经典 network -- 图像分类篇(01 AlexNet / NIN / VGG)(持续更新)
近期,实验室小组成员决定定期学习经典网络模型。因此,特别准备写这么一个博客,持续更新我们的学习、及个人对各种经典网络的理解。如有不足和理解不到位的地方,还望读者提出质疑和批评,定虚心改进。望共同讨论、学习和进步。
系列目录:
经典 network -- 图像分类篇(01 AlexNet / VGG)
经典 network -- 图像分类篇(02 Inception v1-v4)(-ing)
经典 network -- 图像分类篇(03 ResNet v1-v2)
Table of Contents
系列目录:
经典 network -- 图像分类篇(01 AlexNet / NIN / VGG)
AlexNet
The Architecture
Reducing Overfitting
NIN (Network In Network)
Introduction
Network In Network
VGG
Convnet Configurations
Training
经典 network -- 图像分类篇(01 AlexNet / NIN / VGG)
本部分包括 AlexNet,NIN (Network in Network) 和 VGG。
AlexNet
[paper] ImageNet Classification with Deep Convolutional Neural Networks
[pytorch] https://pytorch.org/hub/pytorch_vision_alexnet/
Figure 2: An illustration of the architecture of our CNN, explicitly showing the delineation of responsibilities
between the two GPUs. One GPU runs the layer-parts at the top of the figure while the other runs the layer-parts
at the bottom. The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional, and
the number of neurons in the network’s remaining layers is given by 253,440–186,624–64,896–64,896–43,264–
4096–4096–1000.
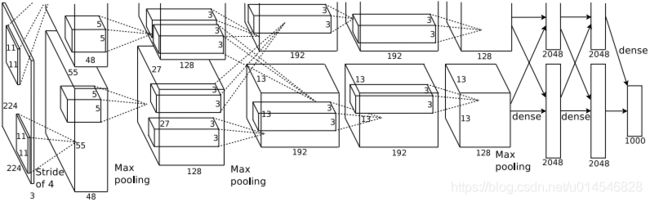
The Architecture
It contains eight learned layers — five convolutional and three fully-connected.
- ReLU Nonlinearity
The standard way to model a neuron’s output f as a function of its input  is with
is with ![]() or
or ![]() . In terms of training time with gradient descent, these saturating nonlinearities are much slower than the non-saturating nonlinearity
. In terms of training time with gradient descent, these saturating nonlinearities are much slower than the non-saturating nonlinearity ![]() . Following Nair and Hinton [20], we refer to neurons with this nonlinearity as Rectified Linear Units (ReLUs). Deep convolutional neural networks with ReLUs train several times faster than their equivalents with tanh units. This is demonstrated in Figure 1. This plot shows that we would not have been able to experiment with such large neural networks for this work if we had used traditional saturating neuron models.
. Following Nair and Hinton [20], we refer to neurons with this nonlinearity as Rectified Linear Units (ReLUs). Deep convolutional neural networks with ReLUs train several times faster than their equivalents with tanh units. This is demonstrated in Figure 1. This plot shows that we would not have been able to experiment with such large neural networks for this work if we had used traditional saturating neuron models.

Figure 1: A four-layer convolutional neural network with ReLUs (solid line) reaches a 25% training error rate on CIFAR-10 six times faster than an equivalent network with tanh neurons (dashed line). The learning rates for each network were chosen independently to make training as fast as possible. No regularization of any kind was employed. The magnitude of the effect demonstrated here varies with network architecture, but networks with ReLUs consistently learn several times faster than equivalents with saturating neurons.
重点:
图1可以看出,虚线的 tanh 的错误率会趋于0.25而很难再降低,即意味着如果我们使用传统的饱和神经元模型,我们就无法用这么大的神经网络来做实验。
We are not the first to consider alternatives to traditional neuron models in CNNs. For example, Jarrett et al. [11] claim that the nonlinearity ![]() works particularly well with their type of contrast normalization followed by local average pooling on the Caltech-101 dataset. However, on this dataset the primary concern is preventing overfitting, so the effect they are observing is different from the accelerated ability to fit the training set which we report when using ReLUs. Faster learning has a great influence on the performance of large models trained on large datasets.
works particularly well with their type of contrast normalization followed by local average pooling on the Caltech-101 dataset. However, on this dataset the primary concern is preventing overfitting, so the effect they are observing is different from the accelerated ability to fit the training set which we report when using ReLUs. Faster learning has a great influence on the performance of large models trained on large datasets.
