算法导论-上课笔记5:动态规划/中位数和顺序统计量
文章目录
- 0 动态规划与分治法
- 1 钢条切割
- 2 矩阵链乘法
-
- 2.1 最优括号化方案的结构特征
- 2.2 一个递归求解方案
- 2.3 计算最优代价
- 2.4 构造最优解
- 3 动态规划原理
-
- 3.1 最优子结构
- 3.2 一些微妙之处
- 3.3 重叠子问题
- 3.4 重构最优解
- 3.5 备忘
- 4 最长公共子序列
- 5 最优二叉搜索树
- 6 中位数和顺序统计量
-
- 6.1 最小值和最大值
- 6.2 期望为线性时间的选择算法
- 6.3 最坏情况为线性时间的选择算法
0 动态规划与分治法
动态规划(dynamic programming)与分治方法相似,都是通过组合子问题的解来求解原问题。其中,分治方法将问题划分为互不相交的子问题,递归地求解子问题,再将它们的解组合起来,求出原问题的解;动态规划应用于子问题重叠的情况,即不同的子问题具有公共的子子问题,这里子问题的求解是递归进行的,会将子问题划分为更小的子子问题。有时分治算法会做许多不必要的工作——反复地求解那些公共子子问题。但是动态规划算法对每个子子问题只求解一次,然后将其解保存在一个表格中,从而无需每次求解一个子子问题时都重新计算,避免了不必要的计算工作。
动态规划方法通常用来求解最优化问题(optimization problem)。这类问题可能有很多可行解,其中每个可行解都对应着某个值,动态规划的目标是寻找具有最优值(最小值或最大值)的解,称这样的解为问题的一个最优解(an optimal solution),而不只说是最优解(the optimal solution),这是因为可能有多个可行解都达到最优值。通常按如下4个步骤来设计一个动态规划算法:
1、刻画一个最优解的结构特征。
2、递归地定义最优解的值。
3、计算最优解的值,通常采用自底向上的方法。
4、利用计算出的信息构造一个最优解。
在上面的步骤中,1、2、3是动态规划算法求解问题的基础,如果仅仅需要一个最优解的值,而非解本身,可以忽略4。如果确实要做步骤4,可能需要在执行3的过程中维护一些额外信息,以便用来构造一个最优解。
1 钢条切割
不会更新此内容。
2 矩阵链乘法
本节介绍的是求解矩阵链相乘问题的动态规划算法。
给定一个由n个矩阵构成的序列,即矩阵链
1、(A1(A2(A3A4)));
2、(A1((A2A3)A4));
3、((A1A2)(A3A4));
4、((A1(A2A3))A4);
5、(((A1A2)A3)A4);
对矩阵链加括号的方式会对乘积运算的代价产生巨大影响。现在分析两个矩阵相乘的代价。下面的伪代码给出了两个矩阵相乘的标准算法,其中属性rows和columns分别是矩阵的行数和列数:
MATRIX-MULTIPLY(A,B)
if A.columns!=B.rows
error "incompatible dimensions"
else let C be a new A.rows×B.columns matrix
for i=1 to A.rows
for j=1 to B.columns
c[i][j]=0
for k=1 to A.columns
c[i][j]=c[i][j]+a[i][k]*b[k][j]
return C
两个矩阵A和B只有相容(compatible),即A的列数等于B的行数时,才能相乘。如果A是p×q的矩阵,B是q×r的矩阵,那么矩阵C=A·B是p×r的矩阵。计算C所需时间由上述伪代码第9行的标量乘法的次数即p·q·r决定。下面使用标量乘法的次数来表示计算所需要的代价。
以矩阵链
1、如果按((A1A2)A3)的顺序计算,为计算矩阵规模是10×5的A1A2需要做10·100·5=5000次标量乘法,再与A3相乘又需要做10·5·50=2500次标量乘法,共需7500次标量乘法。
2、如果按(A1(A2A3))的顺序,计算矩阵规模是100×50的A2A3,需100·5·50=25000次标量乘法,A1再与之相乘又需10·100·50=50000次标量乘法,共需75000次标量乘法。
因此,按第一种顺序计算矩阵链乘积要比第二种顺序快10倍。
矩阵链乘法问题(matrix-chain multiplication problem)可描述为:给定由n个矩阵构成的序列
注意,求解矩阵链乘法问题并不是要真正进行矩阵相乘运算,算法的目标只是确定代价最低的计算顺序,而确定最优计算顺序所花费的时间通常要比随后真正进行矩阵相乘所节省的时间要少。
在用动态规划方法求解矩阵链乘法问题之前,首先需要知道——只是穷举所有可能的括号化方案不会产生一个高效的算法。对一个由n个矩阵构成的链,令P(n)表示可供选择的括号化方案的数量。当n=1时,由于只有一个矩阵,因此只有一种完全括号化方案。当n≥2时,完全括号化的矩阵乘积可描述为两个完全括号化的部分积相乘的形式,而两个部分积的划分点在第k个矩阵和第k+1个矩阵之间,其中k为1,2,…,n-1中的任意一个值。因此,可以得到如下递归公式:
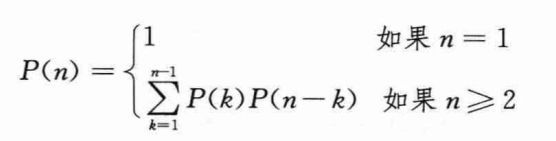
上述递归公式的结果为Ω(2n),即括号化方案的数量与n呈指数关系,因此通过暴力搜索穷尽所有可能的括号化方案来寻找最优方案,是一个糟糕的策略。
下面用动态规划方法来求解矩阵链的最优括号化方案,按照本博文开头提出的4个步骤依次进行。
2.1 最优括号化方案的结构特征
动态规划方法的第一步是寻找最优子结构,然后就可以利用这种子结构从子问题的最优解构造出原问题的最优解。在矩阵链乘法问题中,此步骤的做法如下所述。
为方便起见,用符号Ai…j表示AiAi+1…Aj乘积的结果矩阵,其中i≤j。可以看出,如果问题是非平凡的,即i
下面给出本问题的最优子结构。
