机器学习模型评估指标
Ⅰ. 分类问题常用
- 精度 Accuracy
- 混淆矩阵
- 查准率(准确率)
- 查全率(召回率)
- PR曲线与AP、mAP
- F值
- ROC曲线与AUC值
- Hinge loss
- Matthews相关系数 / phi系数 :二值化输入
1. 混淆矩阵(精确率Precision,召回率Recall)
反映正例、反例查出的准确率

精确率(Precision)和召回率(Recall)
在不同的应用场景下,我们的关注点不同,例如,在预测股票的时候,我们更关心精准率,即我们预测升的那些股票里,真的升了有多少,因为那些我们预测升的股票都是我们投钱的。而在预测病患的场景下,我们更关注召回率,即真的患病的那些人里我们预测错了情况应该越少越好。
精确率和召回率是一对此消彼长的度量。例如在推荐系统中,我们想让推送的内容尽可能用户全都感兴趣,那只能推送我们把握高的内容,这样就漏掉了一些用户感兴趣的内容,召回率就低了;如果想让用户感兴趣的内容都被推送,那只有将所有内容都推送上,宁可错杀一千,不可放过一个,这样准确率就很低了。


在实际工程中,我们往往需要结合两个指标的结果,去寻找一个平衡点,使综合性能最大化。

2. P-R曲线(Precision Recall Curve)
P-R曲线是描述精确率/召回率变化的曲线,根据学习器的预测结果(一般为一个实值或概率)对测试样本进行排序,将最可能是“正例”的样本排在前面,最不可能是“正例”的排在后面,按此顺序逐个把样本作为“正例”进行预测(一个点对应一个阈值)每次计算出当前的P值和R值,如下图所示:


根据 P-R 曲线,我们就可以去评价学习器性能的优劣
- 当曲线没有交叉的时候:外侧曲线的学习器性能优于内侧;
- 当曲线有交叉的时候:比较曲线下面积(值不容易计算)或者 比较两条曲线的平衡点 Break-Even Point (BEP),平衡点是“precision=recall”时的取值,在上图中表示为曲线和对角线的交点,平衡点在外侧的曲线的学习器性能优于内侧
3. F-score
正如上文所述,Precision和Recall指标有时是此消彼长的,即精准率高了,召回率就下降,在一些场景下要兼顾精准率和召回率,最常见的方法就是F-Measure,又称F-Score。F-Measure是P和R的调和平均:

如果引入β(度量了recall 对 precision 的相对重要性),F-Score是加权调和平均:
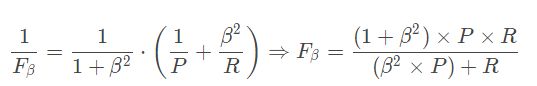
其中β>0。 β越大时recall 有更大影响,反之,precision 有更大影响。
多分类时的F-score(每两两类别的组合都对应一个混淆矩阵)
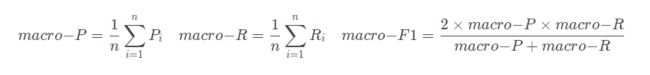

4. ROC与AUC曲线
- ROC曲线主要两个指标就是真正率TPR(即正样本的召回率(TP/(TP+FN)))和假正率FPR(FP/(TN+FP))即负样本误判的程度

- 这两个指标的选择使得ROC可以无视样本的不平衡,使测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变
- 另一个使用原因是,ROC和上面做提到的P-R曲线一样,是一种不依赖于阈值(Threshold)的评价指标,在输出为概率分布的分类模型中,如果仅使用准确率、精确率、召回率作为评价指标进行模型对比时,都必须时基于某一个给定阈值的,对于不同的阈值,各模型的Metrics结果也会有所不同,这样就很难得出一个很置信的结果。
- 与前面的P-R曲线类似,ROC曲线也是通过遍历所有阈值来绘制整条曲线的。如果我们不断的遍历所有阈值,预测的正样本和负样本是在不断变化的,相应的在ROC曲线图中也会沿着曲线滑动。
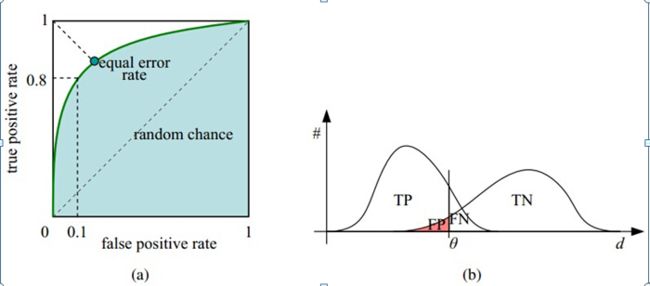 横轴FPR越大,预测正类中实际负类越多。纵轴TPR越大,预测正类中实际正类越多。
横轴FPR越大,预测正类中实际负类越多。纵轴TPR越大,预测正类中实际正类越多。

