详解操作系统线程
一、线程概述
1.1 为什么需要线程
-
一个应用通常需要同时处理很多独立的工作,同时执行的任务称为”执行流“,由于各个执行流是独立的,所以在多核CPU中,不希望他们是顺序执行的。
- 在《详解操作系统进程》的最后面,我们提到了创建子进程可以得到两个并发执行的流,能够并发完成不同的操作,早期,每个执行流都要创建一个进程来实现,但创建子进程的弊端是:父子进程拥有完全相同的内存镜像、变量、寄存器以及除了进程标识符以外所有的东西,非常浪费内存空间,于是就产生了轻量级进程——线程。
-
由于线程比进程更轻量级,所以它比进程更容易创建和销毁,在许多系统中,创建一个线程要比创建一个进程快10~100倍,在多道程序设计中,有大量线程需要动态和快速修改时,这一特性很重要。
-
线程是在进程内部创建的,所有的线程共享进程的text(二进制代码)、data(全局和静态变量)以及堆栈,但每个线程之间又有自己独立的程序计数器(记录接下来要执行哪一条指令)、寄存器(线程当前的工作变量)以及堆栈(记录执行历史,每一个栈帧保存已调用但还没返回的过程),在Linux系统中,每个进程都有一个主线程,可以通过主线程来创建其他线程。
线程就是进程中的一个执行流,是CPU调度的基本单元,所有线程在CPU上并发执行
多道程序编程为什么用线程而不用进程?
例子:启动了一个文件拷贝的程序,由于拷贝时间太长用户想终止拷贝,有以下三种情况:
- 如果该程序按单进程进行调度,进程进入CPU运行之后,由于需要对文件进行I/O,进程进入到等待队列,此时想要中止程序进行,并没有没法能够让等待队列中的程序终止IO操作
- 如果该程序按线程进行调度,可以在进程中创建两个线程,线程1负责文件拷贝,线程2负责等待外部事件,当用户中止拷贝时,线程2收到终止指令进入就绪状态等待CPU调度,然后线程2通知线程1终止对文件的拷贝工作
- 如果按多进程调度,在主进程中创建一个子进程也开始完成上面的终止操作
但使用线程而不是进程的主要原因:
1、线程比进程更节省内存资源
2、由于线程处于同一个进程的内存地址中,而父子进程处于不同的内存地址,所以线程间的通信比进程间的通信代价要小的多
1.2 线程的定义
-
A thread is a basic unit of CPU utilization;it comprises a thread id,a program counter,a register set ,and a stack.
线程是CPU调度的基本单元,它由线程ID,一个程序计数器,寄存器集合和一个栈组成
-
It shares with other threads belonging to the same process its code section,data section,and other operating-system resource,such as open files and signals.
和其他线程共享属于同一个进程的代码部分、数据部分以及其他操作系统资源,比如:打开的文件和信号
-
A tranditional (or heavyweight) process has a single thread of control.If a process has multiple threads of control,it can perform more than one task at a time.
