文章目录
- 1. 数据准备
- 2. 特征权重图
- 3. 特征相关性热度图 heatmap
- 4. LASSO 模型中 Lambda 选值图
- 5. 特征系数随 Lambda 变化曲线
- 6. 随机森林分类器
- 7. ROC 曲线
- 8. 精确度(Precision),敏感度(Sensitivity),特异度(Specificity)等输出
1. 数据准备
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from scipy.stats import ttest_ind, levene
from sklearn.linear_model import LassoCV
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, roc_auc_score, classification_report
xlsx_a = 'data/featureTable/aa.xlsx'
xlsx_b = 'data/featureTable/bb.xlsx'
data_a = pd.read_excel(xlsx_a)
data_b = pd.read_excel(xlsx_b)
print(data_a.shape,data_b.shape)
rows_a,cols_a = data_a.shape
rows_b,cols_b = data_b.shape
labels_a = np.zeros(rows_a)
labels_b = np.ones(rows_b)
data_a.insert(0, 'label', labels_a)
data_b.insert(0, 'label', labels_b)
data = pd.concat([data_a,data_b])
data_train, data_test = train_test_split(data,test_size=0.3, random_state = 15)
data_train_a = data_train[:][data_train['label'] == 0]
data_train_b = data_train[:][data_train['label'] == 1]
data_test_a = data_test[:][data_test['label'] == 0]
data_test_b = data_test[:][data_test['label'] == 1]
print(data_train_a.shape)
print(data_train_b.shape)
print(data_test_a.shape)
print(data_test_b.shape)
index = []
for colName in data.columns[:]:
if levene(data_train_a[colName], data_train_b[colName])[1] > 0.05:
if ttest_ind(data_train_a[colName], data_train_b[colName])[1] < 0.05:
index.append(colName)
else:
if ttest_ind(data_train_a[colName], data_train_b[colName],equal_var=False)[1] < 0.05:
index.append(colName)
print(len(index))
print(index)
data_train_a = data_train_a[index]
data_train_b = data_train_b[index]
data_train = pd.concat([data_train_a, data_train_b])
data_train = shuffle(data_train)
data_train.index = range(len(data_train))
X_train = data_train[data_train.columns[1:]]
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_train = pd.DataFrame(X_train)
X_train.columns = index[1:]
y_train = data_train['label']
data_test_a = data_test_a[index]
data_test_b = data_test_b[index]
data_test = pd.concat([data_test_a, data_test_b])
data_test = shuffle(data_test)
data_test.index = range(len(data_test))
X_test = data_test[data_test.columns[1:]]
X_test = scaler.transform(X_test)
X_test = pd.DataFrame(X_test)
X_test.columns = index[1:]
y_test = data_test['label']
alphas = np.logspace(-4,1,50)
model_lassoCV = LassoCV(alphas = alphas, max_iter = 100000).fit(X_train,y_train)
coef = pd.Series(model_lassoCV.coef_, index = X_train.columns)