假设AiAi+1…Aj的最优括号化方案的分割点在Ak和Ak+1之间,则继续对“前缀”子链AiAi+1…Ak进行括号化时,应该直接采用独立求解它时所得的最优方案,因为如果不采用独立求解AiAi+1…Ak所得的最优方案来对它进行括号化,那么可以将此最优解代入AiAi+1…Aj的最优解中,代替原来对子链AiAi+1…Ak进行括号化的方案(这个方案比AiAi+1…Ak最优解的代价更高呢),显然,这样得到的解比AiAi+1…Aj原来的“最优解”代价更低——这时产生了矛盾,因此对“前缀”子链AiAi+1…Ak进行括号化时,应该直接采用独立求解它时所得的最优方案。同样地,对子链Ak+1Ak+2…Aj,有相似的结论——在原问题AiAi+1…Aj的最优括号化方案中,对子链Ak+1Ak+2…Aj进行括号化的方法,就是它自身的最优括号化方案。
现在展示如何利用最优子结构性质从子问题的最优解构造原问题的最优解。一个非平凡的矩阵链乘法问题实例的任何解都需要划分链,而任何最优解都是由子问题实例的最优解构成的。因此,为了构造一个矩阵链乘法问题实例的最优解,可以:
1、将问题划分为两个子问题,即AiAi+1…Ak和Ak+1Ak+2…Aj的最优括号化问题;
2、求出两个子问题实例的最优解;
3、最后将子问题的最优解组合起来。
在上述过程中,必须保证在确定分割点时,已经考察了所有可能的划分点,这样就可以保证不会遗漏最优解。
2.2 一个递归求解方案
下面用子问题的最优解来递归地定义原问题最优解的代价。对矩阵链乘法问题,可以将对所有1≤i≤j≤n确定AiAi+1…Aj的最小代价括号化方案作为子问题。令m[i,j]表示计算矩阵Ai…j所需标量乘法次数的最小值,那么,原问题的最优解——计算Ai…n所需的最低代价就是m[1,n]。
递归地定义m[i,j]如下。
对于i=j时的平凡问题,矩阵链只包含唯一的矩阵Ai…i=Ai,因此不需要做任何标量乘法运算。所以,对所有i=1,2,…,n,有m[i,i]=0。若i
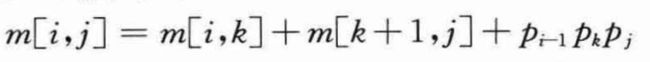
上述递归公式假定最优分割点k是已知的,但实际上是不知道的。不过,k只有j-i种可能的取值,即k=i,i+1,…,j-1。由于最优分割点必在其中,故只需检查所有可能情况,找到最优者即可。因此,AiAi+1…Aj最小代价括号化方案的递归求解公式变为:
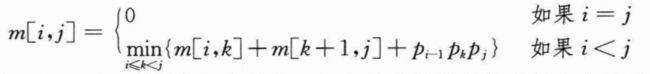
上述m[i,j]的值给出了子问题最优解的代价,但它并未提供足够的信息来构造最优解。为此,需要用s[i,j]保存AiAi+1…Aj最优括号化方案的分割点位置k,也就是使得m[i,j]=m[i,k]+m[k+1,j]+pi-1·pk·pj成立的k值。
2.3 计算最优代价
现在可以基于上一节最后一张图片中的递归公式(以后再提到就称是递归公式A了)写出一个递归算法,来计算A1·A2·…·An相乘的最小代价m[1,n]了。
必须明确的是,需要求解的不同子问题的数目是相对较少的:每对满足1≤i≤j≤n的i和j对应一个唯一的子问题,共有:
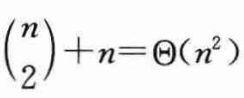
个。上式中,等号左面有两部分:
1、第一部分是从n个位置中选择出两个不同的整数i,j,其中i≠j,子问题个数是一个组合数;
2、第二部分是从n个位置中选择出两个相同的整数i,j,其中i=j,共有n个子问题。
递归算法会在递归调用树的不同分支中多次遇到同一个子问题。这种子问题重叠的性质是应用动态规划的标识之一。
现在采用自底向上表格法代替基于递归公式A的递归算法来计算最优代价,后面的章节中会给出对应的带备忘的自顶向下方法。
首先假定矩阵Ai的规模为pi-1×pi,其中i=1,2,…,n。算法的输入是一个序列p=
为了实现自底向上方法,必须确定计算m[i,j]时需要访问哪些其他表项。递归公式A显示,j-i+1个矩阵链相乘的最优计算代价m[i,j]只依赖于那些少于j-i+1个矩阵链相乘的最优计算代价。也就是说,对k=i,i+1,…,j-1,矩阵Ai…k是k-i+1个矩阵的积,矩阵Ak+1,j是j-k个矩阵的积,其中k-i+1
下面给出MATRIX-CHAIN-ORDER实现了自底向上表格法的伪代码:
MATRIX-CHAIN-ORDER(p)
n=p.length-1 //n为矩阵个数
let m[1..n,1..n] and s[1..n-1,2..n] be new tables
for i=1 to n
m[i,i]=0
for l=2 to n //l是链的长度,从链长为2的矩阵链开始递增计算
for i=1 to n-l+1
j=i+l-1
m[i,j]=∞
for k=i to j-1
q=m[i,k]+m[k+1,j]+p(i-1)*pk*pj
if q<m[i,j]
m[i,j]=q
s[i,j]=k
return m and s
下面是对上述伪代码的部分解释:
1、首先在第4-5行,是对所有i=1,2,…,n,令m[i,i]=0,这是长度为1的链的最小计算代价。
2、在第6-14行的for循环的第一个循环步中,利用递归公式A对所有i=1,2,…,n-1,去计算m[i,i+1],这是长度l=2的链的最小计算代价。
3、在第6-14行的for循环的第二个循环步中,算法对所有i=1,2,…,n-2计算m[i,i+2],这是长度l=3的链的最小计算代价,依此类推…
4、在第6-14行的for循环的每个循环步中,第11-14行计算代价m[i,j]时仅依赖于已经计算出的表项m[i,k]和m[k+1,j]。
简单分析MATRIX-CHAIN-ORDER的嵌套循环结构,可以看到算法的运行时间为O(n3)——因为循环嵌套的深度为三层,而每层的循环变量(l、i和k)最多取n-1个值。
除此之外,算法还需要Θ(n2)的内存空间来保存表m和s。因此,MATRIX-CHAIN-ORDER比起穷举所有可能的括号化方案来寻找最优解的指数阶算法要高效得多呢!