传统的(重量级)进程只有一个线程控制流,如果一个进程有多个线程控制流,它可以同时执行多个任务
二、线程详解
2.1 多线程进程
单线程进程和多线程进程
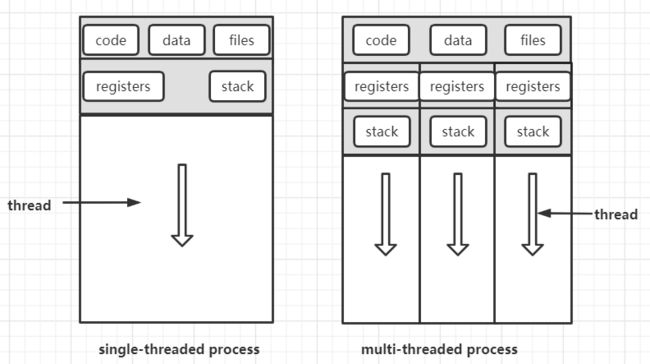
在多线程模型中,每个线程共享code、data、files,但每个线程又有独立的寄存器和栈。
采用多线程的优点:
- 响应性:服务器可以为每个请求创建一个线程来响应
- 资源共享:一个进程下的所有线程都可以访问该进程的共享资源(比如全局变量和静态变量)
- 经济:创建线程不需要像创建进程一样为公共资源分配额外的内存,所有线程共享
- 可伸缩性:多线程可以在单个核CPU上并发执行,也可以在多核CPU上并发和并行执行
多核编程
在多处理器系统中(现在基本都是多核处理器),多核编程机制让应用程序可以更有效地将自身的多个执行任务(并发线程)分配到不同的处理器上运行,以实现并行运算
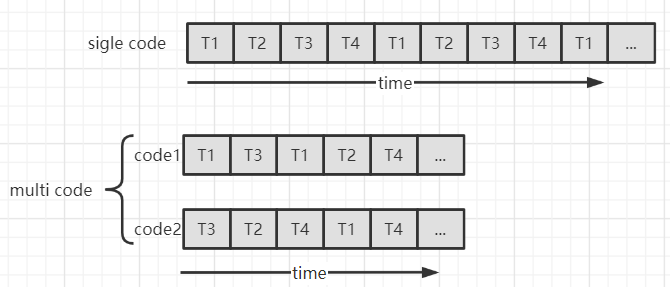
在单核处理器中,所有线程串行并发执行,而在多核处理器中,所有线程并行并发执行
2.2 多线程模型
-
用户线程ULT(User Level Thread)
ULT在user mode下运行,它的管理无需内核支持
-
内核线程KLT(Kernel Level Thread)
KTL在kernel mode下运行,由操作系统支持与管理
M:1模型

所有的用户线程都与一个内核线程绑定,从用户视角来看,可以创建多个执行流,但着多个执行流是串行执行的
优点:用户可以创建多个执行流
缺点:实际运行过程中,只有一个内核线程在串行执行,效率低
1:1模型
现在主流的操作系统(linux/windows)大都采用1:1的模型,即每个用户线程对应一个核心线程
JVM虚拟机采用的也是该模型,即应用程序每创建一个线程,都需要创建一个与之对应的核心线程
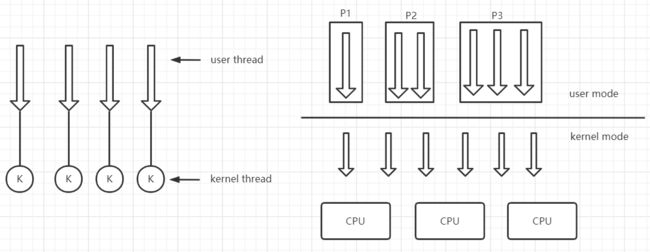
优点:支持并行和并发执行
缺点:每个用户线程都需要一个核心线程,对于内核开销比加大
该模型称为NPTL(Native POSIX Thread Library),原生POSIX线程库
M:M模型
在多对多模型中,核心线程数少于用户线程数,但大于CPU的数量,多个用户线程对应一个核心线程
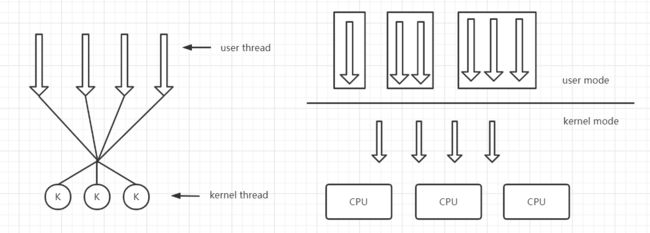
优点:相对于1:1线程模型,节省了内核开销
缺点:操作系统需要额外为用户线程分配核心线程,实现复杂
该模型称为NGPT(Next Generation POSIX Threads),下一代POSIX线程模型
线程库
Thread Library为程序员提供创建和管理线程的API
-
POSIX Pthreads:用户线程库和内核线程库
Pthreads是POSIX标准定义的线程创建与同步API,不同的操作系统对该标准的实现不尽相同
-
Windows Threads:内核线程库
-
Java Threads:依据所依赖的操作系统而定,JVM在不同的操作系统是不同的
三、处理器调度
3.1 CPU调度程序
- 多道程序设计的目的将CPU的利用率最大化
