C/C++预处理过程详细梳理(预处理步骤+宏定义#define/#include+inline函数+宏展开顺序+条件预处理+其它预处理定义)
C/C++预处理过程的详细梳理(宏定义+条件预处理+其它预处理)
目录
- C/C++预处理过程的详细梳理(宏定义+条件预处理+其它预处理)
- 1 预处理的步骤
-
- 1.1 把源代码中出现的字符映射到源字符集
- 1.2 将多个**物理行**替换成一个**逻辑行**
- 1.3 将注释替换为空格
- 1.4 将**逻辑行**划分成预处理记号(Token)和空白字符
- 1.5 宏展开,处理#include预处理指示
- 1.6 将转义序列替换
- 1.7 连接相邻字符串
- 1.8 丢弃空白字符,如空格和Tab等
- 2 宏定义
-
- 2.1 变量宏定义和函数宏定义:#define
-
- 2.1.1 宏定义与函数的不同点
- 3 内联函数(C99)
- 4 #、##运算符和可变参数
-
- 4.1 `#`号运算符:创建字符串
- 4.2 `##`号运算符:连接两个预处理Token
- 4.3 `…`:宏定义的可变参数`__VA_ARGS__`
- 5 宏展开的顺序(不会递归展开)
- 文件包含:#include
- 6 #undef指令
- 7 条件编译
- 8 预定义宏
- 9 泛型选择
C预处理器在程序执行之前查看程序,根据程序中的预处理指令,预处理器把符号缩写替换成其表示的内容。基本上它的工作就是文本替换。
1 预处理的步骤
1.1 把源代码中出现的字符映射到源字符集
字符常量要用单引号括起来,例如 ‘}’ ,注意单引号只能括一个字符而不能像双引号那样括一串字符,字符常量也可以是一个转义序列,例如 ‘\n’ ,这时虽然单引号括了两个字符,但实际上只表示一个字符。和字符串字面值中使用转义序列有一点区别,如果在字符常量中要表示双引号"和问号?,既可以使用转义序列 " 和 ? ,也可以直接用字符"和?,而要表示’和\则必须使用转义序列。C语言规定了一些三连符(Trigraph),在某些特殊的终端上缺少某些字符,需要用Trigraph输入,例如用 ??= 表示#字符。预处理首先就是将这些三连符替换成相应的单字符。
1.2 将多个物理行替换成一个逻辑行
把用 \ 字符续行的多行代码接成一行。定位每个反斜杠后面跟着的换行符实例,并删除它们,这种续行的写法要求 \ 后面紧跟换行,中间不能有其它空白字符。例如:
//两个物理行
printf("That is wond\
erful!\n");
//转换成一个逻辑行:
printf("That is wonderful!\n");
#define STR "hello, "\
"world" //world前面的是tab
//会变成如下形式
#define STR "hello, " "world"
1.3 将注释替换为空格
编译器将用一个空格字符替换每一条注释,不管是单行注释还是多行注释都替换成一个空格。
int/*这看起来并不是空格*/fox;
//会变成:
int fox;
1.4 将逻辑行划分成预处理记号(Token)和空白字符
预处理Token包括标识符、整数常量、浮点数常量、字符常量、字符串、运算符和其它符号。继续上面的例子,两个源代码行被接成一个逻辑代码行,然后这个逻辑代码行被划分成Token和空白字符(+号为方便描述所加):
#+ define + 空格 + STR + 空格 + "hello+ " + Tab + Tab + “world”
1.5 宏展开,处理#include预处理指示
如果遇到 #include预处理指示,则把相应的源文件包含进来,并对源文件做以上1-4步预处理。如果遇到宏定义则做宏展开。
1.6 将转义序列替换
找出字符常量或字符串中的转义序列,用相应的字节来替换它,比如把 \n 替换成字节0x0a。
1.7 连接相邻字符串
比如有如下代码:
printf(
STR);
经过第四步逻辑行处理后,可得到以下Token:
printf + ( + 换行 + Tab + STR + ) + ; + 换行
再经过第五步宏展开,可得:
printf + ( + 换行 + Tab + "hello, " + Tab + Tab + “world” + ) + ; + 换行
然后把相邻的字符串连接起来,其中"hello, " 和 "world"两个字符串可以连接在一起,最后结果为:
printf + ( + 换行 + Tab + "hello, " + “world” + ) + ; + 换行