当矩阵链长度为6,且矩阵规模如下表时:

算法MATRIX-CHAIN-ORDER计算出的m表和s表如下图:
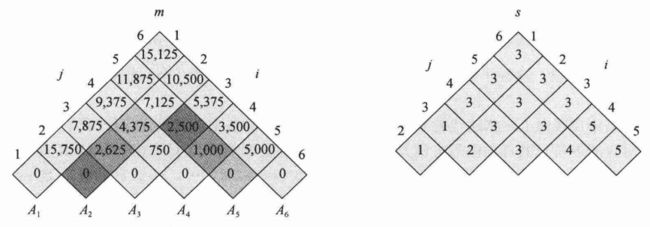
上面的两个表均进行了旋转,使得主对角线方向变为水平方向。表m只使用主对角线和上三角部分,表s只使用上三角部分。我手写了表m与表s的计算过程如下:
由表m可知,6个矩阵相乘所需的最少标量乘法运算次数为m[1,6]=15125。
由于定义的m[i,j]仅在i≤j时有意义,因此表m只使用主对角线及之上的部分。在这种布局中,可以看到子矩阵链Ai·Ai+1·…·Aj相乘的代价m[i,j]恰好位于始于Ai的东北至西南方向的直线与始于Aj的西北至东南方向的直线的交点上。表中同一行中的表项都对应长度相同的矩阵链。MATRIX-CHAIN-ORDER按自下而上、自左至右的顺序计算所有行:当计算表项m[i,j]时,会用到乘积pi-1·pk·pj,其中k=i,i+1,…,j-1,还会用到m[i,j]西南方向和东南方向上的所有表项。
2.4 构造最优解
虽然MATRIX-CHAIN-ORDER求出了计算矩阵链乘积所需的最少标量乘法运算次数,但它并未直接指出如何进行这种最优代价的矩阵链乘法计算。表s[1…n-1,2…n]记录了构造最优解所需的信息。每个表项s[i,j]记录了一个k值,指出Ai·Ai+1·…·Aj的最优括号化方案的分割点应在Ak和Ak+1之间。因此A1…n的最优计算方案中最后一次矩阵乘法运算应该是A1…s[1,n]As[1,n]+1…n。
可以用相同的方法递归地求出更早的矩阵乘法的具体计算过程,因为s[1,s[1,n]]指出了计算A1…s[1,n]时应进行的最后一次矩阵乘法运算;s[s[1,n]+1,n]指出了计算As[1,n]+1…n时应进行的最后一次矩阵乘法运算。
下面给出的伪代码可以输出
PRINT-OPTIMAL-PARENS(s,i,j)
if i==j
print "A"i
else
print "("
PRINT-OPTIMAL-PARENS(s,i,s[i,j])
PRINT-OPTIMAL-PARENS(s,s[i,j]+1,j)
print ")"
对【2.3 计算最优代价】一节最后矩阵链长度为6的例子,调用PRINT-OPTIMAL-PARENS(s,1,6),会输出括号化方案((A1(A2A3))((A4A5)A6))。
调用PRINT-OPTIMAL-PARENS(s,1,n)即可输出
3 动态规划原理
适合应用动态规划方法求解的最优化问题应该具备两个要素:
1、拥有最优子结构;
2、子问题是重叠的。
3.1 最优子结构
用动态规划方法求解最优化问题的第一步就是刻画最优解的结构。如果一个问题的最优解包含其子问题的最优解,就称此问题具有最优子结构性质。
某个问题是否适合应用动态规划算法,它是否具有最优子结构性质是一个好线索,当然,具有最优子结构性质也可能意味着适合应用贪心策略。
使用动态规划方法时,通过子问题的最优解来构造原问题的最优解,因此必须小心确保考察了最优解中用到的所有子问题。
在发掘最优子结构性质的过程中,实际上遵循了如下的通用模式:
1、证明问题最优解的第一个组成部分是做出一个选择,例如在矩阵链乘法问题中选择矩阵链的划分位置。做出这次选择会产生一个或多个待解的子问题。
2、对于一个给定问题,在其可能的第一步选择中,需要假定已经知道哪种选择才会得到最优解。而现在并不关心这种选择具体是如何得到的,只是假定已经知道了这种选择。
3、给定可获得最优解的选择后,需要确定这次选择会产生哪些子问题,以及如何最好地刻画子问题空间。
4、利用“剪切——粘贴”(cut-and-paste)技术证明:作为构成原问题最优解的组成部分,每个子问题的解就是它本身的最优解。证明这一点是利用反证法:假定子问题的解不是其自身的最优解,那么就可以从原问题的解中“剪切”掉这些非最优解,将最优解“粘贴”进去,从而得到原问题一个更优的解,这与最初的解是原问题最优解的前提假设矛盾。如果原问题的最优解包含多个子问题,通常它们都很相似,可以将针对一个子问题的“剪切一粘贴”论证方法稍加修改,用于其他子问题。
一个刻画子问题空间的好经验是:保持子问题空间尽可能简单,只在必要时才扩展它。与之相对的,假定试图限制矩阵链A1A2…Aj乘法问题的子问题空间。如前所述,最优括号化方案必然在某个位置k(1≤k
对于不同问题领域,最优子结构的不同体现在两个方面:
1、原问题的最优解中涉及多少个子问题;
2、在确定最优解使用哪些子问题时,需要考察多少种选择。
AiAi+1…Aj的矩阵链乘法问题中,最优解使用两个子问题,因此需要考察j-i种情况。对于给定的矩阵链划分位置——矩阵Ak,需要求解两个子问题:
1、AiAi+1…Ak;
2、Ak+1Ak+2…Aj。
的括号化方案——而且两个子问题都必须求解最优方案。一旦确定了子问题的最优解,就可以在j-i个候选的k中选取最优者。
可以用:
1、子问题的总数;
2、每个子问题需要考察多少种选择。
以上两个因素的乘积来粗略分析动态规划算法的运行时间。如对于矩阵链乘法问题共有Θ(n2)个子问题,每个子问题最多需要考察n-1种选择,因此运行时间为O(n3)。
