机器学习工程实例 垃圾邮件过滤系统 数据预处理 训练模型 交叉验证 精准率召回率计算 步骤详细解析
本博客所有内容均整理自《Hands-On Machine Learning with Scikit-Learn & TensorFlow》一书及其GitHub源码。
看《Hands-On》一书至第三章,习题里面后两题是实际操作的编程题,自己初步动手效果不错,特此记录一下。
运行环境:Jupyter Notebook 语言:Python3.6.4
0、题目描述
总体目标:创建一个垃圾邮件过滤系统
基本步骤:
- 从http://spamassassin.apache.org/old/publiccorpus/网址下载开源数据,包括垃圾邮件和普通邮件
- 解压数据集,观察并熟悉数据格式
- 将数据集分成训练集和测试集
- 制作一个针对该数据集的数据预处理管道,将每一封邮件转换成特征向量的形式
- 添加超参数
- 训练几种机器学习分类器,计算精确率和召回率
1、数据获取
根据题目要求,我们第一步要去下载数据集,其实这一步可以直接打开网址手动下载,但是既然是用Python语言做处理,我们就索性使用Python写代码去下载。
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "http://spamassassin.apache.org/old/publiccorpus/"
HAM_URL = DOWNLOAD_ROOT + "20030228_easy_ham.tar.bz2"
SPAM_URL = DOWNLOAD_ROOT + "20030228_spam.tar.bz2"
SPAM_PATH = os.path.join("datasets", "spam")
def fetch_spam_data(spam_url=SPAM_URL, spam_path=SPAM_PATH):
if not os.path.isdir(spam_path):
os.makedirs(spam_path)
for filename, url in (("ham.tar.bz2", HAM_URL), ("spam.tar.bz2", SPAM_URL)):
path = os.path.join(spam_path, filename)
if not os.path.isfile(path):
urllib.request.urlretrieve(url, path)
tar_bz2_file = tarfile.open(path)
tar_bz2_file.extractall(path=SPAM_PATH)
tar_bz2_file.close()这一步实现下载数据和创建文件路径,首先,我们把所有的文件路径先人为设好,虽然此时根本就没有这样的路径,但是可以先将其设好,然后使用以下两句来通过代码创建path_you_want_to_create(这里具体的路径就随个人自定义了)路径:
if not os.path.isdir(spam_path):
os.makedirs(spam_path)创建好路径之后,我们使用以下两句来实现网络数据向指定路径的下载:
if not os.path.isfile(path):
urllib.request.urlretrieve(url, path)下载完成之后就是解压了,这里其实我相当于是开了上帝视角,提前就知道下载下来的数据是tar格式的压缩文件,于是使用tarfile.open()函数去打开,使用extractall()函数去解压。
定义好了函数之后,直接调用该函数就可以创建路径,下载数据,并解压。
fetch_spam_data()至此,数据获取过程结束!
2、数据预处理
题目明确要求,下载并解压数据之后,我们必须观察并熟悉数据格式,然后将数据分成训练集和测试集,再制作一个数据预处理的特征管道来对数据进行清洗,这一系列的操作组合起来,就是数据预处理过程。
我们首先将解压好的数据打开看看。
HAM_DIR = os.path.join(SPAM_PATH, "easy_ham")
SPAM_DIR = os.path.join(SPAM_PATH, "spam")
ham_filenames = [name for name in sorted(os.listdir(HAM_DIR)) if len(name) > 20]
spam_filenames = [name for name in sorted(os.listdir(SPAM_DIR)) if len(name) > 20]这里我对数据进行了一次排序,相当于做了一次整理,要求name长度大于20,是因为防止下载的数据不全,因为不管是垃圾邮件还是普通邮件,肯定都是不止20封的。
获取到数据之后,我们首先来看一下垃圾邮件和普通邮件分别有多少封。
len(ham_filenames)
len(spam_filenames)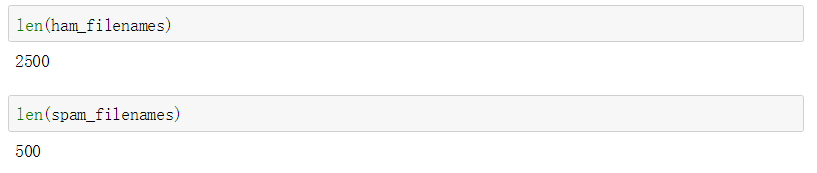
根据结果显示,被标为垃圾邮件的有500封,被标为普通邮件的有2500封。很明显,这个实际结果的分类情况是不均衡的。
