寒假博客日记——第八天
图像分割
使用oxford-IIIT宠物数据集,获取方式如下:
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
tar -xvf images.tar.gz
tar -xvf annotations.tar.gz
在windows下可以直接访问网站下载,本菜逼使用wget命令下载后,不知道文件被下载到哪里了(应该要指定下载目录)于是又在浏览器里面下载了一次。
让我们看一下样本图像:


import os
input_dir='images/'
target_dir='annotations/trimaps/'
input_img_paths=sorted([
os.path.join(input_dir,fname) for fname in os.listdir(input_dir)
if fname.endswith('.jpg') and not fname.startswith('.')
# 将所有的输入图片路径存放到该列表,注意input是jpg格式,掩码是png格式
])
target_paths=sorted([
os.path.join(target_dir,fname) for fname in os.listdir(target_dir)
if fname.endswith('.png') and not fname.startswith('.')
])
import matplotlib.pyplot as plt
from tensorflow.keras.utils import load_img,img_to_array
plt.axis('off')
plt.imshow(load_img(input_img_paths[9]))
plt.show()
然后将数据处理为array格式, 并划分训练集和验证集:
import numpy as np
import random
img_size=(200,200) # 调整成统一尺寸
num_imgs=len(input_img_paths) # 样本总数
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_paths)
# 用相同的随机种子进行路径打乱,可以保证标签和输入的顺序相同
def path_to_input_image(path):
return img_to_array(load_img(path,target_size=img_size))
# 读取指定路径的图片为array格式
def path_to_target(path):
img=img_to_array(
load_img(path,target_size=img_size,color_mode='grayscale')
)
img=img.astype('uint8')-1 # 使标签变成0,1,2
return img
input_imgs=np.zeros((num_imgs,)+img_size+(3,),dtype='float32')
# 构造一个(样本数,200,200,3)的全零数组,存放输入用
targets=np.zeros((num_imgs,)+img_size+(1,),dtype='uint8')
# 构造一个(样本数,200,200,1)的全零数组,存放标签用
for i in range(num_imgs):
input_imgs[i]=path_to_input_image(input_img_paths[i]) # 读取第i个输入
targets[i]=path_to_target(target_paths[i]) # 读取第i个标签
num_val_samples=1000 # 验证集大小
train_input_imgs=input_imgs[:-num_val_samples]
train_targets=targets[:-num_val_samples]
val_input_imgs=input_imgs[-num_val_samples:]
val_targets=targets[-num_val_samples:]
# 划分训练集和验证集
下面我们来定义模型:
from tensorflow import keras
import keras
from keras.layers import *
def get_model(img_size,num_classes):
inputs=Input(shape=img_size+(3,))
x=Rescaling(1./255)(inputs) # 归一化
x=Conv2D(64,3,strides=2,activation='relu',padding='same')(x) # 用same确保特征图尺寸不变
x=Conv2D(64,3,activation='relu',padding='same')(x)
x=Conv2D(128,3,strides=2,activation='relu',padding='same')(x)
x=Conv2D(128,3,activation='relu',padding='same')(x)
x=Conv2D(256,3,strides=2,activation='relu',padding='same')(x)
x=Conv2D(256,3,activation='relu',padding='same')(x)
x=Conv2DTranspose(256,3,activation='relu',padding='same')(x)
x=Conv2DTranspose(256,3,strides=2,activation='relu',padding='same')(x)
x=Conv2DTranspose(128,3,activation='relu',padding='same')(x)
x=Conv2DTranspose(128,3,strides=2,activation='relu',padding='same')(x)
