推荐系统之LFM算法详解
个性化召回
召回:从item中选取一部分作为候选集
1)不同的用户喜欢不同的item
2)部分作为候选集,降低系统的负担
根据用户的属性行为上下文等信息从物品全集中选取其感兴趣的物品作为候选集;召回的重要作用:召回决定了最终推荐结果的天花板
个性化召回解析分三种:
1.基于用户行为
2.基于user profile
3.基于隐语义的 LFM
工业届个性化召回架构:个性化召回算法LFM(latent factor model)即潜在因素模型:隐语义模型
1. LFM算法的来源
相比USerCF算法(基于类似用户进行推荐)和ItemCF(基于类似物品进行推荐)算法;我们还可以直接对物品和用户的兴趣分类。对应某个用户先得到他的兴趣分类,确定他喜欢哪一类的物品,再在这个类里挑选他可能喜欢的物品。
提到协同领域,很多人首先想到的就是item CF与user CF,那么这里说到的LFM与这两者又有什么区别呢?
首先简单回忆一下item CF与user CF。
item CF
缺点:
1)用户对商品的评价非常稀疏,这样基于用户的评价所得到的用户间的相似性可能不准确(即稀疏性问题);
2)随着用户和商品的增多,系统的性能会越来越低;
3)如果从来没有用户对某一商品加以评价,则这个商品就不可能被推荐(即最初评价问题)。
主体是item,首先考虑的是item层面。也就是说,可以根据目标用户喜欢的物品,寻找和这些物品相似的物品,再推荐给用户。
Item CF是基于公式间求解相似度矩阵,相同来说,缺乏学习的过程。
ItemCF可以将item sim的举证写到redis或者内存,线上实时点击,可以做到较好的用户响应行为。
空间复杂度:ItemCF,需要的空间=物品数^2;
时间复杂度: itemCF:M个用户平均点击次数K,计算Item的相似度,时间复杂度=MKK
user CF
主体是user,首先考虑的是user层面。也就是说,可以先计算和目标用户兴趣相似的用户,之后再根据计算出来的用户喜欢的物品给目标用户推荐物品。
LFM
先对所有的物品进行分类,再根据用户的兴趣分类给用户推荐该分类中的物品。
LFM由于得到了User和Item向量,计算用户的toplike物品时候,如果推荐系统的总量很大,那么就要将每一个item的向量做点乘运算,复杂度比较高,也比较耗时,得到了用户toplike之后,写入到Redis当中,线上系统访问系统的时候,直接推荐toplike链表,但是实时性稍微差一点。
LFM只是存储user向量和Item向量,需要空间复杂度=用户数隐类数+物品数隐类数;
假设D样本,迭代N次,F为隐类的个数,那么LFM训练的时间复杂度=DFN
item CF算法,是将item(物品)进行划分,这样一旦item贡献的次数越多,就会造成两个item越相近。举个例子来说,就是当你看你喜欢的电视节目的时候,为了不错过精彩的内容,你广告部分也会看;这时,后台就会统计,你看了***电视节目,也看了***广告。这样就可能分析出***电视节目与***广告比较接近。
然而,事实上两者并不一样,为了解决这一问题,就会需要人工打标签,进行降权处理。这种方式就需要消耗大量的人力,不适用。
对此,就需要LFM。LFM是根据用户对item的点击与否,来获取user与item之间的关系,item与item之间的关系。我的理解就是,LFM不仅会考虑item,也会考虑item。
2.什么是LFM算法?