根据ROC曲线,判断模型性能:
- 我们希望负样本误判的越少越好,正样本召回的越多越好,即TPR越高,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好。
- 进行模型的性能比较时,与PR曲线类似,若一个模型A的ROC曲线被另一个模型B的ROC曲线完全包住,则称B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优
- AUC (Area Under Curve)又称为曲线下面积,是处于ROC Curve下方的那部分面积的大小。上文中我们已经提到,对于ROC曲线下方面积越大表明模型性能越好,于是AUC就是由此产生的评价指标。
- AUC对所有可能的分类阈值的效果进行综合衡量。首先AUC值是一个概率值,可以理解为随机挑选一个正样本以及一个负样本,分类器判定正样本分值高于负样本分值的概率就是AUC值。简言之,AUC值越大,当前的分类算法越有可能将正样本分值高于负样本分值,即能够更好的分类。

PR曲线和ROC
ROC和PRC在模型性能评估上效果都差不多,但需要注意的是,在正负样本分布得极不均匀(highly skewed datasets)的情况下,PRC比ROC能更有效地反应分类器的好坏。在数据极度不平衡的情况下,譬如说1万封邮件中只有1封垃圾邮件,那么如果我挑出10封,50封,100…封垃圾邮件(假设我们每次挑出的N封邮件中都包含真正的那封垃圾邮件),Recall都是100%,但是FPR分别是9/9999, 49/9999, 99/9999(数据都比较好看:FPR越低越好),而Precision却只有1/10,1/50, 1/100 (数据很差:Precision越高越好)。所以在数据非常不均衡的情况下,看ROC的AUC可能是看不出太多好坏的,而PR curve就要敏感的多
5. GINI系数
Gini系数 = 2AUC - 1
6. KS(Kolmogorov-Smirnov)
KS统计量是信用评分和其他很多学科中常见的统计量,在金融风控领域中,常用于衡量模型对正负样本的区分度。通常来说,值越大,模型区分正负样本的能力越强,一般0.3以上,说明模型的效果比较好(申请评分卡)。其定义如下:
![]()
KS和ROC的关系:KS=max(TPR-FPR)
Ⅱ. 回归拟合
- R2决定系数
- 平均绝对误差(MAE mean absolute error)
- 均方误差(MSE mean squared error)
- 均方根误差(RMSE root mean squared error)
Ⅲ. 聚类模型评估
1. 簇内误差平方和SSE
理论上,该数值越小越好。该指标的局限性在于只考虑了簇内相似度,没有考虑不同簇之间的关系。
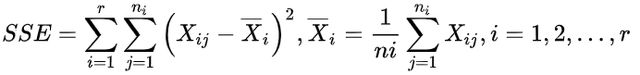
2. CP紧密性 Compactness
针对单个聚类簇,计算簇内样本与中心点的平均距离,最后取所有簇的平均值即可计算出该指标。和SSE类似,也是只考虑了簇内相似度, 数值越小,聚类效果越好。

3. SP间隔性 Separation
通过计算两两聚类中心点的距离来得到最终的数值。和紧密型相反,该指标仅仅考虑不同簇之间的距离,数值越大,聚类效果越好。

4. 轮廓系数 Silhouette Coefficient
最佳值为1,最差值为-1。接近0的值表示重叠的群集。负值通常表示样本已分配给错误的聚类,因为不同的聚类更为相似

簇内不相似度a(i) :i向量到同簇内其他点不相似程度的平均值,体现凝聚度
簇间不相似度b(i) :i向量到其他簇的平均不相似程度的最小值,体现分离度
5. CH指数 Calinski-Harabaz Index
综合考虑了簇间距离和簇内距离。CH的数值越大,说明簇内距离越小,簇间距离越大,聚类效果越好。
6. DBI 戴维森堡丁指数 Davies-Bouldin Index
聚类簇之间的距离越远,聚类内的距离越近,DB指数的值越小,聚类性能越好。
7. DVI 邓恩指数 Dunn Validity Index
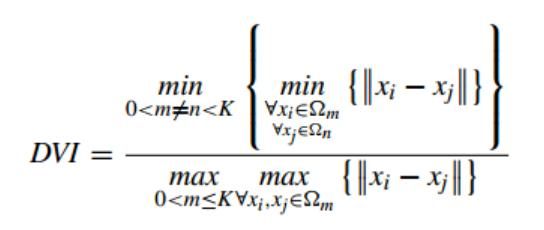
分子为聚类簇间样本的最小距离,分母为聚类簇内样本的最大距离,类间距离越大,类内距离越小,DVI指数的值越大,聚类性能越好。
Ⅳ. 目标检测任务
- 目标检测任务常用的评价指标是建立在图像分类评价指标的基础之上
1. IOU(Intersection over Union)交并比
预测框与标注框的交集与并集之比,数值越大表示该检测器的性能越好