接下来,我们就要实际去获取邮件的具体内容了,这需要用到email模块,我们根据该模块自定义一个获取邮件内容的函数,并调用该函数来分别获取垃圾邮件和普通邮件。
import email
import email.policy
def load_email(is_spam, filename, spam_path=SPAM_PATH):
directory = "spam" if is_spam else "easy_ham"
with open(os.path.join(spam_path, directory, filename), "rb") as f:
return email.parser.BytesParser(policy=email.policy.default).parse(f)
ham_emails = [load_email(is_spam=False, filename=name) for name in ham_filenames]
spam_emails = [load_email(is_spam=True, filename=name) for name in spam_filenames]email模块的具体使用方式暂且忽略,从代码中可以看出,我们通过判断is_spam变量是True还是False来区分垃圾邮件和普通邮件,并且最终获得的邮件数据应该是一个稀疏矩阵(parse)。据此,ham_emails和spam_emails就得到了。
我们先来直观感受一下这两类邮件内容,分别随意选取一封,获取内容,并去掉邮件头,发送日期等信息。
print(ham_emails[4].get_content().strip())
print(spam_emails[5].get_content().strip())首先是普通邮件:

从内容上来看,这是一封以个人名义发送的邮件,很可能使用的邮箱是雅虎邮箱,具体内容都是一些偏私人的东西。
再来看一下垃圾邮件:

很明显这就是一封广告邮件,虽然最后发信人还极力表示“This is not spam!”,可能他自己也认为这就是一封spam吧。
对比这两封邮件,我们可以很明显发现,首先,普通邮件应该不会有那么多的数字,而垃圾邮件则不然,因为广告邮件经常需要留下电话号码,标出价格等等,所以数字很多;其次,垃圾邮件会有很多奇怪的符号,比如$,¥,甚至这里根本无法识别的符号,而普通的邮件一般不存在这些;最后,垃圾邮件有调查问卷一样的东西,包括大量下划线,而普通邮件几乎不可能有下划线。
OK,上面都是我们个人根据这两封邮件做出的简单推测,不一定具有普适性,想要更准确地来预测垃圾邮件和普通邮件的区别,还是得从大数据量的结果来分析。但是从上面的简单分析推测我们还是可以找出一些端倪,起码每封邮件的结构以及数字、图片这些信息的数量很可能比较重要,所以我们自定义两个函数,来获取邮件结构,并对不同结构的邮件进行计数。
def get_email_structure(email):
if isinstance(email, str):
return email
payload = email.get_payload()
if isinstance(payload, list):
return "multipart({})".format(", ".join([
get_email_structure(sub_email)
for sub_email in payload
]))
else:
return email.get_content_type()
from collections import Counter
def structures_counter(emails):
structures = Counter()
for email in emails:
structure = get_email_structure(email)
structures[structure] += 1
return structures第一个函数主要就是获取内容的类型,第二个函数就是对不同类型的邮件进行计数。
有了这两个函数,我们就可以对普通邮件和垃圾邮件分别统计它们的类型了,这里必须分开统计,这样才可以从大数据的统计级别上看出垃圾邮件和普通邮件之间在结构上的不同。
structures_counter(ham_emails).most_common()
structures_counter(spam_emails).most_common()首先来看普通邮件的结构分析结果:

然后来看垃圾邮件的结构分析结果:

我们对比分析上面两类邮件的结构分析结果,可以得出以下有趣的发现:
- 无论是哪类邮件,最多的结构类型都是“text/plain”,这一点很好理解,邮件嘛,肯定还是基于文字的
- 对于普通邮件,除去单一的文字结构,其他全是混合结构的,没有其他类型的单一结构,而且混合结构里也一定包含文字类型;而对于垃圾邮件,除去文字类型之外,还有一种单一结构,而且占比很高,那就是“text/html”!这一点发现很激动人心,因为前面光对比我们随意选择的垃圾邮件并没有看到html结构的网址,但是基于大数据的统计就可以看出,有很多垃圾邮件就是专门只有文字和网址链接的!
