pytorch中关于梯度计算
关于Autogrand的几个概念:
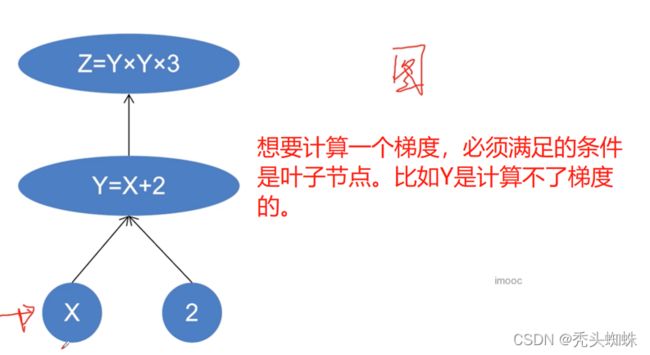
叶子张量 :可以理解为是一个初始变量,如下图所示,只有x为叶子节点,y和z都是结果节点。
pytorch中只能计算叶子节点的梯度(x)。
grand VS grand_fn
grand : 该Tensor的梯度值,每次在计算backward时需要将前一时刻的梯度归零,否则梯度值会累加。
grand_fn :叶子节点通常为None,只有结果节点的grand_fn 才有效,用于指示梯度函数是哪种类型。
梯度函数:
torch.autograd.backward (tensors,grand_tensor = None,retain_graph = None, create_graph = False )
tensors : 用于计算梯度的tensor,torch.autograd.backward(x)== x.backward()
grand_tensor : 在计算矩阵的梯度时会用到,如果输出z是一个标量则不用传参,若z是矩阵则需要传参,shape一般需要和前面计算的tensors 保持一致。函数会自动把这个参数拉成一个行向量与求出的雅克比矩阵相称得到最后的梯度。详情可查看文章https://www.cnblogs.com/JeasonIsCoding/p/10164948.html
retain_graph :通常在调用一次backward后,pytorch会自动把计算图销毁,所以想要对某个变量重复调用backward,则需将该参数设置为Ture。
create_graph :若为True,就会创建一个专门的graph of the derivative,这可以方便计算高阶微分。若y = x^2, 若为True就可以把y对x的导师2x保持起来。


以下是计算梯度的实例
x.register_hook():钩子(Hook)可以把它理解成回调函数的一种。当系统执行到某处时,检查是否有hook,有则回调。在pytorch中的钩子函数也是一个意思。
import torch
x = torch.ones([2,2],requires_grad=True)
x.register_hook( lambda grad:grad*2 ) #钩子节点,使计算出来的梯度*2
print(x)
y = x+2
z = y*y*3
print(z)
#nn = torch.rand(2,2)
nn = torch.ones(2,2)
print(nn)
z.backward( gradient=nn,retain_graph=True) #retain_graph=True 表示对计算图的保留,
#由于上面保留了计算图,这里还会做一次梯度计算并且累加
torch.autograd.backward(z, grad_tensors=nn, retain_graph=True)
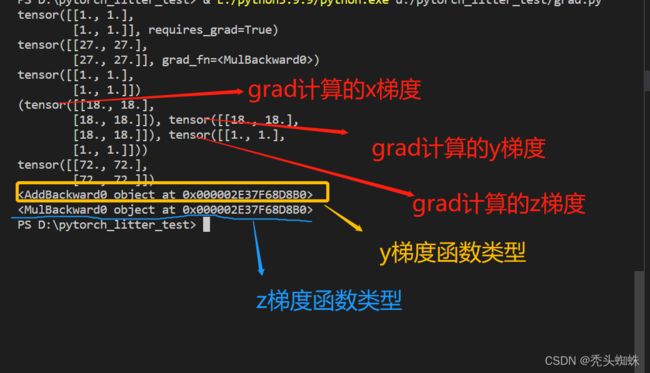
#grad函数与上面两种的区别;用grand 函数计算的梯度不会执行钩子函数,而且梯度不会累加.且还能计算除了叶子节点以外的梯度
print ( torch.autograd.grad(z, [x,y, z], grad_outputs=nn) )
print(x.grad)
print(y.grad_fn)
print(z.grad_fn)
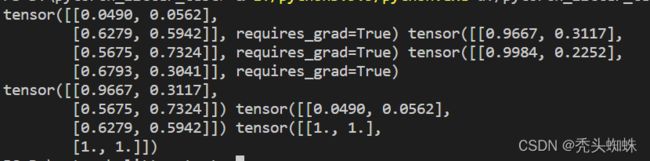
自定义Function
有些操作可能没有导数,通过Function自己去定义它的forward和backward,进而完成对梯度的运算。
import torch
class line( torch.autograd.Function ):
@staticmethod
#ctx为上下文的管理器,这个管理器会对变量进行存储,并且在后面backward中会用到
def forward(ctx, w, x, b):
ctx.save_for_backward(w, x, b)
return w*x + b
@staticmethod
#grad_out是上一级梯度,由于是需要用到链式法则这样一个关系
def backward(ctx, grad_out):
w, x, b = ctx.saved_tensors
grad_w = grad_out*x
grad_x = grad_out*w
grad_b = grad_out
return grad_w, grad_x, grad_b
w = torch.rand(2,2,requires_grad=True)
x = torch.rand(2,2,requires_grad=True)
b = torch.rand(2,2,requires_grad=True)
out = line.apply(w, x, b)
out.backward( torch.ones(2,2) )
print(w,x,b)
print( w.grad, x.grad , b.grad)```
可以得知w的导数是x, x的导数是w, b的导数是1