pytorch神经网络对Excel数据集进行处理2.0(读取,转为tensor格式,归一化),并且以鸢尾花(iris)数据集为例,实现BP神经网络
第一版本可以看1.0
第二版本与1.0不一样的地方是使用了Dataset进行预处理数据,使用起来更加方便,同时使用了SummaryWriter保存准确率数据。其中SummaryWriter使用方法看SummaryWriter,同时增加了独热编码方法:
我将以鸢尾花数据集作为例子进行展示:
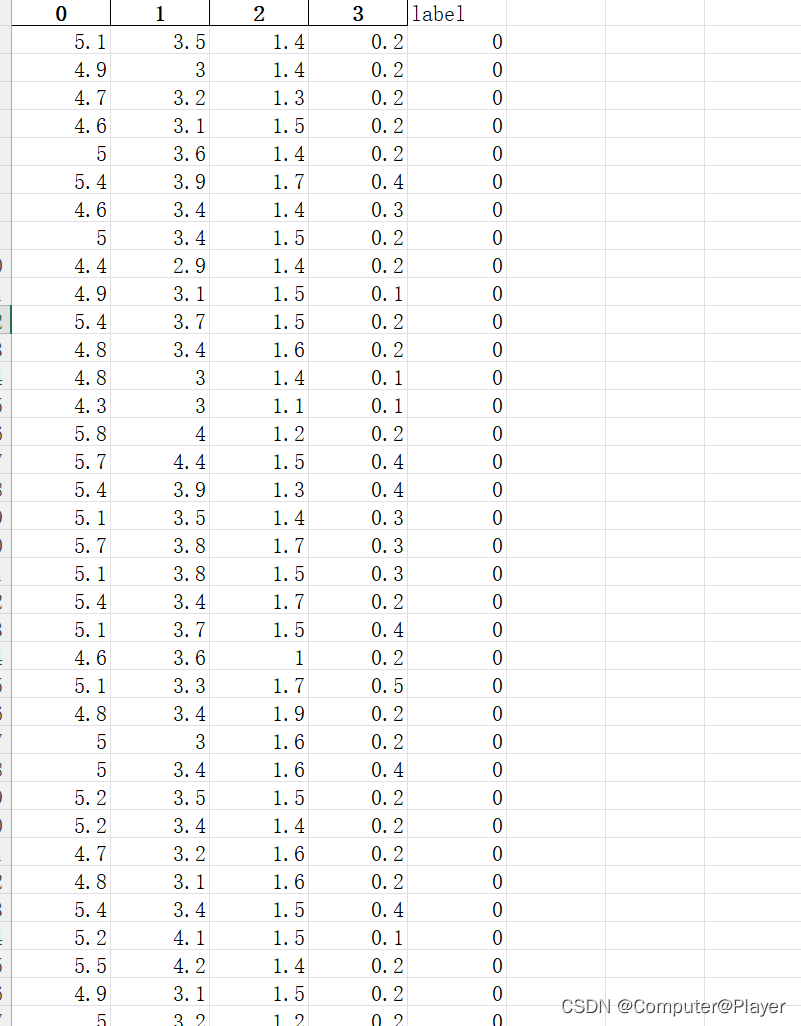
可以看到鸢尾花数据集有四个特征,分别是0,1,2,3,label是鸢尾花种类,共三种,分别以0,1,2表示。
1.使用Dataset预处理数据:
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset
import torch.nn.functional as F
class Excel_dataset(Dataset):
def __init__(self, dir, if_normalize=False, if_onehot=False):
super(Excel_dataset, self).__init__()
if (dir.endswith('.csv')):
data = pd.read_csv(dir)
elif (dir.endswith('.xlsx') or dir.endswith('.xls')):
data = pd.read_excel(dir, engine="openpyxl")
nplist = data.T.to_numpy()
data = nplist[0:-1].T
self.data = np.float64(data)
self.target = nplist[-1]
self.target_type = []
#记录标签有几类
for i in self.target:
try:
self.target_type.index(i)
except(BaseException):
self.target_type.append(i)
# print(i)
# 将标签转为自然数编码
self.target_num = []
for i in self.target:
self.target_num.append(self.target_type.index(i))
# print(self.target_type.index(i))
# Tensor化
self.data = np.array(self.data)
self.data = torch.FloatTensor(self.data)
self.target_num = np.array(self.target_num)
self.target_num = self.target_num.astype(float)
self.target_num = torch.LongTensor(self.target_num)
self.if_onehot = if_onehot
#生成独热编码
self.target_onehot = []
if if_onehot == True:
for i in self.target_num:
tar = F.one_hot(i.to(torch.int64), len(self.target_type))
self.target_onehot.append(tar)
# pass
if if_normalize == True:
self.data = nn.functional.normalize(self.data)
def __getitem__(self, index):
# tar = F.one_hot(self.target[index].to(torch.int64), len(self.target_type))
# print(tar)
if self.if_onehot == True:
return self.data[index], self.target_onehot[index]
else:
return self.data[index], self.target_num[index]
def __len__(self):
return len(self.target)
def data_split(data, rate):
train_l = int(len(data) * rate)
test_l = len(data) - train_l
"""打乱数据集并且划分"""
train_set, test_set = torch.utils.data.random_split(data, [train_l, test_l])
return train_set, test_set
使用方法:
Excel_dataset(dir, if_normalize=True,if_onehot=False)
其中dir为Excel文件路径加名字,if_normalize为数据是否归一化,默认为不归一,True为进行归一化,if_onehot为是否使用独热编码,默认为不使用。
返回值为数据集特征与标签。
举个栗子:
data = Excel_dataset('iris.xlsx', if_normalize=True)
print(data[0][0],data[0][1])
#data.data为所有的特征
print(data.data)
#data.target为所有的标签
print(data.target)
# data.target_type为所有的标签类型
print(data.target_type)
![]()
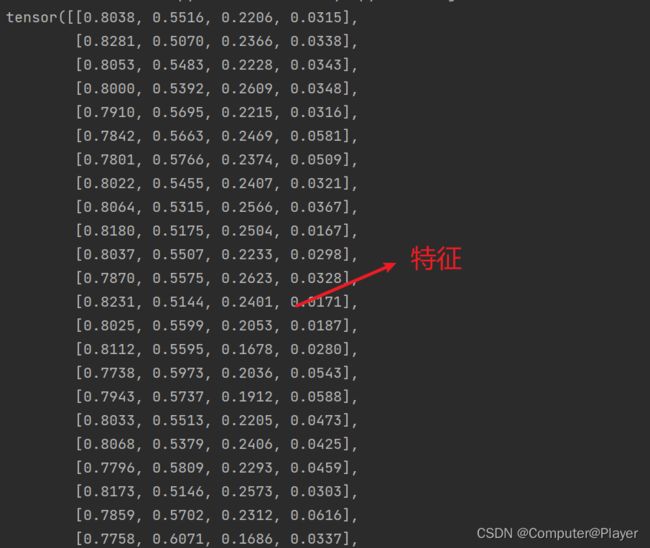
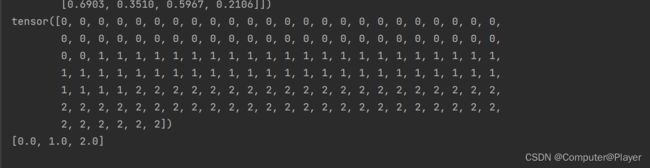
2.划分训练集测试集
def data_split(data, rate):
train_l = int(len(data) * rate)
test_l = len(data) - train_l
"""打乱数据集并且划分"""
train_set, test_set = torch.utils.data.random_split(data, [train_l, test_l])
return train_set, test_set
data_split(data, rate)中,data为Excel_dataset获取的返回值,rate为训练集所占比例,返回值为训练集和测试集数据:
data_train, data_test = data_split(data, 0.8)
