经典深度学习网络训练模型
经典的深度学习网络训练模型整理
一
1.【AlexNet】-2012
https://blog.csdn.net/zyqdragon/article/details/72353420
深度学习AlexNet模型详细分析
Alex在2012年提出的alexnet网络结构模型引爆了神经网络的应用热潮,并赢得了2012届图像识别大赛的冠军,使得CNN成为在图像分类上的核心算法模型。
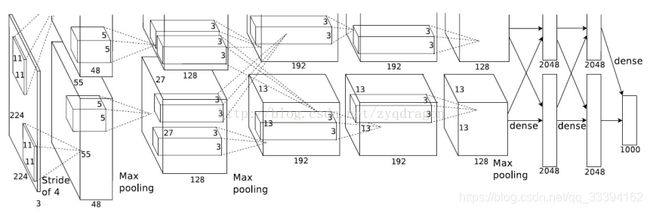
先给出AlexNet的一些参数和结构图:
卷积层:5层
全连接层:3层
深度:8层
参数个数:60M
神经元个数:650k
分类数目:1000类
输入层:227×227×3227×227×3
C1:96×11×11×3 (卷积核个数/宽/高/厚度)
C2:256×5×5×48(卷积核个数/宽/高/厚度)
C3:384×3×3×256(卷积核个数/宽/高/厚度)
C4:384×3×3×192(卷积核个数/宽/高/厚度)
C5:256×3×3×192(卷积核个数/宽/高/厚度)
作者:chaibubble
原文:https://blog.csdn.net/chaipp0607/article/details/72847422
https://blog.csdn.net/chaipp0607/article/details/72847422
从AlexNet理解卷积神经网络的一般结构
CNN中的卷积层操作与图像处理中的卷积是一样的,都是一个卷积核对图像做自上而下,自左而右的加权和操作,不同指出在于,在传统图像处理中,我们人为指定卷积核,比如Soble,我们可以提取出来图像的水平边缘和垂直边缘特征。而在CNN中,卷积核的尺寸是人为指定的,但是卷积核内的数全部都是需要不断学习得到的。比如一个卷积核的尺寸为3×3×33×3×3,分别是宽,高和厚度,那么这一个卷积核中的参数有27个。
在这里需要说明一点:
卷积核的厚度=被卷积的图像的通道数
卷积核的个数=卷积操作后输出的通道数
举一个例子,输入图像尺寸5×5×35×5×3(宽/高/通道数),卷积核尺寸:3×3×33×3×3(宽/高/厚度),步长:1,边界填充:0,卷积核数量:1。用这样的一个卷积核去卷积图像中某一个位置后,是将该位置上宽3,高3,通道3上27个像素值分别乘以卷积核上27个对应位置的参数,得到一个数,依次滑动,得到卷积后的图像,这个图像的通道数为1(与卷积核个数相同)
所以,卷积后的图像尺寸为:3×3×13×3×1(宽/高/通道数)

在AlexNet问世之后,CNN以一个很快的速度发展,截止到2017年,已经有了多代的网络结构问世,深度、宽度上也越来越大,效率和正确率上也越来越好:
AlexNet—NiN—VGG—GoogLeNet—ResNet
在这些结构中:
NiN 引入1×11×1卷积层(Bottleneck layer)和全局池化;
VGG将7×77×7替换成三个3×33×3;
GoogLeNet引入了Inception模块;
ResNet引入了直连思想;
DenseNet引入稠密链接,将当前的层与之后的所有层直连。
其中的一些网络甚至替换了AlexNet中提出的一些思想,但是CNN大体上结构依旧遵循着AlexNet,甚至还有很多传统ANN的思想存在。
2.【NiN】-2013
https://blog.csdn.net/P_LarT/article/details/83821743
卷积神经网络之NiN(2013)
新奇点
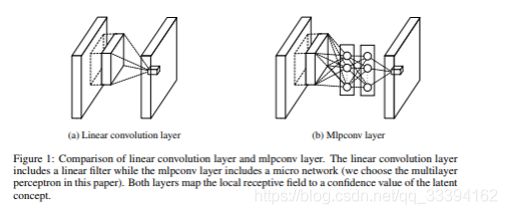
MLP Convolution Layers(MLP卷积层)
全局平均池化(GAP)层输出作为可信度
在卷积后面再跟一个1x1的卷积核对图像进行卷积
NiN在每次卷积完之后使用,目的是为了在进入下一层的时候合并更多的特征参数。同样NiN层也是违背LeNet的设计原则(浅层网络使用大的卷积核),但却有效地合并卷积特征,减少网络参数、同样的内存可以存储更大的网络。这个“网络的网络”(NIN)能够提高CNN的局部感知区域。
https://blog.csdn.net/u012885745/article/details/84714124
扒一扒神经网络–NIN
1.论文中的MLP在传统卷积后接了两个全连接层(等价于1*1的卷积层),隐层的第一层的神经单元就是patch中每个通道对应的每个像素赋予权重和bias后的计算值,然后再向后继续重复这种计算n-1次,通过这种方式,通过对特征图的线性组合实现了多通道之间的信息融合
2.全局平均池化替换全连接层
在传统的神经网络中,最后一个卷积层通常会被向量化输入到全连接层,然后接一个softmax进行分类。但全连接层由于神经元多,参数量大,常常容易引起过拟合问题,影响了模型的泛化能力。dropout [2]是一种解决这个问题的方式。
作者提出了另一种方式直接替换掉了全连接层,那就是全局平均池化。这种方法将卷积的最后一层(在NIN中也就是MLP的最后一层)的结果,对于每个类别有一张特征图(也就是将最后一层的特征图数设为类别数)然后进行全局平均池化,其结果将被直接输入到softmax中进行分类,得到每一个类别的预测值。
这样做的好处是:
a. 由于对网络的最后一层特征图直接进行池化作为分类器的输入,因此这种模式下可以使得特征图与类别之间的对应关系得到了增强。在下图的NIN可视化图中也可以看出,最后一个MLP层的特征图的最大激活区域与输入图像的真实物体的区域是相同的。
b. 这一层没有多余参数,因此对比起全连接层可以在一定程度上避免过拟合
c. 全局平均池化结合了图像的空间信息,因此这种模型对于输入的空间转换更鲁棒。
结构
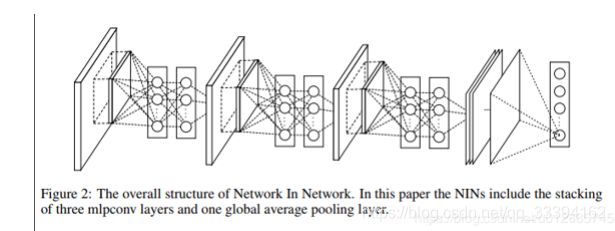
该论文的网络框架其实就是三层卷积,每个卷积层中都包含了一个MLP增强非线性能力。最后是一个全局平均池化层(GAP)层和softmax层。
3.【VGG】-2015
1.https://blog.csdn.net/u012885745/article/details/84634898
扒一扒神经网络–VGG
Very Deep Convolutional Networks for Large-Scale Image Recognition
代码:tensorflow对VGG的实现
https://github.com/tensorflow/tensorflow/blob/361a82d73a50a800510674b3aaa20e4845e56434/tensorflow/contrib/slim/python/slim/nets/vgg.py