面为了方便理解,这里用具体的例子介绍算法的思想。
对于音乐,每一个用户都有自己的喜好,比如A喜欢带有小清新的、吉他伴奏的、王菲等元素(latent factor),如果一首歌(item)带有这些元素,那么就将这首歌推荐给该用户,也就是用元素去连接用户和音乐。每个人对不同的元素偏好不同,而每首歌包含的元素也不一样。
所以,我们希望能找到这样两个矩阵:潜在因子-用户矩阵Q、潜在因子-音乐矩阵P
(1)潜在因子-用户矩阵:表示不同的用户对于不用元素的偏好程度,1代表很喜欢,0代表不喜欢。
比如: (2)潜在因子-音乐矩阵:表示每种音乐含有各种元素的成分,比如下表中,音乐A是一个偏小清新的音乐,含有小清新这个Latent Factor的成分是0.9,重口味的成分是0.1,优雅的成分是0.2……
(2)潜在因子-音乐矩阵:表示每种音乐含有各种元素的成分,比如下表中,音乐A是一个偏小清新的音乐,含有小清新这个Latent Factor的成分是0.9,重口味的成分是0.1,优雅的成分是0.2……
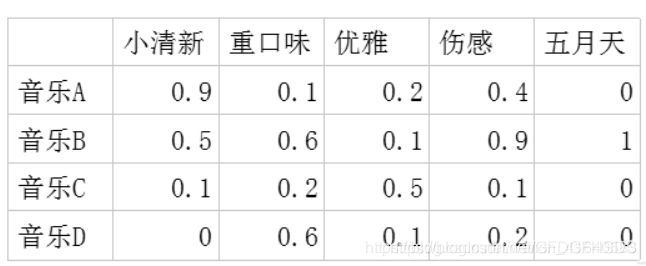 利用这两个矩阵,我们能得出张三对音乐A的喜欢程度是:张三对小清新的偏好音乐A含有小清新的成分+对重口味的偏好音乐A含有重口味的成分+对优雅的偏好音乐A含有优雅的成分+……
利用这两个矩阵,我们能得出张三对音乐A的喜欢程度是:张三对小清新的偏好音乐A含有小清新的成分+对重口味的偏好音乐A含有重口味的成分+对优雅的偏好音乐A含有优雅的成分+……
即:0.60.9 + 0.80.1 + 0.10.2 + 0.10.4 + 0.70 = 0.68
每个用户对每首歌都这样计算可以得到不同用户对不同歌曲的评分矩阵。(注,这里的破浪线表示的是估计的评分,接下来我们还会用到不带波浪线的R表示实际的评分):
 因此我们队张三推荐四首歌中得分最高的B,对李四推荐得分最高的C,王五推荐B。
因此我们队张三推荐四首歌中得分最高的B,对李四推荐得分最高的C,王五推荐B。
基于上面的思想,基于兴趣分类的方法大概需要解决3个问题:
①:如何对物品分类
②:如何确定用户对哪些物品分类,以及感兴趣的程度
③:确定了用户的兴趣,选择这个类的哪些物品推荐给用户?以及如何确定这些物品在这个类中的权重?
下面问题来了,这个潜在因子(latent factor)是怎么得到的呢?
由于面对海量的让用户自己给音乐分类并告诉我们自己的偏好系数显然是不现实的,事实上我们能获得的数据只有用户行为数据。我们沿用 @邰原朗的量化标准:单曲循环=5, 分享=4, 收藏=3, 主动播放=2 , 听完=1, 跳过=-2 , 拉黑=-5,在分析时能获得的实际评分矩阵R,也就是输入矩阵大概是这个样子:
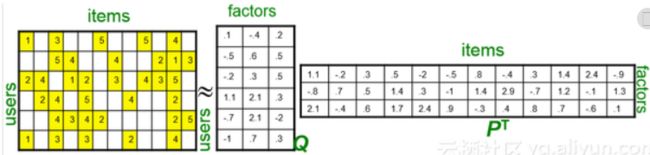
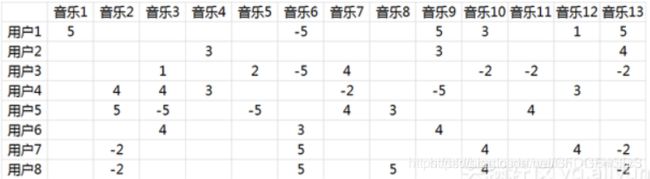 事实上这是个非常非常稀疏的矩阵,因为大部分用户只听过全部音乐中很少一部分。如何利用这个矩阵去找潜在因子呢?这里主要应用到的是矩阵的UV分解。也就是将上面的评分矩阵分解为两个低维度的矩阵,用Q和P两个矩阵的乘积去估计实际的评分矩阵,而且我们希望估计的评分矩阵
