卷积神经网络发展
LeNet
LeNet 诞生于 1994 年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。自从 1988 年开始,在许多次成功的迭代后,这项由 Yann LeCun 完成的开拓性成果被命名为 LeNet5。
下面是LeNet的网络结构
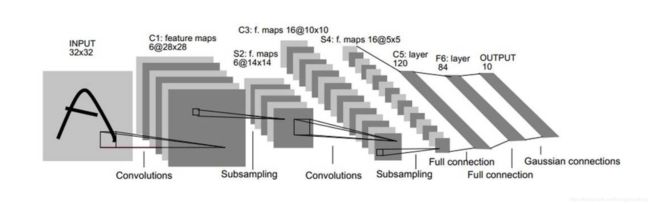
不计算输入层,LeNet-5一共是一个7层的神经网络。中间有提取特征的卷积层,也有降维的pooling层,最后经过三个FC全连接层得到输出。首先给出卷积&池化计算之后尺寸的计算公式
N = ( W − F + 2 P ) / S + 1 N=(W-F+2P)/S+1 N=(W−F+2P)/S+1
其中,数据维度为W*W,Filter大小为 F×F,S:步长P:padding的像素数。通过上述公式就可以计算每次卷积&池化之后的数据的尺寸情况了。下面看下几个网络中几层的情况:
C1层有6个卷积核,每个卷积核是 5 ∗ 5 5*5 5∗5的尺寸,所以经过卷积后的尺寸为 ( 32 − 5 + 0 ) / 1 + 1 = 28 (32-5+0)/1+1=28 (32−5+0)/1+1=28,有6个卷积核,则经过C1层后的输出后 6 @ 28 ∗ 28 6@28*28 6@28∗28。
S2层为降采样的pooling层,pooling层的采样层尺寸为 2 ∗ 2 2*2 2∗2的采样层,步长S为2,所以同理可以计算得到S2层的输出结果为 6 @ 14 ∗ 14 6@14*14 6@14∗14。
C3层是有16个卷积核,尺寸是 5 ∗ 5 5*5 5∗5的,同理得到输出为 16 @ 10 ∗ 10 16@10*10 16@10∗10。
S4层同上类似的pooling层,输出结果为 16 @ 5 ∗ 5 16@5*5 16@5∗5。
C5层是有120个卷积核的卷积层,每个卷积核是 5 ∗ 5 5*5 5∗5的尺寸。通过该卷积层,正好输出的结果是 120 ∗ 1 ∗ 1 120*1*1 120∗1∗1,可以直接连接后续的全连接层。
F6层为全连接层,将输出84个特征单元。
最后输出层的输出结果为10个类别。
### LeNet代码
import numpy as np
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# check device
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
# parameters
RANDOM_SEED = 42
LEARNING_RATE = 0.001
BATCH_SIZE = 32
N_EPOCHS = 15
IMG_SIZE = 32
N_CLASSES = 10
def train(train_loader, model, criterion, optimizer, device):
'''
Function for the training step of the training loop
'''
model.train()
running_loss = 0
for X, y_true in train_loader:
optimizer.zero_grad()
X = X.to(device)
y_true = y_true.to(device)
# Forward pass
y_hat, _ = model(X)
loss = criterion(y_hat, y_true)
running_loss += loss.item() * X.size(0)
# Backward pass
loss.backward()
optimizer.step()
epoch_loss = running_loss / len(train_loader.dataset)
return model, optimizer, epoch_loss
def validate(valid_loader, model, criterion, device):
'''
Function for the validation step of the training loop
'''
model.eval()
running_loss = 0
for X, y_true in valid_loader:
X = X.to(device)
y_true = y_true.to(device)
# Forward pass and record loss
y_hat, _ = model(X)
loss = criterion(y_hat, y_true)
running_loss += loss.item() * X.size(0)
epoch_loss = running_loss / len(valid_loader.dataset)
return model, epoch_loss
def get_accuracy(model, data_loader, device):
'''
Function for computing the accuracy of the predictions over the entire data_loader
'''
correct_pred = 0
n = 0
with torch.no_grad():
model.eval()
for X, y_true in data_loader:
X = X.to(device)
y_true = y_true.to(device)
_, y_prob = model(X)
_, predicted_labels = torch.max(y_prob, 1)
n += y_true.size(0)
correct_pred += (predicted_labels == y_true).sum()
return correct_pred.float() / n
def training_loop(model, criterion, optimizer, train_loader, valid_loader, epochs, device, print_every=1):
'''
Function defining the entire training loop
'''
# set objects for storing metrics
best_loss = 1e10
train_losses = []
valid_losses = []
# Train model
for epoch in range(0, epochs):
# training
model, optimizer, train_loss = train(train_loader, model, criterion, optimizer, device)
train_losses.append(train_loss)
# validation
with torch.no_grad():
model, valid_loss = validate(valid_loader, model, criterion, device)
valid_losses.append(valid_loss)
if epoch % print_every == (print_every - 1):
train_acc = get_accuracy(model, train_loader, device=device)
valid_acc = get_accuracy(model, valid_loader, device=device)
print(f'{datetime.now().time().replace(microsecond=0)} --- '
f'Epoch: {epoch}\t'
f'Train loss: {train_loss:.4f}\t'
f'Valid loss: {valid_loss:.4f}\t'
f'Train accuracy: {100 * train_acc:.2f}\t'
f'Valid accuracy: {100 * valid_acc:.2f}')
# plot_losses(train_losses, valid_losses)
return model, optimizer, (train_losses, valid_losses)
class LeNet5(nn.Module):
def __init__(self, n_classes):
super(LeNet5, self).__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2),
nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1),
nn.Tanh()
)
self.classifier = nn.Sequential(
nn.Linear(in_features=120, out_features=84),
nn.Tanh(),
nn.Linear(in_features=84, out_features=n_classes),
)
def forward(self, x):
x = self.feature_extractor(x)
x = torch.flatten(x, 1)
logits = self.classifier(x)
probs = F.softmax(logits, dim=1)
return logits, probs
# define transforms
transforms = transforms.Compose([transforms.Resize((32, 32)),
transforms.ToTensor()])
# download and create datasets
train_dataset = datasets.MNIST(root='mnist_data',
train=True,
transform=transforms,
download=True)
valid_dataset = datasets.MNIST(root='mnist_data',
train=False,
transform=transforms)
# define the data loaders
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=BATCH_SIZE,
shuffle=False)
torch.manual_seed(RANDOM_SEED)
model = LeNet5(N_CLASSES).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss()
model, optimizer, _ = training_loop(model, criterion, optimizer, train_loader, valid_loader, N_EPOCHS, DEVICE)