x=Conv2DTranspose(64,3,activation='relu',padding='same')(x)
x=Conv2DTranspose(64,3,strides=2,activation='relu',padding='same')(x)
outputs=Conv2D(num_classes,3,activation='softmax',padding='same')(x)
model=keras.Model(inputs,outputs)
return model
model=get_model(img_size,num_classes=3)
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 200, 200, 3)] 0
rescaling (Rescaling) (None, 200, 200, 3) 0
conv2d (Conv2D) (None, 100, 100, 64) 1792
conv2d_1 (Conv2D) (None, 100, 100, 64) 36928
conv2d_2 (Conv2D) (None, 50, 50, 128) 73856
conv2d_3 (Conv2D) (None, 50, 50, 128) 147584
conv2d_4 (Conv2D) (None, 25, 25, 256) 295168
conv2d_5 (Conv2D) (None, 25, 25, 256) 590080
conv2d_transpose (Conv2DTra (None, 25, 25, 256) 590080
nspose)
conv2d_transpose_1 (Conv2DT (None, 50, 50, 256) 590080
ranspose)
conv2d_transpose_2 (Conv2DT (None, 50, 50, 128) 295040
ranspose)
conv2d_transpose_3 (Conv2DT (None, 100, 100, 128) 147584
ranspose)
conv2d_transpose_4 (Conv2DT (None, 100, 100, 64) 73792
ranspose)
conv2d_transpose_5 (Conv2DT (None, 200, 200, 64) 36928
ranspose)
conv2d_6 (Conv2D) (None, 200, 200, 3) 1731
=================================================================
Total params: 2,880,643
Trainable params: 2,880,643
Non-trainable params: 0
_________________________________________________________________
进程已结束,退出代码0
这个模型和卷积网络很类似,都用了很多Conv2D,但是下采样的方式不同,分类任务中使用的最大池化层进行下采样,而在分割任务中使用步幅为2的卷积核进行下采样。这是因为在分类任务中我们关注的是类别特征,用最大池化层下采样可以获取到图像的类别特征。而在分割任务中我们关注的是空间特征,用最大池化层会破坏掉空间特征,因为我们不知道某个采样值来自池化窗口4个位置中的哪一个。所以如果关注特征的位置,往往使用步幅进行下采样,而不是最大池化层。Conv2DTranspose是Conv2D的逆过程,可以进行上采样。
然后训练模型,由于模型很大,训练起来比较慢,一个epoch要11s左右:
import keras.losses
import keras.models
import keras.callbacks
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
callbacks=keras.callbacks.EarlyStopping(patience=15,restore_best_weights=True)
history=model.fit(train_input_imgs,train_targets,epochs=60,
callbacks=[callbacks],batch_size=64,
validation_data=(val_input_imgs,val_targets))
model.save('分割.h5')
#model=keras.models.load_model('分割.h5')
epochs=range(1,len(history.history['loss'])+1)
loss=history.history['loss']
val_loss=history.history['val_loss']
plt.figure()
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Training and Validation loss')
plt.legend()
plt.show()
from tensorflow.keras.utils import array_to_img
i=4
test_image=val_input_imgs[i]
plt.axis('off')
plt.imshow(array_to_img(test_image))
plt.show()
mask=model.predict(np.expand_dims(test_image,0))[0] # 扩充批尺寸,并取第一个元素
def display_mask(pred):
mask=np.argmax(pred,axis=-1)
mask*=127
plt.axis('off')
plt.imshow(mask)
display_mask(mask)
plt.show()


在验证集上分割的准确率大概是85%左右,在训练集上大概是91%左右,虽有一些小瑕疵,但是大体上可以完整分割了。