事实上这是个非常非常稀疏的矩阵,因为大部分用户只听过全部音乐中很少一部分。如何利用这个矩阵去找潜在因子呢?这里主要应用到的是矩阵的UV分解。也就是将上面的评分矩阵分解为两个低维度的矩阵,用Q和P两个矩阵的乘积去估计实际的评分矩阵,而且我们希望估计的评分矩阵
隐语义模型计算用户u对物品i兴趣的公式:
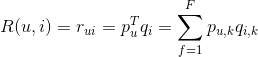
Pu,k表示用户u的兴趣和第k个隐类的关系,而Qi,k表示物品i与第k个隐类的关系。F为隐类的数量,r便是用户对物品的兴趣度。
接下的问题便是如何计算这两个参数p和q了,对于这种线性模型的计算方法,这里使用的是梯度下降法,详细的推导过程可以看一下我的另一篇博客。大概的思路便是使用一个数据集,包括用户喜欢的物品和不喜欢的物品,根据这个数据集来计算p和q。
下面给出公式,对于正样本,我们规定r=1,负样本r=0:
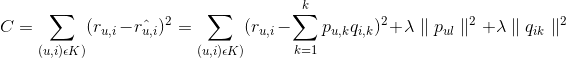
有时会写成这种形式:
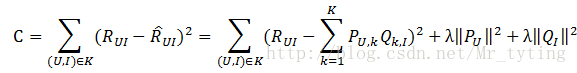
上式中后两项的是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的优化使用随机梯度下降算法: 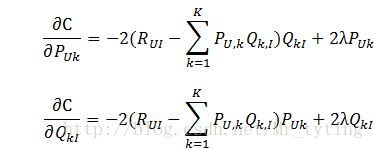
迭代计算不断优化参数(迭代次数事先人为设置),直到参数收敛。 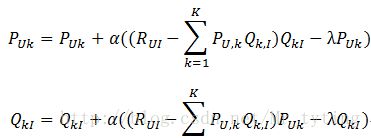
其中P矩阵表示:特定用户对特定类的喜好程度,Q表示特定电影属于特定类的权重。这样就实现了由用户行为对电影自动聚类。如果推荐一部电影给某个特定用户,通过查询这部电影在PQ矩阵内的具体值就能预测这个用户对这部电影的评分。
该模型的参数:

Latent Factor Model,很多人称为SVD,其实是比较伪的SVD,一直是最近今年推荐系统研究的热点。但LFM的研究一直是在评分预测问题上的,很少有人用它去生成TopN推荐的列表,而且也很少有人研究如何将这个数据用到非评分数据上。其实LFM在评分预测和在TopN上应用的道理是一样的。
在TopN问题上,道理是一样的,(隐反馈数据集上R只有1,0,分别表示感兴趣,不感兴趣,并且原始数据中只有明确1类的正样本,负反馈数据需要我们自己收集生成,如何生成负样本是个需要解决的问题,上面也讲到依据什么原则解决,但是还需要改进,正负样本比例是个比较重要参数)获取PQ矩阵,就可以向某个特定用户推荐他喜欢的电影类内电影中权重最高的电影或者按权重从大到小排序推荐N个电影给他。
这里聊聊这个LFM在TopN上的应用,现在很少有LFM算法应用在TopN上,不过LFM在实践部分还是有其前景的。
3.LFM算法的应用场景
根据上述内容,可以得到相应的模型输出,即两个潜在因子矩阵。其中,潜在因子的维度是之前设定的,可以理解为你认为有哪些特征可能会影响user对item的喜好程度。
那么得到模型输出后,如何应用?