本文并不是第一个提出对神经元模型做改变的工作,如 [What is the best multi-stage architecture for object recognition?] 中提出的 ![]() 模型。
模型。
作者提出一个观点:快速学习对在大型数据集上训练的大型模型的性能有很大的影响。
- Training on Multiple GPUs
The parallelization scheme that we employ essentially puts half of the kernels (or neurons) on each GPU, with one additional trick: the GPUs communicate only in certain layers. This means that, for example, the kernels of layer 3 take input from all kernel maps in layer 2. However, kernels in layer 4 take input only from those kernel maps in layer 3 which reside on the same GPU. Choosing the pattern of connectivity is a problem for cross-validation, but this allows us to precisely tune the amount of communication until it is an acceptable fraction of the amount of computation.
This scheme reduces our top-1 and top-5 error rates by 1.7% and 1.2%, respectively, as compared with a net with half as many kernels in each convolutional layer trained on one GPU. The two-GPU net takes slightly less time to train than the one-GPU net
我们采用的并行方案基本上是在每个GPU中放置一半核(或神经元),还有一个额外的技巧:GPU间的通讯只在某些层进行。这就是说,例如,第3层的核需要从第2层中所有核映射输入。然而,第4层的核只需要从第3层中位于同一GPU的那些核映射输入。选择连接模式是一个交叉验证的问题,但是这让我们可以精确地调整通信量,直到它的计算量在可接受的部分。
- Local Response Normalization
Denoting by ![]() the activity of a neuron computed by applying kernel
the activity of a neuron computed by applying kernel 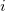 at position
at position ![]() and then applying the ReLU nonlinearity, the response-normalized activity
and then applying the ReLU nonlinearity, the response-normalized activity ![]() is given by the expression
is given by the expression

where the sum runs over 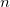 “adjacent” kernel maps at the same spatial position, and
“adjacent” kernel maps at the same spatial position, and 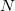 is the total number of kernels in the layer. The ordering of the kernel maps is of course arbitrary and determined before training begins. This sort of response normalization implements a form of lateral inhibition inspired by the type found in real neurons, creating competition for big activities amongst neuron outputs computed using different kernels.
is the total number of kernels in the layer. The ordering of the kernel maps is of course arbitrary and determined before training begins. This sort of response normalization implements a form of lateral inhibition inspired by the type found in real neurons, creating competition for big activities amongst neuron outputs computed using different kernels.
We applied this normalization after applying the ReLU nonlinearity in certain layers (see Section 3.5). This scheme bears some resemblance to the local contrast normalization scheme of Jarrett et al. [11], but ours would be more correctly termed “brightness normalization”, since we do not subtract the mean activity.
重点:
1. 公式计算的是 n个“相邻的”的核映射、位于相同空间位置的点的和,N是该层中的核总数;
2. 核映射的顺序是任意的,且在训练开始前就确定;
3. 受到在真实神经元中发现的类型启发,这种响应归一化实现了一种侧向抑制,在使用不同核计算神经元输出的过程中创造对大激活度的竞争;
4. 在某些层应用ReLU归一化后再应用这种归一化。
5. 我们的方案更正确的命名为“brightness normalization”,因为我们不减去平均活跃度;
6. 响应归一化将我们的top-1与top-5误差率分别减少了1.4%与1.2%;
7. 在CIFAR-10数据集上的有效性:四层CNN不带归一化时的测试误差率是13%,带归一化时是11%。
- Overlapping Pooling
Pooling layers in CNNs summarize the outputs of neighboring groups of neurons in the same kernel map. Traditionally, the neighborhoods summarized by adjacent pooling units do not overlap (e.g., [17, 11, 4]). To be more precise, a pooling layer can be thought of as consisting of a grid of pooling units spaced ![]() pixels apart, each summarizing a neighborhood of size
pixels apart, each summarizing a neighborhood of size ![]() centered at the location of the pooling unit. If we set
centered at the location of the pooling unit. If we set ![]() , we obtain traditional local pooling as commonly employed in CNNs. If we set
, we obtain traditional local pooling as commonly employed in CNNs. If we set ![]() , we obtain overlapping pooling. This is what we use throughout our network, with
, we obtain overlapping pooling. This is what we use throughout our network, with ![]() and
and ![]() . This scheme reduces the top-1 and top-5 error rates by 0.4% and 0.3%, respectively, as compared with the non-overlapping scheme
. This scheme reduces the top-1 and top-5 error rates by 0.4% and 0.3%, respectively, as compared with the non-overlapping scheme ![]() ,
, ![]() , which produces output of equivalent dimensions. We generally observe during training that models with overlapping pooling find it slightly more difficult to overfit.