进阶知识
下面讲讲关于现代卷积神经网络架构模式的进阶知识。
残差连接
网络深度过大的时候会出现梯度消失,这是因为函数连太长,导致传播过程中的噪声过大,掩盖的信息梯度,反向传播会停止,残差连接提供了信息捷径,能够将较早的层的误差梯度信息以无噪声的方式传播给后面的层。
使用残差连接的时候可能出现输入的尺寸和输出的尺寸不一致的情况,此时无法使用add运算将输入和输出相加,处理的办法如下:
- 当输入输出的图像尺寸一致,而图像的深度不一致时,使用1*1卷积改变输入的通道数:
import keras
from keras.layers import *
from keras.utils.vis_utils import plot_model
# 当输出的通道数和输入的通道数不同时:
inputs=Input(shape=(32,32,1))
x=Conv2D(32,3,activation='relu',padding='same')(inputs)
residual=x # 一个指针,记录残差
x=Conv2D(64,3,activation='relu',padding='same')(x) # 通道数变成64了
residual=Conv2D(64,1)(residual) # 不使用激活函数,用1*1的卷积核改变通道数
x=add([x,residual])
model=keras.Model(inputs,x)
plot_model(model,'model1.png',True)
- 当输入输出的图像尺寸和通道数都不一致时(通常是输出经过了最大池化层):使用增大步幅的方式对输入进行下采样,仍然使用1*1卷积核,调整通道数
# 当输出的尺寸和输入不同时:
inputs=Input(shape=(32,32,3))
x=Conv2D(32,3,activation='relu')(inputs)
residual=x
x=Conv2D(64,3,activation='relu',padding='same')(x)
x=MaxPooling2D(2,padding='same')(x)
residual=Conv2D(64,1,strides=2)(residual) # 不要激活函数
x=add([x,residual])
model=keras.Model(inputs,x)
plot_model(model,'model3.png',True)
总结上面两点,可以设置一个残差块函数:
def residual_block(x,filters,pooling=False):
residual=x
x=Conv2D(filters,3,activation='relu',padding='same')(x)
x=Conv2D(filters,3,activation='relu',padding='same')(x)
if pooling:
x=MaxPooling2D(2,padding='same')(x)
residual=Conv2D(filters,1,strides=2)(residual)
# 如果使用最大池化层,那么输入也要经过步幅为2的1*1卷积核下采样
elif filters!=residual.shape[-1]:
residual=Conv2D(filters,1)(residual)
# 如果输入的通道数和输出的通道数不一致,用1*1卷积进行调整
x=add([x,residual])
return x
inputs=Input(shape=(32,32,3))
x=Rescaling(1./255)(inputs)
x=residual_block(x,filters=32,pooling=True)
x=residual_block(x,filters=64,pooling=True)
x=residual_block(x,filters=128,pooling=False)
x=GlobalAvgPool2D()(x)
outputs=Dense(1,'sigmoid')(x)
model=keras.Model(inputs,outputs)
plot_model(model,'model4.png',True)
批量规范化BatchNormalization
批量规范化可以用于模型内部的层的标准化,有助于梯度的传播。
x=Conv2D(32,3,use_bias=False) # 因为要进行标准化,所以偏置不起作用,可以节省微量的计算资源
x=BatchNormalization()(x)
x=Activation('relu')(x)
作者推荐的写法是把激活函数写在BN层以后,据说可以更好的让激活函数起作用,不过我不是特别认可,因为这可能导致一些神经元死亡,其值直接无法传给后面的层。
深度可分离卷积
Conv2D的卷积核是3维的,其中有一个维度是通道数,说明Conv2D是同时处理位置信息和通道信息的,但是在训练过程中生成的各通道其相关性是非常弱的(因为一个卷积核生成一个通道,不同的卷积核生成不同的通道),所以深度可分离卷积的思想就是把位置信息和通道信息的处理分离开。
它采用的卷积核是2维的,没有通道数这个维度,因此一个卷积核只处理一个通道。这大大减小了卷积核中的参数。卷积核处理完每个通道后,将所有的通道拼接起来,然后使用1*1的卷积核来处理拼接后的特征图(该1*1的卷积核是3维的)。即:先学习空间特征,后学习通道特征。
深度可分离卷积使用的参数远远小于卷积,收敛更快,过拟合的风险更小。但是在GPU上并没有运行得更快,这是因为NVDIA的显卡专门优化了卷积的运算速率,将卷积的效率提升到了极致,但是对于深度可分离的卷积并没有做硬件上的优化。如果在CPU上运行,会发现运行速度快了很多。
在之前的猫狗大战数据集上再次训练,看看使用了深度可分离卷积和残差连接后的改进情况:
import os,shutil,pathlib
import matplotlib.pyplot as plt
original_dir=pathlib.Path('../猫狗大战/train')
new_base_dir=pathlib.Path('.')
