ ∫ Δ Δ ˉ d x i = Δ Δ ˉ Δ ˉ ∫ Δ d x i = Δ ∫ Δ d x i ≜ f ( Δ ) \dfrac{\Delta\bar\Delta}{\int \Delta\bar\Delta dxi}=\dfrac{\Delta\bar\Delta}{\bar\Delta\int \Delta dxi}=\dfrac{\Delta}{\int \Delta dxi}\triangleq f(\Delta) ∫ΔΔˉdxiΔΔˉ=Δˉ∫ΔdxiΔΔˉ=∫ΔdxiΔ≜f(Δ)
即 p ( x i ∣ X ∖ x i ) p(x_i|X\setminus x_i) p(xi∣X∖xi)仅与与 x i x_i xi相关的条件概率有关。
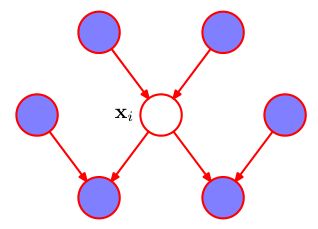
从因子分解中,我们很容易找到与 x i x_i xi有关的因子: x i x_i xi作为儿子的 p ( x i ∣ p a i ) p(x_i|pa_i) p(xi∣pai)与 x i x_i xi作为父亲的 p ( c h i ∣ x i , p a c h i ) p(ch_i|x_i,pa_{ch_i}) p(chi∣xi,pachi),其中 c h i ch_i chi为 x i x_i xi的子节点,除 x i x_i xi以外的 p a c h i pa_{ch_i} pachi称为 x i x_i xi的同父节点。因此,与 x i x_i xi有关的节点仅为其父节点、子节点与同父节点,构成下图所示的马尔可夫毯:
贝叶斯网络的分类及其具体模型
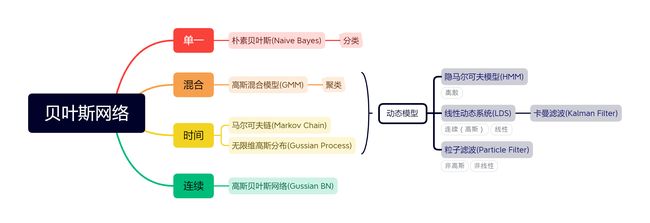
可以按照从单一模型到混合模型,从有限时空(离散)到无限时空(连续)将贝叶斯网络分成如下几类:
马尔可夫随机场(Markov Random Fields)
通过上述讨论,我们发现,在使用有向图表示变量的联合概率时,会出现head-to-head型较为反常的结构;而当我们利用无向图表示变量的联合概率时,由于无向边不再具有head与tail的区分,故这样的问题能很好的得到解决。
基本概念
马尔可夫随机场(又称马尔可夫网络)即是用无向图来表达变量的联合概率。在马尔可夫随机场中,无向边表示了变量之间的软约束。
与贝叶斯网络相反,讨论马尔可夫随机场的条件独立性是较为容易的。
条件独立性
马尔可夫随机场的条件独立性体现在三个方面上:全局马尔可夫性、局部马尔可夫性和成对马尔可夫性,且三者等价。
全局马尔可夫性
实际上,D-划分中的D是directing的缩写,特指的是有向图中判断条件独立性的划分方法。借助D-划分的思想,我们一样可以确定无向图中的马尔可夫性。
由于不存在head与tail之分,自然就不会出现head-to-head的情形,而tail-to-tail与head-to-tail都可以看作观测中间节点使得两端的节点被阻断,从而独立。
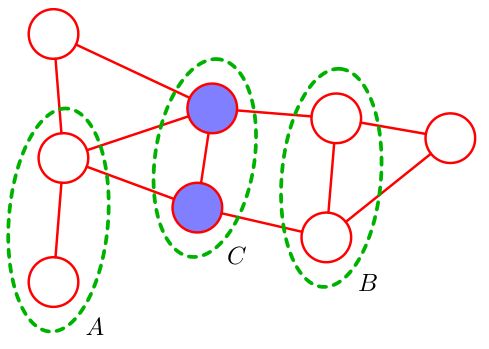
按照这样的思路,我们很容易得到无向图全局马尔可夫性。对于给定的变量集合 X A , X B , X C , ∀ a ∈ X A , ∀ b ∈ X B , ∀ P s . t . a − P − b , X_A,X_B,X_C,\forall a\in X_A,\forall b\in X_B,\forall P\ s.t.a-P-b, XA,XB,XC,∀a∈XA,∀b∈XB,∀P s.t.a−P−b,若 ∃ c ∈ P s . t . c ∈ X C \exist c\in P\ s.t.c\in X_C ∃c∈P s.t.c∈XC,那么 X A ⊥ ⊥ X B ∣ X C X_A\perp\!\!\!\perp X_B|X_C XA⊥⊥XB∣XC.
如图,从A到B的所有路径都被C所阻断,即可得到 X A ⊥ ⊥ X B ∣ X C X_A\perp\!\!\!\perp X_B|X_C XA⊥⊥XB∣XC.