(1)计算用户toplike:对于与用户没有被展示的item,可以计算出一个用户对item的倾向性得分,取top即toplike,后直接完成用户对item的喜爱度列表,写入离线即可完成对在线的推荐。
(2)计算item的topsim:得到item的向量可以用很多表示距离的公式包括cos等等,计算出每一个item的相似度矩阵,该矩阵可以用于线上推荐。当用户点击item之后,给其推荐与该item的topsim item。
(3)计算item的topic:根据得到的item向量,可以用聚类的方法,如K-means等等,取出一些隐含的类别。也就是一些隐含的topic能将item分成不同的簇,推荐时按簇推荐。
实战:分别实现LFM算法在预测评分和TopN上的代码:
预测评分,分解出PQ:
在这里插入代码片`#coding:utf-8
'''
本函数用来实现推荐系统里面的LFM算法,并且求出QR矩阵
运用梯度下降法来进行参数更新
'''
import numpy as np
import math
import random
import pandas as pd
def qr(k,learningRate,lamda_user,lamda_item,noOfIteration,file_training):
'''
:param k: 隐含的特征个数,其实就是将用户兴趣分成k类,将物品分成k类
:param learningRate:在梯度下降更新参数过程中的学习率
:param lamda_user:Pu的正则化参数
:param lamda_item:Qr的正则化参数
:param noOfIteration:最大迭代次数
:param file_training:字符串;文件路径及文件名
:return:
'''
maximumRating=0
lines = pd.read_csv(file_training, delim_whitespace=True, header=None)
numberOfUsers=0
numberOfItems=0
userID=np.zeros((len(lines)))
itemID=np.zeros((len(lines)))
rating=np.zeros((len(lines)))
count=0
for i in range(len(lines)):
userID[count] = int(lines.iloc[i][0])-1
if userID[count]>(numberOfUsers-1):
numberOfUsers = userID[count]+1
itemID[count] = int(lines.iloc[i][1])-1
if itemID[count]>(numberOfItems-1):
numberOfItems= itemID[count]+1
rating[count] = float(lines.iloc[i][2])
if rating[count]>maximumRating:
maximumRating = rating[count]
count=count+1
maximumRating=float(maximumRating)
####初始化LFM的矩阵P和矩阵Q,采用随机初化的办法进行初始化,以我的经验,这样比全零初始化更快达到最优。
p=np.array([[float(random.uniform(0,math.sqrt(maximumRating/k))) for i in range(k)] for j in range(int(numberOfUsers))])
q=np.array([[float(random.uniform(0,math.sqrt(maximumRating/k))) for i in range(k)] for j in range(int(numberOfItems))])
##利用梯度下降法更新参数
error=np.zeros((noOfIteration))
for i in range(noOfIteration):
for j in range(len(lines)):
p[int(userID[j]), :] = p[int(userID[j]), :] + learningRate * ((rating[j] -np.dot(p[int(userID[j]), :],q[int(itemID[j]), :])) * q[int(itemID[j]), :] - lamda_user * p[int(userID[j]), :])
q[int(itemID[j]), :] = q[int(itemID[j]), :] + learningRate * ((rating[j] -np.dot(p[int(userID[j]), :],q[int(itemID[j]), :])) * p[int(userID[j]), :] - lamda_item * q[int(itemID[j]), :])
for j in range (len(lines)):
error[i]= error[i] + math.pow(rating[j] - np.dot(p[int(userID[j]),:], q[int(itemID[j]),:]),2)
error[i]=math.sqrt(error[i])/len(lines)
return error,p,q
if __name__=='__main__':
(error,p,q)=qr(10, 0.02, 0.01, 0.01, 1000, 'u.data')
print p,q`
#(1)用户正反馈数据
def getUserPositiveItem(frame, userID):
'''
获取用户正反馈物品:用户评分过的物品
:param frame: ratings数据
:param userID: 用户ID
:return: 正反馈物品
'''
series = frame[frame['UserID'] == userID]['MovieID']
positiveItemList = list(series.values)
return positiveItemList
#(2)用户负反馈数据,根据用户无评分物品进行推荐,越热门的物品用户却没有进行过评分,认为用户越有可能对这物品没有兴趣
def getUserNegativeItem(frame, userID):
'''
获取用户负反馈物品:热门但是用户没有进行过评分 与正反馈数量相等
:param frame: ratings数据
:param userID:用户ID
:return: 负反馈物品
'''
userItemlist = list(set(frame[frame['UserID'] == userID]['MovieID'])) #用户评分过的物品
otherItemList = [item for item in set(frame['MovieID'].values) if item not in userItemlist] #用户没有评分的物品