1.8 丢弃空白字符,如空格和Tab等
经过以上处理之后,把空白字符丢掉,把Token交给C编译器做语法解析,这时就不再是预处
理Token,而称为C Token了。这里丢掉的空白字符包括
空格、换行、水平Tab、垂直Tab、分页符。
继续上面的例子,最后交给C编译器做语法解析的Token是:
printf + ( + “hello,world” + ) + ;
注意,把一个预处理指示写成多行要用 \ 续行,因为根据定义,一条预处理指示只
能由一个逻辑代码行组成,而把C代码写成多行则不需要用 \ 续行,因为换行在C代码中只不过是一种空白字符,在做语法解析时所有空白字符都已经丢掉了。
现在我们可以给出预处理指示的严格定义:
一条预处理指示由一个逻辑代码行组成,以 # 开头,后面跟若干个预处理Token,在预处理指示中允许使用的空白字符只有空格和Tab。
2 宏定义
2.1 变量宏定义和函数宏定义:#define
使用#define来定义明示常量,也叫符号常量。预处理器指令从#开始运行,到后面的第一个换行符为止,也就是说指令的长度仅限于一行(逻辑行)。
示例程序1:
// main1.c
#include在命令行中可以使用如下两个命令,对main1.c程序进行预处理:
gcc -E main1.c
cpp main1.c
得到的结果如下:
int main(void)
{
int x = 2;
printf("X is %d.\n",x);
x = 2*2;
printf("X is %d.\n",x);
printf("%s\n","This is a test.have a try");
printf("TWO:OW\n");
x = x*x;
printf("The result is %d.\n",x);;
printf("The result is %d.\n",x + 2*x + 2);;
printf("The result is %d.\n",x++*x++);;
int x1 = 14;
int x2 = 20;
int x3 = 30;
printf("x" "1" " = %d\n", x1);;
printf("x" "2" " = %d\n", x2);;
printf("x" "3" " = %d\n", x3);;
return 0;
}
下图为经过预处理之后的代码与原始的程序的代码对比图:
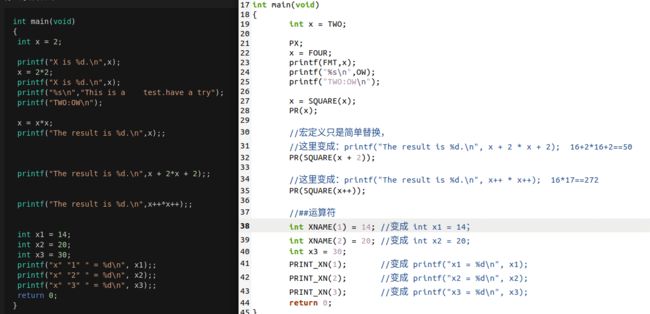
关于函数宏定义的注意事项可以参考博客:
https://blog.csdn.net/luolaihua2018/article/details/123935238
总结来说,函数式宏定义和真正的函数有以下不同点:
2.1.1 宏定义与函数的不同点
-
宏定义的参数没有类型, 预处理器只负责做形式上的替换,而不做参数类型检查,所以传参时要格外小心。
-
调用真正函数的代码和调用函数式宏定义的代码编译生成的指令不同。宏定义是简单的字符替换,每调用一次就替换一次。而函数需要进行传参和跳转,函数的调用也要编译生成传参指令和call指令。从代码量角度来讲,函数不管有多少次调用,在内存中只有一个函数体。而宏定义调用一次就有一个宏定义展开。
-
函数式的宏定义要格外要注意不能省去 保护参数的括号 以及外层括号,比如宏定义:
#define SQUARE(X) X*X-1
它的原意是求X的平方再减一,若X = a-b,则 原始会被替换成 z = a-b*a-b-1,导致计算错误,所以原始应写成:
#define SQUARE(X) (X)*(X)-1
事实上除了保护参数的括号,外层括号也不能省去,比如 y = SQUARE(X) * SQUARE(X),X = a-b。在宏展开后,y = ( a-b)( a-b)-1 * ( a-b)( a-b)-1,和函数原意不符,导致计算错误,所以正确的写法应为:
#define SQUARE(X) ((X)*(X)-1)
-
调用函数时先求实参表达式的值再传给形参,如果实参表达式有副作用Side Effect,那么这些Side
Effect只发生一次。例如MAX(++a, ++b),如果MAX是个真正的函数, a和b只增加一次。但如果MAX是
上面那样的宏定义,则要展开成k = ((++a)>(++b)?(++a):(++b)), a和b就不一定是增加一次还是两次了。 -
即使实参没有Side Effect,使用函数式宏定义也往往会导致较低的代码执行效率。