局部马尔可夫性
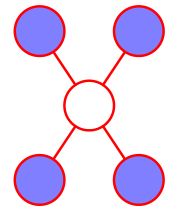
利用马尔可夫毯,我们容易发现一旦i的邻居节点(记作 n e i ne_i nei)被观测,那么i与除邻居节点及i以外的节点将变得条件独立,即
x i ⊥ ⊥ X ∖ ( x i ∪ n e i ) ∣ n e i x_i\perp\!\!\!\perp X\setminus (x_i\cup ne_i)|ne_i xi⊥⊥X∖(xi∪nei)∣nei
成对马尔可夫性
考虑马尔可夫网络上的任意两个没有边直接相连的节点i,j,若除i,j外所有的节点都被观测,那么由于i,j没有直接相连的边,它们之间的连接将被阻断,即
x i ⊥ ⊥ x j ∣ X ∖ { x i , x j } x_i\perp\!\!\!\perp x_j|X\setminus\{x_i,x_j\} xi⊥⊥xj∣X∖{xi,xj}
因子分解
因子分解的目的是为了体现条件独立性,以成对马尔可夫性为例,如果 x i ⊥ ⊥ x j ∣ X ∖ { x i , x j } x_i\perp\!\!\!\perp x_j|X\setminus\{x_i,x_j\} xi⊥⊥xj∣X∖{xi,xj},那么 x i , x j x_i,x_j xi,xj应该位于不同的因子中,这样 p ( x i , x j ∣ X ∖ { x i , x j } ) p(x_i,x_j|X\setminus\{x_i,x_j\}) p(xi,xj∣X∖{xi,xj})才有可能写成 p ( x i ∣ X ∖ { x i , x j } ) p ( x j ∣ X ∖ { x i , x j } ) p(x_i|X\setminus\{x_i,x_j\})p(x_j|X\setminus\{x_i,x_j\}) p(xi∣X∖{xi,xj})p(xj∣X∖{xi,xj})的形式。
为了实现这一目的,我们引入团(clique)的概念:团是完全子图。换句话说,团是原图上的某些节点构成的集合,并且这些节点两两相连。在此基础上我们还可以将具有如下性质的团定义最大团:不可能将图中的任何⼀个其他的节点包含到这个团中而不破坏团的性质(所含节点两两相连)。
我们将最大团记作 C C C,最大团中变量构成的集合记作 X C X_C XC,并在最大团上定义势函数 ψ C ( X C ) \psi_C(X_C) ψC(XC),那么联合概率的因子分解可以写为:
p ( X ) = 1 Z ∏ C ψ C ( X C ) p(X)=\dfrac{1}{Z}\prod\limits_C \psi_C(X_C) p(X)=Z1C∏ψC(XC)
其中 Z Z Z为归一化因子,为了保证 ∑ X p ( X ) = 1 \sum\limits_Xp(X)=1 X∑p(X)=1,有
Z = ∑ X ∏ C ψ C ( X C ) Z=\sum\limits_X\prod\limits_C\psi_C(X_C) Z=X∑C∏ψC(XC)
注:
- 势函数 ψ C ( X C ) > 0 \psi_C(X_C)>0 ψC(XC)>0,否则概率无法被正确的归一化
- 对 ∏ C \prod\limits_C C∏的理解:即对所有的最大团求积; ψ C \psi_C ψC可以理解为对于不同的最大团, ψ C \psi_C ψC的具体表达可能有不同
- 对 ∑ X \sum\limits_X X∑的理解:这里是对 X = { x 1 , x 2 , ⋯ , x p } X=\{x_1,x_2,\cdots,x_p\} X={x1,x2,⋯,xp}全体的求和,可以一步一步来,写作 ∑ x 1 ∑ x 2 ⋯ ∑ x p \sum\limits_{x_1}\sum\limits_{x_2}\cdots\sum\limits_{x_p} x1∑x2∑⋯xp∑
- 事实上,从后文的讨论中我们会发现,并不一定需要将因子分解定义在最大团上,只需保证 C C C是团即可。但例如对于a,b,c构成的团,若写作 ψ a ( a ) ψ b ( b ) ψ c ( c ) \psi_a(a)\psi_b(b)\psi_c(c) ψa(a)ψb(b)ψc(c),我们可以令 Ψ a , b , c ( a , b , c ) = ψ a ( a ) ψ b ( b ) ψ c ( c ) \Psi_{a,b,c}(a,b,c)=\psi_a(a)\psi_b(b)\psi_c(c) Ψa,b,c(a,b,c)=ψa(a)ψb(b)ψc(c),将三个因子整合在一起,又因为a,b,c构成了团,所以 Ψ a , b , c \Psi_{a,b,c} Ψa,b,c的表达合法,我们可以只考虑最大团,既保证了正确性,又减少了因子的数量,让式子变得更加简洁
你可能会对“势函数”这一名称感到困惑。事实上,这里是借鉴了热力学统计物理的吉布斯分布(Gibbs,又称玻尔兹曼分布)。在热力学中,我们定义 ψ ( X C ) ≜ e x p { − E ( X c ) } \psi(X_C)\triangleq exp\{-E(X_c)\} ψ(XC)≜exp{−E(Xc)},其中 E ( X C ) E(X_C) E(XC)为能量函数,代入因子分解中,我们可以得到
p ( X ) = 1 Z ∏ C e x p { − E ( X c ) } = 1 Z e x p { − ∑ C E ( X C ) } p(X)=\dfrac{1}{Z}\prod\limits_Cexp\{-E(X_c)\}=\dfrac{1}{Z}exp\{-\sum\limits_CE(X_C)\} p(X)=Z1C∏exp{−E(Xc)}=Z1exp{−C∑E(XC)}
进一步地,我们可以将它化作指数族分布:
p ( X ) = h ( X ) e x p { η T ϕ ( X ) − A ( η ) } = 1 Z ( η ) h ( X ) e x p { η T ϕ ( X ) } p(X)=h(X)exp\{\eta^T\phi(X)-A(\eta)\}=\dfrac{1}{Z(\eta)}h(X)exp\{\eta^T\phi(X)\} p(X)=h(X)exp{ηTϕ(X)−A(η)}=Z(η)1h(X)exp{ηTϕ(X)}
类似的,在热力学中,我们利用最大熵原理,同样可以得到指数族分布的最终结果。
事实上,利用Hammesley-Clifford定理可以证明吉布斯分布与马尔可夫随机场的等价性,由于定理的证明较为繁琐,我将其放在附录中,有兴趣的读者可以自行查阅。
无向图与有向图的关系
通过上述讨论,我们发现马尔可夫随机场相较于贝叶斯网络,由于没有head-to-head的异常结构,条件独立性的表达将变得非常直观。有没有一种方法能够让我们将有向图转化为无向图呢?