- 普通邮件占比第二多的混合类型里,会使用到应用和PGP签名,然而垃圾邮件里一封包含相关内容的都没有!这很有意义,因为几乎可以宣判,只要识别到应用和PGP签名,那就是一封普通邮件,而不是垃圾邮件!
人为观察毕竟能力有限,能归纳出以上三点已经算是比较有眼力了。毕竟我们后面是要去做机器学习的,现在大致有个总体把握就足够了。起码我们知道邮件结构对于分类很有用,具体说来有上面三条规律。
接下来,我们来看看邮件头。其实邮件头很明显是一个很重要的特征,比如说某一个邮箱账户地址已经被很多人标注为广告商了,那么该地址发出来的邮件,十有八九就是垃圾邮件了。
好的,我们首先来整体观察一下某一封邮件的邮件头信息:
for header, value in spam_emails[0].items():
print(header,":",value)
spam_emails[0]["Subject"]
首先我们会发现,其实邮件的header参数,不仅仅是邮件标题,而是包含了很多很多题注,value参数则是这些题注的具体内容。而真正的邮件标题,则是Subject特征的值。
我们可以看到这封邮件的标题是“Life Insurance - Why Pay More?”,光看标题就感觉很像是一封人寿保险的广告邮件。
而且仔细观察可以发现,这封邮件被发给了很多人,而且还有被退回的情况,这些特征根据人为经验判断也非常像广告垃圾邮件。
至此,我们已经基本上对这些邮件数据有了一定的了解了,起码已经熟悉数据格式了。
接下来,按照题目要求,我们正式将这些邮件数据分成训练集和测试集。具体的分集方法就是调用train_test_split函数。
import numpy as np
from sklearn.model_selection import train_test_split
X = np.array(ham_emails + spam_emails)
y = np.array([0] * len(ham_emails) + [1] * len(spam_emails))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)分好训练集和测试集之后,我们就来正式开始对邮件数据进行清洗。
首先,我处理的第一个问题是html数据格式。根据上面观察的经验,垃圾邮件里有很多的纯html邮件,这些邮件甚至有可能不包含有效文字,全部是html链接,因为这些邮件的目的很明显只为打广告!
处理html数据格式的方法是从html模块中调用unescape函数,对一些特殊的数据格式进行清除。具体来说,首先删除
部分的内容,然后将所有标记转换为单词”HTML”,据此将所有html标记全部删除,只留下纯文本。其实说白了就是把html链接的具体内容全部删除,替换为单词“HTML”,于是全部剩下文字信息。另外还有一些特殊格式的格式清洗。具体的函数如下:import re
from html import unescape
def html_to_plain_text(html):
text = re.sub('.*?', '', html, flags=re.M | re.S | re.I)
text = re.sub('', ' HYPERLINK ', text, flags=re.M | re.S | re.I)
text = re.sub('<.*?>', '', text, flags=re.M | re.S)
text = re.sub(r'(\s*\n)+', '\n', text, flags=re.M | re.S)
return unescape(text) 接下来我们从垃圾邮件中提取出一个html格式的垃圾邮件,看看我们自定义的函数的清洗效果。首先我们打印原邮件内容:
html_spam_emails = [email for email in X_train[y_train==1]
if get_email_structure(email) == "text/html"]
sample_html_spam = html_spam_emails[7]
print(sample_html_spam.get_content().strip()[:1000], "...")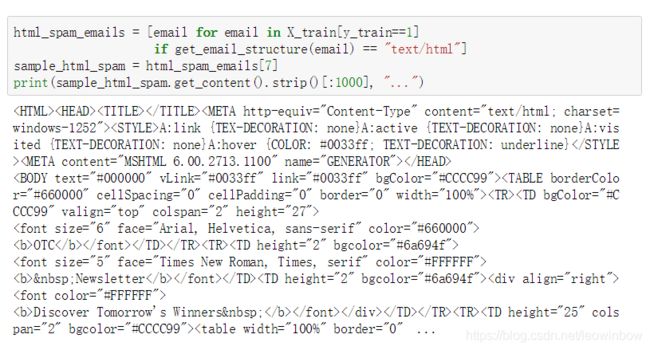
然后再打印转换之后的邮件内容:
print(html_to_plain_text(sample_html_spam.get_content())[:1000], "...")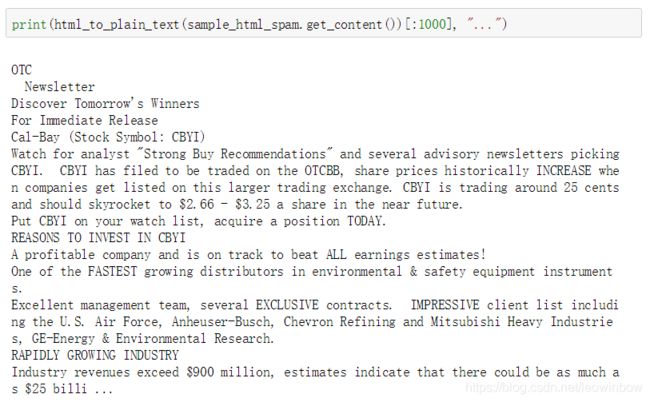
很明显,转换之后的邮件就全部是文字信息了!