def make_subset(subset_name,start_index,end_index): # 拷贝5000张图片到当前目录
for category in ('cat','dog'): # 先拷贝猫,再拷贝狗
dir=new_base_dir/subset_name/category # 要生成图片的目录
os.makedirs(dir,exist_ok=True) # 生成该目录
fnames=[f'{category}.{i}.jpg' for i in range(start_index,end_index)] # 要拷贝的图片名称
for fname in fnames:
shutil.copyfile(src=original_dir/fname,dst=dir/fname) # 将图片从源地址拷贝到目的地址
# make_subset('train',0,1000)
# make_subset('validation',1000,1500)
# make_subset('test',1500,2500)
from tensorflow.keras.utils import image_dataset_from_directory
train_dataset=image_dataset_from_directory(
directory=new_base_dir/'train',
image_size=(180,180),
batch_size=32
)
validation_dataset=image_dataset_from_directory(
directory=new_base_dir/'validation',
image_size=(180,180),
batch_size=32
)
test_dataset=image_dataset_from_directory(
directory=new_base_dir/'test',
image_size=(180,180),
batch_size=32
)
data_augmentation=keras.Sequential(
[
RandomFlip('horizontal'), # 水平翻转
RandomRotation(0.1), # 随机选择
RandomZoom(0.2) # -20%到20%范围内缩放
]
)
inputs=Input(shape=(180,180,3))
x=data_augmentation(inputs)
x=Rescaling(1./255)(x)
x=Conv2D(32,5,use_bias=False)(x) # 特征通道相关性很低对于RGB图像不成立,因为红绿蓝三个通道是高度相关的,所以第一层要用Conv2D
for size in [32,64,128,256,512]: # 通道数指数级递增
residual=x # 残差
x=BatchNormalization()(x)
x=Activation('relu')(x)
x=SeparableConv2D(size,3,padding='same',use_bias=False)(x)
x=BatchNormalization()(x)
x=Activation('relu')(x)
x=SeparableConv2D(size,3,padding='same',use_bias=False)(x)
x=MaxPooling2D(3,strides=2,padding='same')(x)
# 下采样
residual=Conv2D(size,1,strides=2,padding='same',use_bias=False)(residual)
x=add([x,residual])
# 残差连接
x=GlobalAvgPool2D()(x)
x=Dropout(0.5)(x)
outputs=Dense(1,activation='sigmoid')(x)
model=keras.Model(inputs,outputs)
plot_model(model,'model5.png',True)
import keras.callbacks
model.compile(loss=keras.losses.binary_crossentropy,metrics=['accuracy'])
callback=keras.callbacks.EarlyStopping('val_accuracy',patience=50,restore_best_weights=True)
board=keras.callbacks.TensorBoard('log3')
history=model.fit(train_dataset,epochs=500,
validation_data=validation_dataset,
callbacks=[callback,board])
test_loss,test_acc=model.evaluate(test_dataset)
print(f'Test accuracy: {test_acc:.3f}')
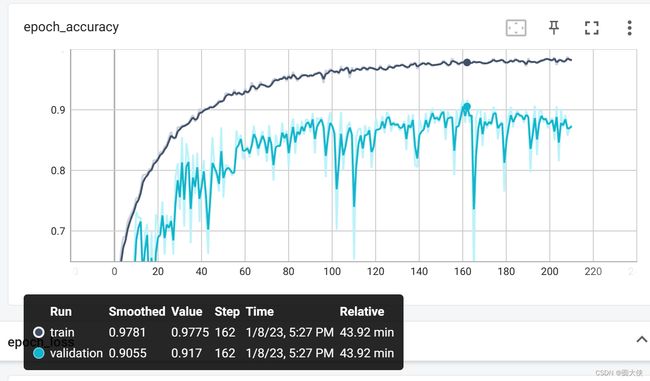
Test accuracy: 0.897
在测试集上准确率接近90%,提升了5%左右,可见更好的网络结构确实能够提升准确率。
卷积神经网络的可解释性
卷积神经网络处理图像时,是能够看到其内部输出的,下面从3个方面来可视化卷积神经网络的中间输出。我们将使用之前加了图像增强的小型猫狗模型
model=keras.models.load_model('猫狗模型.h5')
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 180, 180, 3)] 0
sequential (Sequential) (None, 180, 180, 3) 0
rescaling (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 178, 178, 32) 896
max_pooling2d (MaxPooling2D (None, 89, 89, 32) 0
)
conv2d_1 (Conv2D) (None, 87, 87, 64) 18496
max_pooling2d_1 (MaxPooling (None, 43, 43, 64) 0
2D)
conv2d_2 (Conv2D) (None, 41, 41, 128) 73856
max_pooling2d_2 (MaxPooling (None, 20, 20, 128) 0
2D)
conv2d_3 (Conv2D) (None, 18, 18, 256) 295168