, which produces output of equivalent dimensions. We generally observe during training that models with overlapping pooling find it slightly more difficult to overfit.
重点:采用重叠池化,能够起到一点点抑制过拟合的作用。
- Overall Architecture
As depicted in Figure 2, the net contains eight layers with weights; the first five are convolutional and the remaining three are fully-connected. The output of the last fully-connected layer is fed to a 1000-way softmax which produces a distribution over the 1000 class labels. Our network maximizes the multinomial logistic regression objective, which is equivalent to maximizing the average across training cases of the log-probability of the correct label under the prediction distribution.
The kernels of the second, fourth, and fifth convolutional layers are connected only to those kernel maps in the previous layer which reside on the same GPU. The kernels of the third convolutional layer are connected to all kernel maps in the second layer. The neurons in the fully-connected layers are connected to all neurons in the previous layer.
Response-normalization layers follow the first and second convolutional layers. Max-pooling layers, of the kind described in Section 3.4, follow both response-normalization layers as well as the fifth convolutional layer. The ReLU non-linearity is applied to the output of every convolutional and fully-connected layer.
重点:
1. 网络共 5 个卷积层,3 个全链接层;
2. 最后一个全链接层的输出是 1000 个 softmax,用于 1000 个类;
3. 采用 multinomial logistic regression objective;
4. 第2/4/5 卷积层的输入只为当下 GPU 的前一层输出;第3 卷积层和全链接层与所有的前一层输出连结(来自两个 GPU);
5. Response-normalization layers 在 第1/2 两个卷积层后面使用;
6. Max-pooling 紧跟在每一个 response-normalization layer 和第 5 个卷积层后面;
7. Relu 使用在每个卷积层和全链接层后面。
The first convolutional layer filters the 224×224×3 input image with 96 kernels of size 11×11×3 with a stride of 4 pixels (this is the distance between the receptive field centers of neighboring neurons in a kernel map). The second convolutional layer takes as input the (response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5 × 5 × 48. The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers. The third convolutional layer has 384 kernels of size 3 × 3 × 256 connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth convolutional layer has 384 kernels of size 3 × 3 × 192 , and the fifth convolutional layer has 256 kernels of size 3 × 3 × 192. The fully-connected layers have 4096 neurons each.
重点
1. 第 1 个卷积层利用 96 个大小为11×11×3、步长为4个像素的核,来对大小为224×224×3的输入图像进行滤波;
2. 第 2 个卷积层需要将第 1 个卷积层的(response-normalized 及池化的)输出作为自己的输入,且利用256个大小为5×5×48的核对其进行滤波;
3. 第 3/4/5 个卷积层彼此相连,没有任何介于中间的pooling层与归一化层;
4. 第 3 个卷积层有384个大小为3×3×256的核被连接到第 2 个卷积层的(response-normalized、池化的)输出;
5. 第 4 个卷积层拥有384个大小为3×3×192的核;
6. 第 5 个卷积层拥有256个大小为3×3×192的核;
7. 全连接层都各有4096个神经元。
Reducing Overfitting
Below, we describe the two primary ways in which we combat overfitting.
- Data Augmentation
The easiest and most common method to reduce overfitting on image data is to artificially enlarge the dataset using label-preserving transformations (e.g., [25, 4, 5]). We employ two distinct forms of data augmentation, both of which allow transformed images to be produced from the original images with very little computation, so the transformed images do not need to be stored on disk. In our implementation, the transformed images are generated in Python code on the CPU while the GPU is training on the previous batch of images. So these data augmentation schemes are, in effect, computationally free.
The first form of data augmentation consists of generating image translations and horizontal reflections. We do this by extracting random 224 × 224 patches (and their horizontal reflections) from the 256×256 images and training our network on these extracted patches . This increases the size of our training set by a factor of 2048, though the resulting training examples are, of course, highly interdependent. Without this scheme, our network suffers from substantial overfitting, which would have forced us to use much smaller networks. At test time, the network makes a prediction by extracting five 224 × 224 patches (the four corner patches and the center patch) as well as their horizontal reflections (hence ten patches in all), and averaging the predictions made by the network’s softmax layer on the ten patches.
The second form of data augmentation consists of altering the intensities of the RGB channels in training images. Specifically, we perform PCA on the set of RGB pixel values throughout the ImageNet training set. To each training image, we add multiples of the found principal components, with magnitudes proportional to the corresponding eigenvalues times a random variable drawn from a Gaussian with mean zero and standard deviation 0.1. Therefore to each RGB image pixel ![]() we add the following quantity:
we add the following quantity:
![]()
where ![]() and
and ![]() are th eigenvector and eigenvalue of the 3 × 3 covariance matrix of RGB pixel values, respectively, and
are th eigenvector and eigenvalue of the 3 × 3 covariance matrix of RGB pixel values, respectively, and ![]() is the aforementioned random variable.
is the aforementioned random variable.