接下来我们就可以定义一个函数,将任何一封邮件作为输入,都可以输出一封纯文字信息的邮件。
def email_to_text(email):
html = None
for part in email.walk():
ctype = part.get_content_type()
if not ctype in ("text/plain", "text/html"):
continue
try:
content = part.get_content()
except: # in case of encoding issues
content = str(part.get_payload())
if ctype == "text/plain":
return content
else:
html = content
if html:
return html_to_plain_text(html)这个函数可以处理text/plain格式,text/html格式以及纯html格式。而且不管什么格式的输入,最终都会输出纯文字格式,也就是text/plain格式。
接下来做一个测试看看效果:
print(email_to_text(sample_html_spam)[:100], "...")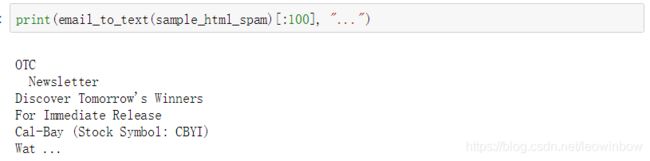
可以看到随便处理一封邮件,输出一定是纯文字形式。
接下来,我们就可以得到所有的邮件的纯文字形式了。得到纯文字形式的邮件之后,我们就可以使用成熟的自然语言处理的工具了。关于自然语言处理,本身就是一个非常巨大的范畴,而且技巧非常非常多,这里就不详细介绍具体的自然语言处理知识了,直接沿用前人留下的经验代码就好。
try:
import nltk
stemmer = nltk.PorterStemmer()
for word in ("Computations", "Computation", "Computing", "Computed", "Compute", "Compulsive"):
print(word, "=>", stemmer.stem(word))
except ImportError:
print("Error: stemming requires the NLTK module.")
stemmer = None其中nltk包的全称是Natural Language Toolkit。
另外我们还需要对URL类型的数据进行清洗,替换为单词“URL”。我们同样使用已有的函数来处理:
try:
import urlextract # may require an Internet connection to download root domain names
url_extractor = urlextract.URLExtract()
print(url_extractor.find_urls("Will it detect github.com and https://youtu.be/7Pq-S557XQU?t=3m32s"))
except ImportError:
print("Error: replacing URLs requires the urlextract module.")
url_extractor = None接下来,我们将使用split函数将所有邮件的这些语句划分成一个一个的单词,即分词,具体的分法是根据空格来作为单词的分界。该邮件数据集几乎全是英文写的,所以使用空格作为分词边界还是比较靠谱的。
from sklearn.base import BaseEstimator, TransformerMixin
class EmailToWordCounterTransformer(BaseEstimator, TransformerMixin):
def __init__(self, strip_headers=True, lower_case=True, remove_punctuation=True,
replace_urls=True, replace_numbers=True, stemming=True):
self.strip_headers = strip_headers
self.lower_case = lower_case
self.remove_punctuation = remove_punctuation
self.replace_urls = replace_urls
self.replace_numbers = replace_numbers
self.stemming = stemming
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X_transformed = []
for email in X:
text = email_to_text(email) or ""
if self.lower_case:
text = text.lower()
if self.replace_urls and url_extractor is not None:
urls = list(set(url_extractor.find_urls(text)))
urls.sort(key=lambda url: len(url), reverse=True)
for url in urls:
text = text.replace(url, " URL ")
if self.replace_numbers:
text = re.sub(r'\d+(?:\.\d*(?:[eE]\d+))?', 'NUMBER', text)
if self.remove_punctuation:
text = re.sub(r'\W+', ' ', text, flags=re.M)
word_counts = Counter(text.split())
if self.stemming and stemmer is not None:
stemmed_word_counts = Counter()
for word, count in word_counts.items():
stemmed_word = stemmer.stem(word)
stemmed_word_counts[stemmed_word] += count
word_counts = stemmed_word_counts
X_transformed.append(word_counts)
return np.array(X_transformed)以上的函数不仅能进行分词,还能将所有单词全部转换为小写,对URL进行替换,对标点符号进行删除,以及对不同的单词实现计数。
我们首先来随便选取一些邮件进行测试:
X_few = X_train[:3]
X_few_wordcounts = EmailToWordCounterTransformer().fit_transform(X_few)
X_few_wordcounts
看起来效果非常好!