尽管函数式宏定义和真正的函数相比有很多缺点,但只要小心使用还是会显著提高代码的执行效率,毕竟省去了分配和释放栈帧、传参、传返回值等一系列工作,因此那些简短并且被频繁调用的函数经常用函数式宏定义来代替实现。例如C标准库的很多函数都提供两种实现,一种是真正的函数实现,一种是宏定义实现。
3 内联函数(C99)
C99引入一个新关键字inline,用于定义内联函数(inline function)。通常函数的调用都有一定的开销,因为函数的调用包括建立调用、传递参数、跳转到函数代码并返回。内联函数就是以空间换时间,使函数的调用更加快捷。
标准规定:具有内部链接的函数可以成为内联函数,还规定了内联函数的定义与调用该函数的代码必须在同一个文件中。因此最简单的办法是使用inline和static修饰。通常,内联函数应定义在首次使用它的文件中,所以内联函数也相当于函数原型。
关于内联函数的细节描述,可以参考博文:和宏一样快的内联函数( An Inline Function is As Fast As a Macro)
如下示例程序:
#include该程序定义了一个内联函数MAX(),并定义了一个max()函数,通过递归以求出数组a中值最大的元素。此外,需要注意以下几点:
-
在日常使用内联函数时,并不建议对内联函数进行嵌套使用(递归),因为内联函数也是类似宏定义的字符串替换,嵌套使用很容易造成代码量增大和冗余。
-
static 关键字不能省略,要将内联函数定义为 静态static函数,读者可以尝试将static关键字去除,
并使用
gcc main.c -g命令进行编译 。编译器会报出undefined reference to MAX的错误,关于此错误的解析可以参考博客:gcc编译inline函数报错:未定义的引用
对main.c进行编译后,然后反汇编:
$ gcc main.c -g
$ objdump -dS a.out
在关于MAX()和max()函数的汇编部分,可以看到:
static inline int MAX(int a, int b)
{
1149: 55 push %rbp
114a: 48 89 e5 mov %rsp,%rbp
114d: 89 7d fc mov %edi,-0x4(%rbp)
1150: 89 75 f8 mov %esi,-0x8(%rbp)
return a > b ? a : b;
1153: 8b 45 fc mov -0x4(%rbp),%eax
1156: 39 45 f8 cmp %eax,-0x8(%rbp)
1159: 0f 4d 45 f8 cmovge -0x8(%rbp),%eax
}
115d: 5d pop %rbp
115e: c3 retq
int max(int n)
{
115f: f3 0f 1e fa endbr64
1163: 55 push %rbp
1164: 48 89 e5 mov %rsp,%rbp
1167: 48 83 ec 10 sub $0x10,%rsp
116b: 89 7d fc mov %edi,-0x4(%rbp)
return n == 0 ? a[0] : MAX(a[n], max(n-1));
116e: 83 7d fc 00 cmpl $0x0,-0x4(%rbp)
1172: 75 08 jne 117c
1174: 8b 05 a6 2e 00 00 mov 0x2ea6(%rip),%eax # 4020
117a: eb 2f jmp 11ab
117c: 8b 45 fc mov -0x4(%rbp),%eax
117f: 83 e8 01 sub $0x1,%eax
1182: 89 c7 mov %eax,%edi
1184: e8 d6 ff ff ff callq 115f
1189: 89 c2 mov %eax,%edx
118b: 8b 45 fc mov -0x4(%rbp),%eax
118e: 48 98 cltq
1190: 48 8d 0c 85 00 00 00 lea 0x0(,%rax,4),%rcx
1197: 00
1198: 48 8d 05 81 2e 00 00 lea 0x2e81(%rip),%rax # 4020
119f: 8b 04 01 mov (%rcx,%rax,1),%eax
11a2: 89 d6 mov %edx,%esi
11a4: 89 c7 mov %eax,%edi
11a6: e8 9e ff ff ff callq 1149