道德图(Moral Graph)
答案是肯定的。概率图模型的设计初衷是将抽象的条件独立性通过图的结构具象的表达出来,而联合概率的因子分解形式是条件独立性的数学表达,所以我们只需要考察转化前后的因子分解即可。
按照上文讨论有向图D-划分时的思路,我们依次考察三种基本结构。
对于tail-to-tail结构,如图:
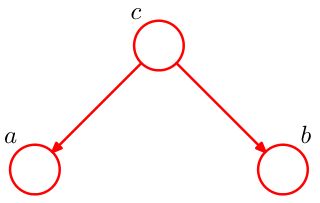
写出它的因子分解:
p ( a , b , c ) = p ( a ∣ c ) p ( b ∣ c ) p ( c ) p(a,b,c)=p(a|c)p(b|c)p(c) p(a,b,c)=p(a∣c)p(b∣c)p(c)
调整一下顺序,我们有
p ( a , b , c ) = p ( a ∣ c ) p ( c ) ⏟ ψ a , c p ( b ∣ c ) ⏟ ψ b , c p(a,b,c)=\underbrace{p(a|c)p(c)}_{\psi_{a,c}}\underbrace{p(b|c)}_{\psi_{b,c}} p(a,b,c)=ψa,c p(a∣c)p(c)ψb,c p(b∣c)
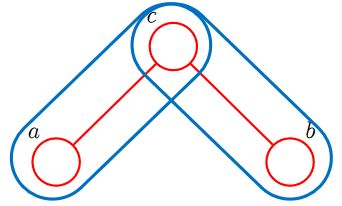
正好对应无向图的因子分解(其中最大团为 { a , c } , { b , c } \{a,c\},\{b,c\} {a,c},{b,c}):
p ( a , b , c ) = 1 Z ψ a , c ( a , c ) ψ b , c ( b , c ) p(a,b,c)=\dfrac{1}{Z}\psi_{a,c}(a,c)\psi_{b,c}(b,c) p(a,b,c)=Z1ψa,c(a,c)ψb,c(b,c)
故tail-to-tail结构的道德图直接将有向边改为无向边即可。
对于head-to-tail结构,如图:
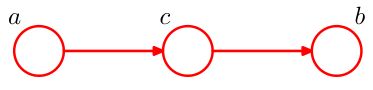
类似的,我们有
p ( a , b , c ) = p ( a ) p ( b ∣ c ) p ( c ∣ a ) = p ( a ) p ( c ∣ a ) ⏟ ψ a , c p ( b ∣ c ) ⏟ ψ b , c = 1 Z ψ a , c ( a , c ) ψ b , c ( b , c ) p(a,b,c)=p(a)p(b|c)p(c|a)=\underbrace{p(a)p(c|a)}_{\psi_{a,c}}\underbrace{p(b|c)}_{\psi_{b,c}}=\dfrac{1}{Z}\psi_{a,c}(a,c)\psi_{b,c}(b,c) p(a,b,c)=p(a)p(b∣c)p(c∣a)=ψa,c p(a)p(c∣a)ψb,c p(b∣c)=Z1ψa,c(a,c)ψb,c(b,c)
故对应的道德图为
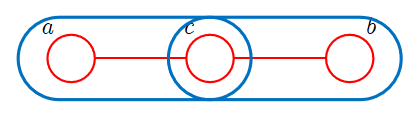
对于head-to-head结构,如图:

类似的,我们有
p ( a , b , c ) = p ( a ) p ( b ) p ( c ∣ a , b ) = p ( a ) p ( b ) p ( c ∣ a , b ) ⏟ ψ a , b , c = 1 Z ψ a , b , c ( a , b , c ) p(a,b,c)=p(a)p(b)p(c|a,b)=\underbrace{p(a)p(b)p(c|a,b)}_{\psi_{a,b,c}}=\dfrac{1}{Z}\psi_{a,b,c}(a,b,c) p(a,b,c)=p(a)p(b)p(c∣a,b)=ψa,b,c p(a)p(b)p(c∣a,b)=Z1ψa,b,c(a,b,c)
故对应的道德图为

与前两种基本结构不同的地方在于,由于项 p ( c ∣ a , b ) p(c|a,b) p(c∣a,b)的存在,它只能被归入 ψ a , b , c \psi_{a,b,c} ψa,b,c中,故最终得到的道德图中 a , b , c a,b,c a,b,c整体以最大团的形式出现,换言之, a , b a,b a,b之间产生了连边。
事实上,这是道德图命名的由来之处, a , b a,b a,b产生连接的过程被称为“伦理”(moralization),伦理过程后的图被称作道德图。
注:中文版给出的翻译为“伦理”,可能参考了将图理解为亲人关系的比喻;原文的确切翻译为“道德教化”,较为抽象
综上,我们将有向图转换为对应的道德图有赖于一下两条规则:
- 对于图中任何节点i,将 p a i pa_i pai中的节点两两相连
- 将图中的所有有向边替换为无向边
例如下面的有向图(a),按照上述规则我们很容易得到它对应的道德图(b):
图的表达能力
通过对道德图的讨论,我们可以对有向图与无向图在表达条件独立性这一具体任务下的表达能力做一个总结。
直观的来说,二者的关系可以表为如下的韦恩图:
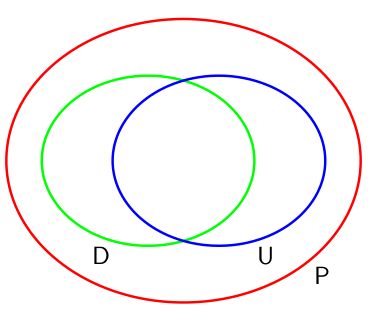
其中 P P P为所有概率分布组成的全集,而 D , U D,U D,U分别为有向图和无向图能完美表达的概率分布的部分。
至于何为完美,原书中引入如下两个概念:
依赖图(Dependency map,D图):如果⼀个概率分布中的所有条件独立性质都通过⼀个图反映出来,那么这个图被称为这个概率分布的D图,比如完全非连接的散点图(分布的独立性 ⊂ \sub ⊂图的独立性)
独立图(Independence map,I图):如果⼀个图的每个条件独立性质都可以由⼀个具体的概率分布满足,那么这个图被称为这个概率分布的I图,比如完全连接的完全图(图的独立性 ⊂ \sub ⊂分布的独立性)
既是依赖图又是独立图的图被称作完美图。
其中 D D D与 U U U的交集即为刚才讨论的一部分道德图,而有部分的图位于 D ∖ U D\setminus U D∖U与 U ∖ D U\setminus D U∖D的部分,如下:

左图原先表达的 A ⊥ ⊥ B ∣ ϕ , A ̸ ⊥ ⊥ B ∣ C A\perp\!\!\!\perp B|\phi,A\not\!\perp\!\!\!\perp B|C A⊥⊥B∣ϕ,A⊥⊥B∣C,无法同时在一张具有三个点的无向图中表出;同样,右图原先表达的 A ̸ ⊥ ⊥ B ∣ ϕ , A ⊥ ⊥ B ∣ C ∪ D , C ⊥ ⊥ D ∣ A ∪ B A\not\!\perp\!\!\!\perp B|\phi,A\perp\!\!\!\perp B|C\cup D,C\perp\!\!\!\perp D|A\cup B A⊥⊥B∣ϕ,A⊥⊥B∣C∪D,C⊥⊥D∣A∪B也无法同时在一张具有四个点的有向图中表出。
推断概述
利用概率图模型,我们可以解决以下几类推断任务:
- 边缘概率 p ( x i ) p(x_i) p(xi):利用加法法则, p ( x i ) = ∑ x 1 ∑ x 2 ⋯ ∑ x i − 1 ∑ x i + 1 ⋯ ∑ x p p ( X ) = ∑ X ∖ x i p ( X ) p(x_i)=\sum\limits_{x_1}\sum\limits_{x_2}\cdots\sum\limits_{x_{i-1}}\sum\limits_{x_{i+1}}\cdots\sum\limits_{x_p}p(X)=\sum\limits_{X\setminus x_i}p(X) p(xi)=x1∑x2∑⋯xi−1∑xi+1∑⋯xp∑p(X)=X∖xi∑p(X)
- 条件概率 p ( X A ∣ X B ) p(X_A|X_B) p(XA∣XB):利用贝叶斯法则
- 最大后验 X m a x = arg max X p ( X ) X^{max}=\mathop{\arg\max}\limits_X\ p(X) Xmax=Xargmax p(X)
注:从推断部分起,我们默认所有随机变量变量都是离散的;对于连续型随机变量,只需将求和改为积分即可
下文我们主要讨论精确推断,精确推断有如下几种方法:
-
变量消除法(Variable Elimination)
回到我们的具体任务上来。当我们利用加法法则进行推断时,我们的核心做法是对联合概率进行求和。稍后我们会看到,直接利用变量消除法暴力的计算边缘概率会造成计算复杂度极高的问题。但从上述对因子分解的讨论中我们不难看出,联合概率中的部分因子与某些变量并无直接关联。这样,我们就可以利用乘法对加法的分配率,将部分无关因子从求和式中提出,进而简化我们的运算。由于将某因子提出后,剩余的和式中的总变量得以减少,故名之曰变量消除。
-
信念传播(Belief Propagation)
利用变量消除法,在同一个概率图上求解不同随机变量的边缘概率时,会出现重复计算的问题。而信念传播的本质是为了减少重复的计算,将计算结构存储下来,空间换时间,进一步优化算法效率。
信念传播算法提出“信息”(message)的概念,将这些在不同计算中出现重叠的部分以“信息”的形式进行传递。这些重叠部分互相引用的特点构成了传递的基础,如同不断传播的信念,正是算法名称的由来之处。
纯粹的变量消除法还会带来这样一个问题:我们难以确定变量的最优消除次序(属于NP-Hard问题),从图结构出发来安排变量的消除次序是信念传播的另一大优势所在。
结合上述的乘法对加法的分配律,利用信念传播的思想,就有了著名的Sum-Product算法(加和-乘积算法)。加和-乘积算法在不同的图结构上有不同的作用范围,下文我们主要在引入因子节点的因子图的基础上讲解Sum-Product算法,事实上我们也可以完全脱离因子的概念得到该算法的另一种版本,我将在附录中进行讲解,供兴趣的读者参考。形式不同,思想相同,作用范围略有不同:前者因因子图的特性,能处理在有向图转化为对应道德图时产生的环结构,而后者仅能处理树结构。
事实上,这样的算法步骤亦可用于最大后验的求解,由于乘法对max函数同样具有分配律,我们只需对Sum-Product算法稍加修改就可以得到Max-Product算法(最大化乘积算法)。由于Max-Product中涉及连续的乘法操作,对于概率这种小数据来说,精度的保持较为困难,我们可以简单的给两边取一个对数,这样乘法就化为了加法,简单优化后的Max-Sum算法(最大化加和算法)能很好的解决精度问题。
-
联合树算法(Junction Tree)
上文中提到的Sum-Product算法(及其衍生算法)都难以直接运用到一般的图结构中。从图本身的性质出发,我们可以对图进行一些变换,使得这些算法能被很好的运用到一般的无环图中,而算法的基本思想并没有改变。
