word2vec的cbow
word2vec假设一个词和它周围的词是强相关的(叫discributional representation/asummption)
CBOW(Continuous Bag-of-Words)的目的是用一个词附近的几个词来表示这个词,比如一句话
“曾经有一份真诚的爱情摆在我的面前“
cbow就是要用神经网络把“曾经有一份真诚的”和“在我的面前”这两坨东西来表现(representation)“爱情”
嗨哟(还有)一点就是word2vec需要一个语料库,就是一堆词
用这句话当栗子
这两坨东西(“曾经有一份真诚的”,“在我的面前”)是在“爱情”前后,我们叫做“爱情”的上下文(context)
1. 先分一波词
1.1 把“曾经有一份真诚的爱情摆在我的面前”里的stop words[‘的’]去了,变成“曾经有一份真诚爱情摆在我面前”
1.2 分词,这句话就变成了[曾经,有,一份,真诚,爱情,摆在,我,面前]
1.3 把“爱情”抽出来,就剩[曾经,有,一份,真诚,摆在,我,面前]
2. 语料库登场
2.1 假设我们的语料库长这样[曾经, 有, 一份, 真诚, 爱情, 摆在, 我, 面前, 但是, 没有, 珍惜] (11个词,11维)(实际的语料库要比这个大的多的多)
3. 开始操作
3.1 结合了语料库和“爱情”的上下文再one-hot一波后,我们分好的词们就长这样了
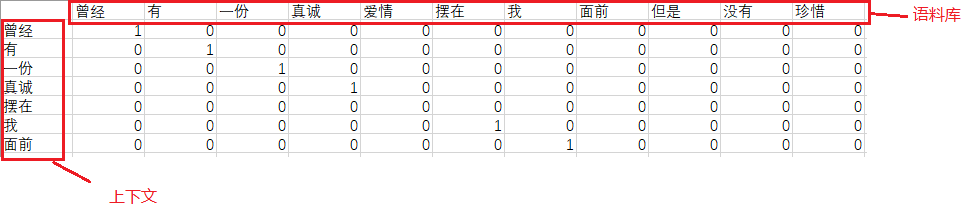
也就是
曾经 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
有 [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
一份 [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
真诚 [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
摆在 [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
我 [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
面前 [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
在这里的这7个向量,我们先叫他们上下文的向量
同理,
爱情就是 [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
4.构建神经网络
4.1 word2vec的神经网络分为输入层,投影层(隐藏层)和输出层。
4.2 需要把上下文的向量加和作为输入层
也就是这样
曾经+有+一份+ 真诚+爱情+摆在+我+面前 = [1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0 ] (11维, 和语料库一样)
(输入层: [1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0 ] )
4.3 投影层跟着感jio来就好,设置几个节点(nodes)都行,这里就先设俩方便描述
(投影层节点的数量=2 )
4.4 输出层就是 “爱情” [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
4.5 在输入层和投影层之间加入矩阵U
4.6 在投影层和输出层之间加入矩阵V
4.7 接下来,咱们的神经网络就长这样了
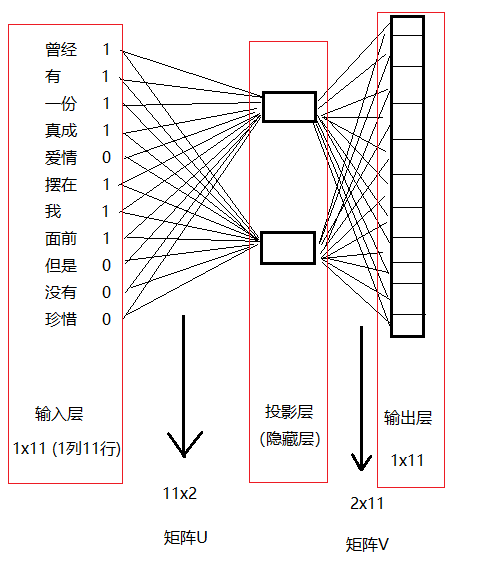
4.8 输入层的维度 * 矩阵U的维度 * 矩阵V的维度 = 输出层的维度
即 1 x 11 * 11 x 2 * 2 x 11 = 1 x 11 (输出层的维度)
我们需要找到最好的矩阵U和矩阵V来做到最后输出的结果越接近“爱情 [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]”越好

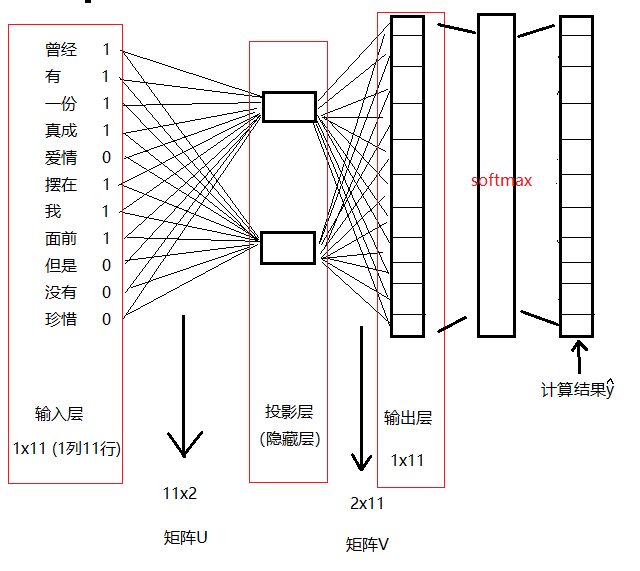
到这一步输出层输出的结果各种数字都有,我们需要做一波归一化(的概率),用softmax。
于是整个模型就长这样了
softmax的公式长这样
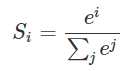
(TODO:写篇关于softmax的)
4.9 损失函数可以这样定义
J(θ) = ((y-bar) - 爱情) ^ 2
意思就是对(计算的结果的每一个维度 - 真是爱情这个词的相应的维度)的平方和
也可以用交叉熵来做损失函数,然后盘(优化)它
也可以用上下文向量的均值和真实的爱情的交叉熵来做损失函数
(TODO:写篇关于交叉熵的)
4.10 我们的目标是极小化损失函数J(θ), 可以用梯度下降算法来训练以找到较好的矩阵U和V。
(TODO:写篇关于梯度下降的)
4.11 当达到某个标准或阈值的时候,就可以收工了。
5. 可能的结果
最后计算的结果可能是[0.001, 0.002, 0.068, 0.0035, 0.91, 0.032, 0.0021, 0.047, 0.0065, 0.0032, 0.0049]
真是值爱情[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
以这个栗子为栗,计算的结果应该是在第5个维度的值,接近1
一些思考
- word2vec基本上就是语料库+上下文+神经网络
- cbow的神经网络最后没有用sigmoid的激活函数,而是使用了softmax来做了归一化的概率。
- 这个栗子中投影层用了2个节点,可以用m来替换,意思就是可以是任意数量的节点。