3.构建神经网络
# 定义BP神经网络
class BPNerualNetwork(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(nn.Linear(4, 12),
nn.ReLU(),
nn.Linear(12, 3),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = self.model(x)
return x
4.数据预处理完毕,全部代码演示:
iris_data_load.py
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset
import torch.nn.functional as F
class Excel_dataset(Dataset):
def __init__(self, dir, if_normalize=False, if_onehot=False):
super(Excel_dataset, self).__init__()
if (dir.endswith('.csv')):
data = pd.read_csv(dir)
elif (dir.endswith('.xlsx') or dir.endswith('.xls')):
data = pd.read_excel(dir, engine="openpyxl")
nplist = data.T.to_numpy()
data = nplist[0:-1].T
self.data = np.float64(data)
self.target = nplist[-1]
self.target_type = []
#记录标签有几类
for i in self.target:
try:
self.target_type.index(i)
except(BaseException):
self.target_type.append(i)
# print(i)
# 将标签转为自然数编码
self.target_num = []
for i in self.target:
self.target_num.append(self.target_type.index(i))
# print(self.target_type.index(i))
# Tensor化
self.data = np.array(self.data)
self.data = torch.FloatTensor(self.data)
self.target_num = np.array(self.target_num)
self.target_num = self.target_num.astype(float)
self.target_num = torch.LongTensor(self.target_num)
self.if_onehot = if_onehot
#生成独热编码
self.target_onehot = []
if if_onehot == True:
for i in self.target_num:
tar = F.one_hot(i.to(torch.int64), len(self.target_type))
self.target_onehot.append(tar)
# pass
if if_normalize == True:
self.data = nn.functional.normalize(self.data)
def __getitem__(self, index):
# tar = F.one_hot(self.target[index].to(torch.int64), len(self.target_type))
# print(tar)
if self.if_onehot == True:
return self.data[index], self.target_onehot[index]
else:
return self.data[index], self.target_num[index]
def __len__(self):
return len(self.target)
def data_split(data, rate):
train_l = int(len(data) * rate)
test_l = len(data) - train_l
"""打乱数据集并且划分"""
train_set, test_set = torch.utils.data.random_split(data, [train_l, test_l])
return train_set, test_set
自然数编码:
main
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from iris_data_load import data_split, Excel_dataset
import time
from torch.utils.tensorboard import SummaryWriter
# 定义BP神经网络
class BPNerualNetwork(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == "__main__":
data = Excel_dataset('iris.xlsx', if_normalize=True)
data_train, data_test = data_split(data, 0.8)
Epoch = 1000
input_size = 4
hidden_size = 12
output_size = 3
LR = 0.005
batchsize = 30
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net = BPNerualNetwork()
optimizer = torch.optim.Adam(net.parameters(), LR)
# 设定损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 训练并且记录每次准确率,loss 函数输入为:训练输入,训练标签,测试输入,测试标签,一个batch大小
data_loader = DataLoader(data_train, batch_size=batchsize, shuffle=False)
a = time.time()
writer = SummaryWriter('logs')
for epoch in range(1001):