得到这些分开的单词以及单词计数之后,我们就要自定义一个类,来进行自定义的fit和transform了。我们希望fit方法能根据出现的单词创建一个单词列表,而transform方法则能够根据创建的单词列表以及各单词出现的计数来生成单词向量。
from scipy.sparse import csr_matrix
class WordCounterToVectorTransformer(BaseEstimator, TransformerMixin):
def __init__(self, vocabulary_size=1000):
self.vocabulary_size = vocabulary_size
def fit(self, X, y=None):
total_count = Counter()
for word_count in X:
for word, count in word_count.items():
total_count[word] += min(count, 10)
most_common = total_count.most_common()[:self.vocabulary_size]
self.most_common_ = most_common
self.vocabulary_ = {word: index + 1 for index, (word, count) in enumerate(most_common)}
return self
def transform(self, X, y=None):
rows = []
cols = []
data = []
for row, word_count in enumerate(X):
for word, count in word_count.items():
rows.append(row)
cols.append(self.vocabulary_.get(word, 0))
data.append(count)
return csr_matrix((data, (rows, cols)), shape=(len(X), self.vocabulary_size + 1))该类首先规定单词列表最多只能有1000个单词,即出现次数太少的单词将不会被记录;然后对各个单词进行计数;并将计数结果全部以向量的形式记录下来。
我们来看看该类的效果:
vocab_transformer = WordCounterToVectorTransformer(vocabulary_size=10)
X_few_vectors = vocab_transformer.fit_transform(X_few_wordcounts)
X_few_vectors
X_few_vectors.toarray()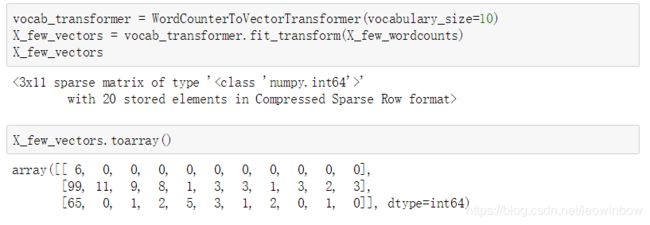
我们使用toarray()函数将记录的结果以矩阵的形式展现出来,但是这个矩阵具体表示什么意思呢?