重点:
两种增加训练样本的方法:
1. 平移和水平映射;
2. 改变训练图像中RGB通道的强度。
特别学习PCA图像增强算法:
1. 首先,用PCA遍历整个数据集;
2. 对于每个图像,成倍增加前面计算到的主成分;比例大小为对应特征值乘以一个从均值为0、标准差为0.1的高斯分布中提取的随机变量。
- Dropout
Combining the predictions of many different models is a very successful way to reduce test errors [1, 3], but it appears to be too expensive for big neural networks that already take several days to train. There is, however, a very efficient version of model combination that only costs about a factor of two during training. The recently-introduced technique, called “dropout” [Improving neural networks by preventing co-adaptation of feature detectors], consists of setting to zero the output of each hidden neuron with probability 0.5. The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in backpropagation. So every time an input is presented, the neural network samples a different architecture, but all these architectures share weights. This technique reduces complex co-adaptations of neurons, since a neuron cannot rely on the presence of particular other neurons. It is, therefore, forced to learn more robust features that are useful in conjunction with many different random subsets of the other neurons. At test time, we use all the neurons but multiply their outputs by 0.5, which is a reasonable approximation to taking the geometric mean of the predictive distributions produced by the exponentially-many dropout networks. We use dropout in the first two fully-connected layers of Figure 2. Without dropout, our network exhibits substantial overfitting. Dropout roughly doubles the number of iterations required to converge.
重点:
1. dropout 技术可以减少神经元之间复杂的相互适应,因为神经元并不是总要依赖于其他神经元的存在;
2. 本文的 dropout 层在前两个全链接层(即第 6/7 层);
3. dropout 有效地解决了过拟合问题;
4. 但 dropout 使得训练时间增加了近一倍(收敛速度是不加dropout的两倍)。
NIN (Network In Network)
Introduction
Convolutional neural networks (CNNs) [1] consist of alternating convolutional layers and pooling layers. Convolution layers take inner product of the linear filter and the underlying receptive field followed by a nonlinear activation function at every local portion of the input. The resulting outputs are called feature maps.
The convolution filter in CNN is a generalized linear model (GLM) for the underlying data patch, and we argue that the level of abstraction is low with GLM. By abstraction we mean that the feature is invariant to the variants of the same concept [2]. Replacing the GLM with a more potent nonlinear function approximator can enhance the abstraction ability of the local model. GLM can achieve a good extent of abstraction when the samples of the latent concepts are linearly separable, i.e. the variants of the concepts all live on one side of the separation plane defined by the GLM. Thus conventional CNN implicitly makes the assumption that the latent concepts are linearly separable. However, the data for the same concept often live on a nonlinear manifold, therefore the representations that capture these concepts are generally highly nonlinear function of the input. In NIN, the GLM is replaced with a ”micro network” structure which is a general nonlinear function approximator. In this work, we choose multilayer perceptron [3] as the instantiation of the micro network, which is a universal function approximator and a neural network trainable by back-propagation.
这一段给出了本文的 motivation:
卷积滤波器是线性的模型,叫做 GLM;然而数据通常存在于非线性流形上,捕捉这些概念的表示通常是输入的高度非线性函数。
因此,本文将 GLM 用 ”micro network” 的结构替代,这个结构要求是非线性的。
本文的 micro network 选用的是多层感知器,通过反向传播是可以被训练的。
Figure 1: Comparison of linear convolution layer and mlpconv layer. The linear convolution layer includes a linear filter while the mlpconv layer includes a micro network (we choose the multilayer perceptron in this paper). Both layers map the local receptive field to a confidence value of the latent concept.
