超详细! 生成DataFrame、读取和保存各种格式数据
公众号后台回复“图书“,了解更多号主新书内容
作者:叶庭云
来源:修炼Python
一、生成DataFrame
以字典形式生成
import pandas as pd
datas = {
'排名': [1, 2, 3, 4, 5],
'综合得分': [894, 603, 589, 570, 569],
'粉丝数': [309147, 93704, 98757, 124712, 59847],
'获赞数': [12200, 31637, 4987, 1736, 8996]
}
df = pd.DataFrame(datas)
df
结果如下:
以列表形式生成
datas1 = [
{'排名': 1, '综合得分': 894, '粉丝数': 309147, '获赞数': 12200},
{'排名': 2, '综合得分': 603, '粉丝数': 93704, '获赞数': 31637},
{'排名': 3, '综合得分': 589, '粉丝数': 98757, '获赞数': 4987},
{'排名': 4, '综合得分': 570, '粉丝数': 124712, '获赞数': 1736},
{'排名': 5, '综合得分': 569, '粉丝数': 59847, '获赞数': 8996}
]
df1 = pd.DataFrame(datas1)
df1
结果如下: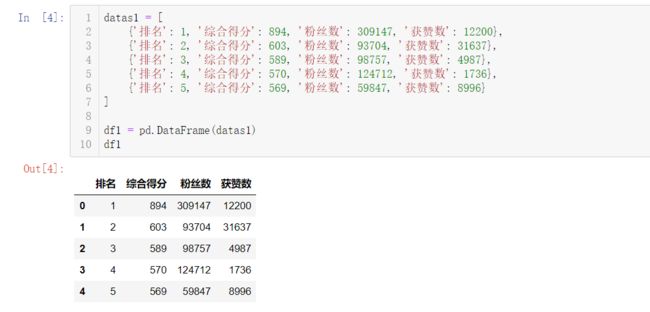
在爬取数据时,保存数据如果用pandas,需要组织数据生成DataFrame,以上两种方法是很常用的,熟练掌握这两种方法在保存爬取下来的数据时很有帮助。
二、读取数据
pd.read_excel( ):读取 Excel 表格数据
# 读取 Excel 数据
df2 = pd.read_excel('rank_datas.xlsx')
# 随机抽取5行数据
df2.sample(5)