itemCount = [len(frame[frame['MovieID'] == item]['UserID']) for item in otherItemList] #物品热门程度
series = pd.Series(itemCount, index=otherItemList)
series = series.sort_values(ascending=False)[:len(userItemlist)] #获取正反馈物品数量的负反馈物品
negativeItemList = list(series.index)
return negativeItemList
#(3)接下来是初始化参数p和q,这里我们采用随机初始化的方式,将p和q取值在[0,1]之间:
def initPara(userID, itemID, classCount):
'''
初始化参数q,p矩阵, 随机
:param userCount:用户ID
:param itemCount:物品ID
:param classCount: 隐类数量
:return: 参数p,q
'''
arrayp = np.random.rand(len(userID), classCount)
arrayq = np.random.rand(classCount, len(itemID))
p = pd.DataFrame(arrayp, columns=range(0,classCount), index=userID)
q = pd.DataFrame(arrayq, columns=itemID, index=range(0,classCount))
return p,q
#(4)定义函数计算用户对物品的兴趣
def lfmPredict(p, q, userID, itemID):
'''
利用参数p,q预测目标用户对目标物品的兴趣度
:param p: 用户兴趣和隐类的关系
:param q: 隐类和物品的关系
:param userID: 目标用户
:param itemID: 目标物品
:return: 预测兴趣度
'''
p = np.mat(p.ix[userID].values)
q = np.mat(q[itemID].values).T
r = (p * q).sum()
r = sigmod(r)
return r
def sigmod(x):
'''
单位阶跃函数,将兴趣度限定在[0,1]范围内
:param x: 兴趣度
:return: 兴趣度
'''
y = 1.0/(1+exp(-x))
return y
#(5)隐语义模型,利用梯度下降迭代计算参数p和q
def latenFactorModel(frame, classCount, iterCount, alpha, lamda):
'''
隐语义模型计算参数p,q
:param frame: 源数据
:param classCount: 隐类数量
:param iterCount: 迭代次数
:param alpha: 步长
:param lamda: 正则化参数
:return: 参数p,q
'''
p, q, userItem = initModel(frame, classCount)
for step in range(0, iterCount):
for user in userItem:
for userID, samples in user.items():
for itemID, rui in samples.items():
eui = rui - lfmPredict(p, q, userID, itemID)
for f in range(0, classCount):
print('step %d user %d class %d' % (step, userID, f))
p[f][userID] += alpha * (eui * q[itemID][f] - lamda * p[f][userID])
q[itemID][f] += alpha * (eui * p[f][userID] - lamda * q[itemID][f])
alpha *= 0.9
return p, q
(6)最后根据计算出来的p和q参数对用户进行物品的推荐
def recommend(frame, userID, p, q, TopN=10):
'''
推荐TopN个物品给目标用户
:param frame: 源数据
:param userID: 目标用户
:param p: 用户兴趣和隐类的关系
:param q: 隐类和物品的关系
:param TopN: 推荐数量
:return: 推荐物品
'''
userItemlist = list(set(frame[frame['UserID'] == userID]['MovieID']))
otherItemList = [item for item in set(frame['MovieID'].values) if item not in userItemlist]
predictList = [lfmPredict(p, q, userID, itemID) for itemID in otherItemList]
series = pd.Series(predictList, index=otherItemList)
series = series.sort_values(ascending=False)[:TopN]
return series
# coding: utf-8 -*-
import random
import pickle
import pandas as pd
import numpy as np
from math import exp
class Corpus:
items_dict_path = 'data/lfm_items.dict'
@classmethod
def pre_process(cls):
file_path = 'data/ratings.csv'
cls.frame = pd.read_csv(file_path)
cls.user_ids = set(cls.frame['UserID'].values)
cls.item_ids = set(cls.frame['MovieID'].values)
cls.items_dict = {user_id: cls._get_pos_neg_item(user_id) for user_id in list(cls.user_ids)}
cls.save()
@classmethod
def _get_pos_neg_item(cls, user_id):
"""
Define the pos and neg item for user.
pos_item mean items that user have rating, and neg_item can be items
that user never see before.
Simple down sample method to solve unbalance sample.