传统的卷积层,局部感受野的运算仅仅只是一个单层的神经网络;
利用多层感知器的微型网络,对每个局部感受野的神经元进行更加复杂的非线性运算。
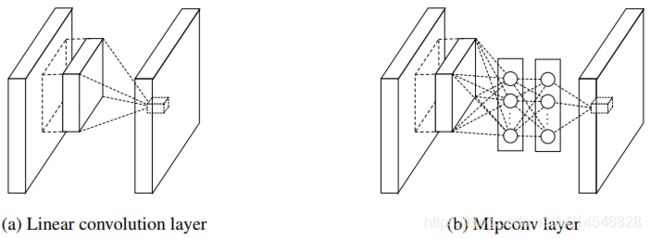
The resulting structure which we call an mlpconv layer is compared with CNN in Figure 1. Both the linear convolutional layer and the mlpconv layer map the local receptive field to an output feature vector. The mlpconv maps the input local patch to the output feature vector with a multilayer perceptron (MLP) consisting of multiple fully connected layers with nonlinear activation functions. The MLP is shared among all local receptive fields. The feature maps are obtained by sliding the MLP over the input in a similar manner as CNN and are then fed into the next layer. The overall structure of the NIN is the stacking of multiple mlpconv layers. It is called “Network In Network” (NIN) as we have micro networks (MLP), which are composing elements of the overall deep network, within mlpconv layers.
重点:
1. 含有 MLP 的卷积层叫做 mlpconv layer,mlpconv 指的是: multilayer perceptron + convolution;mlpconv 贯穿整个的网络叫 Network in Netwrok;
2. mlpconv 使用多层感知器将输入局部patch映射到输出特征向量;多层感知器由多个具有非线性激活函数的全连接层组成;
3. MLP在所有局部感受野之间共享;
4. 通过将MLP以类似于CNN的方式在输入上滑动获得特征图,然后将其输入到下一层;
Instead of adopting the traditional fully connected layers for classification in CNN, we directly output the spatial average of the feature maps from the last mlpconv layer as the confidence of categories via a global average pooling layer, and then the resulting vector is fed into the softmax layer.
In traditional CNN, it is difficult to interpret how the category level information from the objective cost layer is passed back to the previous convolution layer due to the fully connected layers which act as a black box in between.
In contrast, global average pooling is more meaningful and interpretable as it enforces correspondance between feature maps and categories, which is made possible by a stronger local modeling using the micro network.
Furthermore, the fully connected layers are prone to overfitting and heavily depend on dropout regularization [4] [5], while global average pooling is itself a structural regularizer, which natively prevents overfitting for the overall structure.
重点:
1. 我们不采用传统的全连通层进行分类,而是直接输出来自最后一层 mlpconv 的 feature maps 的空间平均作为类别的置信度,通过全局平均池层,然后将得到的向量送入 softmax 层。
2. 原因:
1)在传统的CNN中,由于完全连接的层之间充当了一个黑盒子,很难解释来自目标成本层的类别级信息是如何传递回之前的卷积层的。全局平均池更有意义和可解释性,因为它加强了feature map和categories之间的对应,这是通过使用 micro network 进行更强的局部建模来实现的。
2)全连通层容易发生过拟合,严重依赖dropout正则化[4][5],而全局平均池本身就是一个结构正则化器,从本质上防止了整体结构的过拟合。(为什么全局平均池本身就是一个结构正则化器?)
Network In Network
- MLP Convolution Layers
Given no priors about the distributions of the latent concepts, it is desirable to use a universal function approximator for feature extraction of the local patches, as it is capable of approximating more abstract representations of the latent concepts. Radial basis network and multilayer perceptron are two well known universal function approximators. We choose multilayer perceptron in this work for two reasons. First, multilayer perceptron is compatible with the structure of convolutional neural networks, which is trained using back-propagation. Second, multilayer perceptron can be a deep model itself, which is consistent with the spirit of feature re-use [2]. This new type of layer is called mlpconv in this paper, in which MLP replaces the GLM to convolve over the input. Figure 1 illustrates the difference between linear convolutional layer and mlpconv layer. The calculation performed by mlpconv layer is shown as follows:
(2)
Here is the number of layers in the multilayer perceptron. Rectified linear unit is used as the activation function in the multilayer perceptron.
重点:
有两种 universal function approximators:Radial basis network 径向基神经网络 and multilayer perceptron 多层感知器。
本文选自多想感知器的原因:
1. 多层感知器与卷积神经网络的结构兼容,卷积神经网络通过反向传播进行训练;
2. 多层感知器本身可以是一个深度模型,这与特征重用的实质是一致的。
Comparison to maxout layers:
the maxout layers in the maxout network performs max pooling across multiple affine feature maps [Maxout Networks]. The feature maps of maxout layers are calculated as follows:
![]()
Maxout over linear functions forms a piecewise linear function which is capable of modeling any convex function. For a convex function, samples with function values below a specific threshold form a convex set. Therefore, by approximating convex functions of the local patch, maxout has the capability of forming separation hyperplanes for concepts whose samples are within a convex set (i.e. l2 balls, convex cones). Mlpconv layer differs from maxout layer in that the convex function approximator is replaced by a universal function approximator, which has greater capability in modeling various distributions of latent concepts.
