Pandas - 10.4 多个分组聚合
多个分组
import pandas as pd
import seaborn as sns
tips_10 = sns.load_dataset('tips').sample(10, random_state=42)
print(tips_10)
'''
total_bill tip sex smoker day time size
24 19.82 3.18 Male No Sat Dinner 2
6 8.77 2.00 Male No Sun Dinner 2
153 24.55 2.00 Male No Sun Dinner 4
211 25.89 5.16 Male Yes Sat Dinner 4
198 13.00 2.00 Female Yes Thur Lunch 2
176 17.89 2.00 Male Yes Sun Dinner 2
192 28.44 2.56 Male Yes Thur Lunch 2
124 12.48 2.52 Female No Thur Lunch 2
9 14.78 3.23 Male No Sun Dinner 2
101 15.38 3.00 Female Yes Fri Dinner 2
'''
多指标聚合
按照多个指标分组的情况,与单个指标分组差别不大,在获取分组时需要用元组
bill_sex_time = tips_10.groupby(['sex', 'time'])
# 查看实际分组
print(bill_sex_time.groups)
'''
{('Female', 'Dinner'): [101], ('Female', 'Lunch'): [198, 124], ('Male', 'Dinner'): [24, 6, 153, 211, 176, 9], ('Male', 'Lunch'): [192]}
the type is:
'''
for sex_group in bill_sex_time:
print('the type is: {}'.format(type(sex_group)))
print('the length is: {}\n'.format(len(sex_group)))
first_element = sex_group[0]
print('the first element is:{}'.format(first_element))
print('it has a type of: {}\n'.format(type(first_element)))
second_element = sex_group[1]
print('the second element is:\n{}'.format(second_element))
print('it has a type of: {}\n'.format(type(second_element)))
print('what we have:')
print(sex_group)
break
'''
the type is:
the length is: 2
the first element is:('Male', 'Lunch')
it has a type of:
the second element is:
total_bill tip sex smoker day time size
192 28.44 2.56 Male Yes Thur Lunch 2
it has a type of:
what we have:
(('Male', 'Lunch'), total_bill tip sex smoker day time size
192 28.44 2.56 Male Yes Thur Lunch 2)
'''
获取分组结果
Male_Dinner = bill_sex_time.get_group(('Male', 'Dinner'))
print(Male_Dinner)
'''
total_bill tip sex smoker day time size
24 19.82 3.18 Male No Sat Dinner 2
6 8.77 2.00 Male No Sun Dinner 2
153 24.55 2.00 Male No Sun Dinner 4
211 25.89 5.16 Male Yes Sat Dinner 4
176 17.89 2.00 Male Yes Sun Dinner 2
9 14.78 3.23 Male No Sun Dinner 2
'''
聚合计算
对多个指标分组的结果进行计算,聚合计算的结果是一个比较奇怪的DataFrame
group_avg = bill_sex_time.mean()
print(group_avg)
'''
total_bill tip size
sex time
Male Lunch 28.440000 2.560000 2.000000
Dinner 18.616667 2.928333 2.666667
Female Lunch 12.740000 2.260000 2.000000
Dinner 15.380000 3.000000 2.000000
'''
print(type(group_avg))
'''
'''
print(group_avg.columns)
'''
Index(['total_bill', 'tip', 'size'], dtype='object')
'''
print(group_avg.index)
'''
MultiIndex([( 'Male', 'Lunch'),
( 'Male', 'Dinner'),
('Female', 'Lunch'),
('Female', 'Dinner')],
names=['sex', 'time'])
'''
平铺结果
两种方法:
- reset_index()
- groupby方法中使用as_index=False参数(默认为True)
group_method = tips_10.groupby(['sex', 'time']).mean().reset_index()
print(group_method)
'''
sex time total_bill tip size
0 Male Lunch 28.440000 2.560000 2.000000
1 Male Dinner 18.616667 2.928333 2.666667
2 Female Lunch 12.740000 2.260000 2.000000
3 Female Dinner 15.380000 3.000000 2.000000