- 多个进程同时存在于内存(并发),当一个进程不使用CPU时,系统调度另一个进程占用CPU
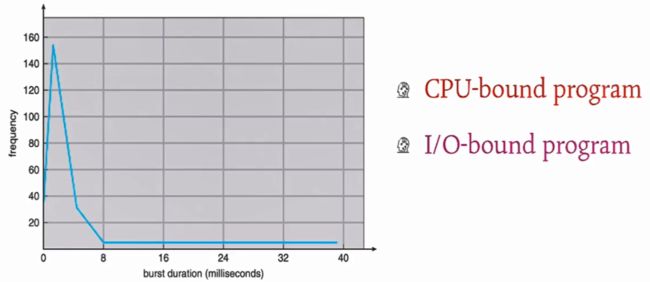
长进程:占用CPU时间长
短进程:占用CPU时间短
如上图所示,横轴为进程运行需要的时间,纵轴为频率,可以看出来峰值集中在8ms以内,也就是说大部分的进程占用CPU的时间在8ms以内,只有少部分进程占用CPU时间在8ms以上
占用时间比较少(8ms以内)的称为之为CPU密集型程序,主要利用CPU进行运算,大部分时间在CPU上运行,少部分时间用于I/O操作;占用时间比较多(8ms以上)的称之为I/O密集型程序,这类程序占用CPU的时间可能不是很多,但大部分时间在进行I/O操作。
定义
-
Whenever the CPU becomes idle,the operating system must select one of the processes in the ready queue to be executed.The selection process is carried out by the CPU scheduler.
无论何时,只要CPU空闲,操作系统就必须从就绪队列选择一个进程执行,选中的程序被CPU调度器执行
抢占调度
-
非抢占调度(Nonpreemptive scheduling)
一旦某个进程得到CPU,就会一直占用到终止或等待状态
-
抢占调度(Preemptive scheduling)
3.2 CPU调度准则
调度算法性能衡量
- CPU利用率:CPU的忙碌程度
- 响应时间:对于交互系统而言,从提交任务到第一次响应的时间
- 等待时间:进程累计在就绪队列中等待的时间
- 周转时间:从提交到完成的时间,包括在CPU中的运行时间、调度时间、等待时间
- 吞吐率:每个时钟单位处理的任务数,吞吐率越高,系统调度花费的时间就越多
- 公平性:以合理的方式让进程共享CPU,防止饥饿现象(后面会介绍饥饿现象)
调度性能指标
-
作业(job) = 进程(process)
-
假设作业i提交给系统的时刻是ts,完成时刻是tf,所需时间为tk,那么
平均作业周转时间T(ti是单个作业的周转时间)
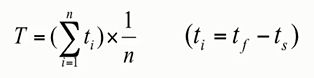
3.3 调度算法(策略)
先来先服务(FCFS)
-
First-Come,First-Served(FCFS)
也称为先进先出(First-Input,First-Output),按照进程进入就绪队列的顺序来使用CPU
- 早期系统里,FCFS意味着一个程序会一直运行到结束(尽管期间会出现等待I/O的情况)
- 如今,当一个程序阻塞时会让出CPU
- FCFS属于非抢占式调度算法
-
假如现在有三个进程:P1、P2和P3,它们在就绪队列的等待时间分别为28、9和3
如果三个进程的到达顺序为:P1、P2、P3
则等待时间分别为:P1=0,P2=28,P3=37
平均等待时间是:(0+28+37)/3 = 22
平均作业周转时间是:(28+37+40)/3 = 35
如果换一种执行顺序:P3、P2、P1
则等待时间分别是:P1=12、P2=3、P3=0
平均等待时间是:(12+3+0)/3 = 5