maxout线性函数形成了一个分段线性函数,可以给任何凸函数建模。对于一个凸函数来说,函数值在特定阈值下的样本点形成一个凸集,因此,通过拟合局部块的凸函数,可以形成样本点在凸集内的概念的分割超平面(例如,l2 balls, convex cones)。mlpconv层和maxout层的不同之处在与见凸函数拟合器用通用函数拟合器替代,使其能对更多的隐含概念分布建模。[此段转载于这里]
- Global Average Pooling
In this paper, we propose another strategy called global average pooling to replace the traditional fully connected layers in CNN. The idea is to generate one feature map for each corresponding category of the classification task in the last mlpconv layer. Instead of adding fully connected layers on top of the feature maps, we take the average of each feature map, and the resulting vector is fed directly into the softmax layer.
One advantage of global average pooling over the fully connected layers is that it is more native to the convolution structure by enforcing correspondences between feature maps and categories. Thus the feature maps can be easily interpreted as categories confidence maps. Another advantage is that there is no parameter to optimize in the global average pooling thus overfitting is avoided at this layer.
Futhermore, global average pooling sums out the spatial information, thus it is more robust to spatial translations of the input. We can see global average pooling as a structural regularizer that explicitly enforces feature maps to be confidence maps of concepts (categories). This is made possible by the mlpconv layers, as they makes better approximation to the confidence maps than GLMs.
在本文中,我们提出了另一个策略,叫做全局平均池化层,用它来替代CNN中的全连接层。想法是在最后一个mlpconv层生成一个分类任务中相应类别的特征图。我们没有在特征图最顶端增加全连接层,而是求每个特征图的平均值,得到的结果向量直接输入softmax层。GAP相比全连接层的优点在于通过增强特征图与类比间的对应关系使卷积结构保留的更好,使特征图分类是可信的得到很好的解释;另一个优点是GAP层中没有参数设置,因此避免了过拟合;此外,GAP汇聚了空间信息,所以对输入的空间转换更鲁棒。
我们可以看到GAP作为一个正则化器,加强了特征图与概念(类别)的可信度的联系。这是通过mlpconv层实现的,因为他们比GLM更好逼近置信图(conficence maps)。[此段转载于这里]
Figure 2: The overall structure of Network In Network. In this paper the NINs include the stacking of three mlpconv layers and one global average pooling layer.
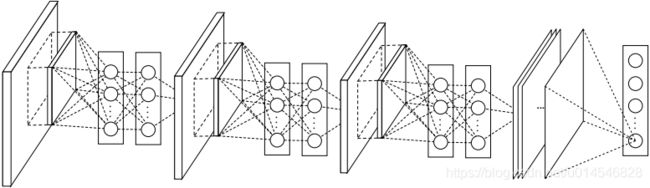
- Network In Network Structure
The overall structure of NIN is a stack of mlpconv layers, on top of which lie the global average pooling and the objective cost layer. Sub-sampling layers can be added in between the mlpconv layers as in CNN and maxout networks. Figure 2 shows an NIN with three mlpconv layers. Within each mlpconv layer, there is a three-layer perceptron. The number of layers in both NIN and the micro networks is flexible and can be tuned for specific tasks.
NIN的整体结构是一系列mlpconve层的堆叠,最上层接一个GAP层和分类层。mlpconv层间的子层可以被相加,像CNN和maxout网络一样。图2展示了一个包含三个mlpconv层的NIN。每个mlpconv层,包含一个三层的感知器,NIN和微型网络的层数都是灵活的,可以根据具体任务微调。
VGG
[paper] Very Deep Convolutional Networks for Large-Scale Image Recognition
[pytorch] https://pytorch.org/docs/stable/_modules/torchvision/models/vgg.html
Convnet Configurations
To measure the improvement brought by the increased ConvNet depth in a fair setting, all our ConvNet layer configurations are designed using the same principles, inspired by Ciresan et al. (2011); Krizhevsky et al. (2012). In this section, we first describe a generic layout of our ConvNet configurations (Sect. 2.1) and then detail the specific configurations used in the evaluation (Sect. 2.2). Our design choices are then discussed and compared to the prior art in Sect. 2.3.
- Architecture
The only preprocessing we do is subtracting the mean RGB value, computed on the training set, from each pixel.