"""
print('Process: {}'.format(user_id))
pos_item_ids = set(cls.frame[cls.frame['UserID'] == user_id]['MovieID'])
neg_item_ids = cls.item_ids ^ pos_item_ids
# neg_item_ids = [(item_id, len(self.frame[self.frame['MovieID'] == item_id]['UserID'])) for item_id in neg_item_ids]
# neg_item_ids = sorted(neg_item_ids, key=lambda x: x[1], reverse=True)
neg_item_ids = list(neg_item_ids)[:len(pos_item_ids)]
item_dict = {}
for item in pos_item_ids: item_dict[item] = 1
for item in neg_item_ids: item_dict[item] = 0
return item_dict
@classmethod
def save(cls):
f = open(cls.items_dict_path, 'wb')
pickle.dump(cls.items_dict, f)
f.close()
@classmethod
def load(cls):
f = open(cls.items_dict_path, 'rb')
items_dict = pickle.load(f)
f.close()
return items_dict
class LFM:
def __init__(self):
self.class_count = 5
self.iter_count = 5
self.lr = 0.02
self.lam = 0.01
self._init_model()
def _init_model(self):
"""
Get corpus and initialize model params.
"""
file_path = 'data/ratings.csv'
self.frame = pd.read_csv(file_path)
self.user_ids = set(self.frame['UserID'].values)
self.item_ids = set(self.frame['MovieID'].values)
self.items_dict = Corpus.load()
array_p = np.random.randn(len(self.user_ids), self.class_count)
array_q = np.random.randn(len(self.item_ids), self.class_count)
self.p = pd.DataFrame(array_p, columns=range(0, self.class_count), index=list(self.user_ids))
self.q = pd.DataFrame(array_q, columns=range(0, self.class_count), index=list(self.item_ids))
def _predict(self, user_id, item_id):
"""
Calculate interest between user_id and item_id.
p is the look-up-table for user's interest of each class.
q means the probability of each item being classified as each class.
"""
p = np.mat(self.p.ix[user_id].values)
q = np.mat(self.q.ix[item_id].values).T
r = (p * q).sum()
logit = 1.0 / (1 + exp(-r))
return logit
def _loss(self, user_id, item_id, y, step):
"""
Loss Function define as MSE, the code write here not that formula you think.
"""
e = y - self._predict(user_id, item_id)
print('Step: {}, user_id: {}, item_id: {}, y: {}, loss: {}'.
format(step, user_id, item_id, y, e))
return e
def _optimize(self, user_id, item_id, e):
"""
Use SGD as optimizer, with L2 p, q square regular.
e.g: E = 1/2 * (y - predict)^2, predict = matrix_p * matrix_q
derivation(E, p) = -matrix_q*(y - predict), derivation(E, q) = -matrix_p*(y - predict),
derivation(l2_square,p) = lam * p, derivation(l2_square, q) = lam * q
delta_p = lr * (derivation(E, p) + derivation(l2_square,p))
delta_q = lr * (derivation(E, q) + derivation(l2_square, q))
"""
gradient_p = -e * self.q.ix[item_id].values
l2_p = self.lam * self.p.ix[user_id].values
delta_p = self.lr * (gradient_p + l2_p)
gradient_q = -e * self.p.ix[user_id].values
l2_q = self.lam * self.q.ix[item_id].values
delta_q = self.lr * (gradient_q + l2_q)
self.p.loc[user_id] -= delta_p
self.q.loc[item_id] -= delta_q
def train(self):
"""
Train model.
"""
for step in range(0, self.iter_count):
for user_id, item_dict in self.items_dict.items():
item_ids = list(item_dict.keys())
random.shuffle(item_ids)
for item_id in item_ids:
e = self._loss(user_id, item_id, item_dict[item_id], step)
self._optimize(user_id, item_id, e)
self.lr *= 0.9
self.save()
def predict(self, user_id, top_n=10):
"""
Calculate all item user have not meet before and return the top n interest items.
"""
self.load()
user_item_ids = set(self.frame[self.frame['UserID'] == user_id]['MovieID'])
other_item_ids = self.item_ids ^ user_item_ids
interest_list = [self._predict(user_id, item_id) for item_id in other_item_ids]
candidates = sorted(zip(list(other_item_ids), interest_list), key=lambda x: x[1], reverse=True)
return candidates[:top_n]
def save(self):
"""
Save model params.
"""
f = open('data/lfm.model', 'wb')
pickle.dump((self.p, self.q), f)
f.close()
def load(self):
"""
Load model params.
"""
f = open('data/lfm.model', 'rb')
self.p, self.q = pickle.load(f)
f.close()