对于有环图,由于环的存在,我们难以对其进行精确推断,在这种图结构中我们只能采取近似推断的方法。循环置信传播是一种在某些情况下能发挥巨大作用的确定性近似方法。
上述的联合树算法与近似推断方法,并不在我们的讨论范围内。有兴趣的读者请自行查阅相关资料。
Sum-Product算法
预备
在继续下文的讨论之前,为了更好的利用乘法分配率,将我先加深一下对 ∑ \sum ∑符号的理解。
- 对多个变量求和: ∑ a ∑ b \sum\limits_a\sum\limits_b a∑b∑可以简写为 ∑ a , b \sum\limits_{a,b} a,b∑;同样的, ∑ a , b \sum\limits_{a,b} a,b∑可以看作是 ∑ a ∑ b \sum\limits_a\sum\limits_b a∑b∑.事实上,从for型循环的角度来看, ∑ \sum ∑实际上是提供了一个计算的环境, ∑ a \sum\limits_a a∑为变量a提供了计算环境,故a不能直接提到求和号的外部,而这个a的求和环境对b不会造成任何影响,可以将b提到求和号的外部
- 乘法对加法的分配律:小学初学乘法分配率的时候,多以 c ( a + b ) = c a + c b c(a+b)=ca+cb c(a+b)=ca+cb的形式出现,我们了解到乘数 c c c对和式是怎样的作用效果;但反过来 c a + c b = c ( a + b ) ca+cb=c(a+b) ca+cb=c(a+b),意味着多个加数有公共的因子(所谓公共即加数在变但因子不变,因子与加数的变化无关),我们可以把这个公共部分拿到求和号外面来,例如 ∑ a f ( c ) g ( a ) = f ( c ) ∑ a g ( a ) \sum\limits_{a}f(c)g(a)=f(c)\sum\limits_a g(a) a∑f(c)g(a)=f(c)a∑g(a),与上述”环境说“相一致
有时候,我们会遇到形如”加括号”的操作,即 ∑ ∑ = ( ∑ ) ( ∑ ) \sum\sum=(\sum)(\sum) ∑∑=(∑)(∑).事实上,这是由于第二个求和号及其求和对象与第一个求和号无关,将其作为一个整体提出;从提供环境的角度来看,前一个求和号无法为后一个求和号提供环境,二者互不干扰,我们简单的利用括号隔开它们,这与提公因式在形式上是一致的
所谓的大型计算的化简,基本上是不断的对因子进行拆分合并,对求和式进行拆分合并,提出或放入不同的因子,以得到一个相对简洁的形式;如果算不下去了,就再交换一下求和顺序。
变量消除法
概述中,我们提到所有这些算法都是在变量消除法的基础上进行的,所有我们先结合具体实例,对变量消除法进行讨论。

例如上面这个贝叶斯网络,我们想知道边缘概率 p ( d ) p(d) p(d).
出于讨论的方便起见,我们假设 a , b , c , d a,b,c,d a,b,c,d均为离散的二值随机变量,取值集合为 { 0 , 1 } \{0,1\} {0,1}.
利用加法法则与贝叶斯网络的因子分解,我们有
p ( d ) = ∑ a , b , c p ( a , b , c , d ) = ∑ a , b , c p ( a ) p ( b ∣ a ) p ( c ∣ b ) p ( d ∣ c ) p(d)=\sum_{a,b,c}p(a,b,c,d)=\sum\limits_{a,b,c}p(a)p(b|a)p(c|b)p(d|c) p(d)=a,b,c∑p(a,b,c,d)=a,b,c∑p(a)p(b∣a)p(c∣b)p(d∣c)
我们先进行暴力计算。求和号 ∑ a , b , c \sum\limits_{a,b,c} a,b,c∑要求我们提供 a , b , c a,b,c a,b,c的求和环境,我们让 a , b , c a,b,c a,b,c分别取遍 { 0 , 1 } \{0,1\} {0,1},有
p ( d = 0 ) = p ( a = 0 ) p ( b = 0 ∣ a = 0 ) p ( c = 0 ∣ b = 0 ) p ( d = 0 ∣ c = 0 ) + p ( a = 0 ) p ( b = 0 ∣ a = 0 ) p ( c = 1 ∣ b = 0 ) p ( d = 0 ∣ c = 1 ) + p ( a = 0 ) p ( b = 1 ∣ a = 0 ) p ( c = 0 ∣ b = 1 ) p ( d = 0 ∣ c = 0 ) + p ( a = 0 ) p ( b = 1 ∣ a = 0 ) p ( c = 1 ∣ b = 1 ) p ( d = 0 ∣ c = 1 ) + p ( a = 1 ) p ( b = 0 ∣ a = 1 ) p ( c = 0 ∣ b = 0 ) p ( d = 0 ∣ c = 0 ) + p ( a = 1 ) p ( b = 0 ∣ a = 1 ) p ( c = 1 ∣ b = 0 ) p ( d = 0 ∣ c = 1 ) + p ( a = 1 ) p ( b = 1 ∣ a = 1 ) p ( c = 0 ∣ b = 1 ) p ( d = 0 ∣ c = 0 ) + p ( a = 1 ) p ( b = 