The image is passed through a stack of convolutional (conv.) layers, where we use filters with a very small receptive field: 3 × 3 (which is the smallest size to capture the notion of left/right, up/down, center). In one of the configurations we also utilise 1 × 1 convolution filters, which can be seen as a linear transformation of the input channels (followed by non-linearity).
The convolution stride is fixed to 1 pixel; the spatial padding of conv. layer input is such that the spatial resolution is preserved after convolution, i.e. the padding is 1 pixel for 3 × 3 conv. layers.
Spatial pooling is carried out by five max-pooling layers, which follow some of the conv. layers (not all the conv. layers are followed by max-pooling). Max-pooling is performed over a 2 × 2 pixel window, with stride 2.
A stack of convolutional layers (which has a different depth in different architectures) is followed by three Fully-Connected (FC) layers: the first two have 4096 channels each, the third performs 1000- way ILSVRC classification and thus contains 1000 channels (one for each class).
The final layer is the soft-max layer.
The configuration of the fully connected layers is the same in all networks.
All hidden layers are equipped with tfhe rectification (ReLU (Krizhevsky et al., 2012)) non-linearity.
We note that none of our networks (except for one) contain Local Response Normalisation (LRN) normalisation (Krizhevsky et al., 2012): as will be shown in Sect. 4, such normalisation does not improve the performance on the ILSVRC dataset, but leads to increased memory consumption and computation time.
重点:
1. 唯一的图像预处理是减去整个图像集的平均值;
2. 卷积核基本都是 3x3 的,只有 VGG-16C 中使用了 1x1 的卷积核,如表1;
3. stride = 1;padding = 1 for 3x3 conv.;
4. 采用 max-pooling;5次;核大小为 2x2;stride = 2;
5. 三个全链接层,通道数分别为 4096, 4096, 1000;
6. 最后一层是 soft-max;
7. 在 VGG 的各个版本中,三个全链接层的结构一致;
8. 每个隐藏层都配有 ReLU;
9. 并没有使用 Local Response Normalisation,因为实验发现没有啥作用。(对比组为 VGG-A-LRN,见表1。)
Table 1: ConvNet configurations (shown in columns). The depth of the configurations increases from the left (A) to the right (E), as more layers are added (the added layers are shown in bold). The convolutional layer parameters are denoted as “convhreceptive field sizei-hnumber of channelsi”. The ReLU activation function is not shown for brevity.
- Configurations
The ConvNet configurations, evaluated in this paper, are outlined in Table 1, one per column. In the following we will refer to the nets by their names (A–E). All configurations follow the generic design presented in Sect. 2.1, and differ only in the depth: from 11 weight layers in the network A (8 conv. and 3 FC layers) to 19 weight layers in the network E (16 conv. and 3 FC layers). The width of conv. layers (the number of channels) is rather small, starting from 64 in the first layer and then increasing by a factor of 2 after each max-pooling layer, until it reaches 512. In Table 2 we report the number of parameters for each configuration. In spite of a large depth, the number of weights in our nets is not greater than the number of weights in a more shallow net with larger conv. layer widths and receptive fields (144M weights in (Sermanet et al., 2014)).
Table 2: Number of parameters (in millions).
重点:
1. 列出了不同的网络配置;除深度不同,每种网络的其它设置都一样;
2. 参数量同一些浅层网络还要小,如 Sermanet et al., 2014 [OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks];主要原因在于只用了 3x3 的卷积核。
- Discussion
It is easy to see that a stack of two 3×3 conv. layers (without spatial pooling in between) has an effective receptive field of 5×5; three such layers have a 7 × 7 effective receptive field.
So what have we gained by using, for instance, a stack of three 3×3 conv. layers instead of a single 7×7 layer?
First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative.
Second, we decrease the number of parameters: assuming that both the input and the output of a three-layer 3 × 3 convolution stack has ![]() channels, the stack is parametrised by
channels, the stack is parametrised by ![]() weights; at the same time, a single 7 × 7 conv. layer would require
weights; at the same time, a single 7 × 7 conv. layer would require ![]() parameters, i.e. 81% more.
parameters, i.e. 81% more.
This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
重点:
1. 2 层 3×3 的感受野= 1层 5×5 感受野;3 层 3×3 感受野 = 1 层 7×7 感受野;
2. 为什么要用 3×3 呢?
1)我们加入了三个非线性的校正层,而不是一个,这使得决策函数更有辨别力;
2)参数更少;
3)这可以看作是对 7×7 滤波器进行正则化,迫使它们通过 3×3 滤波器进行分解(在中间注入非线性)。
The incorporation of 1 × 1 conv. layers (configuration C, Table 1) is a way to increase the nonlinearity of the decision function without affecting the receptive fields of the conv. layers. Even though in our case the 1 × 1 convolution is essentially a linear projection onto the space of the same dimensionality (the number of input and output channels is the same), an additional non-linearity is introduced by the rectification function. It should be noted that 1×1 conv. layers have recently been utilised in the “Network in Network” architecture of Lin et al. (2014).