}
11ab: c9 leaveq
11ac: c3 retq
在倒数第四行可以看到MAX函数的调用call命令:11a6: e8 9e ff ff ff callq 1149 ,说明MAX()函数此时是作为普通函数使用的。
如果使用-O选项指定GCC进行优化编译,然后反汇编:
$ gcc main.c -g -O
$ objdump -dS a.out
可以看到max()函数的汇编代码,但是没有MAX()函数的汇编:
int max(int n)
{
1149: f3 0f 1e fa endbr64
return n == 0 ? a[0] : MAX(a[n], max(n-1));
114d: 85 ff test %edi,%edi
114f: 75 07 jne 1158
1151: 8b 05 c9 2e 00 00 mov 0x2ec9(%rip),%eax # 4020
}
1157: c3 retq
{
1158: 53 push %rbx
1159: 89 fb mov %edi,%ebx
return n == 0 ? a[0] : MAX(a[n], max(n-1));
115b: 8d 7f ff lea -0x1(%rdi),%edi
115e: e8 e6 ff ff ff callq 1149
1163: 48 8d 15 b6 2e 00 00 lea 0x2eb6(%rip),%rdx # 4020
116a: 48 63 db movslq %ebx,%rbx
return a > b ? a : b;
116d: 39 04 9a cmp %eax,(%rdx,%rbx,4)
1170: 0f 4d 04 9a cmovge (%rdx,%rbx,4),%eax
}
1174: 5b pop %rbx
1175: c3 retq
可以看到,并没有call指令调用MAX函数, MAX函数的指令是内联在max函数中的,由于源代码和指令的次序无法对应, max和MAX函数的源代码也交错在一起显示。 因为MAX()函数已经嵌入到max()函数里面了,此时编译器把MAX()函数当作内联函数,所以没有给它分配单独的代码空间,所以也无法获得该内联函数的地址。
关于C语言的内联函数的使用总结,有如下几点:
- 由于并未给内联函数预留单独的代码块,所以无法获得内联函数的地址,另外,内联函数无法在调试器中显示。
- 由于内联函数具有内部链接,所以在多个文件中定义同一个内联函数不会产生什么影响。
- 如果多个文件都需要使用同一个内联函数,可以将它定义在h头文件中。
4 #、##运算符和可变参数
4.1 #号运算符:创建字符串
在函数式宏定义中, #运算符用于创建字符串, #运算符后面应该跟一个形参(中间可以有空格或Tab),例如:
//define.c
#include使用cpp指令将define.c文件进行预处理:cpp define.c,可以看到:
# 11 "define.c"
int main()
{
printf("hello world \n");
printf("strncmp(\"ab\\\"c\\0d\", \"abc\", '\\4\"') == 0" ": @\n");
return 0;
}
注意,如果实参中包含字符常量或字符串,则宏展开之后字符串的界定符"要替换成 \",字符常量或字符
串中的\和"字符要替换成\\和\"。 最后打印出的结果为:
$ gcc define.c
$ ./a.out
hello world
strncmp("ab\"c\0d", "abc", '\4"') == 0: @
4.2 ##号运算符:连接两个预处理Token
在宏定义中可以用##运算符把前后两个预处理Token连接成一个预处理Token,和#运算符不同, ##运算符不仅限于函数式宏定义,变量式宏定义也可以用。例如:
//预处理粘合剂:##运算符
#define XNAME(n) x ## n
#define PRINT(f) print ## f
#define PRINT_XN(n) printf("x" #n " = %d\n", x ## n);
int main()
{
int XNAME(3) = 666;
PRINT(f)("Hello\n");
PRINT_XN(3)
return 0;
}
使用命令 cpp define.c查看经过预处理之后的代码:
int main()
{
int x3 = 666;
printf("Hello\n");