pd.read_csv( ):读取 csv 表格数据
# 读取 csv 数据
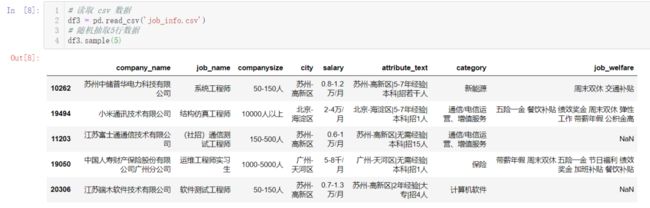
df3 = pd.read_csv('job_info.csv')
# 随机抽取5行数据
df3.sample(5)
pd.read_html( ):读取 html 网页上的表格数据
# 读取 html 数据
df4 = pd.read_html('aliyun-ddns.html')[0]
# 随机抽取5行数据
df4.sample(5)
结果如下: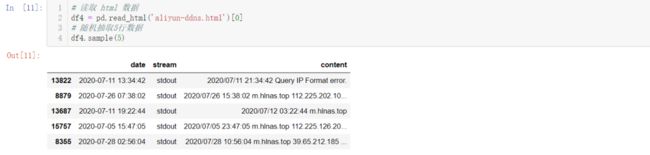 pd.read_html( )这个方法虽然少用,但它的功能非常强大,有时可以用做爬虫,直接抓取网页 Table 表格型数据,得到DataFrame。
pd.read_html( )这个方法虽然少用,但它的功能非常强大,有时可以用做爬虫,直接抓取网页 Table 表格型数据,得到DataFrame。
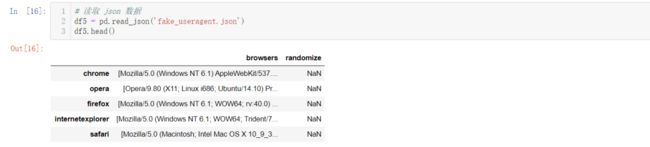
pd.read_json( ):读取 json 数据
# 读取 json 数据
df5 = pd.read_json('fake_useragent.json')
df5.head()
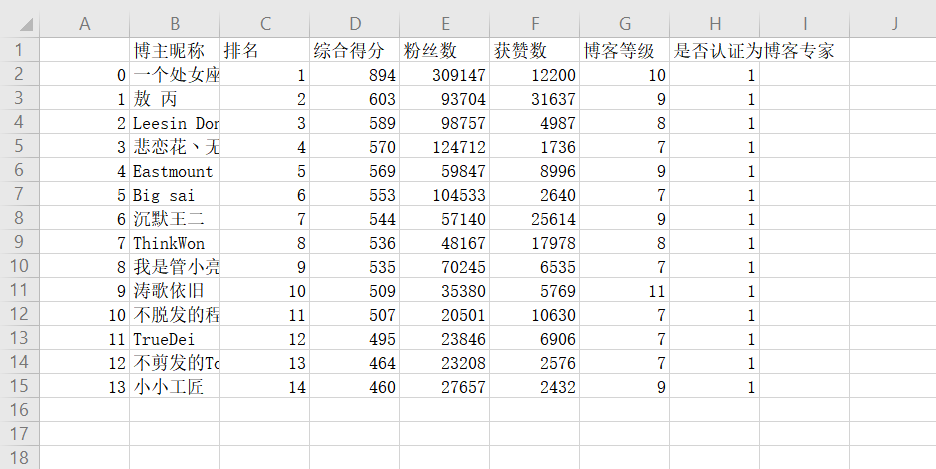
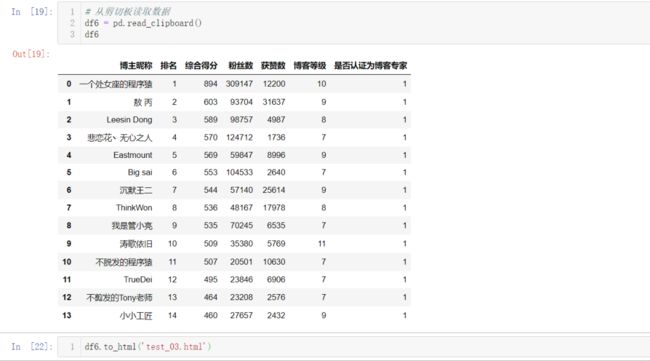
pd.read_clipboard( ):从剪切板读取数据
三、保存数据
df.to_csv( ):保存到csv

结果如下:
df.to_excel( ):保存到 Excel
结果如下:

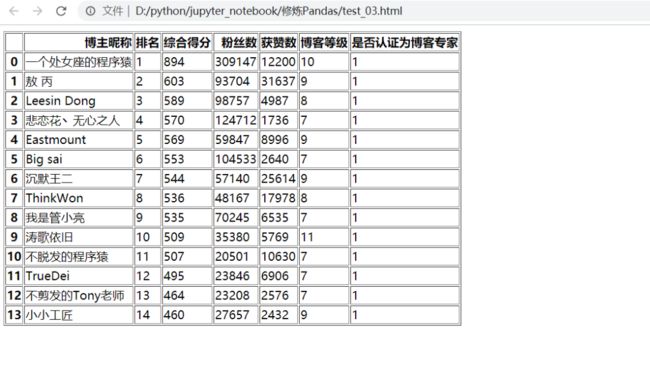
df.to_html():保存到html
结果如下:
◆ ◆ ◆ ◆ ◆
麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 卧槽!原来爬取B站弹幕这么简单● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