1 ∣ a = 1 ) p ( c = 1 ∣ b = 1 ) p ( d = 0 ∣ c = 1 ) p(d=0)=p(a=0)p(b=0|a=0)p(c=0|b=0)p(d=0|c=0)+p(a=0)p(b=0|a=0)p(c=1|b=0)p(d=0|c=1)+\\ p(a=0)p(b=1|a=0)p(c=0|b=1)p(d=0|c=0)+p(a=0)p(b=1|a=0)p(c=1|b=1)p(d=0|c=1)+\\ p(a=1)p(b=0|a=1)p(c=0|b=0)p(d=0|c=0)+p(a=1)p(b=0|a=1)p(c=1|b=0)p(d=0|c=1)+\\ p(a=1)p(b=1|a=1)p(c=0|b=1)p(d=0|c=0)+p(a=1)p(b=1|a=1)p(c=1|b=1)p(d=0|c=1) p(d=0)=p(a=0)p(b=0∣a=0)p(c=0∣b=0)p(d=0∣c=0)+p(a=0)p(b=0∣a=0)p(c=1∣b=0)p(d=0∣c=1)+p(a=0)p(b=1∣a=0)p(c=0∣b=1)p(d=0∣c=0)+p(a=0)p(b=1∣a=0)p(c=1∣b=1)p(d=0∣c=1)+p(a=1)p(b=0∣a=1)p(c=0∣b=0)p(d=0∣c=0)+p(a=1)p(b=0∣a=1)p(c=1∣b=0)p(d=0∣c=1)+p(a=1)p(b=1∣a=1)p(c=0∣b=1)p(d=0∣c=0)+p(a=1)p(b=1∣a=1)p(c=1∣b=1)p(d=0∣c=1)
p ( d = 1 ) = p ( a = 0 ) p ( b = 0 ∣ a = 0 ) p ( c = 0 ∣ b = 0 ) p ( d = 1 ∣ c = 0 ) + p ( a = 0 ) p ( b = 0 ∣ a = 0 ) p ( c = 1 ∣ b = 0 ) p ( d = 1 ∣ c = 1 ) + p ( a = 0 ) p ( b = 1 ∣ a = 0 ) p ( c = 0 ∣ b = 1 ) p ( d = 1 ∣ c = 0 ) + p ( a = 0 ) p ( b = 1 ∣ a = 0 ) p ( c = 1 ∣ b = 1 ) p ( d = 1 ∣ c = 1 ) + p ( a = 1 ) p ( b = 0 ∣ a = 1 ) p ( c = 0 ∣ b = 0 ) p ( d = 1 ∣ c = 0 ) + p ( a = 1 ) p ( b = 0 ∣ a = 1 ) p ( c = 1 ∣ b = 0 ) p ( d = 1 ∣ c = 1 ) + p ( a = 1 ) p ( b = 1 ∣ a = 1 ) p ( c = 0 ∣ b = 1 ) p ( d = 1 ∣ c = 0 ) + p ( a = 1 ) p ( b = 1 ∣ a = 1 ) p ( c = 1 ∣ b = 1 ) p ( d = 1 ∣ c = 1 ) p(d=1)=p(a=0)p(b=0|a=0)p(c=0|b=0)p(d=1|c=0)+p(a=0)p(b=0|a=0)p(c=1|b=0)p(d=1|c=1)+\\ p(a=0)p(b=1|a=0)p(c=0|b=1)p(d=1|c=0)+p(a=0)p(b=1|a=0)p(c=1|b=1)p(d=1|c=1)+\\ p(a=1)p(b=0|a=1)p(c=0|b=0)p(d=1|c=0)+p(a=1)p(b=0|a=1)p(c=1|b=0)p(d=1|c=1)+\\ p(a=1)p(b=1|a=1)p(c=0|b=1)p(d=1|c=0)+p(a=1)p(b=1|a=1)p(c=1|b=1)p(d=1|c=1) p(d=1)=p(a=0)p(b=0∣a=0)p(c=0∣b=0)p(d=1∣c=0)+p(a=0)p(b=0∣a=0)p(c=1∣b=0)p(d=1∣c=1)+p(a=0)p(b=1∣a=0)p(c=0∣b=1)p(d=1∣c=0)+p(a=0)p(b=1∣a=0)p(c=1∣b=1)p(d=1∣c=1)+p(a=1)p(b=0∣a=1)p(c=0∣b=0)p(d=1∣c=0)+p(a=1)p(b=0∣a=1)p(c=1∣b=0)p(d=1∣c=1)+p(a=1)p(b=1∣a=1)p(c=0∣b=1)p(d=1∣c=0)+p(a=1)p(b=1∣a=1)p(c=1∣b=1)p(d=1∣c=1)
共16项,非常繁琐。计算复杂度为 O ( K p ) O(K^p) O(Kp),其中 K K K为随机变量的取值数, p p p为随机变量的维数。
依据概述中提到的乘法对加法的分配律的思想,我们将其化简为