子问题图也可用来做同样的分析。图中每个顶点对应一个子问题,而需要考察的选择对应关联至子问题顶点的边。对于矩阵链乘法问题,子问题图会有Θ(n2)个顶点,而每个顶点最多有n-1条边,因此共有O(n3)个顶点和边。
在动态规划方法中,通常自底向上地使用最优子结构:首先求得子问题的最优解,然后求原问题的最优解。
在求解原问题过程中,需要在涉及的子问题中做出选择,选出能得到原问题最优解的子问题。原问题最优解的代价通常就是子问题最优解的代价再加上由此次选择直接产生的代价。例如在矩阵链乘法问题中,先确定子矩阵链AiAi+1…Aj的最优括号化方案,然后选择划分位置Ak,选择本身所产生的代价就是pi-1pkpj。
3.2 一些微妙之处
在尝试使用动态规划方法时要小心,要注意问题是否具有最优子结构性质。考虑下面两个问题,其中都是给定一个有向图G=(V,E)和两个顶点u,v∈V:
1、无权最短路径:找到一条从u到v的边数最少的路径。
2、无权最长路径:找到一条从u到v的边数最多的简单路径。这里必须加上简单路径的要求,因为若可以不停地沿着环走,则可以得到任意长的路径。

那无权最长简单路径问题也具有最优子结构性质吗?下图给出了一个例子:
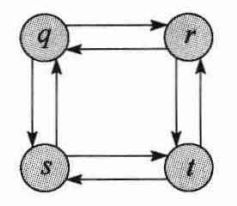
考虑路径q→r→t,它是从q到t的最长简单路径。q→r是从q到r的最长简单路径吗?不是的,q→s→t→r是一条更长的简单路径。r→t是从r到t的最长简单路径吗?同样不是,r→q→s→t比它更长。
上述例子说明,最长简单路径问题不仅缺乏最优子结构性质,由子问题的解组合出的甚至都不是原问题的“合法”解。如果组合最长简单路径q→s→t→r和r→q→s→t,得到的是路径q→s→t→r→q→s→t,并不是简单路径。
为什么最长简单路径问题的子结构与最短路径有这么大的差别?原因在于,虽然最长路径问题和最短路径问题的解都用到了两个子问题,但两个最长简单路径子问题是相关的,而两个最短路径子问题是无关的——也就是说同一个原问题的一个子问题的解不影响另一个子问题的解。对上面一张图中的例子,求q到t的最长简单路径可以分解为两个子问题:求q到r的最长简单路径和r到t的最长简单路径。对于前者,选择路径q→s→t→r,其中用到了顶点s和t。由于两个子问题的解的组合必须产生一条简单路径,因此在求解第二个子问题时就不能再用这两个顶点了。但如果在求解第二个子问题时不允许使用顶点t,就根本无法进行下去了,因为t是原问题解的路径终点,是必须用到的,还不像子问题解的“接合”顶点r那样可以不用。这样,由于一个子问题的解使用了顶点s和t,在另一个子问题的解中就不能再使用它们,但其中至少一个顶点在求解第二个子问题时又必须用到,而获得最优解则两个都要用到,因此说两个子问题是相关的。换个角度来看,现在所面临的困境就是:求解一个子问题时用到了某些资源(在本例中是顶点),导致这些资源在求解其他子问题时不可用。

在矩阵链乘法问题中,子问题为子链AiAi+1…Ak和Ak+1Ak+2…Aj的乘法问题。子链是互不相交的,因此任何矩阵都不会同时包含在两条子链中。
3.3 重叠子问题
适合用动态规划方法求解的最优化问题应该具备的第二个性质是子问题空间必须足够“小”,即问题的递归算法会反复地求解相同的子问题,而不是一直生成新的子问题。一般来讲,不同子问题的总数是输入规模的多项式函数为好。
如果递归算法反复求解相同的子问题,就称最优化问题具有重叠子问题性质。
动态规划算法通常这样利用重叠子问题性质:对每个子问题求解一次,将解存入一个表中,当再次需要这个子问题时直接查表,每次查表的代价为常量时间。
为了详细说明重叠子问题性质,现在重新考虑矩阵链乘法问题。如下图:
发现MATRIX-CHAIN-ORDER在求解高层的子问题时,会反复查找低层上子问题的解。例如,算法会访问表项m[3,4]总共4次:分别在计算m[2,4]、m[1,4]、m[3,5]和m[3,6]时。如果每次都重新计算m[3,4],而不是简单地查表,那么运行时间会急剧上升。为了更好地理解,请看下面的伪代码,它计算矩阵链乘法Ai…j=AiAi+1…Aj所需最少标量乘法运算次数m[i,j],而计算过程是低效的。
RECURSIVE-MATRIX-CHAIN(p,i,j)
if i==j
return 0
m[i,j]=∞
for k=i to j-1
q=RECURSIVE-MATRIX-CHAIN(p,i,k)+RECURSIVE-MATRIX-CHAIN(p,k+1,j)+p(i-1)p(k)p(j)
if q<m[i,j]
m[i,j]=q
return m[i,j]
上述过程直接基于下图:
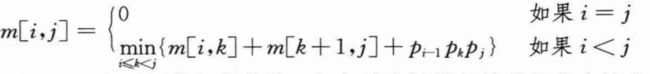
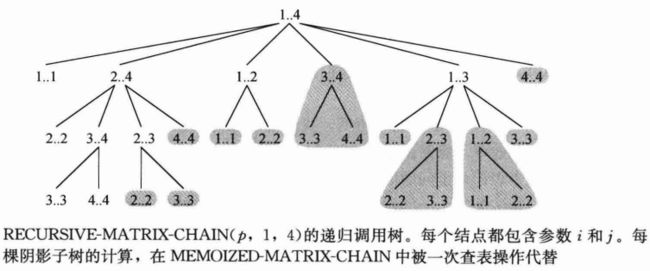
下图显示了调用RECURSIVE-MATRIX-CHAIN(p,1,4)所产生的递归调用树,其中每个结点都标记出了参数i和j。可以看到,某些i、j值对出现了许多次:
下面证明此过程计算m[1,n]的时间至少是n的指数函数。
令T(n)表示RECURSIVE-MATRIX-CHAIN计算n个矩阵的矩阵链的最优括号化方案所花费的时间。由于第2-3行和第7-8行至少各花费单位时间,第6行的加法运算也是如此,因此得到如下递归式:
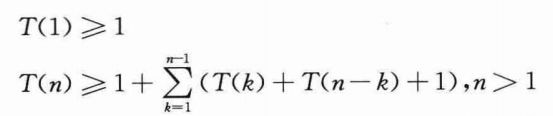