平均周转时间是:(3+12+40)/3 = 18
第二种排列方式比第一种要好,平均周转时间缩短为18
FCFS/FIFO的优缺点:
-
简单易行,代码很容易实现
-
如果短作业处在长作业后面将导致平均等待时间和平均周转时间变长,给短作业的用户很不好的体验
时间片轮转(ROUND ROBIN)
主要用在分时系统中,如今流行的操作系统都属于分时系统
-
每个进程都可以得到相同的CPU时间(CPU时间片,time slice),当时间片到达,进程将被剥夺CPU并加入就绪队列的尾部
-
时间片轮转属于抢占式调度算法
-
n个就绪队列中的进程和时间片p=>
每个进程获得1/n的CPU时间片,大约是q个时间单位,没有进程等待时间会超过(n-1)p
RR算法分析
时间片(time slice)选取
- 取值太小:进程切换开销显著增大(不能小于进程切换时间)
- 取值较大:响应速度下降(取值无穷大将退化成FCFS)
- 一般时间片的选取范围为10ms~100ms
- 上下文切换的时间大概为0.1ms~1ms(1%的CPU时间片开销)
RR算法优缺点:
- 公平算法,每个作业都能即使响应
- 对长作业带来额外的切换开销
比较FCFS和RR
假设有10个进程,每个花费100个CPU时间片,假设RR时间片为1,所有进程同时在就绪队列中
- RR和FCFS/FIFO会在同一时刻全部结束(忽略调度时间)
- RR的平均周转时间相当糟糕
最短作业优先(SJF)
SJF(Shortest Job Firset):下一次调度总是选择所需要CPU时间最短的那个作业
相当于FCFS/FIFO的改进版本,这是一个非抢占式算法,只有当当前进程使用完CPU之后,再从就绪队列选择一个需要CPU时间最短的作业。SJF也可以改成抢占的SRTF,当有新的进程进入到就绪队列,如果它需要的CPU时间更少,则它可以抢占CPU
SJF/SRTF算法分析
-
该算法总是将短进程移到长进程之前执行,因此平均等待时间最小,该算法被证明是最优的
-
饥饿现象:长进程可能长时间无法获得CPU
-
优缺点
优化了响应时间、难以预测作业CPU时间、不公平算法
该算法需要事先知道进程所需要的CPU时间,但预测进程需要的CPU时间并非易事,所以该算法目前只在理论层面
优先级调度(PRIORITY)
优先级通常为固定区间的数字,如[0,10]
- 数字大小与优先级高低的关系在不同系统中实现不一样,以Linux为例,0为最高优先级
- 调度策略:下一次调度总是选择优先级最高的进程
- SJF/SRTF是优先级调度的一个特例
- 优先级调度可以是抢占式,也可以是非抢占式
优先级的定义
-
静态优先级
优先级保持不变,但会出现不公平(饥饿)现象
-
动态优先级
1、根据进程占用CPU时间:当进程占用CPU时间越长,则慢慢降低它的优先级
2、根据进程等待CPU时间:当进程在就绪队列中等待时间越长,则慢慢提升它的优先级
四、Linux线程调度
4.1 创建一个线程
int main(int argc, char const *argv[])
{
pthread_t tid;
pthread_attr_t attr;
//initialize the thread attribution to DEFAULT!
