大白话Prophet模型以及简单的应用(一)
Prophet 是基于加法模型预测时间序列数据。适合于具有季节性影响的时间序列和具有多个季节的历史数据。Prophet对数据中的异常值和缺失值以及趋势的强烈变化有着较好的鲁棒性(耐操性),所以通常情况下都不需要对数据进行处理。
优点:
- 准确快速
本模型是Facebook开源的一个模型,据官网说本模型已经大量运用于许多应用程序中,发现在大多数情况下,它的性能优于其他方法,并且能在短时间内的得到预测 - 参数可解释强
模型中的参数都有着比较具象的含义,有季节性(年月日为周期)、节假日,操作者可以结合项目背景,进行调参,并对别人做出解释
模型原理
y(t)=g(t)+s(s)+h(t)+ϵt
g(t)表示增长函数,用来拟合非周期性变化的。
s(t)用来表示周期性变化,比如说每周,每年,季节等。
h(t)表示假期,节日等特殊原因等造成的变化。
ϵt为噪声项,用他来表示随机无法预测的波动,我们假设ϵt是高斯的。

- 时间序列模型:分析师可以根据不同的项目背景,建立不同的模型
- 模型评估:根据模型对历史数据进行拟合,在模型参数不确定的情况下,进行多种尝试,并对模型进行评估
- 呈现问题:尝试了多种参数后,模型依然不理想,则会把误差较大的原因呈现给分析师
- 结果可视化:以可视化的方式呈现给分析师,分析师可以更加直观的得知问题所在并对模型进行调整
在Prophet模型中,模型评估和呈现问题是自动处理,分析师只需要注重模型建立和结果可视化就行
模型的简单应用
这里我们以基于Prophet模型对新冠的预测中的数据来为大家举例说明,在例子中,我们为大家详细介绍模型
首先向大家展示数据的格式

但是由于Prophet模型的输入必须包含两列数据:ds和y,其中ds列的数据必须是时间戳或日期,日期格式为 YYYY-MM-DD,时间戳格式为 YYYY-MM-DD HH:MM:SS;y列必须是数值,代表我们需要预测的信息。
假设我们要预测确诊病例的情况,首先我们需要对列名进行重命名
导入数据、修改列名
import pandas as pd
path="D:\\疫情预测\\USA.csv"
data=pd.read_csv(path,parse_dates=["date"])
data_new=data.rename(columns={"date":"ds","cases":"y"})
建立模型
from fbprophet import Prophet
pm=Prophet()
参数解释:
这里我们将简单介绍一下Prophet的参数
| 参数 | 描述 |
|---|---|
| growth | 模型的趋势函数,有linear和logistic两种,默认为linear函数 |
| changepoints | 是指一个特殊的日期,在这个日期,模型的趋势将发生一定的改变(比如周末确诊人数一般会激增),我们可以手动设置,若不设置,则模型自动识别 |
| n_changepoints | 表示changepoints的数量,如果changepoints指定了,则该参数失效不被使用,一般配合changepoint_range使用 |
| changepoint_range | 估计趋势变化点的历史比例,若changepoints被指定,则该参数失效不被使用,一般配合n_changepoints使用。例如Prophet(changepoint_range=0.9,n_changepoints=30),表示从历史数据的前90%中自动选取30个趋势变化点。默认情况下是前80%取25个点 |
| changepoint_prior_scale | 设定自动突变点选择的灵活性,值越大越容易出现changepoint |
补充:
linear函数(分段线性函数)
- 线性函数指的是y=kx+b,分段线性函数指的是在每一个子区间上,函数都是线性函数

logistic函数

growth=’linear’和growth=’logistic’该如何选择?
根据图像,很容易看出logistic有上限和下限,所以当项目背景存在一个饱和点的时候,可以选择logistic函数,一般情况使用linear函数,prohphet默认的也是选择linear
除此之外,还有其他参数,本章就不展开细说,下面列出所有参数:
class Prophet(object):
def __init__(
self,
growth='linear',
changepoints=None,
n_changepoints=25,
changepoint_range=0.8,
yearly_seasonality='auto',
weekly_seasonality='auto',
daily_seasonality='auto',
holidays=None,
seasonality_mode='additive',
seasonality_prior_scale=10.0,
holidays_prior_scale=10.0,
changepoint_prior_scale=0.05,
mcmc_samples=0,
interval_width=0.80,
uncertainty_samples=1000,
stan_backend=None
):
模型训练以及预测
#首先分割数据集,我们这里采用预测区间前两个月的数据,来预测后一个月的数据,下面是分割训练集和预测集
train_data = data_new[-90:-30]
test_data = data_new[-30:]
#建立模型并训练
pm=Prophet(changepoint_prior_scale=0.95)
pm.fit(train_data )
#预测30天
future = pm.make_future_dataframe(periods=30)
pm_forecast = pm.predict(future)
可视化
fig1 = pm.plot(pm_forecast)
fig2 = pm.plot_components(pm_forecast)
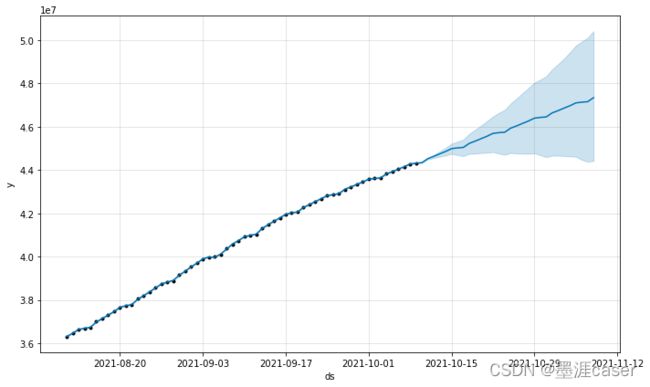
结果如图:
下图黑点为历史数据,蓝线为拟合曲线,蓝色范围为预测区间
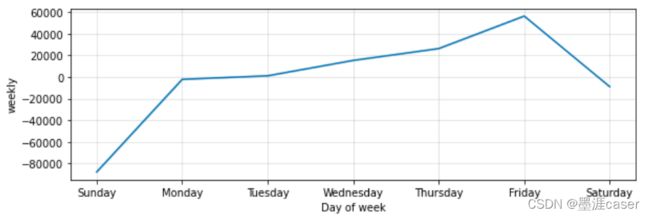
下图为每周的趋势变化,可以得出结论,在周五的时候,确诊人数增加最快,周日增加最慢,那我们可以结合背景做出解释,比如周一到周五大家要工作,所以接触频繁,容易感染,周六周日大家都待在家里,接触少,所以感染不那么容易
自此,我们就通过Prophet模型,完成了对确诊人数的预测,并对结果进行了可视化,下一章我们会对prophet模型的其他方法以及参数进行描述和使用