注意,对i=1,2,…,n-1,每一项T(i)在公式中以T(k)的形式出现了一次,还以T(n-k)的形式出现了一次,而求和项中累加了n-1个1,在求和项之前还加了1,因此公式可改写为:
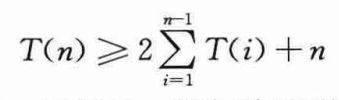
下面用代入法证明T(n)=Ω(2n)。将证明,对所有n≥1,T(n)≥2n-1都成立。基本情况很简单,因为T(1)≥1=20,利用数学归纳法,对n≥2,有:
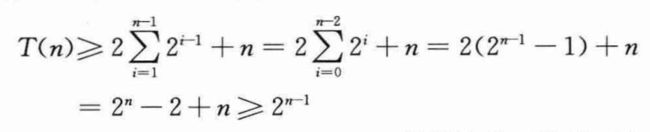
因此调用RECURSIVE-MATRIX-CHAIN(p,1,n)所做的总工作量至少是n的指数函数。
将此自顶向下的递归算法(无备忘)与自底向上的动态规划算法进行比较,后者要高效得多,因为它利用了重叠子问题性质。矩阵链乘法问题只有Θ(n2)个不同的子问题,动态规划算法对每个子问题只求解一次。而递归算法则相反,对每个子问题,每当在递归树中(递归调用时)遇到它,都要重新计算一次。凡是一个问题的自然递归算法的递归调用树中反复出现相同的子问题,而不同子问题的总数很少时,动态规划方法都能提高(有时还是极大地提高)效率。
3.4 重构最优解
通常将每个子问题所做的选择存在一个表中,这样就不必根据代价值来重构这些信息。
对矩阵链乘法问题,利用表s[i,j]重构最优解时可以节省很多时间。假定没有维护s[i,j]表,只是在表m[i,j]中记录了子问题的最优代价。当确定AiAi+1…Aj的最优括号化方案用到了哪些子问题时,就需要检查所有j-i种可能,而j-i并不是一个常数。因此,对一个给定问题的最优解,重构它用到了哪些子问题就需花费Θ(j-i)=ω(1)的时间。而通过在s[i,j]中保存AiAi+1…Aj的划分位置,重构每次选择只需O(1)时间。
3.5 备忘
其实可以保持自顶向下策略,同时达到与自底向上动态规划方法相似的效率。思路就是对自然但低效的递归算法加入备忘机制。与自底向上方法一样,需要维护一个表用于记录子问题的解,但仍保持递归算法的控制流程。
带备忘的递归算法为每个子问题维护一个表项来保存它的解。每个表项的初值设为一个特殊值,表示尚未填入子问题的解。当递归调用过程中第一次遇到子问题时,计算其解,并存入对应表项。随后每次遇到同一个子问题,只是简单地查表,返回其解。
下面给出的是带备忘的RECURSIVE-MATRIX-CHAIN版本:
MEMORIZED-MATRIX-CHAIN(p)
n=p.length-1
let m[1..n,1..n] be a new table
for i=1 to n
for j=i to n
m[i,j]=∞
return LOOKUP-CHAIN(m,p,1,n)
其中,LOOKUP-CHAIN的伪代码如下:
LOOKUP-CHAIN(m,p,i,j)
if m[i,j]<∞
return m[i,j]
if i==j
m[i,j]=0
else for k=i to j-1
q=LOOKUP-CHAIN(m,p,i,k)+LOOKUP-CHAIN(m,p,k+1,j)+p(i-1)p(k)p(j)
if q<m[i,j]
m[i,j]=q
return m[i,j]
与RECURSIVE-MATRIX-CHAIN一样维护一个表m[1…n,1…n],来保存计算出的矩阵Ai…j的最小计算代价m[i,j]。每个表项被初始化为∞,表示还未存入过值。
调用LOOKUP-CHAIN(m,p,i,j)时,如果第2行发现m[i,j]<∞,就直接返回之前已经计算出的代价m[i,j];否则,像RECURSIVE-MATRIX-CHAIN一样计算最小代价,存入m[i,j],并返回。因此,虽然LOOKUP-CHAIN(m,p,i,j)总是返回m[i,j]的值,但只在第一次(以特定的参数i和j)调用时才真正计算。
与自底向上动态规划算法MATRIX-CHAIN-ORDER类似,MEMORIZED-MATRIX-CHAIN的运行时间为O(n3)。MEMORIZED-MATRIX-CHAIN的第6行运行了Θ(n2)次。可以将对LOOKUP-CHAIN的调用分为两类:
1、调用时m[i,j]=∞,因此第4-10行会执行。
2、调用时m[i,j]<∞,因此LOOKUP-CHAIN执行第3行。
第一种调用会发生Θ(n2)次,每个表项一次。第二种调用均为第一种调用所产生的递归调用。而无论何时一个LOOKUP-CHAIN的调用继续进行递归调用,都会产生O(n)次递归调用。因此,第二种调用共有O(n3)次,每次花费O(1)时间,而第一种调用每次花费O(n)时间再加上它产生的递归调用的时间。因此,算法的总时间为O(n3),备忘技术将一个Ω(2n)时间的算法转换为一个O(n3)时间的算法。
为求解矩阵链乘法问题,既可以用带备忘的自顶向下动态规划算法,也可以用自底向上的动态规划算法,时间复杂性均为O(n3)。两种方法都利用了重叠子问题性质。不同的子问题一共只有Θ(n2)个,对每个子问题,两种方法都只计算一次。而没有备忘机制的自然递归算法的运行时间为指数阶,因为它会反复求解相同的子问题。