'''
group_param = tips_10.groupby(['sex', 'time'], as_index=False).mean()
print(group_param)
'''
sex time total_bill tip size
0 Male Lunch 28.440000 2.560000 2.000000
1 Male Dinner 18.616667 2.928333 2.666667
2 Female Lunch 12.740000 2.260000 2.000000
3 Female Dinner 15.380000 3.000000 2.000000
'''
多级索引
epi_sim.txt数据,芝加哥流感病例的流行病学模拟数据
数据包含6列
- ig_type:网络中两个节点的边类型
- intervened:模拟中对人进行干预的时间
- pid:模拟人的ID
- rep:重复运行(每套参数运行多次)
- sid:模拟ID
- tr:流感病毒的传播值
intv_df = pd.read_csv('data/epi_sim.txt')
print(intv_df.shape) # (9434653, 6)
print(intv_df.head())
'''
ig_type intervened pid rep sid tr
0 3 40 294524448 1 201 0.000135
1 3 40 294571037 1 201 0.000135
2 3 40 290699504 1 201 0.000135
3 3 40 288354895 1 201 0.000135
4 3 40 292271290 1 201 0.000135
'''
统计每次重复的干预次数,干预时间和治疗效果,这里随意计算ig_type,因为只需要一个值来得到分组的观测数。
count_only = intv_df.groupby(['rep', 'intervened', 'tr'])['ig_type'].count()
print(len(count_only)) # 1196种
print(count_only.head(10))
'''
rep intervened tr
0 8 0.000166 1
9 0.000152 3
0.000166 1
10 0.000152 1
0.000166 1
12 0.000152 3
0.000166 5
13 0.000152 1
0.000166 3
14 0.000152 3
Name: ig_type, dtype: int64
'''
多级索引Serise做聚合计算
结果是多级索引Serise的形式,可以用reset_index()铺平
print(type(count_only))
'''
结果是多级索引Serise的形式
'''
多级索引Serise的形式,r若要执行另一个groupby操作,必须传入level参数指明多级索引的级别。传入level=[0, 1, 2]分别指定第一级,第二级,第三级索引。表示要细分到三级进行聚合计算。
count_mean = count_only.groupby(level=[0, 1, 2]).mean()
print(count_mean.head())
'''
rep intervened tr
0 8 0.000166 1
9 0.000152 3
0.000166 1
10 0.000152 1
0.000166 1
Name: ig_type, dtype: int64
'''
count_mean = count_only.groupby(level=[0, 1]).mean()
print(count_mean.head())
'''
rep intervened
0 8 1.0
9 2.0
10 1.0
12 4.0
13 2.0
Name: ig_type, dtype: float64
'''
count_mean = count_only.groupby(level=[0]).mean()
print(count_mean.head())
'''
rep
0 8563.024823
1 7715.925275
2 7645.172113
Name: ig_type, dtype: float64
'''
命令合成一句
count_mean = intv_df.groupby(['rep', 'intervened', 'tr'])['ig_type'].count().\
groupby(level=[0, 1, 2]).mean()
传入level的内容也可以是字符串
count_mean = count_only.groupby(level=['rep']).mean()
print(count_mean.head())
'''
rep
0 8563.024823
1 7715.925275
2 7645.172113
Name: ig_type, dtype: float64
'''
count_mean = count_only.groupby(level=['rep', 'tr']).mean()
print(count_mean.head())
'''
rep tr
0 0.000152 8257.146853
0.000166 8877.705036
1 0.000135 6848.275000
0.000152 7474.310127
0.000166 9007.890511
Name: ig_type, dtype: float64
'''
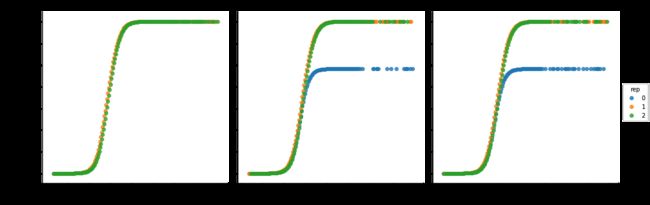
import seaborn as sns
import matplotlib.pyplot as plt
fig = sns.lmplot(x='intervened', y='ig_type', hue='rep', col='tr',
fit_reg=False, data=count_mean.reset_index())
plt.show()
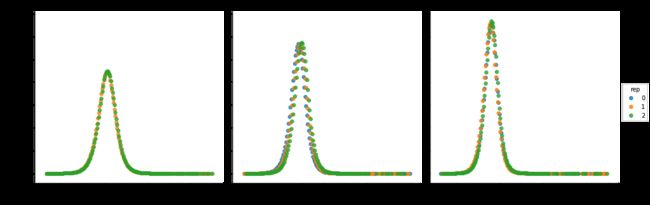
cumulative_count = intv_df.groupby(['rep', 'intervened', 'tr'])['ig_type'].count().\
groupby(level=['rep']).cumsum().reset_index()
fig = sns.lmplot(x='intervened', y='ig_type', hue='rep', col='tr',
fit_reg=False, data=cumulative_count)
plt.show()