∑ a , b , c p ( a ) p ( b ∣ a ) p ( c ∣ b ) p ( d ∣ c ) = ∑ c ∑ b ∑ a p ( a ) p ( b ∣ a ) p ( c ∣ b ) p ( d ∣ c ) = ∑ c p ( d ∣ c ) ∑ b ∑ a p ( a ) p ( b ∣ a ) p ( c ∣ b ) = ∑ c p ( d ∣ c ) ∑ b p ( c ∣ b ) ∑ a p ( a ) p ( b ∣ a ) \sum\limits_{a,b,c}p(a)p(b|a)p(c|b)p(d|c)=\sum\limits_{c}\sum\limits_{b}\sum\limits_{a}p(a)p(b|a)p(c|b)p(d|c)\\ =\sum\limits_{c}p(d|c)\sum\limits_{b}\sum\limits_{a}p(a)p(b|a)p(c|b)\\ =\sum\limits_{c}p(d|c)\sum\limits_{b}p(c|b)\sum\limits_{a}p(a)p(b|a)\\ a,b,c∑p(a)p(b∣a)p(c∣b)p(d∣c)=c∑b∑a∑p(a)p(b∣a)p(c∣b)p(d∣c)=c∑p(d∣c)b∑a∑p(a)p(b∣a)p(c∣b)=c∑p(d∣c)b∑p(c∣b)a∑p(a)p(b∣a)
这样,最内层的求和式 ∑ a p ( a ) p ( b ∣ a ) \sum\limits_{a}p(a)p(b|a) a∑p(a)p(b∣a)就只含有变量 a , b a,b a,b,实现了变量消除。
为了使变量消除更为明显,我们作记号 ϕ x ( y ) \phi_x(y) ϕx(y),指代通过对变量 x x x求和后变得与 x x x无关而成为关于 y y y的因子,则
∑ c p ( d ∣ c ) ∑ b p ( c ∣ b ) ∑ a p ( a ) ⏞ ψ a p ( b ∣ a ) ⏞ ψ a , b ⏟ ϕ a ( b ) = ∑ c p ( d ∣ c ) ∑ b p ( c ∣ b ) ϕ a ( b ) ⏟ ϕ b ( c ) = ∑ c p ( d ∣ c ) ϕ b ( c ) = ϕ c ( d ) \sum\limits_{c}p(d|c)\sum\limits_{b}p(c|b)\underbrace{\sum\limits_{a}\overbrace{p(a)}^{\psi_a}\overbrace{p(b|a)}^{\psi_{a,b}}}_{\phi_a(b)}\\ =\sum\limits_{c}p(d|c)\underbrace{\sum\limits_{b}p(c|b)\phi_a(b)}_{\phi_b(c)}\\ =\sum\limits_{c}p(d|c)\phi_b(c)=\phi_c(d) c∑p(d∣c)b∑p(c∣b)ϕa(b) a∑p(a) ψap(b∣a) ψa,b=c∑p(d∣c)ϕb(c) b∑p(c∣b)ϕa(b)=c∑p(d∣c)ϕb(c)=ϕc(d)
上面的过程非常直观的反应了我们依次消除 a , b , c a,b,c a,b,c的过程。
事实上,我们也可以将 ∑ a , b , c \sum\limits_{a,b,c} a,b,c∑拆为 ∑ a ∑ b ∑ c \sum\limits_{a}\sum\limits_{b}\sum\limits_{c} a∑b∑c∑,但此处讲解变量消除法是为下文讲解信念传播而服务,将其拆为 ∑ c ∑ b ∑ a \sum\limits_{c}\sum\limits_{b}\sum\limits_{a} c∑b∑a∑隐含了信念传播算法的思想(由叶子到根)。
比较化简前后的两个式子
∑ a , b , c p ( a ) p ( b ∣ a ) p ( c ∣ b ) p ( d ∣ c ) ∑ c p ( d ∣ c ) ∑ b p ( c ∣ b ) ∑ a p ( a ) p ( b ∣ a ) \sum\limits_{a,b,c}p(a)p(b|a)p(c|b)p(d|c)\\ \sum\limits_{c}p(d|c)\sum\limits_{b}p(c|b)\sum\limits_{a}p(a)p(b|a) a,b,c∑p(a)p(b∣a)p(c∣b)p(d∣c)c∑p(d∣c)b∑p(c∣b)a∑p(a)p(b∣a)
前者我们需要做 ( 4 − 1 ) ∗ 16 = 48 (4-1)*16=48 (4−1)∗16=48次乘法以及 ( 8 − 1 ) ∗ 2 = 14 (8-1)*2=14 (8−1)∗2=14次加法来完成最终的计算;而采取后者,我们只需要做 3 ∗ 4 = 12 3*4=12 3∗4=12次乘法以及 3 ∗ 2 = 6 3*2=6 3∗2=6次加法来完成最终的计算,计算效率大大提升。
因子图
在进行更加深入的讨论前,我们先引入因子图的概念。
从上文提到的因子分解的角度来看,联合概率可以分解为多个因子的乘积。我们可以直观地将其在图中表达出来:引入因子节点,其与该因子中涉及到的所有变量对应的节点相连。
在这样的观点下,我们可以将联合概率的因子分解形式改写为
f ( X ) = ∏ S f S ( X S ) f(X)=\prod_{S}f_S(X_S) f(X)=S∏fS(XS)
其中 S S S为因子 f S f_S fS涉及到的节点集合, X S X_S XS为变量集合。下结合具体例子进行说明。
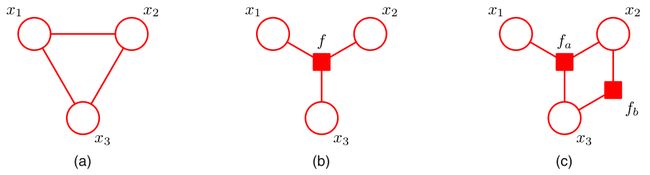
对于图(a)中的马尔可夫随机场,我们可以写出它的因子分解
p ( x 1 , x 2 , x 3 ) = 1 Z ψ 1 , 2 , 3 ( x 1 , x 2 , x 3 ) p(x_1,x_2,x_3)=\frac{1}{Z}\psi_{1,2,3}(x_1,x_2,x_3) p(x1,x2,x3)=Z1ψ1,2,3(x1,x2,x3)