通常情况下,如果每个子问题都必须至少求解一次,自底向上动态规划算法会比自顶向下备忘算法快(都是O(n3)时间,相差一个常量系数),因为自底向上算法没有递归调用的开销,表的维护开销也更小。而且,对于某些问题,可以利用表的访问模式来进一步降低时空代价。相反,如果子问题空间中的某些子问题完全不必求解,备忘方法就会体现出优势了,因为它只会求解那些绝对必要的子问题。
4 最长公共子序列
请见下一篇——笔记6
5 最优二叉搜索树
请见下一篇——笔记6
6 中位数和顺序统计量
在一个由n个元素组成的集合中,第i个顺序统计量(order statistic)是该集合中第i小的元素。例如,在一个元素集合中,最小值是第1个顺序统计量(i=1),最大值是第n个顺序统计量(i=n)。用非形式化的描述来说,一个中位数(median)是它所属集合的“中间元素”:
1、当n为奇数时,中位数是唯一的,位于i=(n+1)/2处。
2、当n为偶数时,存在两个中位数,分别位于i=n/2和i=n/2+1处。
因此,如果不考虑n的奇偶性,中位数总是出现在i=⌊(n+1)/2⌋处(下中位数)和i=⌈(n+2)/2⌉处(上中位数)。简便起见,本博文中所用的“中位数”都是指下中位数。
本节将讨论从一个由n个互异的元素构成的集合中选择第i个顺序统计量的问题。为了方便起见,假设集合中的元素都是互异的,但实际上可以推广到集合中包含重复元素的情形。现在将这一问题形式化定义为如下的选择问题:
1、输入:一个包含n个(互异的)数的集合A和一个整数i,1≤i≤n。
2、输出:元素x∈A,且A中恰好有i-1个其他元素小于x。
可以在O(n·lgn)时间内解决这个选择问题,因为可以用堆排序或归并排序对输入数据进行排序,然后在输出数组中根据下标找出第i个元素即可。下面将介绍一些更快的算法。
6.1 最小值和最大值
在一个有n个元素的集合中,可以做n-1次比较来确定其最小元素:依次遍历集合中的每个元素,并记录下当前最小元素。在下面的程序中,假设该集合元素存放在数组A中,且A.length=n:
MINIMUM(A)
min=A[1]
for i=2 to A.length
if min>A[i]
min=A[i]
return min
同样地,最大值也可以通过n-1次比较找出来。这是能得到的最好结果——对于确定最小值问题,可以得到其下界就是n-1次比较。对于任意一个确定最小值的算法,可以把它看成是在各元素之间进行的一场锦标赛。每次比较都是锦标赛中的一场比赛,两个元素中较小的获胜。需要注意的是,除了最终获胜者以外,每个元素都至少要输掉一场比赛。因此为了确定最小值,必须要做n-1次比较。因此,从所执行的比较次数来看,算法MINIMUM是最优的。
在某些应用中,必须要找出一个包含n个元素的集合中的最小值和最大值,如比赛中的评委打分。用渐近最优的Θ(n)次比较,在n个元素中同时找到最小值和最大值的方法是显然的:只要分别独立地找出最小值和最大值,这各需要n-1次比较,共需2n-2次比较。
事实上只需要最多3⌊n/2⌋次比较就可以同时找到最小值和最大值。具体的方法是记录已知的最小值和最大值。但并不是将每一个输入元素与当前的最小值和最大值进行比较——这样做的代价是每个元素需要2次比较,只需要对输入元素成对地进行处理。首先,将一对输入元素相互进行比较,然后把较小的与当前最小值比较,把较大的与当前最大值进行比较。这样,对每两个元素共需3次比较。
怎样设定已知的最小值和最大值的初始值依赖于n是奇数还是偶数:
1、如果n是奇数,就将最小值和最大值的初值都设为第一个元素的值,然后成对地处理余下的元素。
2、如果n是偶数,就对前两个元素做一次比较,以决定最小值和最大值的初值,然后成对地处理余下的元素。
下面来分析一下总的比较次数:
1、如果n是奇数,那么总共进行3⌊n/2⌋次比较。
2、如果n是偶数,则是先进行一次初始比较,然后进行3(n-2)/2次比较,共3n/2-2次比较。
因此,不管是哪一种情况,总的比较次数至多是3⌊n/2⌋。下面是具体的伪代码:
MAX-MIN(A)
if A[1]>A[2] //第2行到第7行是通过前两个值初始化Max与Min
Min=A[2]
Max=A[1]
else
Min=A[1]
Max=A[2]
m=⌊n/2⌋ //成对处理元素
for i=2 to m
if A[2i-1]>A[2i]
if A[2i]<Min
Min=A[2i]
if A[2i-1]>Max
Max=A[2i-1]
else
if A[2i-1]<Min
Min=A[2i-1]
if A[2i]>Max
Max=A[2i]
if n!=2m //若n是奇数则A[n]还未进行比较
if A[n]<Min
Min=A[n]
if A[n]>Max
Max=A[n]
return (Max,Min)
6.2 期望为线性时间的选择算法
本节将介绍一种解决选择问题的分治算法。与快速排序一样,仍然将输入数组进行递归划分,但与快速排序不同的是,快速排序会递归处理划分的两边,而RANDOMIZED-SELECT只处理划分的一边。这一差异会在性能分析中体现出来:快速排序的期望运行时间是Θ(n·lgn),而RANDOMIZED-SELECT的期望运行时间为Θ(n)。这里假设输入数据都是互异的。
与RANDOMIZED-QUICKSORT一样,因为它的部分行为是由随机数生成器的输出决定的,所以RANDOMIZED-SELECT也是一个随机算法。以下是RANDOMIZED-SELECT的伪代码,它返回数组A[p…r]中第i小的元素:
RANDOMIZED-SELECT(A,p,r,i)
if p==r
return A[p]
q=RANDOMIZED-PARTITION(A,p,r)
k=q-p+1
if i==k //若主元就是答案,则返回A[q]
return A[q]
else if i<k
return RANDOMIZED-SELECT(A,p,q-1,i)
else return RANDOMIZED-SELECT(A,q+1,r,i-k)
上述伪代码用到了RANDOMIZED-PARTITION,伪代码如下:
RANDOMIZED-PARTITION(A,p,r)
i=RANDOMIZED(p,r)
exchange A[r] with A[i]
x=A[r]
i=p-1
for j=p to r-1
if A[j]≤x
i+=1
exchange A[i] with A[j]
exchange A[i+1] with A[r]
return i+1
RANDOMIZED-SELECT的运行过程如下:
1、第2行检查递归的基本情况,即A[p…r]中只包括一个元素。在这种情况下,i必然等于1,则在第3行,只需将A[p]返回作为第i小的元素即可。
2、其他情况,就会调用第4行的RANDOMIZED-PARTITION,将数组A[p…r]划分为两个(可能为空的)子数组A[p…q-1]和A[q+1…r],使得A[p…q-1]中的每个元素都小于或等于A[q],而A[q]小于A[q+1…r]中的每个元素。与快速排序中一样,称A[q]为主元(pivot)。
3、RANDOMIZED-SELECT的第5行计算子数组A[p…q]内的元素个数k,即处于划分的低区的元素的个数加1。
4、第6行检查A[q]是否是第i小的元素。如果是,第7行就返回A[q]。否则,算法要确定第i小的元素落在两个子数组A[p…q-1]和A[q+1…r]的哪一个之中。如果i
RANDOMIZED-SELECT的最坏情况运行时间为Θ(n2),即使是找最小元素也是如此,因为在每次划分时可能极不走运地总是按余下的元素中最大的来进行划分,而划分操作需要Θ(n)时间。该算法有线性的期望运行时间,又因为它是随机化的,所以不存在一个特定的会导致其最坏情况发生的输入数据。
为了分析RANDOMIZED-SELECT的期望运行时间,设该算法在一个含有n个元素的输入数组A[p…r]上的运行时间是一个随机变量,记为T(n)。可以得到期望E[T(n)]的一个上界:程序RANDOMIZED-PARTITION能等概率地返回任何元素作为主元。因此,对每一个k(1≤k≤n),子数组A[p…q]有k个元素(全部小于或等于主元)的概率是1/n。对所有k=1,2,…,n,定义指示器随机变量Xk为:Xk=Ⅰ{子数组A[p…q]正好包含k个元素}。假设元素是互异的,有:
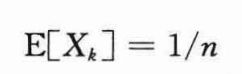
当调用RANDOMIZED-SELECT并选择A[q]作为主元时,事先并不知道是否会立即得到正确答案而结束,也不知道在子数组A[p…q-1]上递归,或者在子数组A[q+1…r]上递归。这个决定依赖于第i小的元素相对于A[q]落在哪个位置。假设T(n)是单调递增的,通过评估最大可能的输入数据递归调用所需时间,可以给出递归调用所需时间的上界。也就是说,为了得到上界,假定第i个元素总是在划分中包含较大元素的一边。对一个给定的RANDOMIZED-SELECT,指示器随机变量Xk恰好在给定的k值上取值1,对其他值都为0。当Xk=1时,可能要递归处理的两个子数组的大小分别为k-1和n-k。因此可以得到递归式:
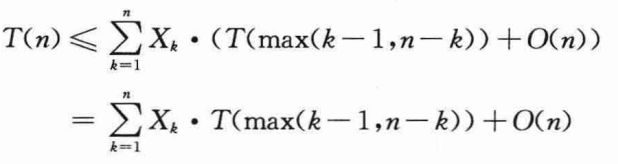
对上式两边取期望得到:
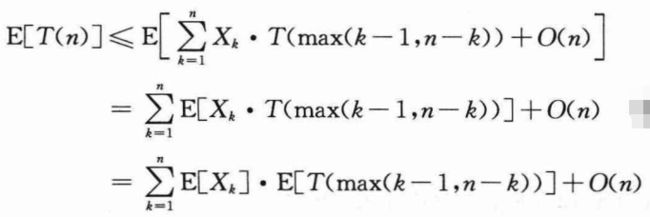
上式中从第2行到第3行利用了Xk和T(max(k-1,n-k))是独立的随机变量。根据下式:
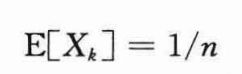
则上上一张图是:
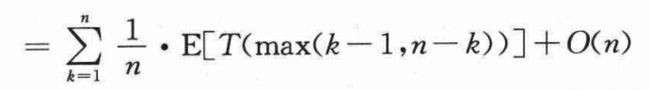
下面来考虑一下表达式max(k-1,n-k),有:
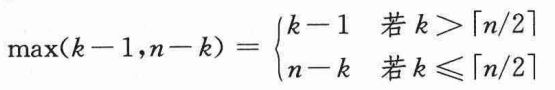
如果n是偶数,则从T(⌈n/2⌉)到T(n-1)的每一项在总和中恰好出现两次。如果n是奇数,除了T(⌊n/2⌋)出现一次以外,其他这些项也都会出现两次。因此有:
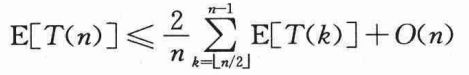
下面用置换法来得到E[T(n)]=O(n)。
假设对满足这个递归式初始条件的某个常数c,有E[T(n)]≤cn。假设对小于某个常数的n,有T(n)=O(1)(稍后将用到这个常数)。同时,还要选择一个常数a,使得对所有的n>0,上式中O(n)项所描述的函数(用来表示算法运行时间中的非递归部分)有上界an。利用这个归纳假设,可以得到:
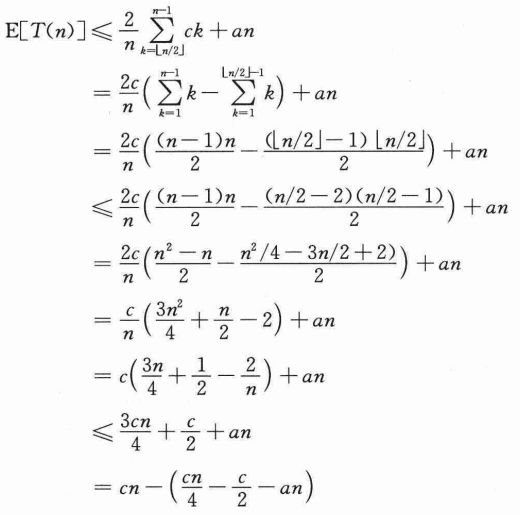