2. AP与mAP
AP(average precision)就是Precision-recall 曲线(P-R曲线)下围成的面积,通常来说一个越好的分类器,AP值越高。mAP(mean average precision)是多个类别AP的平均值。
Ⅴ. 图像分割指标评估
- 像素准确率(Pixel Accuracy,PA)
- 类别像素准确率(Class Pixel Accuray,CPA)
- 类别平均像素准确率(Mean Pixel Accuracy,MPA)
- 交并比(Intersection over Union,IoU)
- 平均交并比(Mean Intersection over Union,MIoU)
- DICE系数
1. 像素准确率(Pixel Accuracy,PA)
像素准确率的含义是预测类别正确的像素数占总像素数的比例。它对应上述的准确率(Accuracy),计算公式如下:
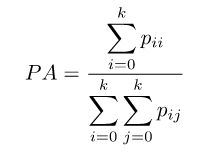
2. DICE系数
DICE系数也是常用的分割评价标准之一,DICE系数的取值范围为0到1,越接近1说明构建的模型越好,分割的效果越好。DICE系数是像素级别的,真实的目标ground truth出现在某片区域X,模型预测结果的目标区域为Y,那么Dice系数公式如下图所示。

上图中,红色矩形块是GroundTruth(用X表示),绿色矩形框是预测的矩形框(用Y表示),它们之间的黄色交集区域是True Positive,剩余的绿色区域为False Positive,剩余的红色区域为False Negative。
3. Hausdorff 距离
Hausdorff 距离: 度量空间中真子集之间的距离。所谓度量空间,也就是一个集合,其中任意元素之间的距离可定义;真子集就简单理解成一组有限(可以是无限)数目的元素(点)集合。因此,Hausdorff距离可以理解成一个点集中的点到另一个点集的最短距离的最大值。

Ⅵ. 生成模型评估
图像生成
Inception score(IS)
- 清晰度:把生成的图片x输入到Inception V3中,将输出1000维的向量,向量的每个维度的值对应图片属于某类的概率,对于一个清晰的图片,它属于某一类的概率应该非常大(其实这个还真不一定,也有可能出现图片很清晰,但是具体属于哪个类却是模棱两可的,而且分类也未必正确,甚至都不在top-5都有可能)。而属于其他类的概率应该很小。
- 多样性:如果一个模型能生成足够多样的图片,那么它生成的图片在各个类别中的分布应该是平均的
- IS对神经网络内部权重十分敏感, TensorFlow, Torch 和 Keras 等不同框架下预训练的 Inception V2 和 Inception V3,尽管不同框架预训练网络达到同样的分类精度,但是Inception score却相差很大。
AM score(AMS)
AMS(AM Score)的考虑是:IS假设类别标签具有均匀性,生成模型GAN生成1000类的概率是大致相等的,故可使用y 相对于类别的熵来量化该项,但当数据在类别分布中不均匀时,IS评价指标是不合理的,更为合理的选择是计算训练数据集的类别标签分布与生成数据集的类别标签分布的KL散度
Frechet Inception Distance score(FID)
GAN的初衷是希望得到一个分布,使得该分布尽可能地与真实分布靠近,但是IS只是考虑了生成图像的清晰度和多样性,完全忽略了真实数据的影响,因此FID考虑更多的是生成图像与真实图像之间的联系。
具体实现过程:将生成的图像x给入inception网络,得到2048维向量输出,取同样数目的生成图像和真实图像各N张,经过Inception网络,各自得到N*2048维特征向量,然后用下面公式计算两个N*2048维特征向量之间的距离:

FID表示的是生成图像的特征向量与真实图像的特征向量之间的距离,该距离越近,表明生成模型的效果越好,即图像的清晰度高,且多样性丰富。
MMD(Maximum Mean Discrepancy)
MMD在迁移学习中具有非常广泛的应用,它是在希尔伯特空间对两个分布的差异的一种度量,故可以考虑使用MMD度量 训练数据集分布和 生成数据集分布的距离,然后使用这个距离作为GAN的评价指标。若MMD距离越小,则表示两者分布越接近,GAN的性能越好。
Image Quality Measures
在该类评价指标中,我们直接对图像本身的质量进行量化,而不像IS借助Inception V3或训练其他神经网络等手段,这里的典型代表有SSIM, PSNR and Sharpness Difference。
- SSIM(Structural SIMilarity):两个图像样本之间的亮度 、对比度 、结构 三个方面
- PSNR(Peak Signal-to-Noise Ratio)即峰值信噪比
- SD(Sharpness Difference)与PSNR计算方式类似,但其更关注锐度信息的差异。
文本生成
ROUGE
主要是一种面向召回率的评价方法ROUGE(Recall-Oriented Understudy for Gisting Evaluation),该方法可细分为ROUGE-N,ROUGE-L,ROUGE-W以及ROUGE-S四种评价指标
BLEU
主要是一种评估机器翻译结果质量的BLEU,BLEU指标先计算生成翻译与相应的参考翻译的n-gram精确率
其他指标
- 精准匹配度(Exact Match, EM):计算预测结果与标准答案是否完全匹配
- 模糊匹配度(F1):计算预测结果与标准答案字级别的匹配程度
References
【机器学习】一文读懂分类算法常用评价指标 - 云+社区 - 腾讯云
深度学习常见任务的一些评价指标总结(如图像分类,目标检测,图像分割等) - 知乎