以上面图片中的情况为例,第一列的数字说明了每封邮件中的忽略单词个数,而后面列的数字则代表着单词列表中的单词在每封邮件中出现的次数。
比如图片中第一列第三行的数字是65,这说明第三封邮件中共有65个单词是没有出现在单词列表中的,即这65个单词是超过1000的部分,被忽略了的;同理,第一列第二行的99即代表第二封邮件有99个单词是被忽略了的。
接下来,对于第二列第二行的数字11,这说明单词列表的第一个单词在第二封邮件中出现了11次;同理,第五列第三行的数字是5,这说明单词列表的第四个单词在第三封邮件中出现了5次。
于是,单词列表就非常重要了,因为只有看了单词列表,我们才知道上述矩阵的第二列到第十一列分别代表哪些单词:
vocab_transformer.vocabulary_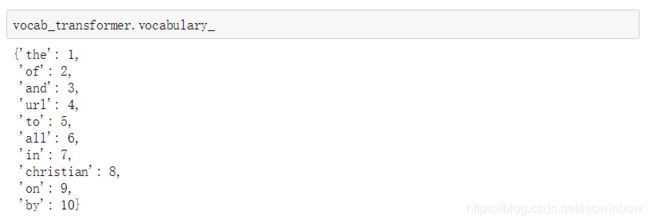
于是据此,我们就得到了根据数据集邮件生成的单词列表,以及关于单词列表的向量或矩阵。
接下来,我们就可以具体来进行数据集的清洗了。其实清洗的方式还是制作管道,在这里,针对垃圾邮件过滤的管道,根据我们之前观察数据的经验,主要就是对初始邮件的清洗,清洗成纯文字形式,然后通过自然语言处理的方式来处理,获得单词计数,然后据此生成单词列表,并对列表内的单词进行计数。
from sklearn.pipeline import Pipeline
preprocess_pipeline = Pipeline([
("email_to_wordcount", EmailToWordCounterTransformer()),
("wordcount_to_vector", WordCounterToVectorTransformer()),
])
X_train_transformed = preprocess_pipeline.fit_transform(X_train)至此,邮件过滤系统的管道就制作好了,数据预处理过程也就结束了。
3、训练模型和交叉验证
到这里,其实工作量已经不大了,所以我把训练模型和交叉验证放到一起了。
其实这两个步骤本来也就是各一行代码解决。
对于模型,我就随便选择了一个逻辑回归来进行学习,其实数据预处理完成得好,使用什么模型都不是特别重要了,毕竟超参数调优是一个太复杂的过程。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
log_clf = LogisticRegression(solver="liblinear", random_state=42)
score = cross_val_score(log_clf, X_train_transformed, y_train, cv=3, verbose=3)
score.mean()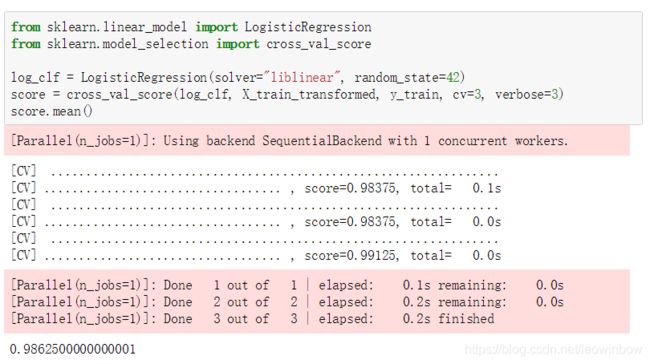
根据结果显示,交叉验证的结果达到了98%以上,接近99%了!某种意义上来说,已经过拟合了。
4、精确率和召回率的计算
接下来根据题目的要求,来计算一下精确率和召回率。
要计算这两个数值,我们必须首先让模型对测试集进行预测,然后把训练集和测试集都进行特征管道的数据清洗,当然这里对训练集的数据清洗在上一步已经完成了,所以只需要对测试集进行清洗和预测;最后,我们据此来计算精确率和召回率:
from sklearn.metrics import precision_score, recall_score
X_test_transformed = preprocess_pipeline.transform(X_test)
log_clf = LogisticRegression(solver="liblinear", random_state=42)
log_clf.fit(X_train_transformed, y_train)
y_pred = log_clf.predict(X_test_transformed)
print("Precision: {:.2f}%".format(100 * precision_score(y_test, y_pred)))
print("Recall: {:.2f}%".format(100 * recall_score(y_test, y_pred)))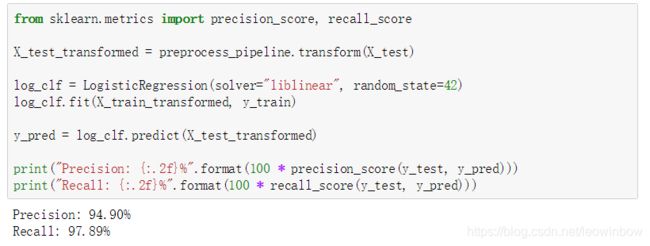
根据结果显示,精确率和召回率都非常非常高!看来并没有过拟合!
5、总结
稍微简单总结一下这个垃圾邮件过滤系统的工程项目。主要步骤其实就7步:
- 数据获取
- 数据特征观察
- 数据清洗
- 制作特征管道
- 训练模型
- 交叉验证
- 计算精确率和召回率
根据这7步来,基本上都可以完成垃圾邮件的过滤系统,只是性能效果的差别了。而且只要前4步进行得顺利,后面从训练模型开始,除了超参数调优之外,就很少受到人为经验的影响了。