printf("x" "3" " = %d\n", x3);
return 0;
}
使用gcc编译并运行:
$ gcc define.c
$ ./a.out
Hello
x3 = 666
如果宏定义里全是 #号呢,如下示例:
//会被编译器看做是两个#:##
#define H # ## #
// 预处理报错:
#define HH ####
中间的##是运算符,宏展开时前后两个#号被这个运算符连接在一起。注意中间的两个空格是不可少的,如果写成####,会被划分成##和##两个Token,而根据定义##运算符用于连接前后两个预处理Token,不能出现在宏定义的开头或末尾,所以会报错:
# 8 "define.c" 2
define.c:17:9: error: '##' cannot appear at either end of a macro expansion
17 | #define HH ####
| ^~
4.3 …:宏定义的可变参数__VA_ARGS__
C语言中的 printf() 和 scanf() 函数其输入的参数可变,宏定义的参数也可以带可变的参数。它主要使用 …与__VA_ARGS__配合使用,示例代码如下:
#define showlist(...) printf(#__VA_ARGS__)
#define report(test,...) ((test) ? printf(#test) : printf(__VA_ARGS__))
//no param
showlist();
// multi params
showlist(The first, second, and third items.);
//no param
report();
// multi params
report(x>y, "x is %d but y is %d", x, y);
第一个showlist宏定义内可以输入可变的参数,并且通过#号将输入的所有可变参数转成字符串。第二个宏定义report指定了第一个参数为test,之后的参数为可变参数。将上述代码进行预处理可得:
printf("");
printf("The first, second, and third items.");
(() ? printf("") : printf());
((x>y) ? printf("x>y") : printf("x is %d but y is %d", x, y));
在宏定义中,可变参数的部分用__VA_ARGS__表示,实参中对应...的几个参数可以看成一个参数替
换到宏定义中__VA_ARGS__所在的地方。调用函数式宏定义允许传空参数,这一点和函数调用不同,读者可以通过下面几个例子理解空参数的用法。
#define FOO() foo
FOO() //foo
FOO(2) //报错,不允许传参数
预处理之后变成foo。 FOO在定义时不带参数,在调用时也不允许传参数给它,否则将会报错:
define.c:35:6: error: macro "FOO" passed 1 arguments, but takes just 0
35 | FOO(2)
| ^
define.c:32: note: macro "FOO" defined here
32 | #define FOO() foo
|
反之,如果宏定义中带了参数,在调用时必须传参数给它,如果不传参数则表示传了一个空参数。
#define FOO(a) foo##a
FOO(bar)
FOO()
预处理之后变成:
foobar
foo
如果宏定义中带了多个参数,比如:
#define FOO(a,b,c) x##a##b##c
FOO() //一个参数都不传,报错
FOO(1,2,3)
FOO(1,,3)
FOO(,,3)
它预处理后的结果为:
FOO
x123
x13
x3
FOO在定义时带三个参数,在调用时也必须传三个参数给它,空参数的位置可以空着,但必须给够
三个参数, FOO(1,2)这样的调用是错误的。
再看一个示例:
#define FOO(a, ...) a##__VA_ARGS__
FOO(1)
FOO(1,2,3,)
预处理之后变成:
1
12,3,
FOO(1)这个调用相当于可变参数部分传了一个空参数, FOO(1,2,3,)这个调用相当于可变参数部分传
了三个参数,第三个是空参数。
5 宏展开的顺序(不会递归展开)
虽然宏展开只是简单的字符替换,但是在宏展开中也要注意展开的顺序以及可能需要做多次替换。如下示例:
#define sh(x) printf("n" #x "=%d, or %d\n",n##x,alt[x])
#define sub_z 26
sh(sub_z)
sh(sub_z)要用sh(x)这个宏定义来展开,形参x对应的实参是sub_z,替换过程如下:
#x要替换成字符串"sub_z"。n##x要替换成nsub_z。- 除了带
#和##运算符的参数之外,其它参数在替换之前要对实参本身做充分的展开,所以应该先把sub_z展开成26再替换到alt[x]中x的位置。 - 现在展开成了printf(“n” “sub_z” “=%d, or %d\n”,nsub_z,alt[26]),所有参数都替换完
了,这时编译器会再扫描一遍,再找出可以展开的宏定义来展开,假设nsub_z或alt是变量式
宏定义,这时会进一步展开。
最后结果为:
printf("n" "sub_z" "=%d, or %d\n",nsub_z,alt[26])
还有一个比较复杂的例子:
#define x 3
#define f(a) f(x * (a))
#undef x
#define x 2
#define g f
#define t(a) a
t(t(g)(0) + t)(1);
展开的步骤是:
- 先把
g展开成f再替换到#define t(a) a中,得到t(f(0) + t)(1);。 - 根据
#define f(a) f(x * (a)),得到t(f(x * (0)) + t)(1);。 - 把
x替换成2,得到t(f(2 * (0)) + t)(1);。注意,一开始定义x为3,但是后来用#undef x取消了x的定义,又重新定义x为2。当处理到t(t(g)(0) + t)(1);这一行代码时x已经定义成2了,所以用2来替换。还要注意一点,现在得到的t(f(2 * (0)) + t)(1);中仍然有f,但不能再次根据#define f(a) f(x * (a))展开了,f(2 * (0))就是由展开f(0)得到的,这里面再遇到f就不展开了,这样规定可以避免无穷展开(类似于无穷递归),因此我们可以放心地使用递归定义,例如#define a a[0],#define a a.member等。 - 根据
#define t(a) a,最终展开成f(2 * (0)) + t(1);。这时不能再展开t(1)了,因为这里
的t就是由展开t(f(2 * (0)) + t)得到的,所以不能再展开了。
文件包含:#include
当预处理器发现#include时,会查看后面的文件名,并把文件的内容包含到当前文件中,即替换源文件中的#include指令。
6 #undef指令
#undef指令用于取消已定义的#define指令
假如有如下定义:
#define LIMIT 100
然后又有如下指令:
#undef LIMIT
将移除上面的定义,可以将LIMIT重新定义一个新值,即使原来没有定义LIMIT,取消LIMIT定义仍然有效,如果想使用一个名称,又不确定之前是否用过,为了安全起见,可以使用#undef指令取消改名字的定义。
7 条件编译
可以使用这些指令告诉编译器根据编译时的条件执行或忽略代码块。
#include8 预定义宏
C99引入一个特殊的标识符__func__支持这一功能。这个标识符应该是一个变量名而不是宏定义,不属于预处理的范畴,但它的作用和__FILE__、 __LINE__类似:
#include9 泛型选择
在程序设计中,泛型编程指那些没有特定类型,但一旦指定一种类型,既可以转换成指定类型的代码。C++在模板中可以创建泛型算法,然后编译器根据指定的类型自动使用实例化代码。C11新增了一种表达式,叫作泛型选择表达式,可根据表达式的类型选择一个值。
-Generic(x, int: 0,float: 1, double: 2, default: 3)
_Generic是C11的关键字,第一个项是一个表达式,后面每个项都由一个类型、一个冒号和一个值组成。
#include些没有特定类型,但一旦指定一种类型,既可以转换成指定类型的代码。C++在模板中可以创建泛型算法,然后编译器根据指定的类型自动使用实例化代码。C11新增了一种表达式,叫作泛型选择表达式,可根据表达式的类型选择一个值。
-Generic(x, int: 0,float: 1, double: 2, default: 3)
_Generic是C11的关键字,第一个项是一个表达式,后面每个项都由一个类型、一个冒号和一个值组成。
#include