还需要证明:对足够大的n,最后一个表达式至多是cn,即需要证明:cn/4-c/2-an≥0,如果在该式两边加上c/2,并且提取因子n,就可以得到n(c/4-a)≥c/2。只要选择的常数c能够满足c/4-a>0,即c>4a,就可以将两边同除以c/4-a,得到:
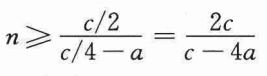
因此,如果假设对所有n<2c/(c-4a),都有T(n)=O(1),那么就有E[T(n)]=O(n)。
结论:假设所有元素是互异的,在期望线性时间内,可以找到任一顺序统计量,特别是中位数。
6.3 最坏情况为线性时间的选择算法
现在来看一个最坏情况运行时间为O(n)的选择算法。像RANDOMIZED-SELECT一样,SELECT算法通过对输入数组的递归划分来找出所需元素,但是,在该算法中能够保证得到对数组的一个好的划分。SELECT使用的也是来自快速排序的确定性划分算法PARTITION,如下:
PARTITION(A,p,r)
x=A[r]
i=p-1
for j=p to r-1
if A[j]≤x
i+=1
exchange A[i] with A[j]
exchange A[i+1] with A[r]
return i+1
本节的SELECT对上述PARTITION进行了修改——把划分的主元也作为输入参数。通过执行下列步骤,算法SELECT可以确定一个有n>1个不同元素的输入数组中第i小的元素。如果n=1,则SELECT只返回它的唯一输入数值作为第i小的元素。
1、将输入数组的n个元素划分为⌊n/5⌋组,每组5个元素,且至多只有一组由剩下的n mod 5个元素组成。
2、寻找这⌈n/5⌉组中每一组的中位数:首先对每组元素进行插入排序,然后确定每组有序元素的中位数。
3、对第2步中找出的⌈n/5⌉个中位数,递归调用SELECT以找出其中位数x(如果有偶数个中位数,为了方便,约定x是较小的中位数)。
4、利用修改过的PARTITION版本,按中位数的中位数x对输入数组进行划分。让k比划分的低区中的元素数目多1,因此x是第k小的元素,并且有n-k个元素在划分的高区。
5、如果i=k,则返回x。如果i
为分析SELECT的运行时间,先要确定大于划分主元x的元素个数的下界。下图给出了一些形象的说明:
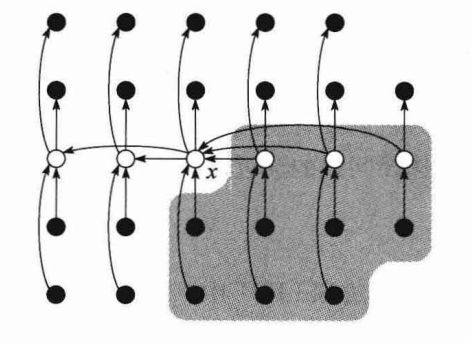
上图是对算法SELECT的分析。所有n个元素都由小圈来表示,并且每一组的5个元素在同一列上。其中,每组的中位数用白色圈表示,而中位数的中位数x也被标识出来(当查找偶数个元素的中位数时,使用较小的中位数)。箭头从较大的元素指向较小的元素,从图中可以看出,在x的右边,每一个包含5个元素的组中有3个元素大于x。在x的左边,每一个包含5个元素的组中有3个元素小于x。除此之外,大于x的元素的背景以阴影来显示。
在前面叙述的第2步找出的中位数中,至少有一半大于或等于中位数的中位数x。因此,在这⌈n/5⌉个组中,除了当n不能被5整除时产生的所含元素少于5的那个组和包含x的那个组之外,至少有一半的组中有3个元素大于x。不算这两个组,大于x的元素个数至少为:
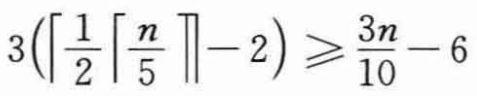
类似地,至少有3n/10-6个元素小于x。因此,在最坏情况下,在第5步中,SELECT的递归调用最多作用于7n/10+6个元素。
现在可以设计一个递归式来推导SELECT算法的最坏情况运行时间T(n)了。
步骤1、2和4需要O(n)时间,其中步骤2是对大小为O(1)的集合调用O(n)次插入排序。步骤3所需时间为T(⌈n/5⌉),步骤5所需时间至多为T(7n/10+6)。假设T是单调递增的,此外还要作如下假设(这一假设初看起来似乎没有什么动机),即任何少于140个元素的输入需要O(1)时间。后面会说明这个140的起源。根据上述假设,可以得到如下递归式:
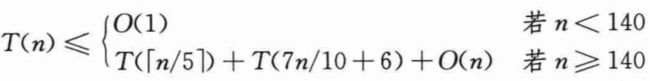
用置换法来证明这个运行时间是线性的——即证明对某个适当大的常数c和所有的n>0,有T(n)≤cn。首先,假设对某个适当大的常数c和所有的n<140,有T(n)≤cn;如果c足够大,这个假设显然成立。同时,还要挑选一个常数a,使得对所有的n>0,上述公式中的O(n)项所对应的函数(这个函数是用来描述算法运行时间中的非递归部分)有上界an。将这个归纳假设代入上述递归式的右边,得到:
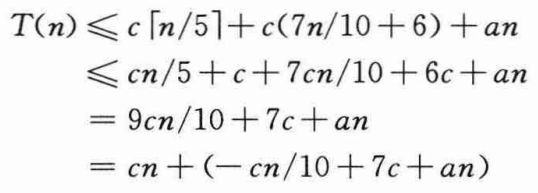
如果下式成立,上式最多是cn:
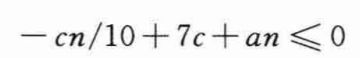
当n>70时,上述不等式等价于不等式c≥10a(n/(n-70))。因为假设n>140,所以有n/(n-70)≤2。因此,选择c≥20a就能够满足上述不等式。注意,这里常数140并没有什么特别之处,可以用任何严格大于70的整数来替换它,然后再相应地选择c即可。因此,最坏情况下SELECT的运行时间是线性的。
与比较排序一样,SELECT和RANDOMIZED-SELECT也是通过元素间的比较来确定它们之间的相对次序的。在比较模型中,即使是在平均情况下,排序仍然需要Ω(n·lgn)时间。本节中的线性时间选择算法不需要任何关于输入的假设,而且它们不受限于Ω(n·lgn)的下界约束,因为它们没有使用排序就解决了选择问题。
END