max_pooling2d_3 (MaxPooling (None, 9, 9, 256) 0
2D)
conv2d_4 (Conv2D) (None, 7, 7, 256) 590080
flatten (Flatten) (None, 12544) 0
dropout (Dropout) (None, 12544) 0
dense (Dense) (None, 1) 12545
=================================================================
Total params: 991,041
Trainable params: 991,041
Non-trainable params: 0
_________________________________________________________________
中间激活值的可视化
首先随便从网上下载一张猫的图片,并显示出来
import numpy as np
import tensorflow.keras as tf_keras
img_path=tf_keras.utils.get_file(
fname='cat.jpg',origin='https://img-datasets.s3.amazonaws.com/cat.jpg'
) # 随便下载一张猫的测试图像,从origin网站下载,命名为cat.jpg,返回值是一个字符串,表示图片在本地的路径
def get_img_array(img_path,target_size):
img=tf_keras.utils.load_img(img_path,target_size=target_size) # 读取一张图片
array=tf_keras.utils.img_to_array(img) # 将图像转换为(180,180,3)格式为float32的np.array
array=np.expand_dims(array,axis=0) # 增加批尺寸维度
return array
img_tensor=get_img_array(img_path,target_size=(180,180))
import matplotlib.pyplot as plt
plt.axis('off')
plt.imshow(img_tensor[0].astype('uint8'))
plt.show()

layer_outputs=[]
layer_name=[]
for layer in model.layers:
if isinstance(layer,(Conv2D,MaxPooling2D)):
layer_outputs.append(layer.output)
layer_name.append(layer.name)
# 把卷积层和池化层的输出加入列表
activation_model=keras.Model(model.input,outputs=layer_outputs)
activations=activation_model.predict(img_tensor)
first_layer_activation=activations[0]
plt.matshow(first_layer_activation[0,:,:,5],cmap='viridis')
plt.show()
查看一下第一层的第五个通道:

猫的轮廓被检测出来了,尤其是眼睛很醒目。
下面显示每一个层、每一个通道的输出:
images_per_row=16 # 每一行放多少张图片
for layer_name, layer_activation in zip(layer_names, activations):
# 对于每一个层
n_features=layer_activation.shape[-1] # 通道数
size=layer_activation.shape[1] # 图像的长宽
n_cols=n_features//images_per_row # 列数
display_grid=np.zeros((
(size+1)*n_cols-1, images_per_row*(size+1)-1
)) # 准备一个空网格,显示这个激活值中的所有通道
for col in range(n_cols):
for row in range(images_per_row):
channel_index=col * images_per_row+row # 通道数的索引
channel_image=layer_activation[0,:,:,channel_index].copy()
# 单个通道
if channel_image.sum() !=0 :
channel_image-=channel_image.mean()
channel_image/=channel_image.std()
channel_image*=64
channel_image+=128
# 将所有通道值规范化到[0,255]范围内,全0通道仍然全为0
channel_image=np.clip(channel_image,0,255).astype('uint8')
display_grid[
col*(size+1):(col+1)*size+col,
row*(size+1):(row+1)*size+row
]=channel_image # 将通道矩阵放在空网格中
scale=1./size
plt.figure(figsize=(scale*display_grid.shape[1],
scale*display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.axis('off')
plt.imshow(display_grid,aspect='auto',cmap='viridis')
plt.savefig(f'{layer_name}.png',dpi=2000)
csdn贴图要一张一张传,太麻烦了,所以把第一层和最后一层贴出来
(传不出来,laji网站)
可以发现前面的层保留了几乎所有的原始图像信息,越到后面越抽象。越到后面出现的空白图片越多,这是因为卷积核没有匹配到特定的模式。深度神经网络可以有效的作为信息蒸馏管道。
总结
今天好像学了蛮多东西,但是总结起来也不过两三点,更多的是体会计算机视觉的思想。关于卷积模型处理图像过程的可视化还只进行了第一点,另外两点要留到明天去学了。已经坚持几天没用电脑刷b站了,但是今天晚上还是不小心打开了哔站,一不小心就刷了近一个小时,都够我打三盘游戏了hhh。需要反思,不能用电脑娱乐!花重金买的显卡是用来学习滴。