pthread_attr_init(&attr);
//线程创建函数
/* 参数列表
1、thread id
2、thread attribution **
3、thread function
4、thread function arguments
*/
pthread_create(&tid,&attr,computing,NULL);
//等待指定的线程结束
//block in the join function util the tid thread terminated
pthread_join(tid,NULL);
return 0;
}
4.2 线程属性
Thread attributes:
//表示当前线程可等待,主线程可以等该线程执行完了再往下执行
Detach state = PTHREAD_CREATE_JOINABLE
//范围 PTHREAD_SCOPE_SYSTEM/PTHREAD_SCOPE_PROCESS
Scope = PTHREAD_SCOPE_SYSTEM
//继承调度器 使用父线程的调度器
Inherit scheduler = PTHREAD_INHERIT_SCHED
//调度策略
Scheduling policy = SCHED_OTHER
//调度优先级
Scheduling priority = 0
Guard Size = 4096 bytes
Stack address = 0x7f0922347000
Stack size = Ox800000 bytes
Scope:范围
-
PTHREAD_SCOPE_SYSTEM
简称SCS,系统范围内的线程
-
PTHREAD_SCOPE_PROCESS
简称PCS,进程范围内的线程
区别:
在于SCS中,CPU可以调度全局范围的线程(相当于1:1的线程模型),而在PCS中,CPU只能调度进程范围内的线程,不能跨进程调度线程(相当于M:M的线程模型),Linux采用的是SCS的方式调度。
Schedule策略及优先级
在Linux操作系统中,调度策略分为两大类
-
Normal scheduling policies(通用)
通用策略策略包含SCHED_OTHER、SCHED_IDLE和SCHED_BATCH三种调度算法,对于通用策略而言,sched_priority(调度优先级)没有任何用,并且必须设置为0
priority value = 0但在通用策略中,也有优先级之分,使用PR表示,该策略里面有个友好值Nice的概念,表示愿意放弃CPU的程度,其中Nice = [-20,19]
PR = 20 + Nice,[0,39]
-
real-time policies(实时)
实时策略包含SCHED_FIFO、SCHED_RR两种调度算法,实时策略的优先级范围在[1,99],1最低,99最高
priority value = [1,99](low~high)实时策略的优先级总是比通用策略的优先级更高对于实时策略而言,PR值的计算方式有所不同
PR = -1 - priority value,[-100,-2]
4.3 进程/线程详情
-
使用”ps -ef “查看进程信息
UID PID PPID C STIME TTY TIME CMD lizhi 8047 7390 0 13:25 pts/0 00:00:00 ./threadScheduling -
使用”ps -eLf“查看线程的详情
UID PID PPID LWP C NLWP STIME TTY TIME CM lizhi 8047 7390 8047 0 2 13:25 pts/0 00:00:00 ./threadScheduling lizhi 8047 7390 8048 0 2 13:25 pts/0 00:00:00 ./threadScheduling由ps -eLf命令可以查看线程的信息,其中PID为进程号,PPID为父进程号,LWP(Light-weight process)轻量级进程/线程号,NLWP线程数量
-
使用”top -p pid“查看进程优先级
进程 USER PR NI VIRT RES SHR � %CPU %MEM TIME+ COMMAND 8047 lizhi 20 0 80424 836 756 S 0.0 0.0 0:00.00 threadSchedulin 11 root rt 0 0 0 0 S 0.0 0.0 0:00.18 migration/0 12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject其中PR就是进程的优先级,NI表示Nice,在实时策略中,没有NI值,所以恒为0。如果进程的PR值小于0或者等于rt,就表示该进程下的线程使用是实时调度策略,其中rt=-100表示最高优先级进程
-
使用"chrt -p pid"查看进程调度策略以及优先级值
pid 8048 当前的调度策略︰ SCHED_OTHER pid 8048 的当前调度优先级:0 -
使用”chrt -f -p 20 pid“可以将进程的调度策略改为FIFO,优先级值为20
//需要用root权限来执行,需要在命令前面加上sudo //-f表示FIFO -r表示RR -p后面的数值表示优先级值 pid 8048 当前的调度策略︰ SCHED_FIFO pid 8048 的当前调度优先级:20
对于通用调度策略,它的优先级跟Nice值有关,动态优先级;对于实时调度策略,它的优先级跟Priority Value有关,只是它们对应的PR的计算方式不同.我们常说的在Linux系统中,优先级值越低优先级越高,这个优先级值指的是PR,而不是Priority Value