# print(epoch)
for step, data in enumerate(data_loader):
net.train()
inputs, labels = data
# labels = labels.to(torch.float)
# 前向传播
out = net(inputs)
# 计算损失函数
loss = loss_func(out, labels)
# 清空上一轮的梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
if epoch % 10 == 0:
net.eval()
with torch.no_grad():
total = len(data_test)
yuce = 0
test_dataloader = DataLoader(data_test, batch_size=1, shuffle=True)
j = 0
for i, (images, labels) in enumerate(test_dataloader):
# images = images.cuda(device)
# labels = labels.cuda(device)
outputs = net(images)
prediction = torch.max(outputs, 1)[1] # torch.max
pred_y = prediction.numpy() # 事先放在了GPU,所以必须得从GPU取到CPU中!!!!!!
# print(pred_y,labels.data.numpy())
if pred_y[0] == labels.data.numpy()[0]:
j += 1
acc = j / total
writer.add_scalar(f'LR={LR}的iris准确率', acc, epoch + 1)
print("训练次数为", epoch + 1, "的准确率为:", acc)
# print(pred, labels)
writer.close()
print(time.time() - a)
使用SummaryWriter查看准确率:
在终端运行:tensorboard --logdir=logs,点击链接即可看到:

独热编码
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from iris_data_load import data_split, Excel_dataset
import time
from torch.utils.tensorboard import SummaryWriter
# 定义BP神经网络
class BPNerualNetwork(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size2),
nn.ReLU(),
nn.Linear(hidden_size2, output_size),
# nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = self.model(x)
x = x.reshape(-1, 3)
return x
if __name__ == "__main__":
data = Excel_dataset('iris.xlsx', if_normalize=True, if_onehot=True)
data_train, data_test = data_split(data, 0.5)
Epoch = 1000
input_size = 4
hidden_size = 24
hidden_size2 = 12
output_size = 3
LR = 0.005
batchsize = 30
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net = BPNerualNetwork()
optimizer = torch.optim.Adam(net.parameters(), LR)
# 设定损失函数
loss_func = torch.nn.CrossEntropyLoss()
data_loader = DataLoader(data_train, batch_size=batchsize, shuffle=False)
a = time.time()
writer = SummaryWriter('logs')
for epoch in range(Epoch + 1):
# print(epoch)
for step, data in enumerate(data_loader):
net.train()
inputs, labels = data
out = net(inputs)
labels = labels.to(torch.float)
# print(out.shape)
# 计算损失函数
loss = loss_func(out, labels)
# 清空上一轮的梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
if epoch % 10 == 0:
net.eval()
with torch.no_grad():
total = len(data_test)
yuce = 0
test_dataloader = DataLoader(data_test, batch_size=1, shuffle=True)
j = 0
for i, (inputs, labels) in enumerate(test_dataloader):
# labels = labels.cuda(device)
outputs = net(inputs)
# print(outputs)
pred_y = torch.max(outputs, 1)[1].detach().numpy() # torch.max
# print(pred_y, labels.tolist())
if pred_y[0] == labels.tolist()[0].index(1):
j += 1
else:
# print(pred_y,labels.tolist())
pass
acc = j / total
writer.add_scalar(f'one_hot LR={LR}的iris准确率', acc, epoch + 1)
#
print("训练次数为", epoch + 1, "的准确率为:", acc)
#
# # print(pred, labels)
writer.close()
print(time.time() - a)