print('%s %d'%('Lasso picked',sum(coef != 0)))
index = coef[coef != 0].index
X_train_raw = X_train
X_train = X_train[index]
X_test = X_test[index]
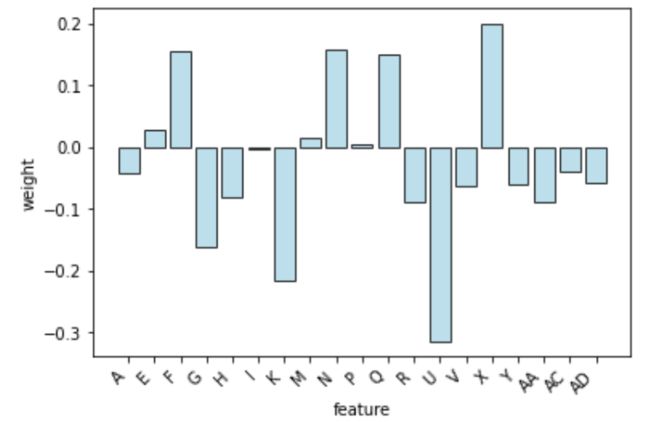
2. 特征权重图
plt.figure()
x_values = np.arange(len(index))
y_values = coef[coef != 0]
plt.bar(x_values, y_values
, color = 'lightblue'
, edgecolor = 'black'
, alpha = 0.8
)
plt.xticks(x_values
, index
, rotation='45'
, ha = 'right'
, va = 'top'
)
plt.xlabel("feature")
plt.ylabel("weight")
plt.show()
3. 特征相关性热度图 heatmap
plt.figure(figsize=(12,10), dpi= 80)
sns.heatmap(X_train.corr()
, xticklabels=X_train.corr().columns
, yticklabels=X_train.corr().columns
, cmap='RdYlGn'
, center=0.5
, annot=True)
plt.title('Correlogram of features', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()

4. LASSO 模型中 Lambda 选值图
MSEs = model_lassoCV.mse_path_
"""
# 等价于下面两行
MSEs_mean, MSEs_std = [], []
for i in range(len(MSEs)):
MSEs_mean.append(MSEs[i].mean())
MSEs_std.append(MSEs[i].std())
"""
MSEs_mean = np.apply_along_axis(np.mean,1,MSEs)
MSEs_std = np.apply_along_axis(np.std,1,MSEs)
plt.figure()
plt.errorbar(model_lassoCV.alphas_,MSEs_mean
, yerr=MSEs_std
, fmt="o"
, ms=3
, mfc="r"
, mec="r"
, ecolor="lightblue"
, elinewidth=2
, capsize=4
, capthick=1)
plt.semilogx()
plt.axvline(model_lassoCV.alpha_,color = 'black',ls="--")
print(model_lassoCV.alpha_)
plt.xlabel('Lambda')
plt.ylabel('MSE')
plt.show()

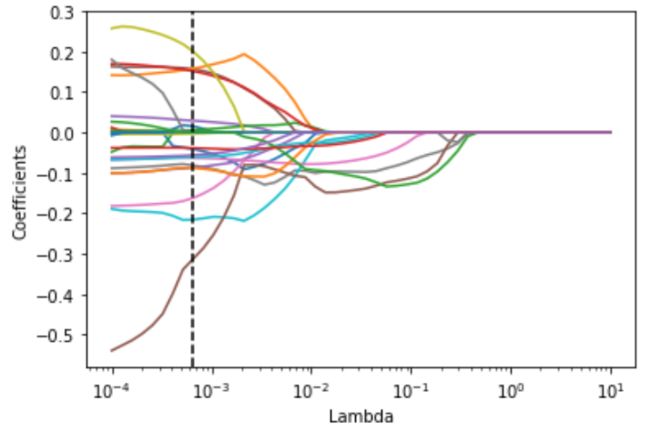
5. 特征系数随 Lambda 变化曲线
coefs = model_lassoCV.path(X_train_raw,y_train,alphas = alphas, max_iter = 100000)[1].T
plt.figure()
plt.semilogx(model_lassoCV.alphas_,coefs, '-')
plt.axvline(model_lassoCV.alpha_,color = 'black',ls="--")
plt.xlabel('Lambda')
plt.ylabel('Coefficients')
plt.show()
6. 随机森林分类器
model_rf = RandomForestClassifier(n_estimators = 200
, criterion = 'entropy'
, random_state = 20
, class_weight = 'balanced'
)
model_rf.fit(X_train,y_train)
print(model_rf.score(X_test,y_test))
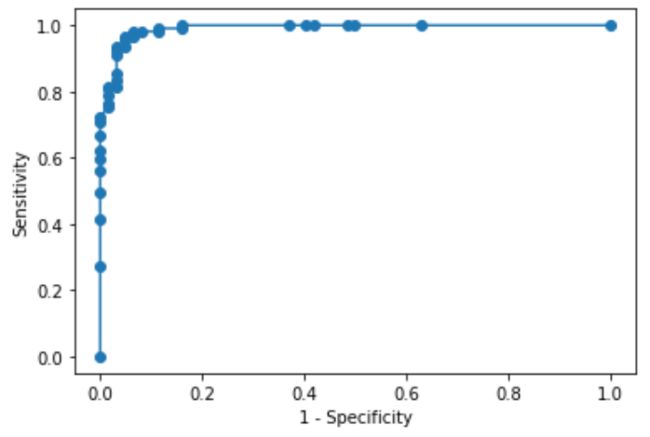
7. ROC 曲线
y_test_probs = model_rf.predict_proba(X_test)
fpr, tpr, thresholds = roc_curve(y_test, y_test_probs[:,1], pos_label = 1)
plt.figure()
plt.plot(fpr, tpr, marker = 'o')
plt.xlabel("1 - Specificity")
plt.ylabel("Sensitivity")
plt.show()
auc_score = roc_auc_score(y_test,model_rf.predict(X_test))
print(auc_score)
8. 精确度(Precision),敏感度(Sensitivity),特异度(Specificity)等输出
y_test_pred = model_rf.predict(X_test)
print(classification_report(y_test, y_test_pred))