当我们按最大团的形式进行分解时,得到的因子 ψ 1 , 2 , 3 \psi_{1,2,3} ψ1,2,3涉及到节点 1 , 2 , 3 1,2,3 1,2,3,我们引入因子节点 f f f代表 ψ 1 , 2 , 3 \psi_{1,2,3} ψ1,2,3,与与之相关的节点 1 , 2 , 3 1,2,3 1,2,3相连,便得到图(b)中的因子图。
事实上,如果你看过附录中的Hammesley-Clifford定理的证明,你会明白我们其实可以按照从下面的方式来对此马尔可夫随机场进行因子分解
p ( x 1 , x 2 , x 3 ) = 1 Z ψ 1 , 2 ( x 1 , x 2 ) ψ 1 , 3 ( x 1 , x 3 ) ψ 2 , 3 ( x 2 , x 3 ) ψ 1 , 2 , 3 ( x 1 , x 2 , x 3 ) p(x_1,x_2,x_3)=\dfrac{1}{Z}\psi_{1,2}(x_1,x_2)\psi_{1,3}(x_1,x_3)\psi_{2,3}(x_2,x_3)\psi_{1,2,3}(x_1,x_2,x_3) p(x1,x2,x3)=Z1ψ1,2(x1,x2)ψ1,3(x1,x3)ψ2,3(x2,x3)ψ1,2,3(x1,x2,x3)
调整求积顺序,我们有
p ( x 1 , x 2 , x 3 ) = 1 Z ψ 1 , 2 ( x 1 , x 2 ) ψ 1 , 3 ( x 1 , x 3 ) ψ 1 , 2 , 3 ( x 1 , x 2 , x 3 ) ⏟ f a ( x 1 , x 2 , x 3 ) ψ 2 , 3 ( x 2 , x 3 ) ⏟ f b ( x 2 , x 3 ) p(x_1,x_2,x_3)=\dfrac{1}{Z}\underbrace{\psi_{1,2}(x_1,x_2)\psi_{1,3}(x_1,x_3)\psi_{1,2,3}(x_1,x_2,x_3)}_{f_a(x_1,x_2,x_3)}\underbrace{\psi_{2,3}(x_2,x_3)}_{f_b(x_2,x_3)} p(x1,x2,x3)=Z1fa(x1,x2,x3) ψ1,2(x1,x2)ψ1,3(x1,x3)ψ1,2,3(x1,x2,x3)fb(x2,x3) ψ2,3(x2,x3)
这样,我们可以引入两个因子节点 f a , f b f_a,f_b fa,fb,让它们分别与相关的节点相连便得到图©中的因子图。
请注意,不要混淆因子与团的概念
可见,同一张概率图,由于因子分解形式的不同,会存在多张对应的因子图。因子图只是针对某一种特定的因子分解形式,将对应的因子形象化表达的手段而已。
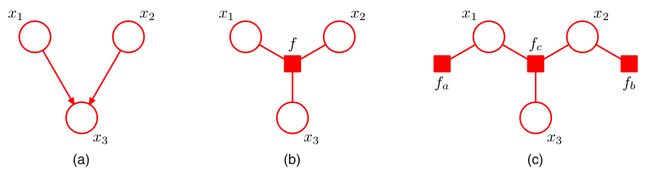
有向图的处理方式完全一致。对于图(a)中的贝叶斯网络,我们写出它的因子分解
p ( x 1 , x 2 , x 3 ) = p ( x 1 ) p ( x 2 ) p ( x 3 ∣ x 1 , x 2 ) p(x_1,x_2,x_3)=p(x_1)p(x_2)p(x_3|x_1,x_2) p(x1,x2,x3)=p(x1)p(x2)p(x3∣x1,x2)
如果我们将三项看作一个整体,即
p ( x 1 ) p ( x 2 ) p ( x 3 ∣ x 1 , x 2 ) ⏟ f ( x 1 , x 2 , x 3 ) \underbrace{p(x_1)p(x_2)p(x_3|x_1,x_2)}_{f(x_1,x_2,x_3)} f(x1,x2,x3) p(x1)p(x2)p(x3∣x1,x2)
那么对应的因子图为图(b).
如果我们将三项看作三个整体,即
p ( x 1 ) ⏟ f a ( x 1 ) p ( x 2 ) ⏟ f b ( x 2 ) p ( x 3 ∣ x 1 , x 2 ) ⏟ f c ( x 1 , x 2 , x 3 ) \underbrace{p(x_1)}_{f_a(x_1)}\underbrace{p(x_2)}_{f_b(x_2)}\underbrace{p(x_3|x_1,x_2)}_{f_c(x_1,x_2,x_3)} fa(x1) p(x1)fb(x2) p(x2)fc(x1,x2,x3) p(x3∣x1,x2)
那么对应的因子图为图©.
可见,即使是同一个因子分解,我们对它的理解不同,一样会产生多种不同的因子图。
在概述中我们提到,基于因子图的Sum-Product算法可以处理道德图中”伦理“过程产生的环结构,原因如下图:

由于”伦理“过程产生的环结构可以被囊括到一个因子中去,所以最终得到的因子图中,环结构将被去除。
除此之外,因子图还存在图结构上的性质:每个因子节点只与变量节点相连,而每个变量节点只与因子节点相连,具有这样性质的图被称为二分图,可以化为如下的形状:
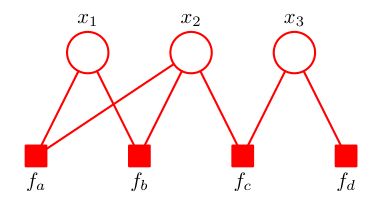
在下面的讨论中,我们并不会利用二分图的性质,而是保持其原有的形态便于直观的读取信息。
下文传送门:
PRML读书会第五期——概率图模型(Graphical Models)【中】