重点:
1×1 卷积层的加入(VGG-C,表1)是在不影响卷积层感受野的情况下,增加非线性决策函数的一种方法。
GoogLeNet (Szegedy et al., 2014 [Going Deeper with Convolutions] ), a top-performing entry of the ILSVRC-2014 classification task, was developed independently of our work, but is similar in that it is based on very deep ConvNet (22 weight layers) and small convolution filters (apart from 3 × 3, they also use 1 × 1 and 5 × 5 convolutions). Their network topology is, however, more complex than ours, and the spatial resolution of the feature maps is reduced more aggressively in the first layers to decrease the amount of computation. As will be shown in Sect. 4.5, our model is outperforming that of Szegedy et al. (2014) in terms of the single-network classification accuracy.
和 GoogLeNet 的直接对比:VGG 更浅,参数小,准确率高。
Training
The ConvNet training procedure generally follows Krizhevsky et al. (2012) (except for sampling the input crops from multi-scale training images, as explained later). Namely, the training is carried out by optimising the multinomial logistic regression objective using mini-batch gradient descent (based on back-propagation (LeCun et al., 1989)) with momentum. The batch size was set to 256, momentum to 0.9.
The training was regularised by weight decay (the L2 penalty multiplier set to 5 · 10E-4 ) and dropout regularisation for the first two fully-connected layers (dropout ratio set to 0.5).
The learning rate was initially set to 10E-2 , and then decreased by a factor of 10 when the validation set accuracy stopped improving. In total, the learning rate was decreased 3 times, and the learning was stopped after 370K iterations (74 epochs).
We conjecture that in spite of the larger number of parameters and the greater depth of our nets compared to (Krizhevsky et al., 2012), the nets required less epochs to converge due to (a) implicit regularisation imposed by greater depth and smaller conv. filter sizes; (b) pre-initialisation of certain layers.
重点:
1. 训练是通过使用小批量梯度下降和动量优化多项逻辑回归目标来进行的;batch大小设置为256,动量设置为0.9;
2. 训练通过weight decay(L2惩罚乘数设置为5·10E-4)和前两个全连接层的dropout正则化(dropout ratio设置为0.5)进行正则化;
3. 学习速率最初设置为10E-2,当验证集精度不再提高时,学习率减小10倍。总的来说,学习率降低了3次,经过370K次迭代(74个epoch)后学习停止;
4. 我们推测,尽管与(Krizhevsky et al., 2012)相比,VGG参数多、网络深,但比较而言,VGG 需要更少的收敛时间,因为(a)更深的网络和更小的卷积施加的隐式正则化;(b)预先设定某些层。
【关于 implicit regularisation 的文章和网页】
Implicit Regularization in Deep Learning Behnam Neyshabur,2017
Understanding implicit regularization in deep learning by analyzing trajectories of gradient descent Nadav Cohen and Wei Hu,2019
Why Deep Learning Works: Implicit Self-Regularization in Deep Neural Networks Michael W. Mahoney,2018
The initialisation of the network weights is important, since bad initialisation can stall learning due to the instability of gradient in deep nets. To circumvent this problem, we began with training the configuration A (Table 1), shallow enough to be trained with random initialisation. Then, when training deeper architectures, we initialised the first four convolutional layers and the last three fullyconnected layers with the layers of net A (the intermediate layers were initialised randomly). We did not decrease the learning rate for the pre-initialised layers, allowing them to change during learning.
For random initialisation (where applicable), we sampled the weights from a normal distribution with the zero mean and 10E-2 variance. The biases were initialised with zero.
It is worth noting that after the paper submission we found that it is possible to initialise the weights without pre-training by using the random initialisation procedure of Glorot & Bengio (2010).
To obtain the fixed-size 224×224 ConvNet input images, they were randomly cropped from rescaled training images (one crop per image per SGD iteration). To further augment the training set, the crops underwent random horizontal flipping and random RGB colour shift (Krizhevsky et al., 2012).
重点:
1. 两种初始化:
1)先训练VGG-A;然后训练其它 VGG 模型时,用已经训练过的 VGG-A 模型作为初始化;
2)采用 Glorot & Bengio 的随机初始化过程;
2. 数据处理:水平翻转和图像颜色转移等。